


安防摄像头遍布大街小巷,但当有人突然摔倒、遭遇袭击,或在公共场所做出危险举动时,现有系统却常常“视而不见”?
问题核心在于:当前基于文本的行人检索技术,像个只会认“走路”和“站立”的“脸盲”——它擅长找特定的人,却对异常行为本身束手无策。
想象一下:老人不慎跌倒、孩童走失惊慌奔跑、突发冲突有人被推搡··· 这些关键瞬间的识别与报警,正是城市安防的“最后一公里”痛点。现有技术对此力不从心,急需能理解行为语义的智能安防。
西安交通大学、合肥工业大学、澳门大学的研究团队,在 ICCV 2025 上提出从数据收集到跨模态建模全流程方案。论文、代码、数据集已开源!立即探索未来安防新范式:

论文标题:
Beyond Walking: A Large-Scale Image-Text Benchmark for Text-based Person Anomaly Search
论文链接:
https://arxiv.org/abs/2411.17776
数据集 & 代码:
https://github.com/Shuyu-XJTU/CMP

新任务:基于文本的「行人异常检索」
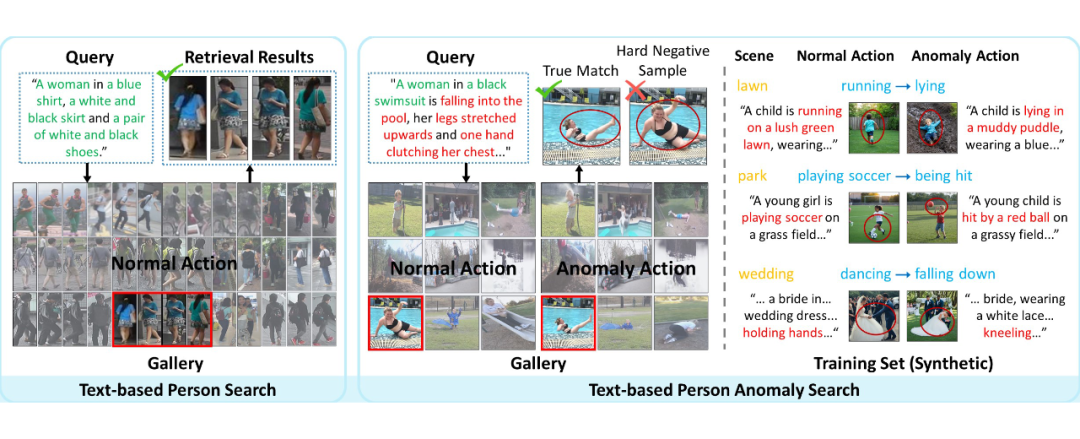
▲ 新任务——基于文本的行人异常检索(右)与传统的基于文本的行人检索(左)的比较。
-
不止找人,更要识“事”!输入“一名穿红衣的男子突然摔倒”或“穿校服的学生被自行车撞倒”,系统能精准定位安防画面中符合该异常描述的行人及行为。
-
彻底突破传统检索仅关注“谁在走”的局限,直击“发生了什么异常”的核心需求。

