
阿里发布了一个工具,叫Flux-Text。
FLUX-Text:用于场景文本编辑的简单和高级扩散变换器基线。

📖 概述
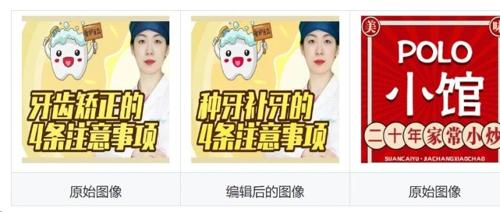
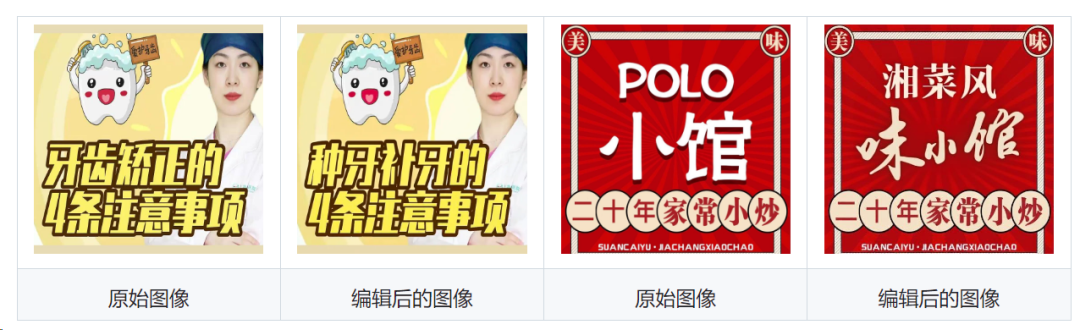
动机: 场景文本编辑是一个具有挑战性的任务,旨在修改或添加图像中的文本,同时保持新生成文本的忠实度和与背景的视觉一致性。这个任务的主要挑战是我们需要编辑具有多种语言属性(例如,字体、大小和样式)、语言类型(例如,英语、中文)和视觉场景(例如,海报、广告、游戏)的多行文本。
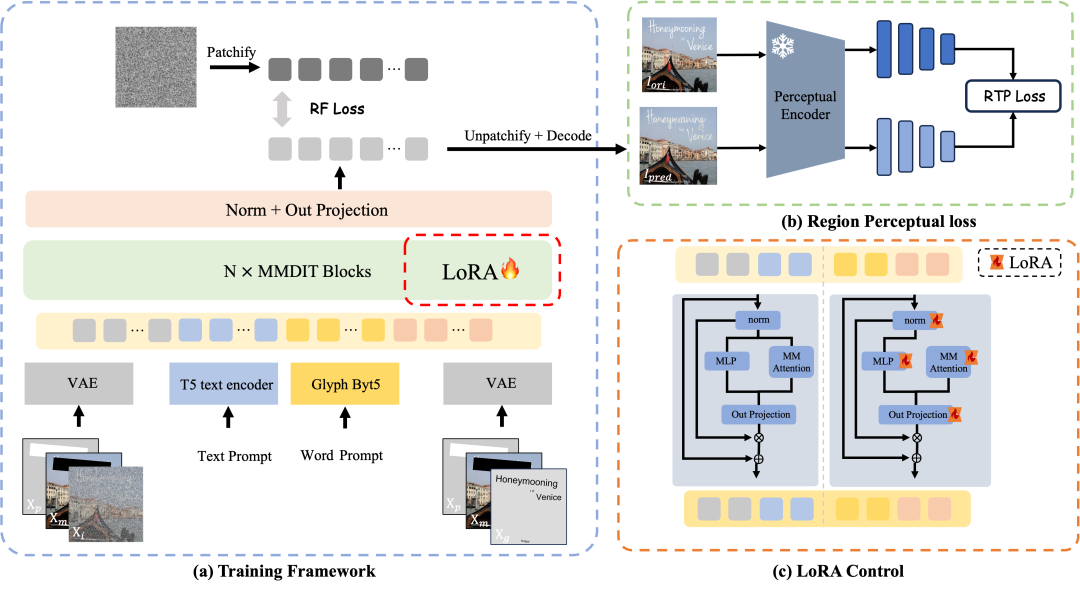
贡献:我们提出了FLUX-Text,这是一种用于在复杂视觉场景中编辑多行文本的新型文本编辑框架。通过结合轻量级条件注入LoRA模块、区域文本感知损失和两阶段训练策略,我们在中文和英文基准测试上取得了显著的改进。
新闻
2025-07-08:🔥 ComfyUI Node 受支持!现在你可以基于 FLUX-Text 构建海报编辑工作流。设置工作流以自动增强产品图像服务信息和服务范围绝对值得尝试。同时,利用第一帧和最后一帧可以创建具有文字效果的视频数据。感谢 社区工作,FLUX-Text 在 8GB VRAM 上运行。
2025-07-04: 🔥 我们已经发布了gradio演示!现在你可以试试FLUX-Text。
2025-07-03:🔥 我们已经发布了 预训练的检查点 在 Hugging Face 上!现在你可以使用官方权重试用 FLUX-Text。

2025-06-26: ⭐️ 推理和评估代码已发布。一旦我们确保一切正常运行,新模型将被合并到此仓库中。
🛠️ 安装
我们建议使用Python 3.10和带有CUDA支持的PyTorch。要设置环境:
