

Voice: 原始 UI。
声音是人类的第一个界面——在书写或打字之前,它就让我们能够分享想法、协调工作并建立关系。随着数字系统的日益强大,声音正在重新成为人类与计算机最自然的交互方式。
然而,今天的系统仍然有限——不可靠、专有且在实际应用中过于脆弱。缩小这一差距需要具备出色转录、深刻理解、多语言流利以及开放灵活部署的工具。
我们发布 Voxtral 模型以加速这一未来。这些最先进的语音理解模型有两种版本——一种是 24B 变体,适用于生产规模的应用,另一种是 3B 变体,适用于本地和边缘部署。两个版本均采用 Apache 2.0 许可证发布,并且也可通过我们的API获取。API 将转录查询路由到优化过的 Voxtral Mini(Voxtral Mini Transcribe)版本,从而实现无与伦比的成本和延迟效率。
开放、亲民且生产就绪的语音理解,让每个人都能受益。
直到最近,获得真正可用的语音智能以投入生产意味着要在两个权衡之间做出选择:
-
开源 ASR 系统,具有较高的词错误率和有限的语义理解能力
-
闭源的 API,结合了强大的转录和语言理解能力,但成本更高且在部署上缺乏控制
Voxtral 桥接了这一差距。它提供最先进的准确性和原生语义理解,在开放的环境中,价格仅为同类 API 的一半以下。这使得高质量的语音智能既经济又可控,可以大规模使用。
Voxtral 模型超越了简单的转录,具备以下功能:
-
长格式上下文:使用 32k token 上下文长度,Voxtral 可以处理长达 30 分钟的音频进行转录,或长达 40 分钟的理解
-
内置问答和总结:可以直接针对音频内容提问或生成结构化摘要,无需串联单独的 ASR 和语言模型
-
