


作者:董兆华
编辑:椰椰,李宝珠
在 HyperAI超神经主办的第 7 期 Meet AI Compiler 技术沙龙活动上,沐曦集成电路的高级总监董兆华,围绕如何在沐曦 GPU 上应用 TVM 进行了深度分享。
7 月 5 日,由 HyperAI超神经主办的 Meet AI Compiler 技术沙龙第 7 期圆满落幕。从 GPU 架构的底层创新,到跨硬件编译生态的顶层设计;从单芯片算子优化,到多节点分布式编译的突破……来自 AI 编译领域的从业者、学者们共同汇聚了这场顶尖的技术盛宴,活动现场座无虚席,交流氛围浓烈。
关注微信公众号「HyperAI超神经」,后台回复关键字「0705 AI 编译器」,即可获取确认授权的讲师演讲 PPT。
活动上,来自 AMD 的张宁架构师为我们深度剖析了 Triton 编译器在 AMD GPU 平台的性能优化秘籍,揭秘如何让 Python 代码轻松驾驭高性能 GPU Kernel;沐曦集成电路的董兆华总监带来了国产 GPU 上 TVM 应用的实战经验,展现自主芯片与开源编译框架碰撞出的火花;字节跳动的郑思泽研究员揭开了 Triton-distributed 的神秘面纱,分享了 Python 如何颠覆分布式通信的性能天花板;北京大学王磊博士带来的 TileLang,更是重新定义算子开发的效率边界。
✦
•
✦




✦
左右滑动,查看更多
✦
在「沐曦 GPU 上的 TVM 应用实践」主题演讲中,来自沐曦集成电路的高级总监董兆华介绍了其 GPU 产品的技术特性、TVM 编译器适配方案、实际应用案例及生态建设愿景,展现了国产 GPU 在高性能计算与 AI 领域的技术突破与应用潜力。
HyperAI超神经在不违原意的前提下,对董兆华老师的演讲分享进行了整理汇总,以下为演讲实录。
沐曦 GPU 介绍
