跳至内容
年初还是「AI 六小虎」齐头并进,如今却只剩寥寥几家还能站上牌桌。DeepSeek 一招「开源即发布」,凭借高性能和极致性价比迅速占据用户的心智,也顺势拿下了国产大模型开源叙事的话语权。
此后,六小虎中不少公司接连遭遇融资受阻、产品停更、团队重组,甚至逐渐淡出公众视野。与此同时,当 DeepSeek 把开源模型卷出了实用门槛,也让其他玩家不得不加速入局。
今天,轮到 Kimi 接棒出手,正式发布并开源 Kimi K2 模型。
Kimi-K2-Base:未经过指令微调的基础预训练模型,适合科研与自定义场景;
Kimi-K2-Instruct:通用指令微调版本(非思考模型),擅长大多数问答与 Agent 任务
官方介绍称,Kimi K2 基于 MoE 架构打造,参数总规模达 1T,激活参数 32B,在代码生成、Agent 调度、数学推理等任务中具备竞争力。
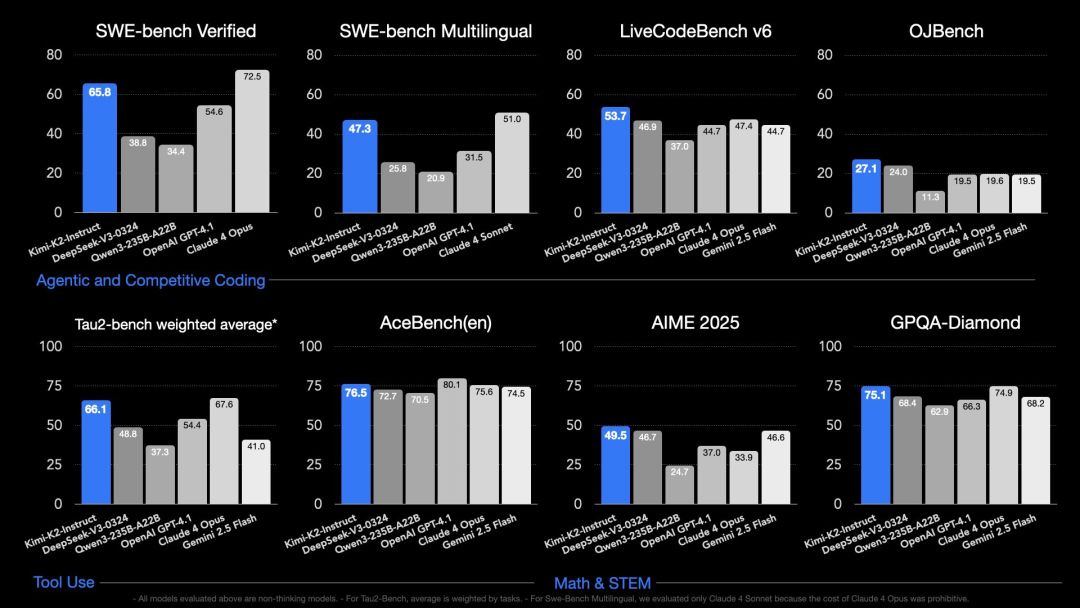
