


新智元报道
新智元报道
【新智元导读】PresentAgent可以把论文、报告等长文档一键变成带真人语音和同步幻灯片的演示视频,流程像人写提纲、做PPT、录音并合成。实验使用30份文档与人工视频对比测试,PresentAgent在内容准确、视觉清晰和观众理解上都接近人类水准,可帮老师、商务人士省去大量做PPT和录音的时间。
演示是一种广泛使用且行之有效的信息传达方式。通过结合视觉元素、结构化的讲解和口头解释,它能够使信息逐步展开,从而让不同受众更容易理解。
尽管效果显著,但将长篇文档(如商业报告、技术手册、政策简报或学术论文)制作成高质量演示视频通常需要耗费大量人工精力。
这个过程涉及内容筛选、幻灯片设计、讲稿撰写、语音录制,以及将所有内容整合成一个连贯的多模态输出。
尽管近年来AI在文档转幻灯片和文本转视频等领域取得进展,但仍存在一个关键问题:这些方法要么只能生成静态的视觉摘要,要么仅能输出无结构的通用视频片段,难以胜任需要结构化讲述的演示任务。
为弥补这一空白,澳大利亚人工智能研究所、英国利物浦大学的研究人员提出了一个新任务:文档到演示视频生成(Document-to-Presentation Video Generation),旨在自动将结构化或非结构化文档转化为配有语音讲解和同步幻灯片的视频演示。

论文链接:https://arxiv.org/pdf/2507.04036
代码链接:https://github.com/AIGeeksGroup/PresentAgent
该任务的挑战远超传统的摘要或文本转语音系统,因为它需要选择性内容抽象、基于布局的视觉规划,以及视觉与语音的精确多模态对齐。
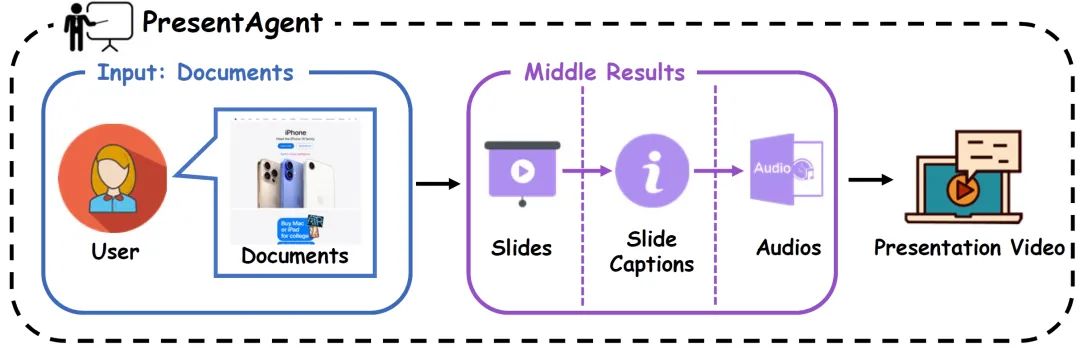
图1:PresentAgent 概览。 该系统以文档(如网页)为输入,经过以下生成流程:(1)文档处理、(2)结构化幻灯片生成、(3)同步字幕创建,以及(4)语音合成。最终输出为一个结合幻灯片和同步讲解的演示视频。图中紫色高亮部分表示生成过程中的关键中间输出
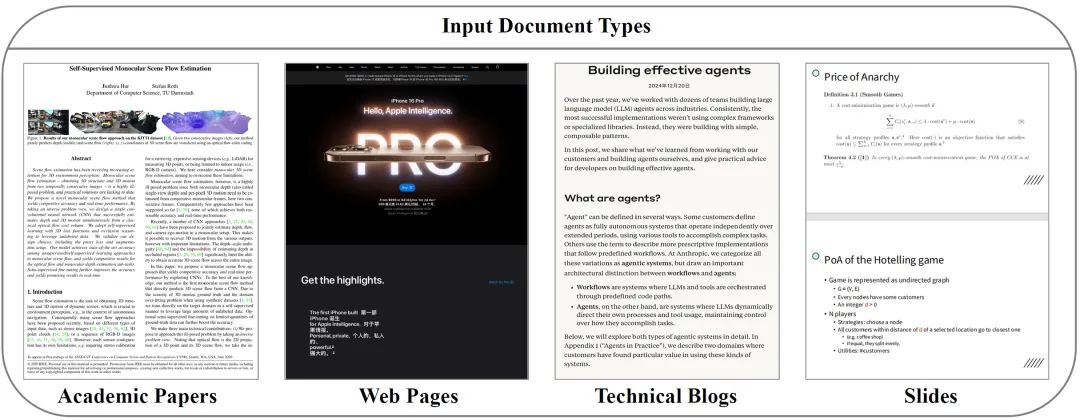
图2:评估基准中的文档多样性
与以往只关注静态幻灯片/图像生成或单一语音摘要的方法不同,研究人员的目标是构建一个完整集成的视频体验,模拟现实中人类演讲者的信息传递方式。
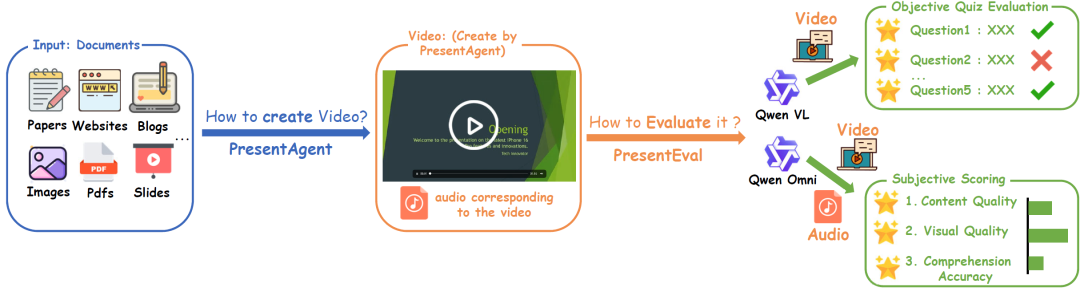
图3:方法框架概览
上图左侧给定多样的输入文档(如论文、网站、博客、幻灯片或 PDF),PresentAgent 能生成带讲解的演示视频,输出为同步的幻灯片和音频。
右侧设计了PresentEval,一个双路径的评估框架:
(1)客观测验评估(上),通过 Qwen-VL 进行事实理解检测;
(2)主观打分评估(下),借助视觉-语言模型从内容质量、视觉设计与语音理解等维度进行评分。