沐曦 GPU 当前包含了 N 系列、C 系列、G 系列等多个产品线,覆盖从 AI 训练推理到科学计算的多元化场景,通过构建多层次软件栈,实现与主流框架的无缝对接。编译器作为核心工具链,负责将上层应用的 API 调用及未编译的机器码并交付给 GPU 并执行。经工程师的精准调整,其性能已达到国际先进水平,且与业界主流计算库形成对应适配关系。
沐曦 GPU 具备丰富的指令级函数接口,我们自研的 MACA C 接口基于 C 语言扩展而来,集成了特定领域的语法元素,与主流厂商的底层编程接口具有功能对等性,开发者可快速完成迁移适配。同时提供 Python、Triton、Fortran 等多样化编程接口,支持 OpenACC、OpenCL 等并行编程标准,在自动并行化代码生成等方面效率优异。
此外,沐曦 GPU 采用 GPGPU(通用图形处理器)架构,基于 LLVM 的编译系统,支持从高层语言到底层机器码的全流程优化,兼顾开发效率与硬件性能,并且提供高性能的软件栈。
沐曦 GPU 上的 TVM 适配
TVM 作为开源的深度学习编译器,能够将深度学习模型转换为可在不同硬件上高效运行的代码,沐曦团队针对自家 GPU 特性,构建了完整的 TVM 适配方案,实现从模型定义到硬件执行的全流程优化。
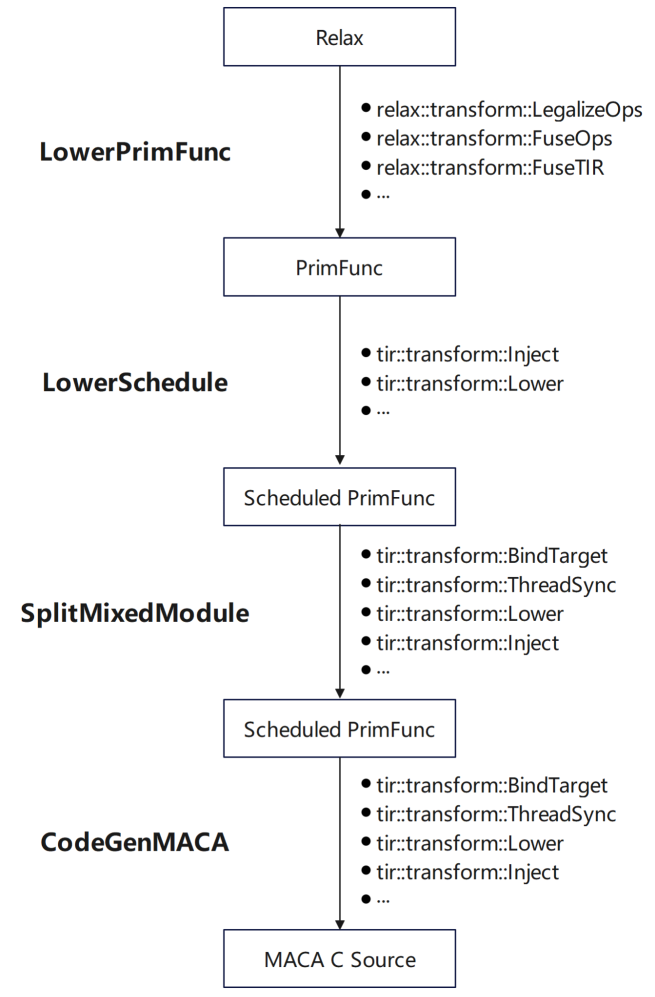
从编译器架构来看,目前已实现完整支持,且理论上可对接四个核心层级。
针对 C++ 接口的适配,我们想将其转换为麻烦的语言求解,这一过程难度较高,工具化自动转换的实现存在一定挑战。
若代码抽象度较高,则更易实现跨层级适配。此外,在对接 LLVM 时,需注意版本兼容性问题——因 LLVM 版本众多,特定版本的适配需依赖对应版本的支持,版本不匹配可能导致编译流程异常。
在 GPU 上沐曦 Arch 适配方面:
tvm.Target 增加 MACA Target 并添加各阶段的支持:首先在 transform/lower 中增加 MACA Target 的 pipeline,复用通用 GPU 流程;然后在 tuning 阶段增加 MACA Target 的调度规则等;最后在 CodeGenMACA 及编译 MACAC 代码构建支持。
此外,在 tvm.Device 增加 MACA Device 以及 MACA Runtime API 的使用,包含了在 MACA Device 上的内存操作,以及运行期的 kernel launch。
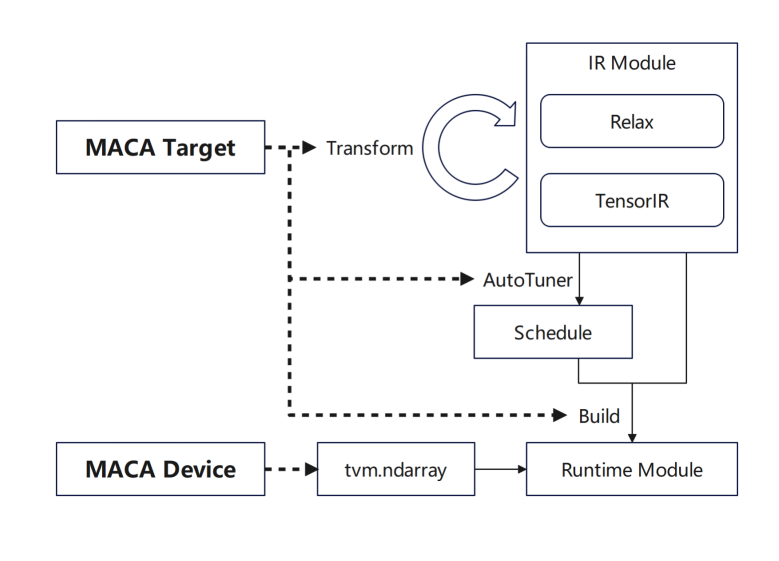
GPU 上沐曦 Arch 适配流程
现在我们的多款产品均已在 TVM 层面支持 subdevice,backend 根据 subdevice 进行不同产品的优化动作。具体而言,在不同产品中,编译器会依据设备类型差异,自动选择对应的适配方案;同时在批量编译场景中,正尝试对不同架构进行固定化的选择配置。在通用编译阶段,编译器会根据具体配置,针对不同架构动态调整功能相关的编译规则。
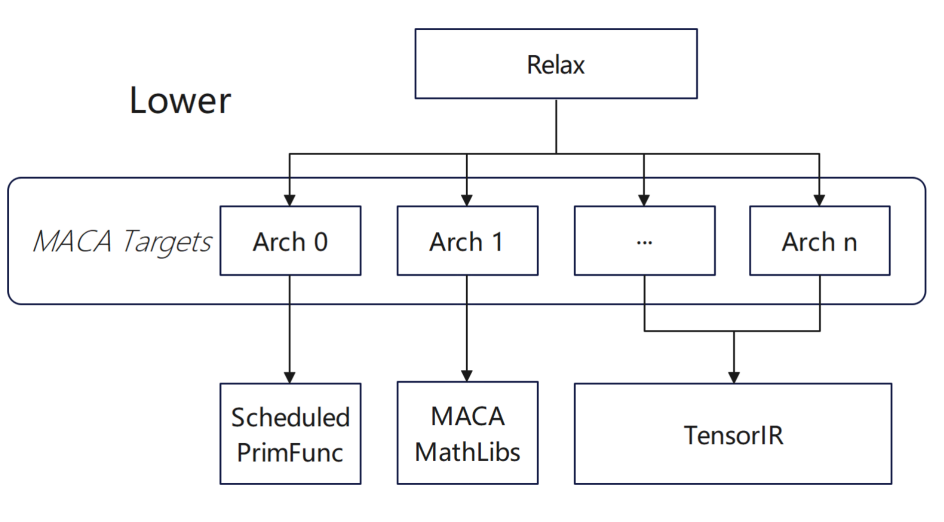
Lower 阶段根据不同 arch 选择不同算子实现
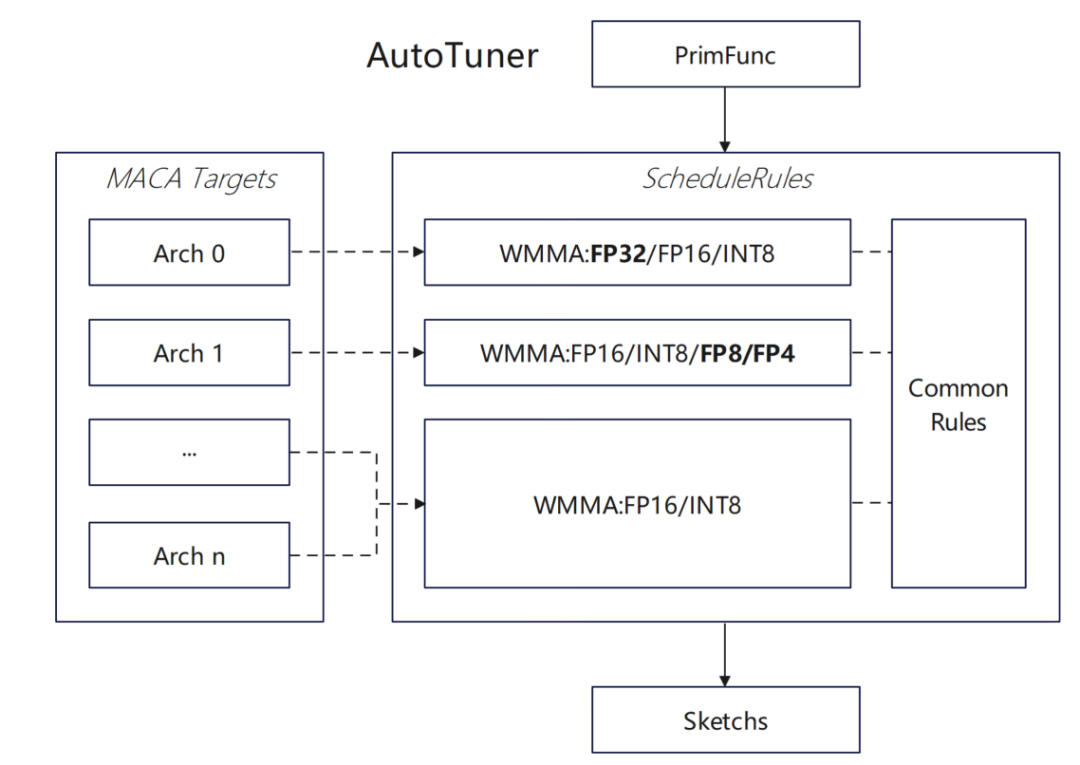
Tuning 阶段根据不同 arch 选择不同调度规则
在算子适配方面,我们做了上层配置,主要包括:
算子适配工作流
在适配过程中,为了达到较好性能,我们根据其特性进行了特殊处理:
对于我们来讲,vendor 定制优化算子更倾向于通过 Python 和 MACA C 两种方式:
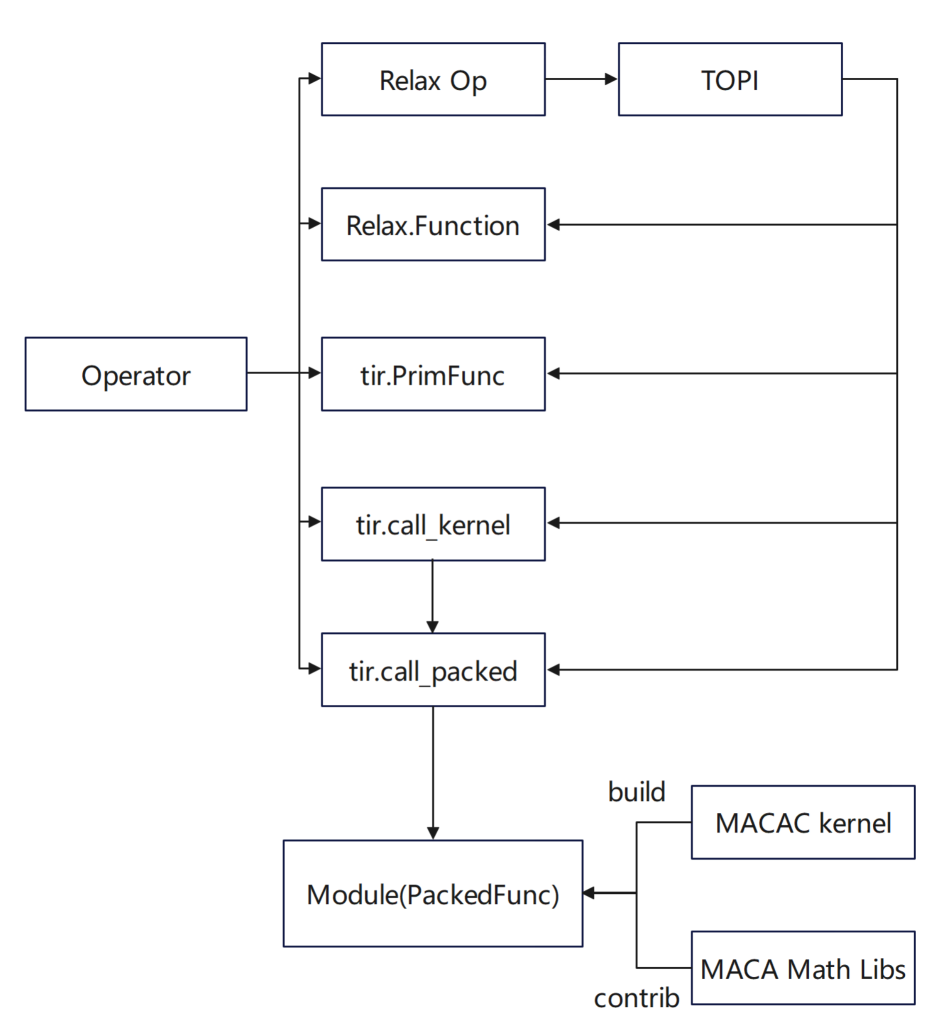