# Create a new conda environmentconda create -n flux_text python=3.10conda activate flux_text# Install other dependenciespip install -r requirements.txtpip install flash_attn --no-build-isolationpip install Pillow==9.5.0
🤗 模型介绍
FLUX-Text 是场景文本编辑模型的开源版本。FLUX-Text 可用于编辑海报、情感等。下表显示了我们当前提供的文本编辑模型列表及其基础信息。

🔥 ComfyUI
通过 GitHub 安装
🔥 快速开始
这是一个使用 FLUX-Text 的基本示例:
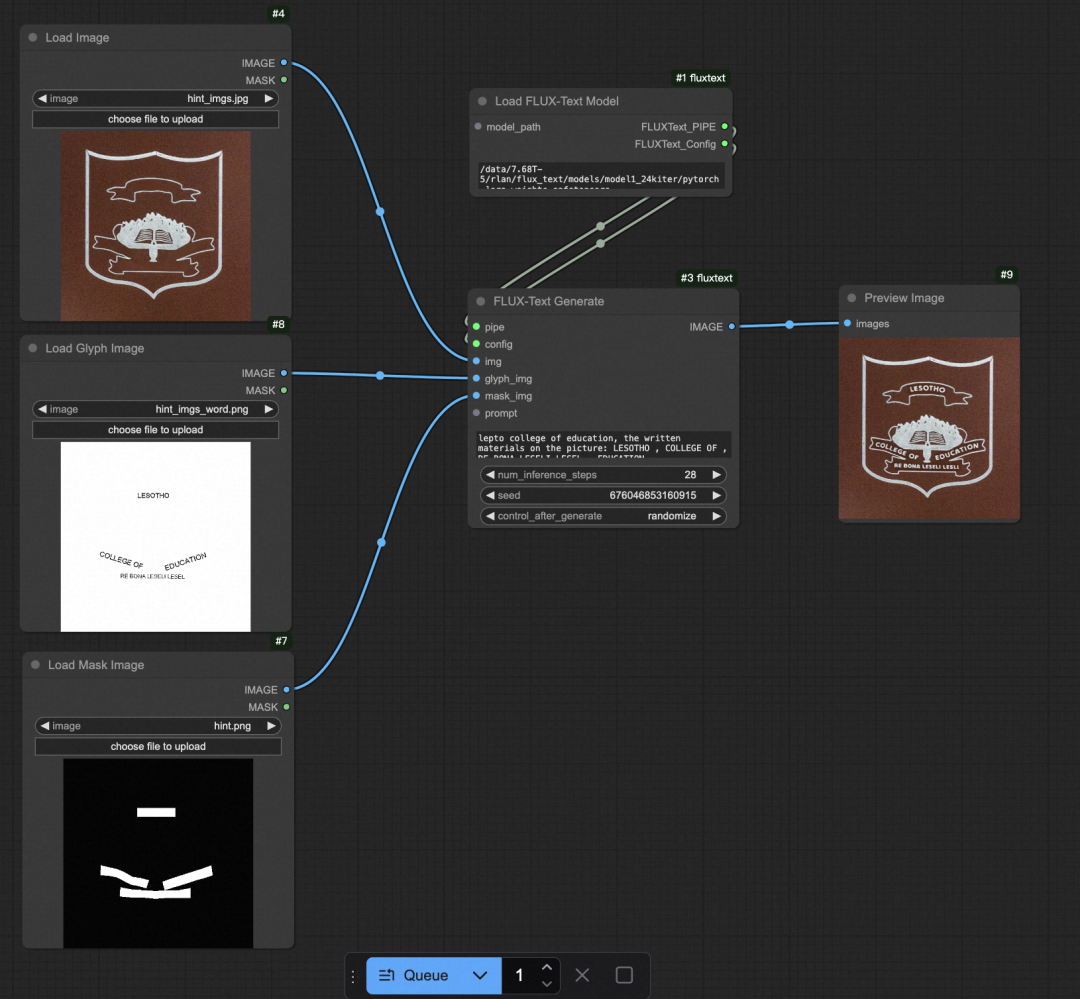
import numpy as npfrom PIL import Imageimport torchimport yamlfrom src.flux.condition import Conditionfrom src.flux.generate_fill import generate_fillfrom src.train.model import OminiModelFIllfrom safetensors.torch import load_fileconfig_path = ""lora_path = ""with open(config_path, "r") as f:config = yaml.safe_load(f)model = OminiModelFIll(flux_pipe_id=config["flux_path"],lora_config=config["train"]["lora_config"],device=f"cuda",dtype=getattr(torch, config["dtype"]),optimizer_config=config["train"]["optimizer"],model_config=config.get("model", {}),gradient_checkpointing=True,byt5_encoder_config=None,)state_dict = load_file(lora_path)state_dict_new = {x.replace('lora_A', 'lora_A.default').replace('lora_B', 'lora_B.default').replace('transformer.', ''): v for x, v in state_dict.items()}model.transformer.load_state_dict(state_dict_new, strict=False)pipe = model.flux_pipeprompt = "lepto college of education, the written materials on the picture: LESOTHO , COLLEGE OF , RE BONA LESELI LESEL , EDUCATION ."hint = Image.open("assets/hint.png").resize((512, 512)).convert('RGB')img = Image.open("assets/hint_imgs.jpg").resize((512, 512))condition_img = Image.open("assets/hint_imgs_word.png").resize((512, 512)).convert('RGB')hint = np.array(hint) / 255condition_img = np.array(condition_img)condition_img = (255 - condition_img) / 255condition_img = [condition_img, hint, img]position_delta = [0, 0]condition = Condition(condition_type='word_fill',condition=condition_img,position_delta=position_delta,)generator = torch.Generator(device="cuda")res = generate_fill(pipe,prompt=prompt,conditions=[condition],height=512,width=512,generator=generator,model_config=config.get("model", {}),default_lora=True,)res.images[0].save('flux_fill.png')
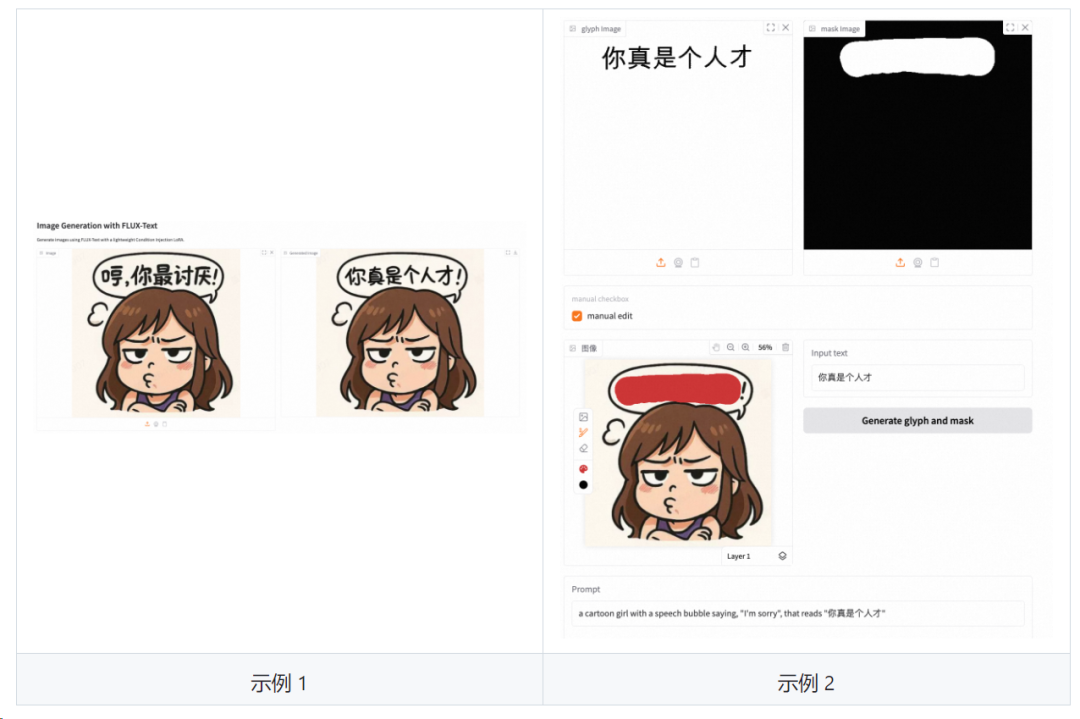
🤗 格拉迪欧
您可以上传字形图像和掩码图像以编辑文本区域。或者您可以使用manual edit来获取字形图像和掩码图像。
首先,在HuggingFace下载模型权重和配置
python app.py --model_path xx.safetensors --config_path config.yaml💪🏻 训练
📊 评估
对于Anytext-benchmark,请设置config_path、model_path、json_path、output_dir在eval/gen_imgs_anytext.sh中,并生成文本编辑结果。
bash eval/gen_imgs_anytext.sh对于Sen.ACC, NED, FID and LPIPS评估,请使用eval文件夹中的脚本。
bash eval/eval_ocr.shbash eval/eval_fid.shbash eval/eval_lpips.sh
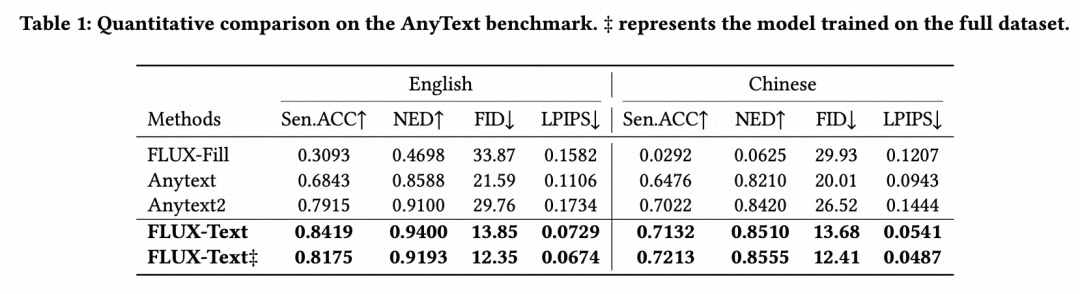
📈 结果
(文:路过银河AI)