

本文的共同第一作者为新加坡南洋理工大学博士后研究员李一鸣博士和浙江大学区块链与数据安全全国重点实验室博士生邵硕,通讯作者为李一鸣博士和浙江大学秦湛教授。其他作者包括:浙江大学博士生何宇,美国马里兰大学博士后研究员国珺峰博士,新加坡南洋理工大学张天威副教授、陶大程教授,美国 IBM 研究院首席研究科学家 Pin-Yu Chen 博士,德国亥姆霍兹信息安全中心主任 Michael Backes 教授,英国牛津大学 Philip Torr 教授,和浙江大学计算机科学与技术学院院长任奎教授。
你是否也曾担心过,随手发给 AI 助手的一份代码或报告,会让你成为下一个泄密新闻的主角?又或是你在网上发布的一张画作,会被各种绘画 AI 批量模仿并用于商业盈利?
这并非危言耸听,而是每个 AI 用户和从业者身上都可能发生的风险。2023 年,三星的一名员工被发现将公司的一份机密源码泄露给了 ChatGPT;同年,意大利数据保护机构也因担心当地居民的对话被用于境外 AI 训练,一度叫停了对 ChatGPT 的使用。随着生成式 AI 的全面普及,越来越多的用户在日常工作生活中使用 AI、依赖 AI,这些真实的事件,为每一位身处 AI 浪潮的用户和从业者敲响了警钟。
这揭示了一种深刻的变革:在 AI 时代,尤其是生成式 AI 的时代,数据不再只是硬盘中的静态文件,而是贯穿 AI 训练、推理、生成的整个生命周期中的「流体」,传统的数据保护方法(如文件加密、防火墙等)已无法应对 AI 场景下的数据保护挑战,对于用户和 AI 从业者而言,迫切需要一个全新的认知框架来全面认识生成式 AI 时代的数据保护问题,来应对数据保护挑战。
在(生成式)人工智能时代,当我们谈论数据保护时,我们在谈论什么?为了回答这一问题,来自浙江大学区块链与数据安全全国重点实验室、南洋理工大学、马里兰大学、IBM、德国亥姆霍兹信息安全中心、牛津大学的研究者们近期发布了前瞻论文《Rethinking Data Protection in the (Generative) Artificial Intelligence Era》,旨在通过通俗易懂的语言,为广大科技群体提供一个新颖的、系统性的视角看待人工智能时代下的数据保护问题。

-
论文题目:Rethinking Data Protection in the (Generative) Artificial Intelligence Era
-
论文链接:http://arxiv.org/abs/2507.03034
在生成式人工智能时代
哪些数据需要被保护?
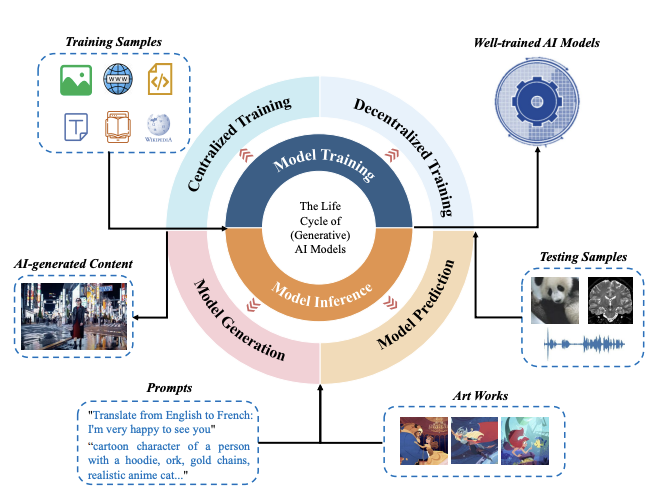
在生成式人工智能时代,数据保护的范畴已远不止传统对静态数据的保护,而是要保护贯穿于整个以模型为中心的生命周期中的各种不同类型的数据,包括训练数据集、人工智能模型、部署集成数据、用户输入和人工智能合成内容。
-
训练数据集:在模型开发的过程中,需要大量高质量的训练数据集作为模型训练的「燃料」。训练数据集往往是从多个不同数据源进行收集的,因而极有可能包含隐私或版权数据。
-