百万级图文基准:「行人异常行为数据集(PAB)」发布!
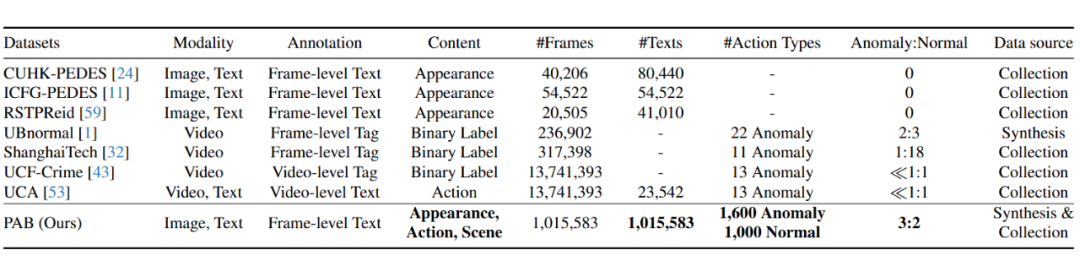
▲ PAB 与现有基于文本的行人检索和视频异常检测数据集在数据质量和数量方面的综合比较
-
规模空前:包含超 101 万张高质量合成训练图像 + 1978 张真实世界测试图像,构建百万级图文对!
-
覆盖广泛:囊括跑步、表演、踢足球等常规动作,更重点覆盖躺卧、被撞击、摔倒等关键异常行为。
-
真实可靠:测试集源于真实世界视频,经过关键点检测、图像相似度过滤、专家人工核验三重严格把关。
-
低成本高效:创新结合 AI 生成图像(扩散模型)+ 大模型自动描述(Qwen2-VL)+ 专家修正,解决异常数据稀缺与标注成本高昂难题。
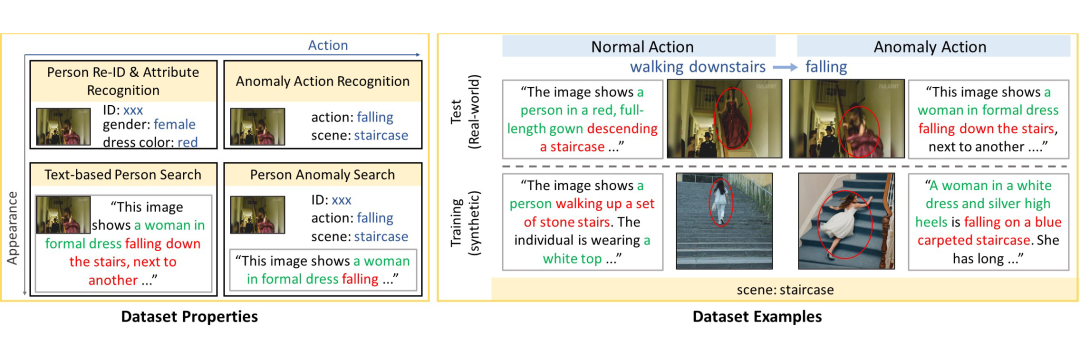
▲ 不同任务的数据集属性(左)与PAB数据集示例(右)

「火眼金睛」框架:跨模态姿态感知(CMP)
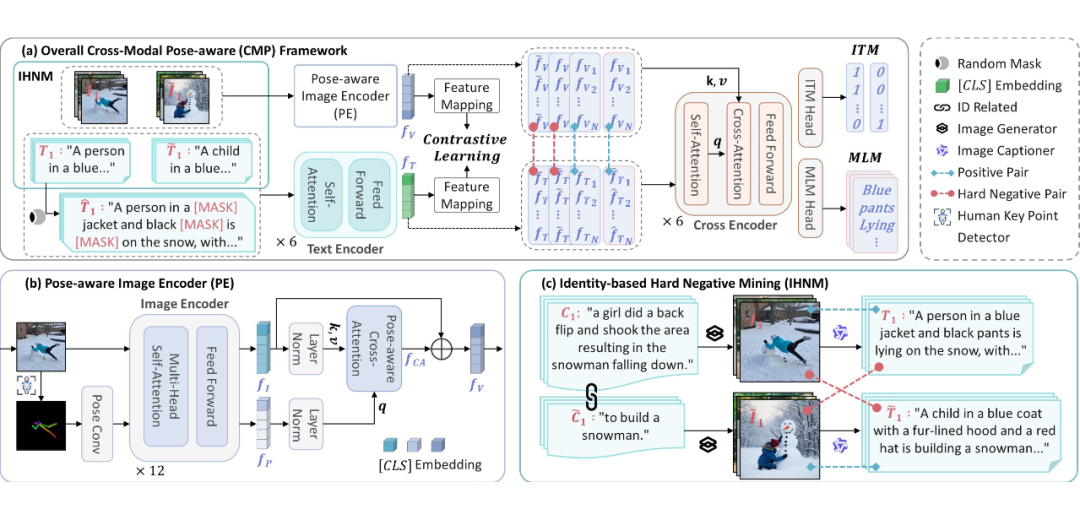
▲ 跨模态姿态感知(CMP)框架概述
-
看懂“姿势”辨异常:创新融合人体姿态信息,让 AI 理解动作语义。
-
“找茬”训练法:采用基于身份的困难负样本挖掘(IHNM)策略,专治“长得像但行为不同”的混淆情况。
-
效果惊人:在真实测试集上达到 84.93% 的 Recall@1 准确率,大幅领先现有方案!