在 SWE Bench Verified、Tau2、AceBench 等基准测试中,K2 均取得开源模型中的 SOTA 成绩。其中,自主编程(Agentic Coding)、工具调用(Tool Use)和数学推理(Math & Reasoning)三大能力维度都有不错的表现。
值得注意的是,上述评测中的所有模型均为非思考模型。在 Tau2-Bench 测试中,平均值按照任务加权计算。在 Swe-Bench 多语言测试中,仅评估了 Claude 4 Sonnet,因为 Claude 4 Opus 的成本过高。
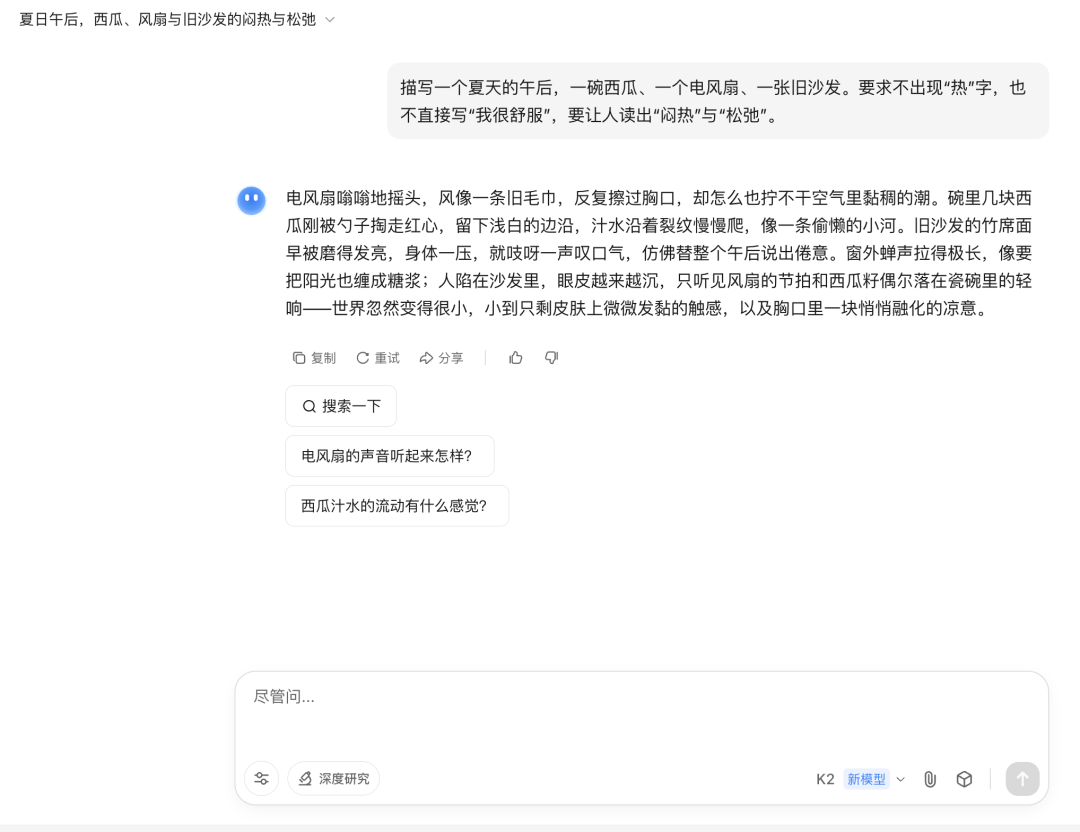
实际体验下来,写作能力的提升是这次版本升级中比较明显的一环。
比如面对「描写一个夏天的午后,一碗西瓜、一个电风扇、一张旧沙发。要求不出现『热』字,也不直接写『我很舒服』,要让人读出闷热与松弛」时,K2 给出的文本既有画面感,又不失情绪的克制表达。语言克制、节奏松弛,甚至带有文学感。
再比如这个相对复杂的案例:「写一篇看似是『在便利店偶遇前任』的平淡故事,但要隐藏一个副线:主角其实身患重病,正在做最后的生活整理。请控制情绪层次,不能直说,结尾只用一句隐喻点明真相。」