人工智能模型:人工智能模型,包括它的架构设置和模型权重,在完成模型训练后,也同样变成了非常重要的数据资产。这些模型是对海量数据的一个压缩和凝练,不仅本身具有重大的应用价值,预训练的模型参数也同样能够帮助其他下游任务模型的快速开发,具备更广泛的产业链价值。
-
部署集成数据:除了人工智能模型之外,在模型部署阶段,当前的人工智能应用都会引入一些额外的辅助数据,用于提高 AI 模型在实际应用中的性能和及时性。两个最突出的例子就是系统提示词和外部数据库。系统提示词能够为生成式人工智能模型提供一个统一的、事先定义的指令和上下文,用于引导模型生成更符合人类价值观或者特定风格的回复;而外部数据库被广泛用于检索增强生成当中,通过为生成式 AI 提供更新、更及时、更专业化的信息,在不需要修改模型的情况下,提高模型生成内容的准确性。
-
用户输入:在模型推理阶段,用户的输入信息也是亟待保护的重要内容,出于隐私、安全和伦理等原因,保护这些提示数据至关重要。例如,从隐私角度来看,用户查询中包含的任何个人信息(如姓名、地址、健康详情等)都应符合数据保护法律并满足用户对隐私的期望。商业机密同样面临风险 —— 例如,员工使用 AI 编程助手并输入专有代码作为提示。若 AI 服务保留此类输入,可能导致商业秘密意外泄露。
-
人工智能合成内容(AIGC):最后一种类型的数据是 AI 合成内容,随着生成式 AI 能力的不断提升,AI 合成内容已经达到了非常高的质量,与人类创造的内容差距越来越小,除此之外,AI 合成内容也能被用于创建大规模的合成数据集,对于 AI 模型的进一步开发等过程也有着重大的价值。
在生成式人工智能时代
我们应该如何保护数据?
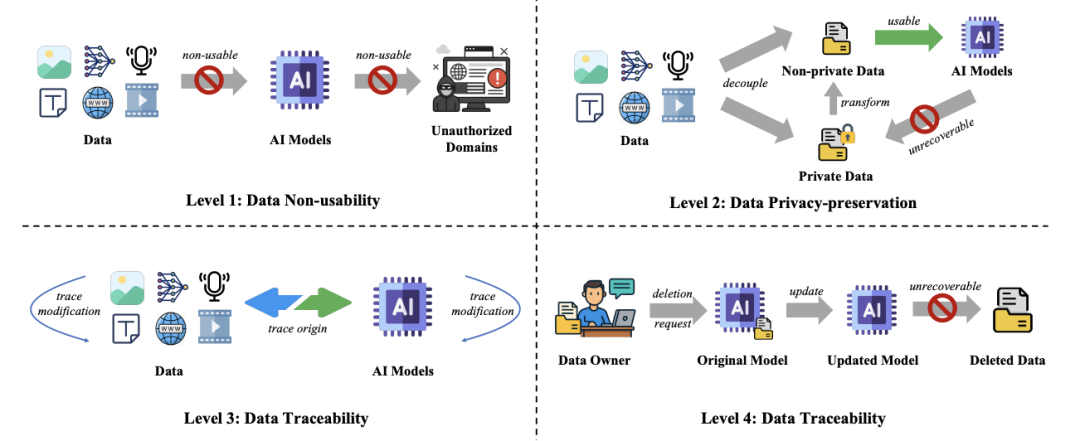
为了系统性地建模 AI 时代的数据保护问题,本文提出了一个全新的数据保护分级体系,将数据保护的目标由强到弱的顺序分为四类:数据不可用、数据隐私保护、数据可溯源、数据可删除。该分类法旨在平衡「数据效用」与「数据控制」的关系,为复杂的数据保护问题提供一个结构化的解决方案,进而指导从业者和监管者根据实际情况寻找一个更好的效用 – 控制平衡。
-
等级 1. 数据不可用(Data Non-usability):数据不可用指的是从根本上阻止数据被用于 AI 模型的训练或者推理流程,即使攻击者获取了数据,这些数据也不会对模型的学习或者预测起到任何正面作用。数据不可用是最高级别的数据保护,通过牺牲数据效用来换取绝对的保护。
-
等级 2. 数据隐私保护(Data Privacy-preservation):数据隐私保护旨在保护数据中的隐私部分,避免个人的隐私信息(如年龄、性别、地址等)在收集和模型推理的过程中被泄露。相比于等级 1,数据隐私保护保持了一定程度的数据可用性,但仍然是很强的数据保护层级。
-
等级 3. 数据可溯源(Data Traceability):数据可溯源指的是当数据被用于 AI 模型开发和应用时,能提供追溯数据来源、数据使用记录和数据修改的能力,这种能力使得监管者或数据所有者能够审计 AI 应用中数据的使用,从而避免数据被不当使用。实现数据可溯源通常只需要对数据进行微小的修改甚至不修改,因此能够很好地保持数据的可用性。
