

这次,所有AI 全军覆没!

ARC Prize今天发布的ARC-AGI-3预览版,让所有前沿AI模型都吃了鸭蛋:人类轻松100%通关,而包括o3和Grok 4在内的最强AI模型,一关都过不了。
这次不是简单的版本升级,而是测试范式的彻底革命——从静态谜题直接跳到了交互式游戏环境。
交互式推理:AI的新考场
ARC-AGI-3引入了一个全新概念:交互式推理基准测试(Interactive Reasoning Benchmark,IRB)。
与传统静态测试不同,IRB要求AI系统具备五大核心能力:
-
探索(Exploration)
-
感知→计划→行动(Percept → Plan → Action)
-
记忆(Memory)
-
目标获取(Goal Acquisition)
-
对齐(Alignment)

ARC Prize指出:
「你适应新事物的效率定义了你的智能,而不是你在单一技能上的表现。」
更难的谜题并不能证明AI更聪明,但学习新规则的能力可以。
三个让AI崩溃的游戏
这次发布的预览版包含3个公开游戏(LS20、FT09、VC33),8月还将发布3个私有游戏。
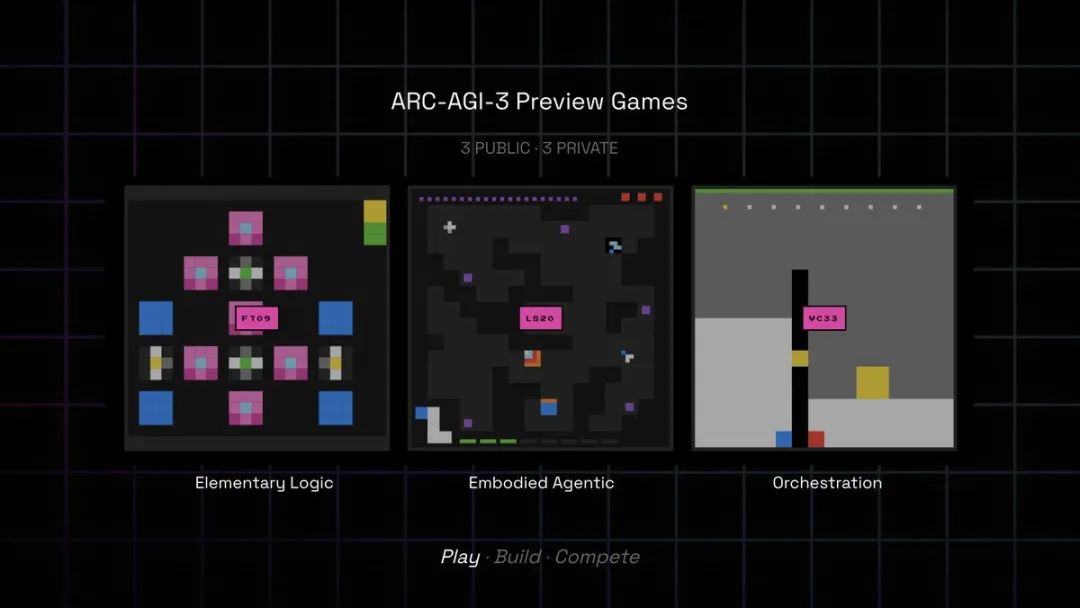
这些游戏的设计原则极其苛刻:
-
零说明书:AI必须自己发现控制方式、规则和目标
-
只需核心知识:不涉及语言、文化符号或专业知识
-
人类1分钟上手,5-10分钟通关
-
必须好玩:这是为了确保测试的有效性
就是这样看似简单的游戏,让最强大的AI模型们集体翻车。
团队展示了o3(上)和Grok 4(下)的游戏录像:
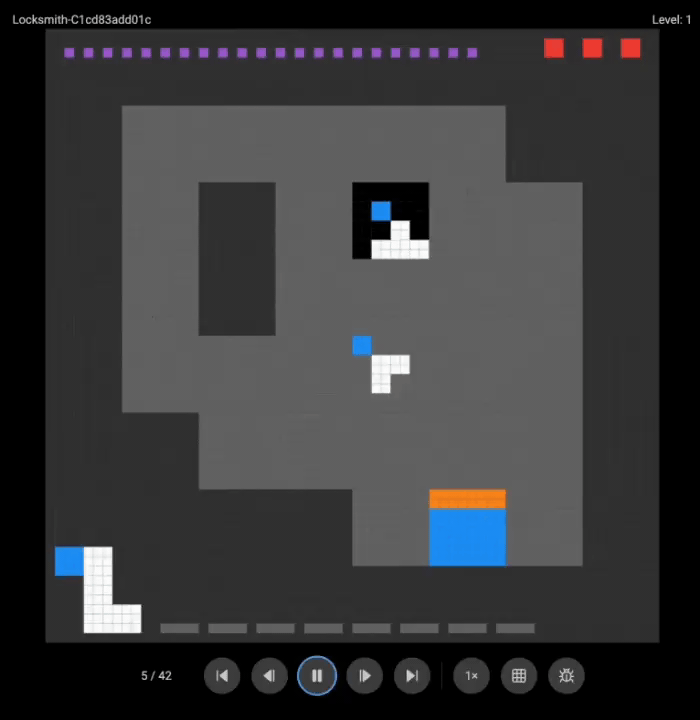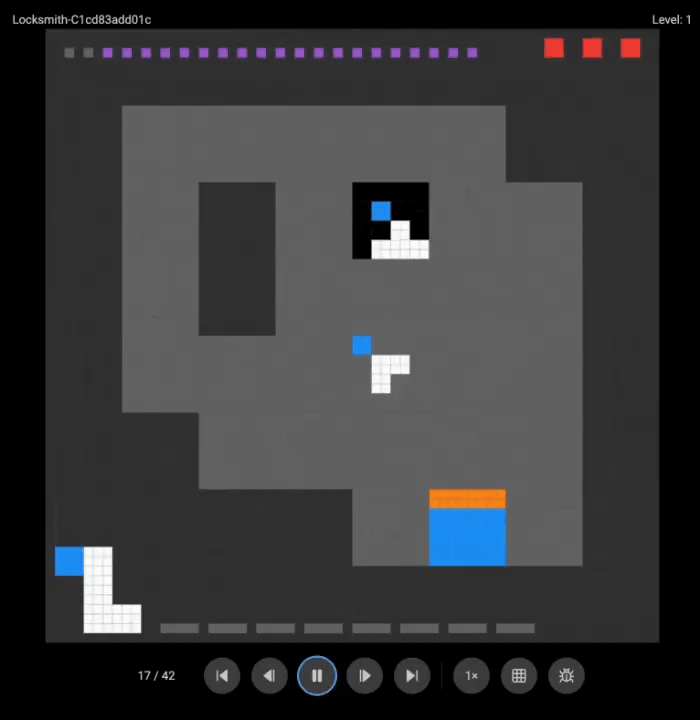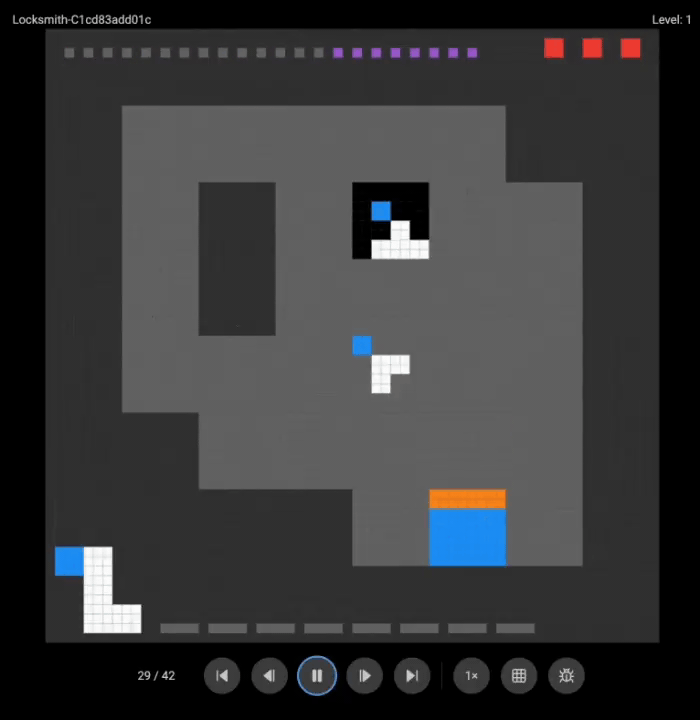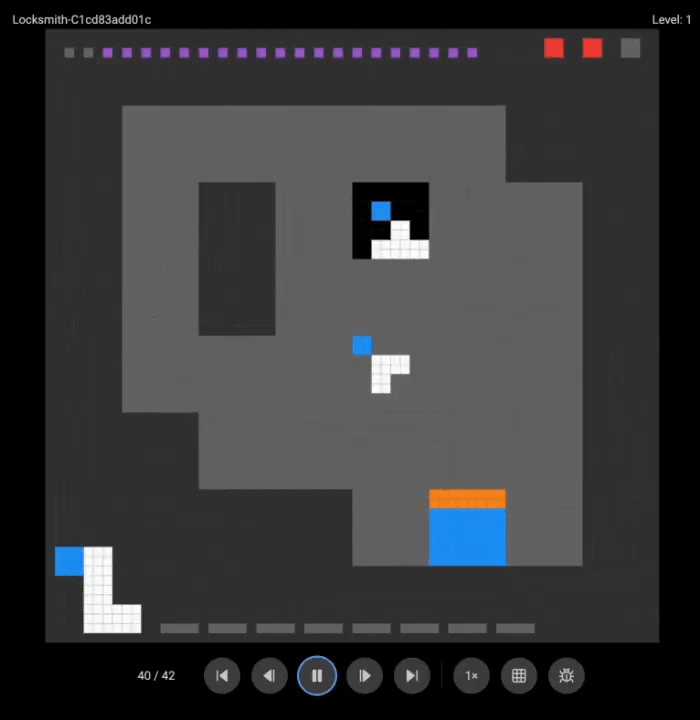
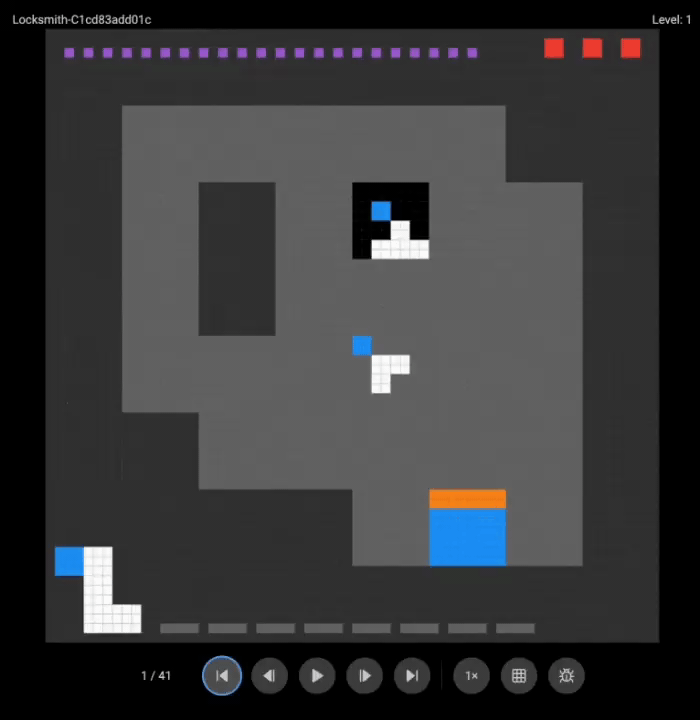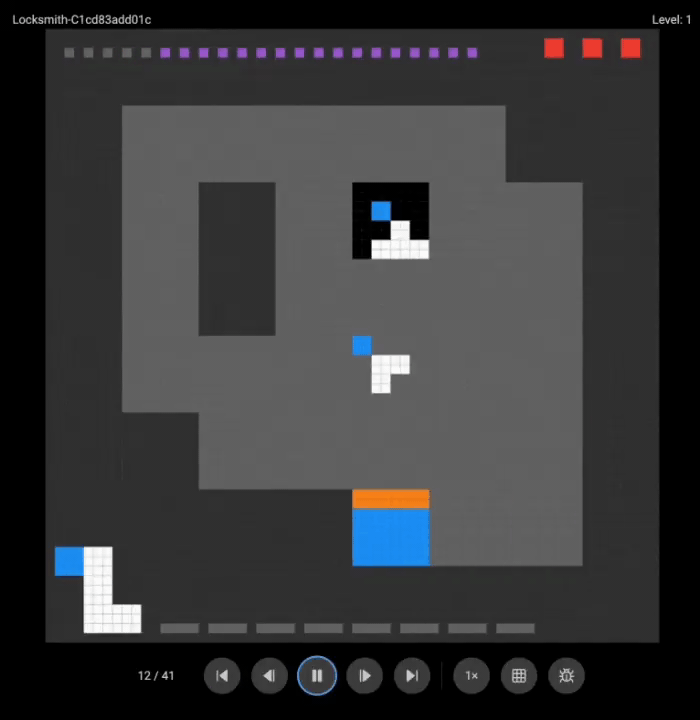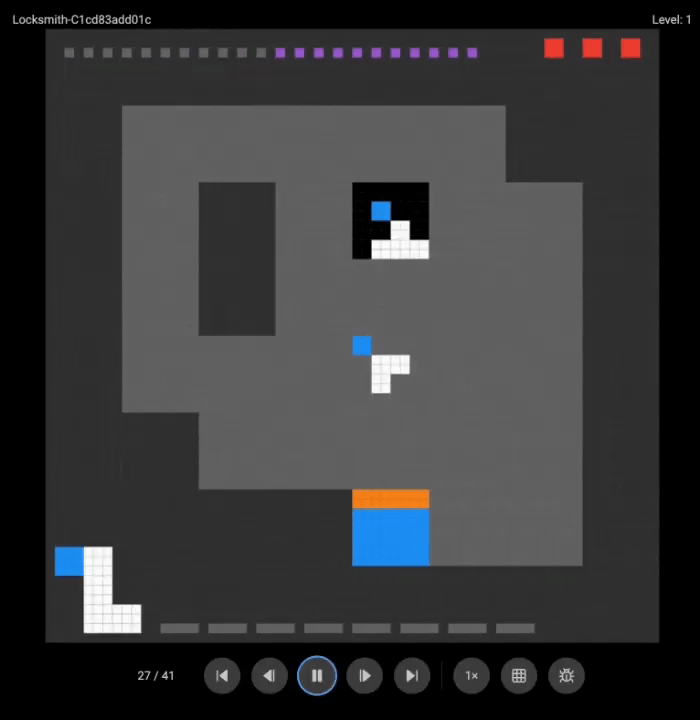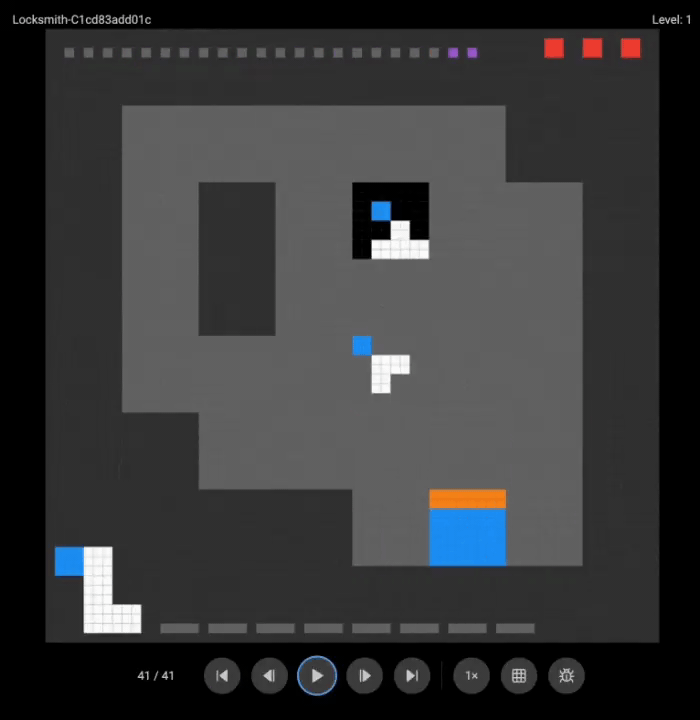
两个超强模型都没能完成任何一关。
这些在其他基准测试上大杀四方的模型,在需要实时探索和适应的任务面前,表现得像个初学者。
API发布
为了推动研究,ARC Prize 这次还同步发布了完整的API:
快速上手指南相当简洁:
# 1. 安装uv
curl -LsSf https://astral.sh/uv/install.sh | sh
# 2. 克隆仓库
git clone https://github.com/arcprize/ARC-AGI-3-Agents.git && cd ARC-AGI-3-Agents && uv sync
# 3. 设置环境变量
cp .env-example .env
# 4. 运行第一个智能体
uv run main.py --agent=random --game=ls20
研究者可以接入任何LLM、强化学习或混合智能体。API支持本地训练,然后连接服务器测试。
从1到3:不断移动的球门?