原生多语言:自动检测语言并在世界上最广泛使用的语言(英语、西班牙语、法语、葡萄牙语、印地语、德语、荷兰语、意大利语等)上提供最先进的性能,帮助团队使用单一系统服务于全球受众
-
直接通过语音调用功能:使用户可以直接触发后端功能、工作流或 API 调用,基于用户的语音意图,将语音交互转化为可执行的系统命令,无需中间解析步骤。
-
擅长处理文本:保留了其语言模型基础模型 Mistral Small 3.1 的文本理解能力。
这些能力使 Voxtral 模型成为现实世界交互和下游操作的理想选择,例如摘要、答案、分析和洞察。对于成本敏感的应用场景,Voxtral Mini Transcribe 的价格不到 OpenAI Whisper 的一半,性能更优。对于高端应用场景,Voxtral Small 的价格不到 ElevenLabs Scribe 的一半,性能相当。
基准
语音转录
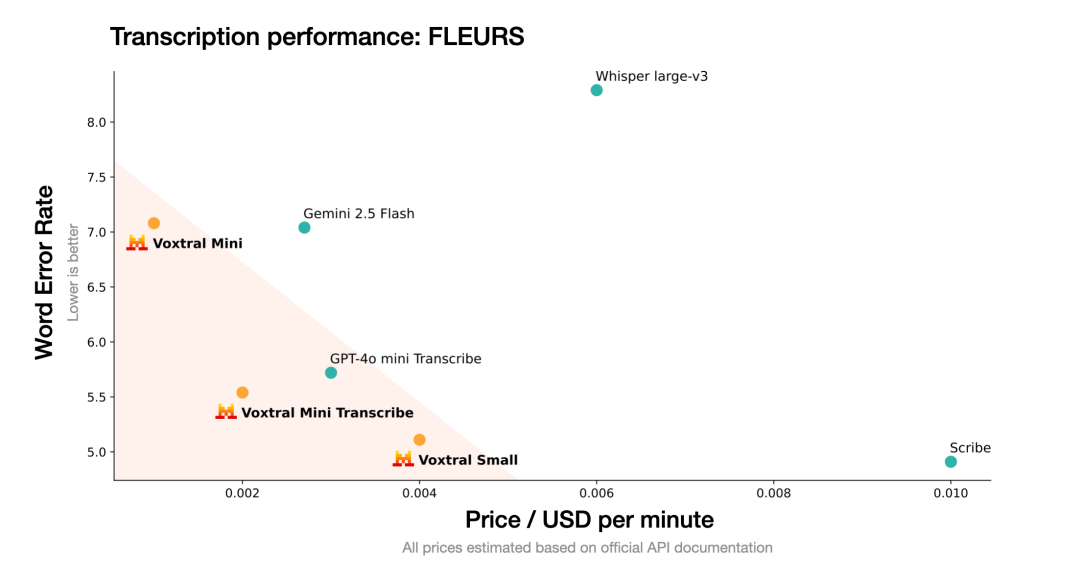
为了评估 Voxtral 的转录能力,我们在一系列的英语和多语言基准上对其进行评估。对于每个任务,我们报告跨语言的宏平均词错误率(越低越好)。对于英语,我们报告短形式(<30 秒)和长形式(>30 秒)的平均值。
Voxtral 在所有任务中全面超越了当前领先的开源语音转录模型 Whisper large-v3。它在所有任务中都击败了 GPT-4o mini Transcribe 和 Gemini 2.5 Flash,并在英语短形式和 Mozilla Common Voice 上取得了最先进的结果,超过了 ElevenLabs Scribe,展示了其强大的多语言能力。
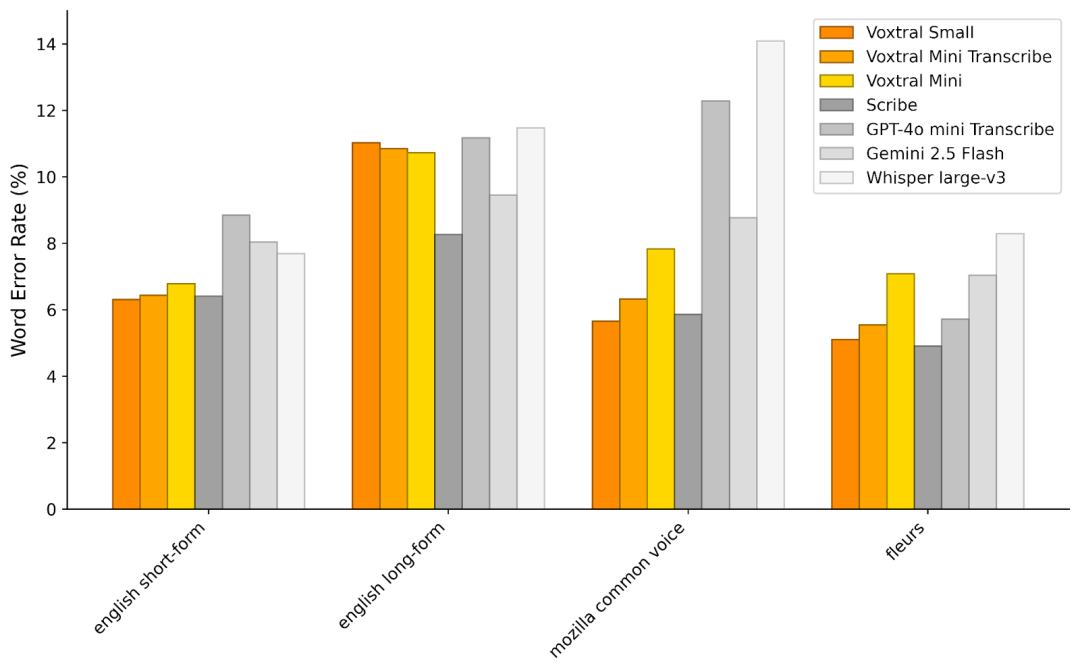