-
等级 4. 数据可删除(Data Deletability):数据可删除指的是在 AI 应用中完全删除一个数据或其影响的能力,这也是许多数据保护法律法规(如欧盟 GDPR)中规定的「可遗忘权」。数据可删除使得开发者可以在数据不被需要或者被撤回许可的场景下以较低的开销消除影响,数据可删除为 AI 应用开发者提供了完整的数据可用性,但仅在数据使用的阶段提供了较弱的数据保护。
现实意义与未来挑战
本文提出的数据保护体系对理解现有技术和进一步推动当前的全球法规和应对未来的挑战,也提供了极具价值的新兴视角。
分析现有数据保护技术的设计理念:本文也介绍了针对上述四个保护级别的一系列设计理念和相应的代表性技术,为现有方法的应用和后续方法的设计提供了统一的视角和框架。
审视全球法规与治理:本文列举了当前全球代表性国家和地区关于数据保护的法律法规,用分级模型的新 “标尺” 审视现有的治理方案,分析了不同地区治理的特点、偏好和不足。
数据保护的进一步探讨和前沿挑战:除了审视当前的治理态势,本文进一步讨论了数据保护的跨学科意义和指出了一些数据保护的前沿挑战。
-
数据保护 vs. 数据安全:数据安全旨在保护数据的内容,避免潜在的有害、有偏见的内容。在 AI 时代,数据安全与数据保护更加紧密相连,一个保护上的漏洞可能引发严重的安全问题,反之亦然。
-
AI 合成内容(AIGC)带来的新挑战:AI 合成内容的兴起带来了全新的治理难题,例如,许多国家和地区都因缺乏人类创作要素而拒绝授予 AI 合成内容版权,这就导致了 AI 合成内容的使用和监管存在灰色地带。与将 AIGC 单纯视为内容本身不同,本文的以模型为中心的数据保护视角突显了更多复杂性。当 AIGC 本身被用作数据,例如用于训练新模型的合成数据、知识蒸馏,或作为检索增强生成系统的输入时,其版权状态变得更加复杂。用于训练生成模型的原始数据的版权(或缺乏版权)是否会影响合成数据的版权状态?如果模型从受版权保护的数据中提炼知识,那么生成的训练模型(作为这些数据中所含信息的紧凑表示)或其生成的数据是否会继承相关限制?这些争议触及数据版权的核心定义:数据版权是否仅与数据内容的「直接表达」相关,还是可以进一步延伸至模型隐含捕获并可转移的统计模式、风格和知识?人工智能模型(尤其是生成式模型)将受版权保护的信息「洗白」成看似新颖且不受保护的 AIGC 内容的潜在风险,也是是一个目前值得关注的重要问题。
-
跨国数据治理难题:AI 的产业链和系统本质是全球化的 —— 收集自一个国家的数据,可能会在另一个国家进行处理和标注,最后向全世界提供服务,这种跨国性的数据流动和各国标准不一的数据保护法规形成了尖锐冲突,从而可能会对全球化的开发者造成巨大的合规挑战。
-
数据保护的伦理考量:AI 时代的所有数据保护都与基本的伦理考量相关联,例如,数据隐私保护和数据可删除体现的是个体对数据的自主权,数据可追溯则有助于降低偏见和提高公平性,而数据不可用是完全避免恶意利用数据的有效途径。在追求技术创新和数据效用的同时,如何平衡和维护这些核心伦理价值,是所有 AI 从业者都需要思考的命题。

©
(文:机器之心)