为应对上述挑战,研究人员提出了一个模块化生成框架——PresentAgent,如图1所示。
其流程包括:
-
将输入文档语义分块(通过大纲规划);
-
为每个语义块生成具有布局指导的幻灯片视觉内容;
-
将关键信息重写为口语化解说文本;
-
语音合成后,与幻灯片进行时间同步,最终生成一个结构良好、讲解清晰的视频演示。
值得一提的是,整个流程具有可控性和领域适应性,适用于多种文档类型和演示风格。
为有效评估此类复杂多模态系统,研究人员整理了一个涵盖教育、金融、政策与科研等多个领域的30组人工制作的文档-演示视频对的测试集。
同时,研究人员设计了一个双路径评估策略:
-
一方面使用固定选择题测试内容理解;
-
另一方面通过视觉语言模型打分,评估视频的内容质量、视觉呈现与观众理解程度。
实验结果表明,该方法生成的视频流畅、结构合理、信息充分,在内容传达和观众理解方面接近人类表现。
这表明将语言模型、视觉布局生成与多模态合成结合,能够实现可解释、可扩展的自动演示生成系统。
主要贡献如下:
-
提出新任务:首次提出“文档到演示视频生成”这一新任务,旨在从各类长文本自动生成结构化的幻灯片视频,并配有语音解说。
-
设计PresentAgent系统:提出一个模块化生成框架,涵盖文档解析、布局感知幻灯片构建、讲稿生成及音视同步,实现可控、可解释的视频生成过程。
-
提出PresentEval评估框架:构建一个由视觉语言模型驱动的多维度评估机制,从内容、视觉与理解等维度对视频进行提示式评分。
-
构建高质量评测数据集:制作了一个包含30对真实文档与对应演示视频的数据集。实验和消融研究显示,PresentAgent不仅接近人类表现,且显著优于现有方案。

该基准不仅评估视频的流畅性与信息准确性,还支持对观众理解程度的评估。
借鉴Paper2Poster的方法,研究人员设计了一个测验式评估,即通过视觉语言模型仅根据生成视频(幻灯片+讲解)回答内容问题,以模拟观众的理解水平。
研究人员还引入人工制作的视频作为参考标准,既用于评分校准,也作为性能上限对比。
如图2所示,基准涵盖四种代表性文档类型(学术论文、网页、技术博客和幻灯片),均配有真实人工讲解视频,覆盖教育、科研、商业报告等多种真实领域。

客观测验评估中的提示样例,每组选择题均基于源文档真实内容手动设计,重点考查主题识别、结构理解与核心观点提取能力,用于评估生成视频是否有效传达原始信息。

主观评分提示示例,其中每项提示关注一个特定维度,旨在指导视觉语言模型以“人类视角”对视频进行评分。缩写说明:Narr. Coh. = 讲解连贯性;Comp. Diff. = 理解难度。

研究人员采用一个「统一的模型驱动评估框架」来对生成的演示视频进行评分,所有评估均使用视觉语言模型,结合针对不同维度设计的提示进行引导。
该评估框架由两部分组成:
-
客观测验评估:通过选择题测量视频传递信息的准确性;