此外,为充分发挥沐曦 GPU 硬件特性,团队对 TVM 调度算法进行了深度优化:
* 为 MACA target 增加 WMMA float32 类型的支持:
首先在 MACA 中支持 float32 类型的 wmma api,在 MACA ScheduleRules 中增加 float32 类型的auto tensorize 规则,使 TVM 能自动识别并利用硬件的 WMMA ,同时在 dlight 优化框架中增加对应 float32 的 tensorize 优化,提升矩阵运算效率。
* 评估异步拷贝对调度算法的影响:
将多次 wmma 计算从加载一组计算一组的模式优化为异步加载下一组数据同步计算当前一组数据的模式,提高流水线效率,并且在 MACA ScheduleRules 中启用 software pipeline 的优化逻辑,为 MACA target 增加异步拷贝指令的注入和代码生成
新的 datatype 的支持上,我们也做了一些尝试:在 DataType 系统中启用 MACA target 适配;在 MACA ScheduleRules 中支持 Float8 类型的 auto tensorize 逻辑,扩展 TVM 对 Float8 等自定义数据类型的支持;在CodeGenMACA 中实现支持 Float8 类型转换与运算代码生成,并在 maca_half_t.h 中补充相关操作定义。
沐曦 GPU 上的 TVM 应用
在框架设计方面,团队实现了两种接入方式:一是在 Relay 前端直接导入 torch 模型并执行,二是使用 torch.compile 将 TVM 作为 backend 使用。通过这两种方式,实现了上层框架与底层硬件的高效衔接。