K2 完全没有写出生病或死亡字眼,而是通过道具、行为、细节缓缓推进情绪张力。故事结构完整,结尾一瓶未开的汽水安静地躺在垃圾桶顶端,成为情绪隐线的收束。令我惊喜的是,甚至还补上了人物小传。
不过,隐喻密度偏高且引用并不合理,却也犯了和 DeepSeek 同样的毛病,尤其少量句式略显设计感过重,仍有提升的空间。
在 Agent/Coding 任务上,Kimi K2 宣称支持 ToolCall 架构,可无缝接入 Owl、Cline、RooCode 等主流框架,具备自动指令拆解和任务链构建能力。目前 Agent 能力已开放 API 使用。
在编程类任务上,K2 虽然整体完成度高,但瑕疵也比较明显,比如还是那个经典的天气卡片案例,Kimi 能完成基础的构建,但 UI 粗糙、动效生硬,在视觉体验上逊色不少。
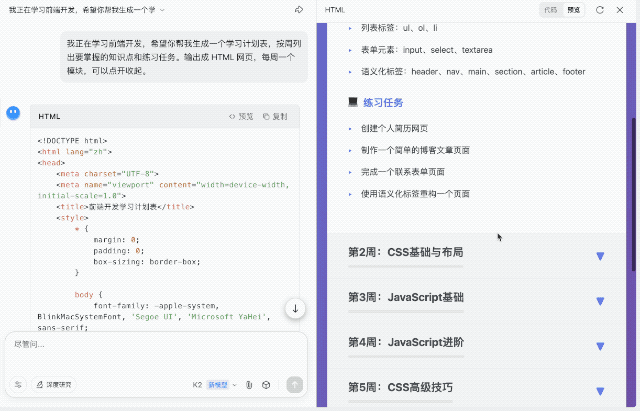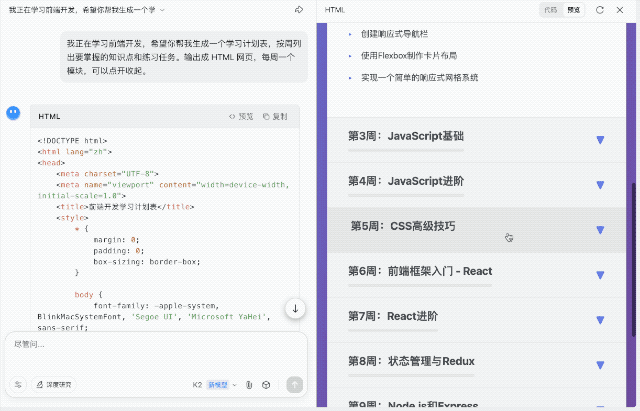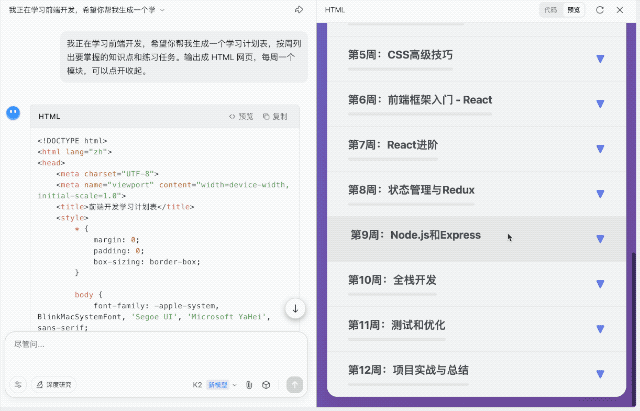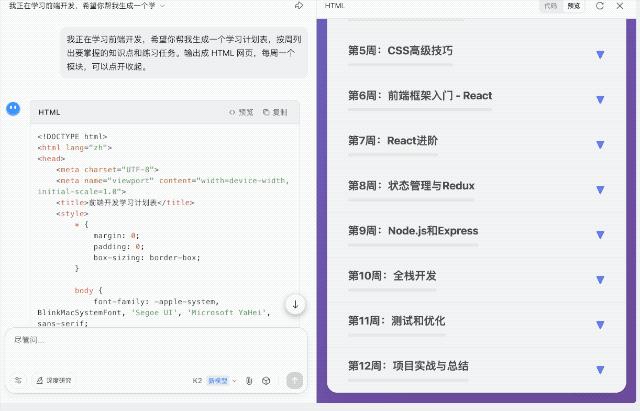