-
主观评分评估:从内容质量、视觉/音频设计与理解清晰度等维度,对视频进 1–5分等级评分。
这两类指标共同构成了对生成视频的全面质量评估体系。
为了支持文档到演示视频生成的评估,研究人员构建了一个多领域、多文体的真实对照数据集——Doc2Present Benchmark,其中每对数据都包含一个文档与一个配套的演示视频。
不同于以往只关注摘要或幻灯片的基准,数据包括商业报告、产品手册、政策简报、教程类文档等,每篇文档均配有人工制作的视频讲解。
数据来源
研究人员从公开平台、教育资源库和专业演示存档中收集了30个高质量演示视频样本,每个视频都具有清晰结构,结合了幻灯片视觉呈现和同步语音讲解。
研究人员手动对齐每个视频与其源文档,并确保视频结构与文档内容一致、幻灯片视觉信息紧凑且结构化、讲解与幻灯片在时间上良好同步。
数据统计信息
文档长度:约3000–8000字
-
视频长度:1–2分钟
-
幻灯片数量:5–10页
这一设置强调了任务的核心挑战:如何将密集、领域专属的文档内容转化为简明易懂的多模态演示内容。
为了评估生成的演示视频的质量,研究人员采用了两种互补的评估策略:客观选择题评估(Objective Quiz Evaluation)和主观评分(Subjective Scoring),如图3所示。
对于每个视频,将幻灯片图像和完整的讲解文本作为统一输入提供给视觉-语言模型,模拟真实观众的观看体验。
在客观评估中,模型需回答一组固定的事实性问题,以判断视频是否准确传达了原始文档中的关键信息。
在主观评分中,模型从三个维度对视频进行打分:讲解的连贯性、视觉设计的清晰度与美观性,以及整体的易理解程度。所有评估都不依赖真实参考,而完全依靠模型对呈现内容的理解。
为了评估生成的视频是否有效传达了原始文档的核心内容,采用固定问题的理解评估协议。
研究人员为每个文档手动设计五道多项选择题,侧重于主题识别、结构理解和论点提取等方面。
如表1所示,评估时,视觉-语言模型接收包含幻灯片和音频转录的完整视频,并回答五个问题。
每题有四个选项,仅有一个正确答案,正确答案基于人工制作的视频标注,最终理解得分(范围0-5)反映模型答对了几题,衡量视频传达原始信息的能力。
为评估生成视频的质量,研究人员采用基于提示的视觉-语言模型评估方式,不同于依赖人工参考或固定指标的方法,要求模型从观众视角出发,用自身推理与偏好打分。
评分关注三个方面:讲解连贯性、幻灯片视觉效果以及整体理解难度。
模型观看视频与音频内容后,分别为每个维度打分(1–5分)并简要解释。具体评分提示见表2,针对不同模态和任务设计了不同的提示语,以实现精准评估。
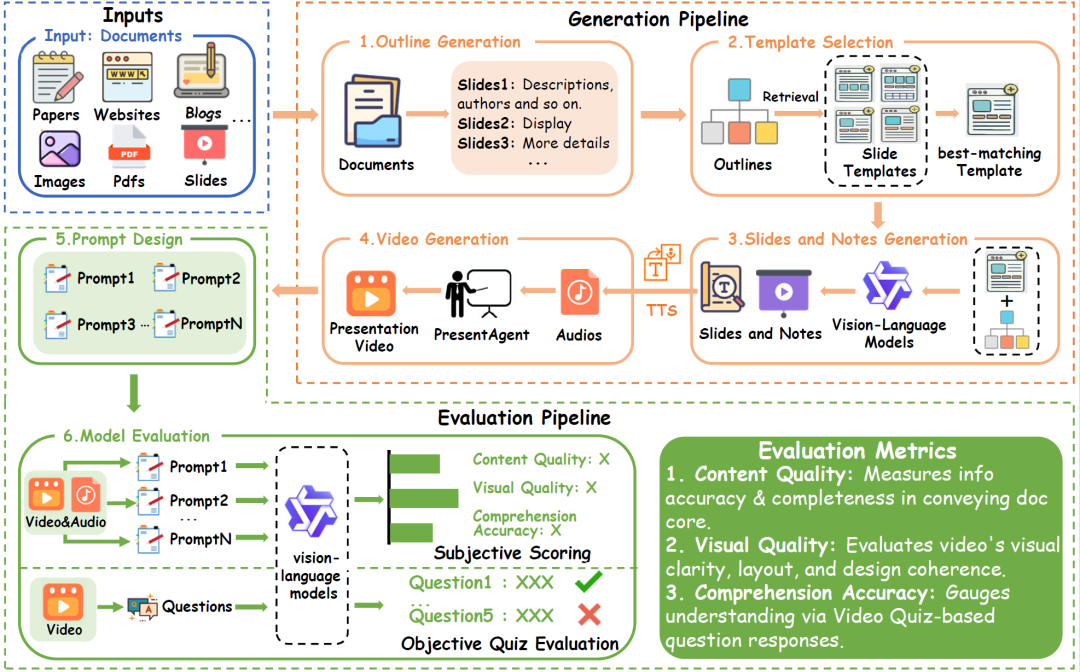
图4:PresentAgent框架概览
该系统以多种类型的文档(例如论文、网页、PDF等)为输入,遵循模块化的生成流程:
-