在 FLEURS 中跨语言评估时,Voxtral Small 在每个任务上都优于 Whisper,实现了多种欧洲语言的最先进的性能。
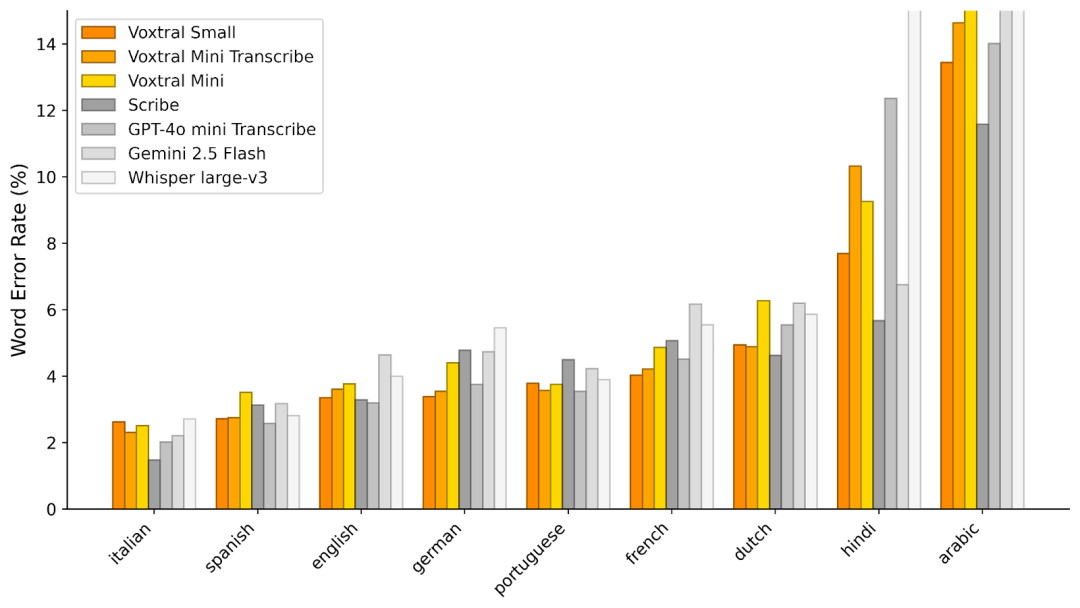
马克罗平均细节:
-
短形式:LibriSpeech 清晰,LibriSpeech 其他,GigaSpeech,VoxPopuli,Switchboard,CHiME-4,SPGISpeech
-
长形式:Earnings-21 10-m,Earnings-22 10-m
-
Mozilla 共同声音 15.1: 英语、法语、德语、西班牙语、意大利语、葡萄牙语、荷兰语、印地语
-
FLEURS: 英语、法语、德语、西班牙语、意大利语、葡萄牙语、荷兰语、印地语、阿拉伯语
音频理解
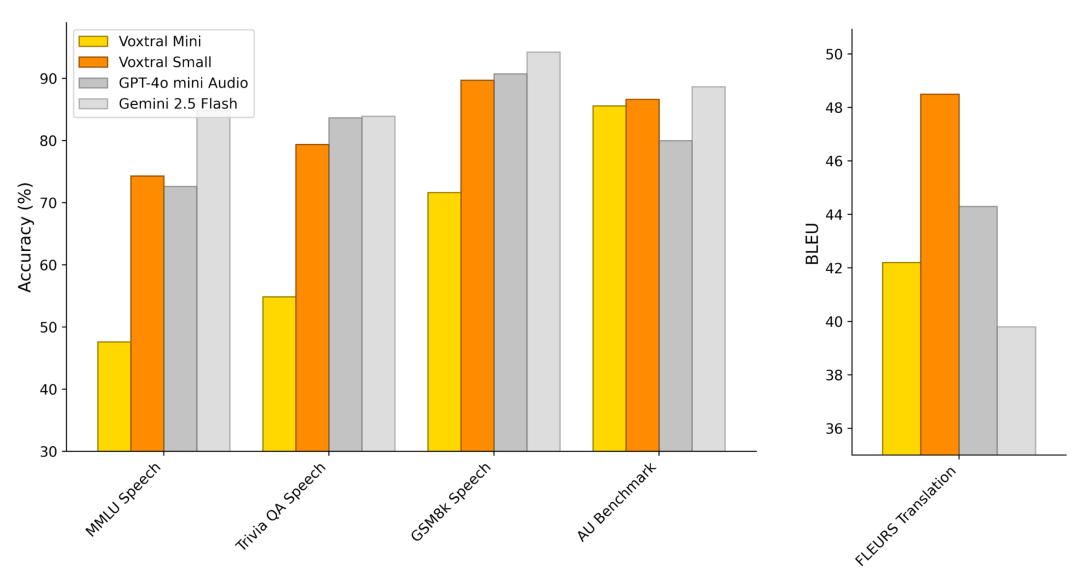
Voxtral Small 和 Mini 可以直接从语音中回答问题,或者通过提供语音和文本提示来回答。为了评估语音理解能力,我们创建了三种常见文本理解任务的语音合成版本。我们还在一个内部语音理解(AU)基准测试上评估了模型,该基准测试要求模型回答 40 个长格式音频示例中的具有挑战性的问题。最后,我们在 FLEURS-Translation 基准测试上评估了语音翻译能力。
Voxtral Small 在所有任务上与 GPT-4o-mini 和 Gemini 2.5 Flash 竞争,并在语音翻译方面取得了最先进的性能。
文本
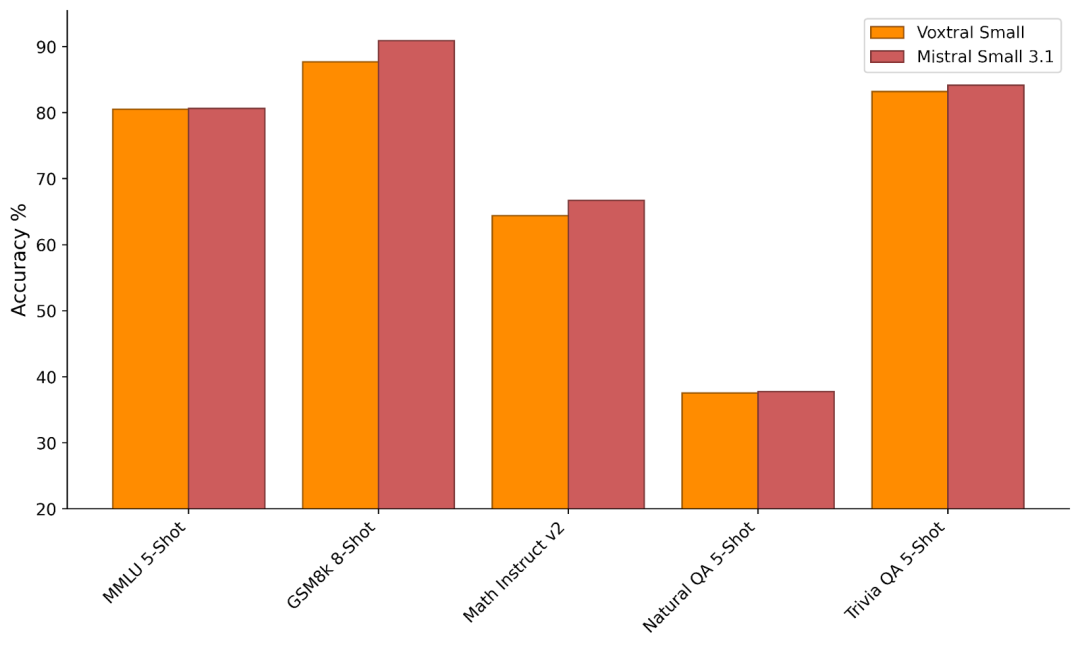
Voxtral 保留其语言模型骨干的文字能力,使其能够分别作为 Ministral 和 Mistral Small 3.1 的即插即用替代品使用。