实验结果
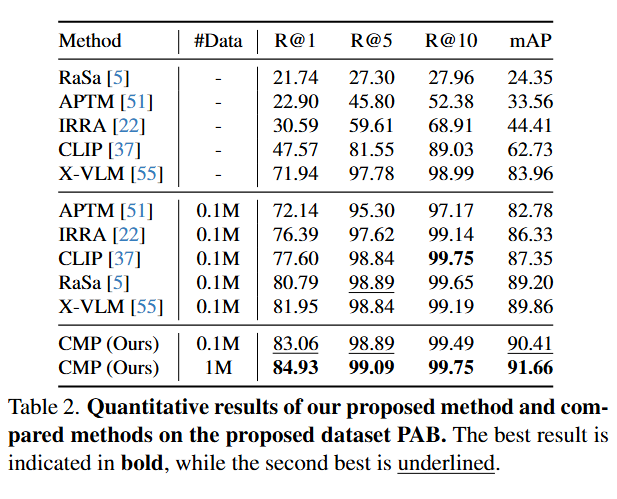
定量结果。表 2 展示了 CMP 与一系列可能的解决方案的实验结果比较。
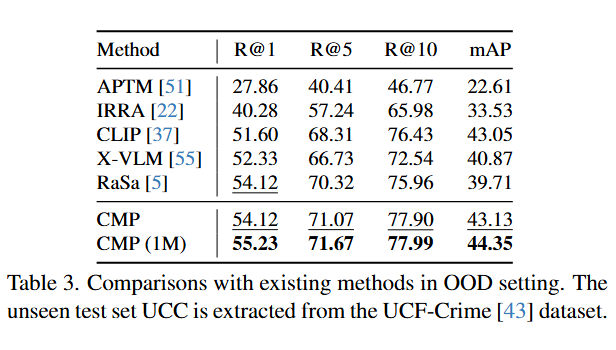
OOD 场景。表 3 展示了用于评估 CMP 模型的可扩展性,进行的 Out-of-Distribution(OOD)测试结果。
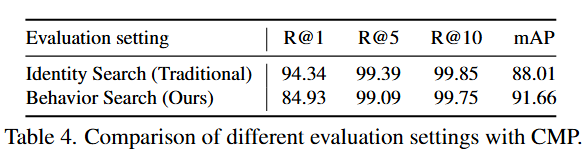
行为检索 v.s. 身份检索。如表 4 所示,传统身份检索方法将具有相同 ID 的所有图像视为正确匹配,异常检索任务需要精确定位特定行为。
定性结果。

▲ 文本查询的 Top-5 异常检索结果

为什么这很重要?
-
城市安全升级:为智慧城市、公共安防系统装上“行为理解引擎”,实现跌倒检测、突发冲突预警、走失人员异常行为识别等。
-
效率倍增:告别人工盯屏,通过自然语言描述快速检索关键事件录像片段。
-
技术拐点:解决了异常行为数据稀缺的核心瓶颈,为 AI 理解复杂场景行为铺平道路。
当城市安防系统真正学会“察言观色”,看懂行人的“一举一动”,百万图文对构建的“异常图鉴”正在让这一未来加速到来。关注 ICCV 2025,关注 AI 如何为城市安全筑牢“智能防线”!
(文:PaperWeekly)