再拉高难度,我要求生成一个按周划分的前端学习计划,输出为 HTML 页面,支持模块展开与收起交互。这一任务对结构组织、内容节奏和 JS 逻辑的要求更高。K2 给出的结果中规中矩。
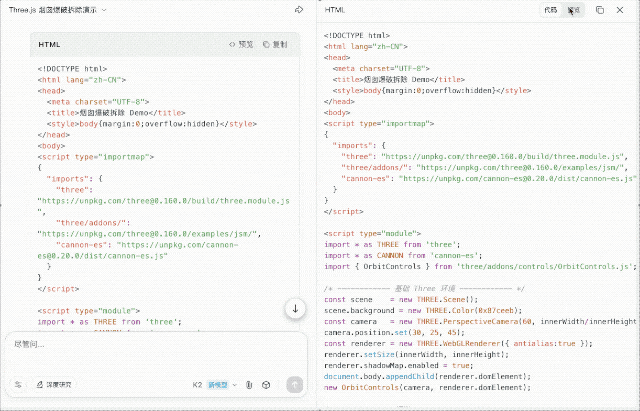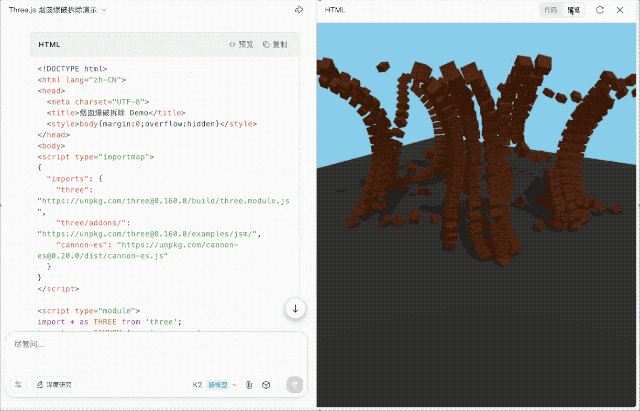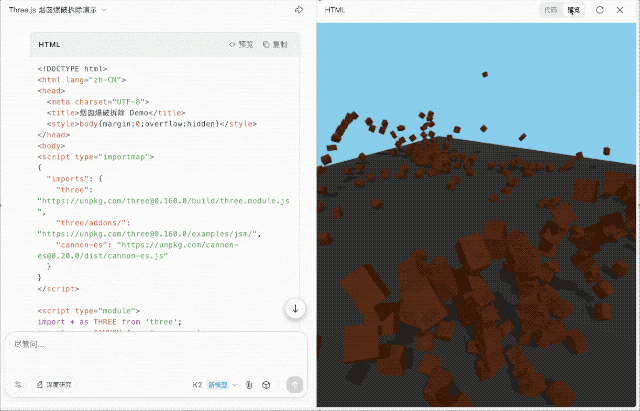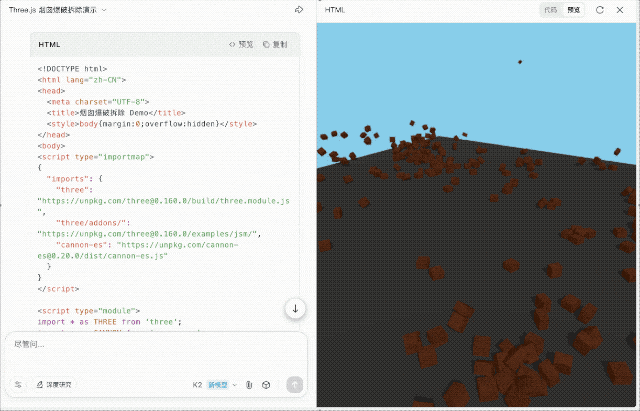
我输入任务:「用 three.js 和 cannon-es.js 实现烟囱倒塌爆破效果」。K2 尝试联网查找资料并组合代码,整体思路在线,执行力尚可,但视觉效果依然较弱。
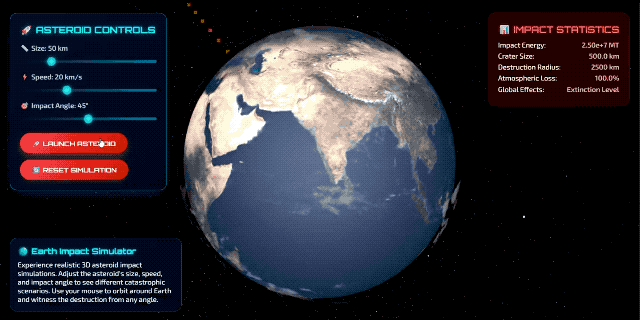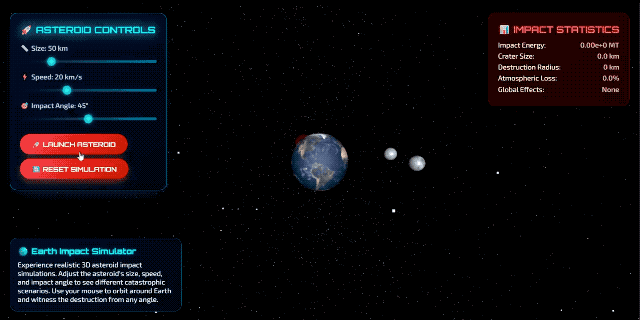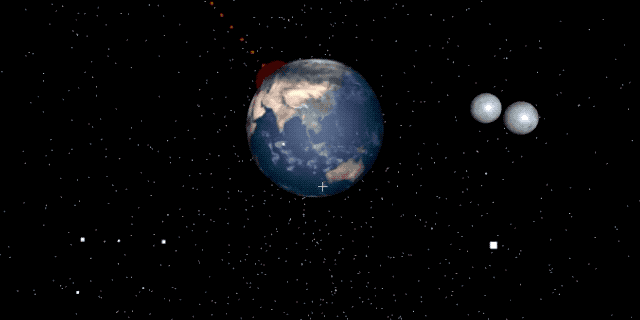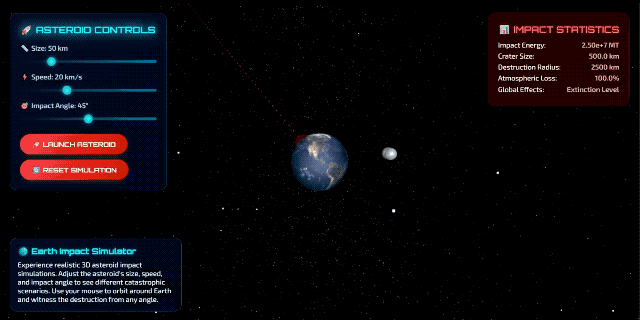
