跳至内容


智东西7月16日消息,今日,谷歌和Meta前研究人员创立的AI初创公司Mistral AI,最新发布了首个开源语音模型:Voxtral语音理解模型系列!
该模型包含24B和3B两个参数规模的版本,均基于Apache 2.0许可证开源,同时提供API服务接口。
Voxtral模型支持32k token的上下文窗口,能够处理长达30分钟的音频转录任务或40分钟的语义理解任务,在各项基准测试指标上全面超越目前主流的开源语音转录模型Whisper large-v3。
Voxtral模型继承了Mistral Small 3.1基座模型的文本理解能力,除了基础的语音转文字功能外,还可以直接对音频内容进行问答交互,生成结构化摘要,并通过语音指令触发API调用。
在公告中,Mistral还给出了几个实例展现其语音生成能力,包括:
在成本敏感型应用场景中,Voxtral Mini转录版的性能优于OpenAI Whisper,而使用成本仅为后者的50%以下。在高阶应用场景中,Voxtral Small在保持与ElevenLabs Scribe相当性能水平的同时,使用成本同样控制在后者50%以下。
开发者可以在Le Chat上试用,通过Hugging Face平台获取模型进行本地部署,也可以使用云端API服务。
针对企业级应用,该模型支持私有化部署方案,可进行特定领域的微调适配,并提供高级上下文处理功能以及专属集成支持。
未来两周内Voxtral模型将在网页和移动端的语音模式中向所有用户推出。
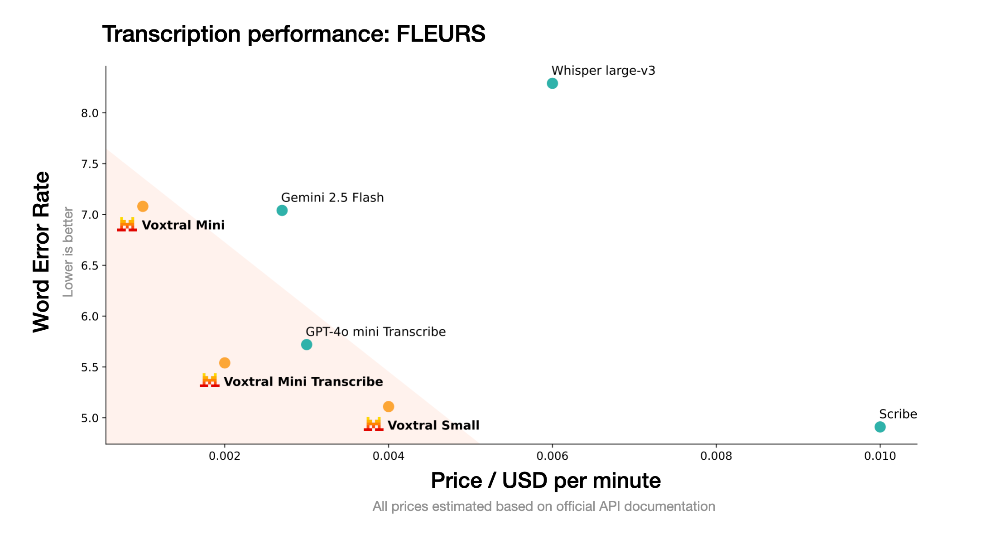
在转录能力上,Voxtral通过多个英语及多语种基准测试进行验证,每个任务的评测结果均采用跨语言宏平均词错率呈现,即数值越低越好。针对英语任务,还分别统计了短音频(<30秒)和长音频(>30秒)的平均表现。
结果显示,Voxtral在各项指标上全面超越当前领先的开源语音转录模型Whisper large-v3。在英语短音频,以及覆盖多种语言和方言的大规模语音数据库Mozilla Common Voice基准上,Voxtral Small超越Gemini 2.5 Flash与GPT-4o mini Transcribe,在英语长音频测试上也超越了Scribe和GPT-4o mini Transcribe。
在多语言基准测试FLEURS的评估中,Voxtral Small模型在所有任务上都超越了Whisper large-V3,并在法语和德语中占据榜单首位。
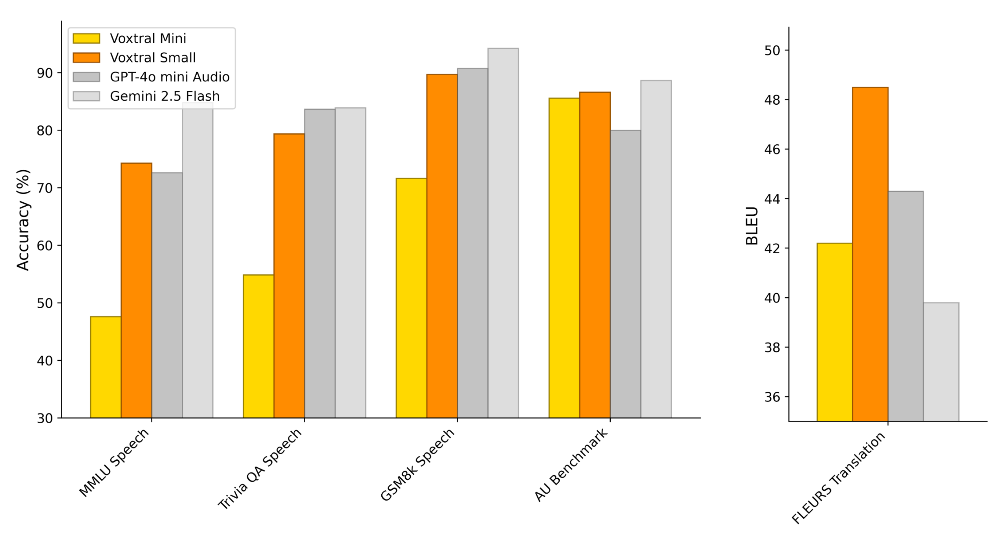
为了更好地测试Voxtral Small和Mini版本的语音理解能力,Mistral的研究团队将三项标准文本理解任务转换为语音输入形式,并构建了包含40个长音频样本的内部音频理解基准(AU Benchmark),要求模型完成复杂问答任务。此外,还基于FLEURS-Translation基准测试了Voxtral的语音翻译性能。
测试结果显示,Voxtral Small在所有任务中与GPT-4o-mini及Gemini 2.5 Flash表现相当,并在语音翻译任务FLEURS Translation中,超越GPT-4o-mini及Gemini 2.5 Flash,位列第一。
在文本方面,Voxtral保留了其基座语言模型的文本处理能力,在各项文本测试中与Mistral Small 3.1成绩相当,官方称可直接替代Ministral和Mistral Small 3.1模型使用。
Mistral AI发布的Voxtral语音模型系列为开源语音AI领域带来了新的技术选择。
从测试结果上看,该模型在转录准确率上超越了同为开源的Whisper,但其与商业模型GPT-4o-mini及Gemini 2.5 Flash还是有着一定的差距,Scribe依旧是语音模型中的“老大”。
Mistral AI在公告中还特别提到,未来几个月,Voxtral模型的音频处理能力还会持续增强,并且将新增说话人分割、音频标记(如年龄和情绪)、词级时间戳、非语音音频识别等功能。
(文:智东西)