
传统RAG靠OCR转录文档、Whisper转录音视频,速度慢、细节丢、情感失真。
如果有一个开源多模态RAG系统,支持文本查询音频、音频查询图像,直接处理音视频原始数据,保留语气/情感/视觉细节,30分钟音频10秒检索,会不会让你的多模态任务直接起飞?
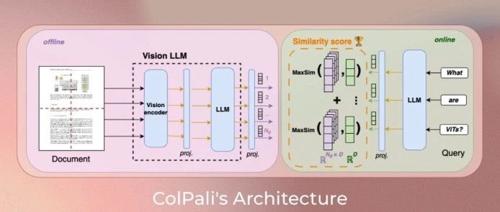
这就是 ColQwen-Omni 的魔法—Vidore开源的3B多模态检索增强生成(RAG)模型,基于ColQwen2和Qwen2-VL,ColQwen-Omni扩展视觉文档检索到音频/短视频,单次查询<100ms,音频检索10秒处理30分钟。
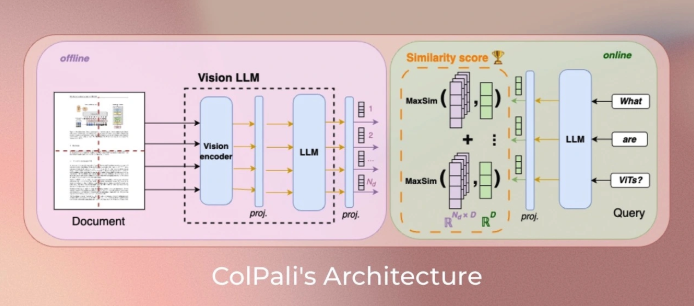
支持跨模态检索(文本查音频、音频查图像等),直接处理音视频原始数据,保留情感、语气和视觉细节。
核心亮点
ColQwen-Omni的魅力在于其五大特性,直击传统RAG痛点:
-
• 跨模态检索:文本查音频、音频查图像,统一向量空间。 -
• 音视频直处理:无需转录,保留语气/情感/环境音(如掌声)、视觉细节(如logo)。 -
• 超快检索:30分钟音频10秒处理,短视频<10秒/clip,查询<100ms。 -
• TMRoPE同步:时间对齐多模态嵌入,视频/音频帧精准对齐。 -
• 轻量高效:3B参数,Colab免费GPU可跑。
快速上手
ColQwen-Omni支持Colab免费GPU,适配Python 3.9+。
确保colpali-engine从源代码安装或使用高于 0.3.11 的版本安装。
pip install git+https://github.com/illuin-tech/colpali使用示例:
import torch
from PIL import Image
from transformers.utils.import_utils import is_flash_attn_2_available
from tqdm import tqdm
from torch.utils.data import DataLoader
from colpali_engine.models import ColQwen2_5Omni, ColQwen2_5OmniProcessor
model = ColQwen2_5Omni.from_pretrained(
"vidore/colqwen-omni-v0.1",
torch_dtype=torch.bfloat16,
device_map="cuda", # or "mps" if on Apple Silicon
attn_implementation="flash_attention_2" # if is_flash_attn_2_available() else None,
).eval()
processor = ColQwen2_5OmniProcessor.from_pretrained("vidore/colqwen-omni-v0.1")
dataset = load_dataset("eustlb/dailytalk-conversations-grouped", split="train[:500]")
audios = [x["array"] for x in dataset["audio"]]
dataloader = DataLoader(
dataset=audios,
batch_size=2,
shuffle=False,
collate_fn=lambda x: processor.process_audios(x),
)
ds = []
for batch_doc in tqdm(dataloader):
with torch.no_grad():
batch_doc = {k: v.to(model.device) for k, v in batch_doc.items()}
embeddings_doc = model(**batch_doc)
ds.extend(list(torch.unbind(embeddings_doc.to("cpu"))))
def get_results(query: str, k=10):
batch_queries = processor.process_queries([query]).to(model.device)
# Forward pass
with torch.no_grad():
query_embeddings = model(**batch_queries)
scores = processor.score_multi_vector(query_embeddings, ds)
# get top-5 scores
return scores[0].topk(k).indices.tolist()
res = get_results("A person looking for a taxi")
# In colab
display(Audio(dataset[res[0]]["audio"]["array"], autoplay=True, rate=dataset[res[0]]["audio"]["sampling_rate"]))适用场景
ColQwen-Omni的跨模态和直处理特性让它适用于多种场景:
-
• 音视频检索:文本查TED演讲、音频查YouTube封面,保留情感/细节。 -
• 文档问答:PDF/图像问答,无需OCR,布局/图表全解析。 -
• 教育研究:检索课程视频/讲义,跨模态分析。 -
• 娱乐分析:短视频/播客内容搜索,情感/环境音保留。 -
• 隐私敏感:Colab本地运行,数据不上传。
写在最后
ColQwen-Omni,它能让我们直接用文本搜索视频/音频/文档中的内容,实现更自然、更快、更强大的知识检索体验。
它让“视频音频就是知识”的愿景更进一步,是构建多模态智能应用的超级引擎。
可以在AI助手、多模态知识库、视频内容分析、跨模态检索系统、AI教育工具等方面发挥出它应用的价值。
GitHub 项目地址:https://github.com/illuin-tech/colpali
模型地址:https://huggingface.co/vidore/colqwen-omni-v0.1

(文:开源星探)