首先进行提纲生成;
-
接着检索出最适合的幻灯片模板;
-
然后借助视觉-语言模型生成幻灯片和解说文稿;
-
将解说文稿通过TTS转换为音频,并合成为完整的演示视频;
-
为了评估视频质量,设计了多个维度的提示语;
-
最后将提示输入基于视觉语言模型(VLM)的评分模块,输出各个维度的指标结果。
为了将长文本文档转化为带口语化讲解的演示视频,设计了一个多阶段的生成框架,模拟人类准备幻灯片与演讲内容的流程。
该方法分为四步:语义分段、结构化幻灯片生成、口语化讲解生成、可视与音频组合为同步视频。
该模块化设计支持可控性、可解释性和多模态对齐,兼顾高质量生成与细粒度评估。下文将分别介绍各模块。
传统方法通常直接从文档片段C生成幻灯片元素S,如下所示:
S={e1,e2,…,en}=f(C)
该方法则视整个文档D为整体输入,通过三步生成演示视频:
-
基于大纲规划生成语义段落序列{C1,…,CK};
-
对每段生成幻灯片Sk与口语讲稿Tk(再转为音频);
-
合成带时间对齐的视频V:
V=Compose({(S1,T1),…,(SK,TK)})=g(D)
该流程不依赖固定模板,而是从高层结构出发,自底向上生成幻灯片和讲解内容,支持多模态对齐与可控生成。
幻灯片模块借鉴了PPTAgent的结构化编辑范式,但目标不同——不是输出.pptx文件,而是为视频合成生成视觉一致的静态幻灯片帧。流程如下:
-
用轻量级语言模型解析文档,划分语义段;
-
为每段匹配合适的幻灯片类型(如:项目符号、图文结合、标题介绍等);
-
使用规则和语义信息将内容映射至HTML模板;
-
调用操作指令(如:replace_text, insert_image})生成最终幻灯片;
-
使用
python-pptx或HTML渲染器渲染为静态图像。
为使幻灯片更具吸引力,研究人员为每页幻灯片生成讲解,并将其合成为语音:
-
针对每个语义段落,提示语言模型生成自然、简洁的口语化讲稿;
-
控制长度在30–150秒之间;
-
使用文本转语音(TTS)系统生成对应音频;
-
将音频与幻灯片匹配,形成时间对齐的素材。
最后一步,将静态幻灯片图像与配音音频合成为完整的视频:
-
每页幻灯片持续显示,与其音频同步;
-
可添加淡入淡出过渡;
-
使用
ffmpeg等视频处理工具合成视频轨; -
输出标准格式(如
.mp4),便于分享或编辑。
研究人员设计实验以验证PresentAgent在生成高质量讲解视频方面的有效性。重点不在与已有基线方法比较,而是评估系统在接近人类表现方面的能力,特别是在PresentEval评估任务中的理解能力。
研究人员构建了一个包含30个长文档的测试集,每个文档配有人类手工制作的演示视频作为参考,涵盖教育、产品说明、科研综述与政策简报等主题。
所有生成与人工视频均使用PresentEval框架进行评估。由于当前尚无模型可完整评估超2分钟的多模态视频,采用分段评估策略:
-
客观评估阶段:使用Qwen-VL-2.5-3B回答固定的多项选择题,评估内容理解;
-
主观评分阶段:提取视频与音频片段,使用Qwen-Omni-7B针对内容质量、视觉/听觉质量和理解难度分别打分。
评分依赖维度提示语,覆盖内容完整性、视觉设计与语音可理解性。
PresentAgent采用高度模块化的多模态生成架构,主要特征如下:
-
语言理解模块支持GPT-4o、GPT-4o-mini、Qwen-VL-Max、Gemini-2.5 Flash/Pro、Claude-3.7-Sonnet,并通过动态路由策略选择最优模型;
-
VLM评估器使用轻量级Qwen-VL-2.5-3B-Instruct,评估布局合理性、图表可读性和跨模态一致性;
-
TTS使用MegaTTS3,支持24kHz高保真合成与节奏/情感控制;
完整流程包括:
-
结构解析与重排:构建主题–子主题树;
-
逐页生成:通过LLM生成含标题、项目符号、图像占位符和替代文本的幻灯片;
-
配音合成与合成输出:支持中英文发音,最终通过
ffmpeg脚本合成1080p视频,含淡入淡出与字幕。
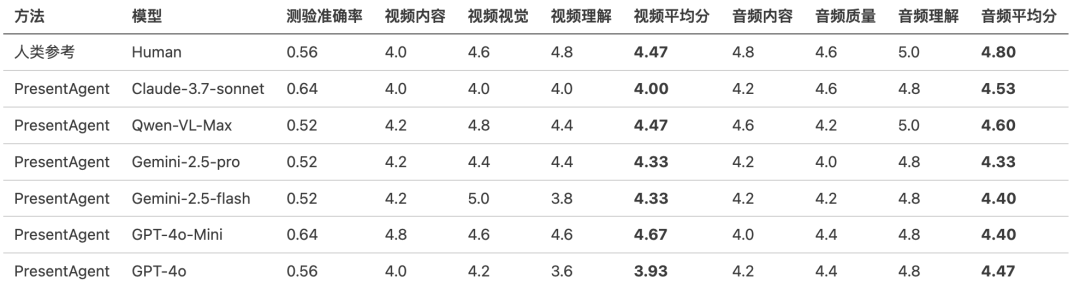
表3:五份测试文档的详细评估结果
表3展示了评估结果,涵盖了事实理解能力(测验准确率)以及基于偏好的视频和音频输出质量评分。
在测验准确率方面,大多数PresentAgent的变体与人工基准结果(0.56)相当甚至更优。其中Claude-3.7-sonnet取得了最高准确率0.64,表明生成内容与源文档之间具有较强的一致性。其他模型如Qwen-VL-Max和Gemini-2.5-flash得分略低(0.52),表明在事实对齐方面仍有提升空间。
在主观质量方面,由人类制作的演示仍在视频和音频整体评分上保持领先。然而,一些PresentAgent变体表现出有竞争力的性能。例如,GPT-4o-Mini在视频内容和视觉吸引力方面获得了最高分(均接近或达到4.8),而Claude-3.7-sonnet则在音频质量方面表现最为平衡(均分为4.53)。
有趣的是,Gemini-2.5-flash在视觉质量上取得了最高得分(5.0),但在理解性方面较低,这反映了美观性与清晰度之间的权衡。这些结果突显了模块化生成流程的有效性,以及统一评估框架PresentEval在捕捉演示质量多个维度方面的实用价值。

图5:自动生成视频示例
图5展示了一个完整的PresentAgent自动生成演示视频示例,其中一篇技术博客被转化为带解说的演示。
系统识别出结构性片段(如引言、技术解释等),并为其生成了包含口语风格字幕和同步语音的幻灯片,涵盖了“并行化工作流”“代理系统架构”等技术主题,展示了系统在保持技术准确性的同时,以清晰、对话式方式传达信息的能力。