让我们回顾一下ARC系列的演进:
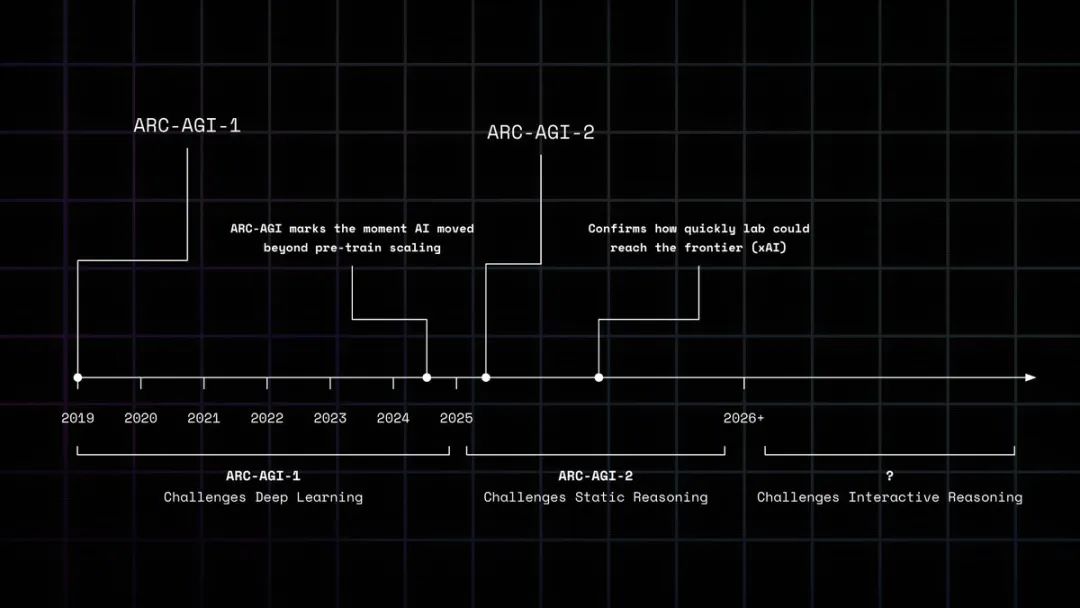
-
ARC-AGI-1(2019):挑战深度学习
-
ARC-AGI-2(2025):挑战静态推理模型
-
ARC-AGI-3(2025-2026):挑战交互式智能体
每次AI 接近突破时,新的测试就会出现。
这引发了社区的强烈质疑和吐槽。
Haider(@slow_developer)指出:
我们还没完成ARC-AGI-2的一半,现在就有ARC-3了。这个测试不是要告诉我们何时达到AGI吗?现在模型接近了,他们就不断制作新测试,移动球门柱。图灵测试通过了,ARC-AGI-1通过了,还是没有AGI。
Ouranos Capital(@ouranoscapital)则质问:
如果每次上一个基准被攻克就推出新的,那还叫什么AGI基准测试?
prosight(@thgisorp)试图解释:
看起来他们建立的是一系列测试,模型需要在所有测试上都达到人类水平才能称为AGI,而不是通过一个就算。
万元奖金……
竞赛奖金设置也成了槽点:

-
第一名:5000美元
-
第二名:2500美元
-
荣誉奖:若干500美元
Ken Navarro(@ken100bands)直接开喷:
1万美元太少了,你们疯了吧。token 都不够跑吧……
sacha(@sachaicb)更是犀利地指出:
第一个ARC奖金100万美元,第三个只有1万美元。看来ARC自己对LLM的规模化也变乐观了。
Zev Persellin(@ZPersellin)倒是看得开:
没人在乎钱。你给不出足够大的奖金。即使10亿也不够。
人类真的100分?