性能评估环节,我选取 resenet50 和 bert 作为基准测试模型,在未进行深度优化的情况下对比了 torch 与 TVM编译执行的性能表现。实验数据表明,TVM 在一些方面具有显著优势,部分场景下性能超越 torch。这得益于 TVM 中间表示(IR)的灵活性及其对硬件特性的针对性优化。
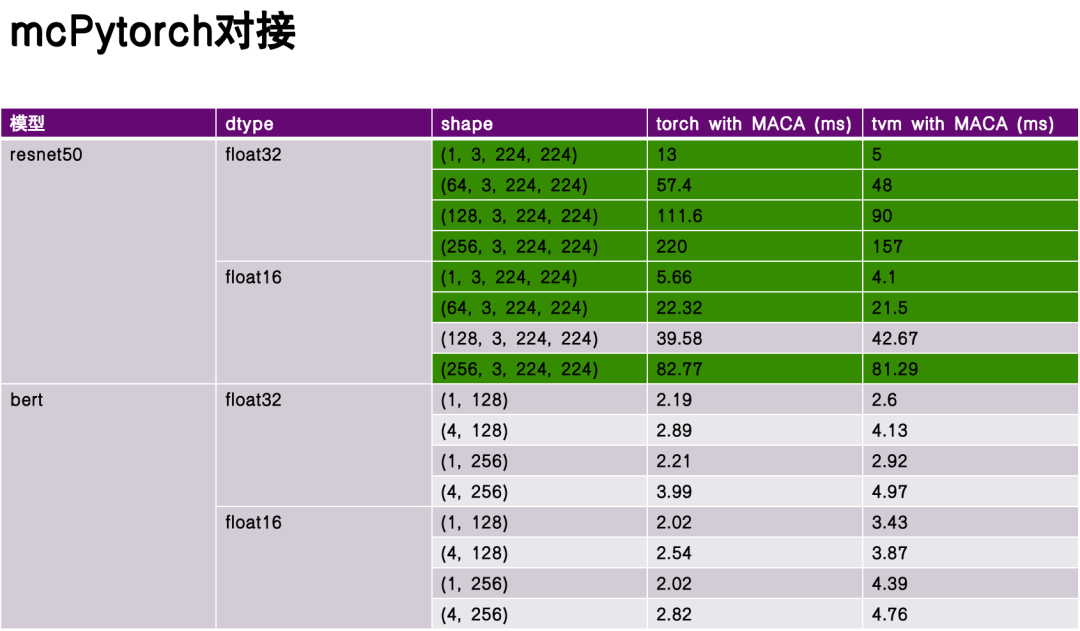
resenet50 和 bert 模型对比图
TileLang 作为 TVM 生态中的领域特定语言(DSL),专注于张量计算的精细化优化,我们团队在以下几方面进行了深度功能适配:
在优化点上,主要围绕在 tl_template 中 gemm 实现和适配沐曦 GPU 特性的算法实现两方面开展。
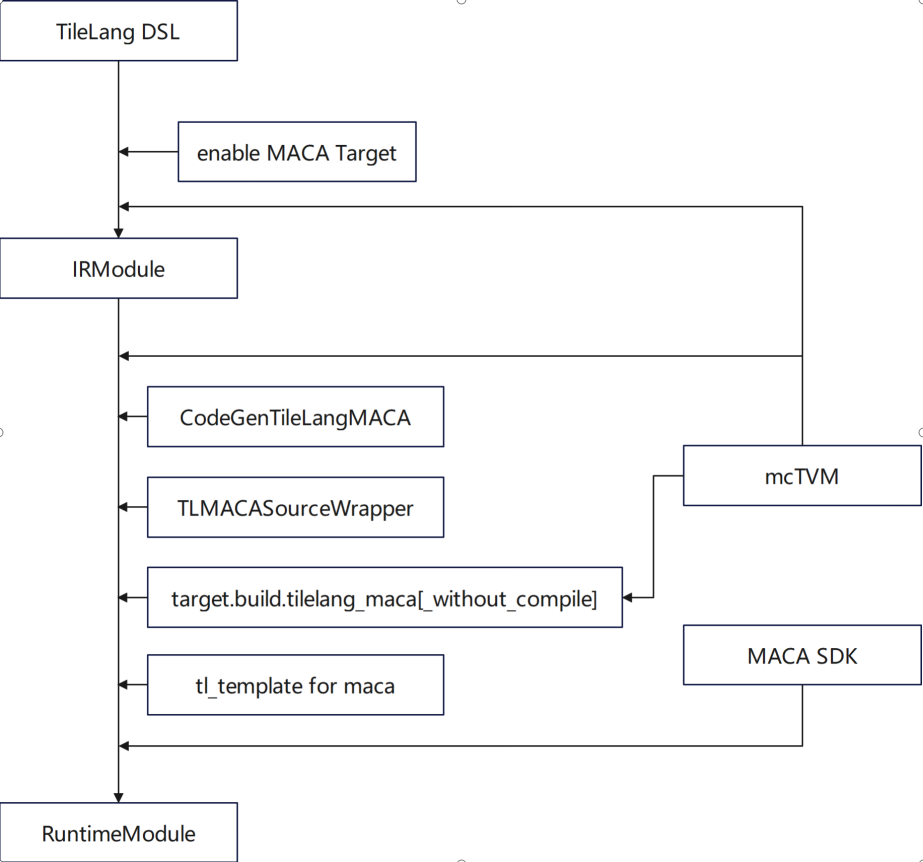
流程架构图
在 Vendor 跟社区的互动方面,TileLang 的设计与发展需平衡三大原则:
在语言设计层面,首要解决的是抽象性与高性能的平衡问题。具体而言,当面临多计算单元时,编译器应提供灵活的策略选择机制——既允许对底层硬件特性有深入了解的开发者指定具体的代码生成路径,也支持普通开发者通过抽象接口实现高效编程,无需关注底层细节。这种平衡是 TileLang 作为 DSL 在设计阶段需重点考量的核心要素。
其次,需考虑 Vendor 的定制化配置和 DSL 的标准化。编译器应支持多层次的优化选项配置,例如允许高级用户(advanced users)通过参数调整循环展开层次、继承性压力等底层编译策略,从而获得更优的代码生成效果。同时,针对不同硬件架构,编译器需提供针对性的优化提示与标注机制,辅助开发者根据硬件特性选择最优编译路径,提升开发效率。