研究人员合成了整合视觉幻灯片、文本解说和语音音频的演示风格视频,模拟了现实中的多模态交流场景。目前的评估方法主要关注各模态的独立质量,例如视觉清晰度、文本相关性以及音频可理解性,这些维度目前被分别对待。
然而,在现实应用中,沟通的有效性往往取决于各模态之间的语义与时间上的协同一致性。
因此,未来的研究应超越孤立评估,迈向融合感知(fusion-aware)的理解与评估,意味着不仅要建模图像、音频和文本模态之间的交互与对齐,还需赋予系统在多模态语义联合下的推理能力。
现有模型如ImageBind提供了多模态的统一嵌入空间,但在高层推理与语义理解能力方面仍有所不足。
一个有前景的方向是:将表示对齐(representation alignment)与多模态推理能力(multimodal reasoning)结合起来,构建融合对齐的模态编码器与强大的语言模型。
这将使系统具备对复杂多模态输入的联合感知、理解与响应能力——例如,基于语音解说与视觉线索解释某个视觉概念,或识别模态间的不一致性。
开发此类具有推理能力的融合感知模型,将是推动多模态理解向真实世界应用场景迈进的关键。
该工作目前面临两个主要限制:
-
由于使用商业LLM/VLM API(如 GPT-4o 和 Gemini-2.5-Pro)存在高计算成本,评估仅限于5篇学术论文,可能未能充分代表该基准数据集中展示的文档多样性;
-
PresentAgent当前生成的是静态幻灯片,尚未支持动态动画或转场效果,这主要受到视频合成架构限制以及生成速度与视觉质量之间的权衡约束(正如 ChronoMagic-Bench中关于时间一致性的研究所指出的)。
未来的研究工作将集中在三个方向:
-
第一,通过引入更多种类的开源大模型作为基础,包括多种架构设计、能力范围和微调策略,拓展至更多类别的文档,以支持更广泛的生成与评估任务,覆盖教育、政策、商业等实际场景,力求实现系统能力的全面评估;
-
第二,通过优化视频合成架构,引入动态动画能力,在保证生成效率的同时提升视觉表现,适配复杂的场景转场;
-
第三,探索轻量级蒸馏方法与具备物理感知能力的渲染引擎,从而提升生成效率、写实程度和对不同硬件环境的适应性。
研究人员提出了PresentAgent,一个用于将长篇文本文档转换为带有语音讲解的演示视频的模块化系统。通过系统性地处理幻灯片规划、语音解说合成以及视音同步渲染等流程,PresentAgent 支持对多种类型文档的可控生成与复用的多模态输出。
为支持严格评估,研究人员构建了文档–视频对齐的基准数据集,并提出了双重评估策略:事实问答与基于偏好的视觉语言评分。实验结果(包括消融实验与模型对比)表明,PresentAgent 能够生成结构清晰、表达生动且信息密集的演示内容,整体效果接近人类水准。
结果展示了融合语言模型与视觉模型在可解释且面向观众的内容生成方面的潜力,为未来在教育、商业、无障碍传播等场景中的自动化、可控多模态生成研究奠定了基础。
(文:新智元)