更尴尬的是,不少人类玩家表示自己也搞不定。
Sergey(@Sergey_lll)自我怀疑:
100%?我不确定自己还是不是人类。
Wesley Austen(@WesleyAusten)崩溃了:
我太笨了玩不了这游戏😭 我不相信人类通过率是100%。至少我们需要知道目标是什么😭
Ravikant Dewangan(@ronitkd)也承认:
别逗了,我连第一关都过不了😅!人类怎么可能100%通关?
Jonathan Whitaker(@johnowhitaker)则把游戏界面转成纯文本让人类玩,并吐槽:
人类普遍智能吗?你是人吗?试试新的ARC AGI 3游戏吧!我相信你能行;)
结果呢?
他报告说:
如果有人完成了游戏,请告诉我!在那之前,我要报告人类成功率为0%。别作弊哦😃
Homo futuris(@homo__futuris)也开始怀疑测试的合理性:
我完全不懂…我是亚人类吗?我有那么迟钝吗?100%的人类都能完成谜题?5年级的Mariana也能?还是说ARC AGI已经不知道该怎么为非生物智能发明不可能的谜题了?
体验问题和Bug满天飞
除了难度问题,技术问题也不少。
Ryan Morey(@RyanMorey)遇到了加载错误:
很棒!!但尝试加载我的回放时出现了fetch错误
Ankith(@dhtikna)抱怨:
UI在手机浏览器上不友好
Dshoopy(@Dshoopy0)更直接:
你们的网站坏了,游戏会随机卡住。
joshlee361(@joshlee361)提出建议:
说实话,我希望有个更简单的方式运行你们的测试,也许可以在数据集中包含一个小型求解器应用,这样用户可以更快、更便宜地在本地测试他们的AI设置?
Jonathan Whitaker还吐槽API文档:
API文档极其难以转换成AI可用的格式,都2025年了,大家应该有个.md文件包含所有内容,让人们可以喂给他们的代码猴子AI。
游戏设计哲学
chris j handel(@chris_j_handel)提出:
在这个你们用规则控制的道德竞赛中,如果把所有可能和可用的AI的最佳答案组合成一个与现实最兼容的故事,并在所有AI之间分享奖金,这算作弊吗?智能不是竞争,而是合作。
NatureAli(@AliTBD21)倒是比较乐观:
有趣的游戏!这对AI智能体来说将是一个具有挑战性但必要的下一步。
Mark(@MarkOkedoyin)提醒大家:
伙计们冷静点,他们连ARC AGI 1都还没打败呢。
Facu Fagalde(@facundo_fagalde)开玩笑说:
ARC-AGI 3会是最后一个吗?也许之后会有ARC-ASI 1🤣
不过,ARC-AGI-3的发布确实证明了一个事实:在需要实时探索和适应的任务上,今天最强大的AI 仍然像是个蹒跚学步的孩子。

但我想说的是,当我们急于想要证明AI 还不够聪明时,或许更应该反思:我们设计的测试,真的在测量「智能」吗?
还是只是在测量「像人类一样玩游戏的能力」?
或者,只是不愿意承AGI 早已经实现?
这背后的问题其实是:
什么是AGI?
ARC-AGI-3 主页: https://arcprize.org/arc-agi/3/
[2]ARC-AGI-3 游戏平台: https://three.arcprize.org/
[3]ARC-AGI-3 API文档: https://three.arcprize.org/docs
[4]ARC-AGI-3 排行榜: https://three.arcprize.org/leaderboard
[5]ARC-AGI-3 预览版智能体竞赛: https://arcprize.org/competitions/arc-agi-3-preview-agents/
[6]游戏创意提交表单: https://forms.gle/aVD4L4xRaJqJoZvE6
[7]ARC-AGI-3-Agents GitHub仓库: https://github.com/arcprize/ARC-AGI-3-Agents
[8]快速开始教程视频: https://www.youtube.com/watch?v=xEVg9dcJMkw
[9]ARC Prize Twitter: https://twitter.com/arcprize
[10]原始发布推文: https://twitter.com/arcprize/status/1946260363256996244
[11]Ryan Morey的VC33游戏回放: https://three.arcprize.org/replay/vc33-051d064efa38/58a2766e-9ca6-4263-9e10-e24c35159f45
(文:AGI Hunt)