第三,必须保证代际产品的接口延续性。在编译器与语言工具链的迭代过程中,应确保接口设计的向后兼容性——当前版本的编译逻辑与生成代码,在下一代硬件产品中仍能有效运行,避免因架构迭代导致的代码重构成本。这种延续性是生态建设的基础,能够实现编译器工具链功能的「加法式」积累,而非因不兼容导致的「减法式」损耗,同时可减少用户的学习与迁移成本,避免使用困惑。
挑战和机会
最后我谈一下当前行业发展面临挑战和机会。挑战主要体现在以下几个方面:
首先是框架和基于应用的算法变化快。随着深度学习等领域的快速发展,上层框架与算法更新周期不断缩短,功能和性能的拉升对编译器适配带来压力——编译器社区需要建立高效的适配机制,以快速响应新算子、新计算模式的支持需求。
其次是硬件架构持续演进中。现在编译器能够支持包容部分 GPU 架构的特性,如果未来出现新的硬件架构特性,编译器也需具备对异构硬件特性的包容能力。
第三是编程范式持续演进中。从传统的 C/C++ 到如今兴起的函数式编程、异构编程模型,如何定义其中与 Python 相关的生态链条是一大挑战。
最后是精度、性能与功耗的平衡。在实际应用中,编译器不仅需要关注代码性能,硬件功耗也同等重要。这些因素与后面的指令选择、架构设计都有关联。
未来,我们想和社区做一些共建:
在开源策略上,计划开放框架及算子库核心组件,包括 Flash、MLA 等关键计算模块。通过开源模式促进编译器工具链的迭代优化,形成生态规模效应。
其次,我们希望行业内的应用、框架、算子库、编译器和硬件架构有更密切合作机会。通过定期技术交流(如行业论坛),聚焦编译优化难点、算子调度策略等核心问题,推动跨领域合作,挖掘技术创新点。
沐曦还注重生态共建,建设举措包括:搭建技术社区论坛,接收开发者对编译器工具链的需求反馈与问题报告;举办算子和框架的主题竞赛;提供 Benchmark,以及跟社区共建领域特定的 Test Suite 和 Benchmark。



戳“阅读原文”,免费获取海量数据集资源!
(文:HyperAI超神经)