Try it for free
无论您是在笔记本上进行原型设计、在本地运行私有工作负载,还是在云端扩展到生产环境,入门都非常 straightforward。
-
下载并本地运行:您可以在 Hugging Face 上下载 Voxtral(24B)和 Voxtral Mini(3B)。
-
尝试 API:通过一次 API 调用 将前沿语音智能集成到您的应用程序中。定价从每分钟 0.001 美元起,使高质量的转录和理解在大规模应用中变得经济实惠。了解详情请参阅我们的文档 这里。
-
在 Le Chat 上尝试:在 Le Chat 的语音模式下尝试 Voxtral(将在未来几周内向所有用户推出)——在网页或移动设备上使用。录制或上传音频,获取转录,提问或生成摘要。
-
高级企业功能。
我们还为具有更高安全要求、扩展需求或特定领域需求的企业提供 Voxtral 的定制功能。
-
生产规模的私有部署:我们的解决方案团队可以帮助您在您自己的基础设施中为生产规模的推理设置 Voxtral。这适用于有严格数据隐私要求的受监管行业。这包括在多个 GPU 或节点上部署 Voxtral 的指导和工具,以及针对生产吞吐量和成本效率优化的量化构建。
-
领域特定的微调:与我们的应用 AI团队合作,将 Voxtral 适应特定的上下文,如法律、医疗、客户服务或内部知识库,以提高您使用场景的准确性。
-
Advanced context: 我们邀请设计合作伙伴构建对说话人识别、情绪检测、高级会话分割以及更长上下文窗口的支持,以满足更多样化的需求。
-
专用集成支持:优先访问工程资源和咨询,以帮助将 Voxtral 干净地集成到您的现有工作流程、产品或数据管道中。
(文:路过银河AI)