当然,也有一些比较不错的案例。比如海外博主 @chetaslua 使用提示词「make a website that shows 3D Simulation of Asteroids hitting Earth in html」,产出效果更为成熟,得到的画面如下:
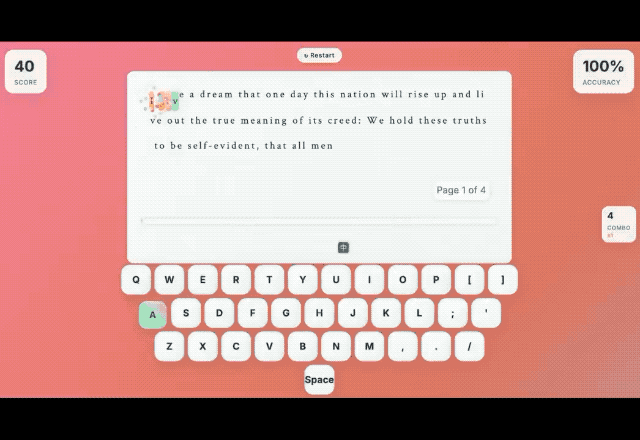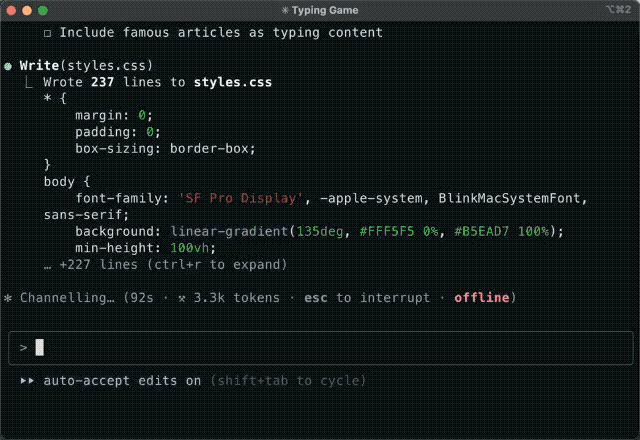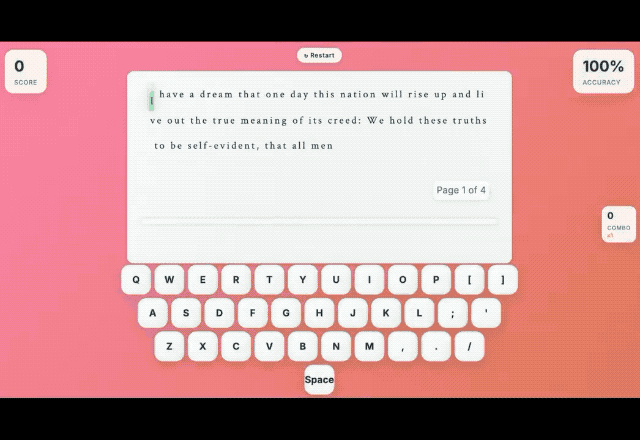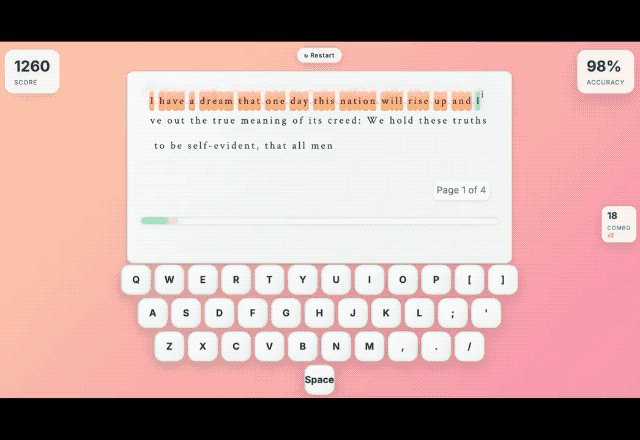
由于 K2 兼容 OpenAI 和 Anthropic 的 API 协议,网友 @Khazzz1c 也使用 K2 在 Claude Code 上开发了一个打字游戏,并评价这个模型 「cracked AF」,这是俚语,意思是「强到离谱、好得不正常」。
在 Kimi K2 背后,是月之暗面 Kimi 团队自研的一整套技术路径。
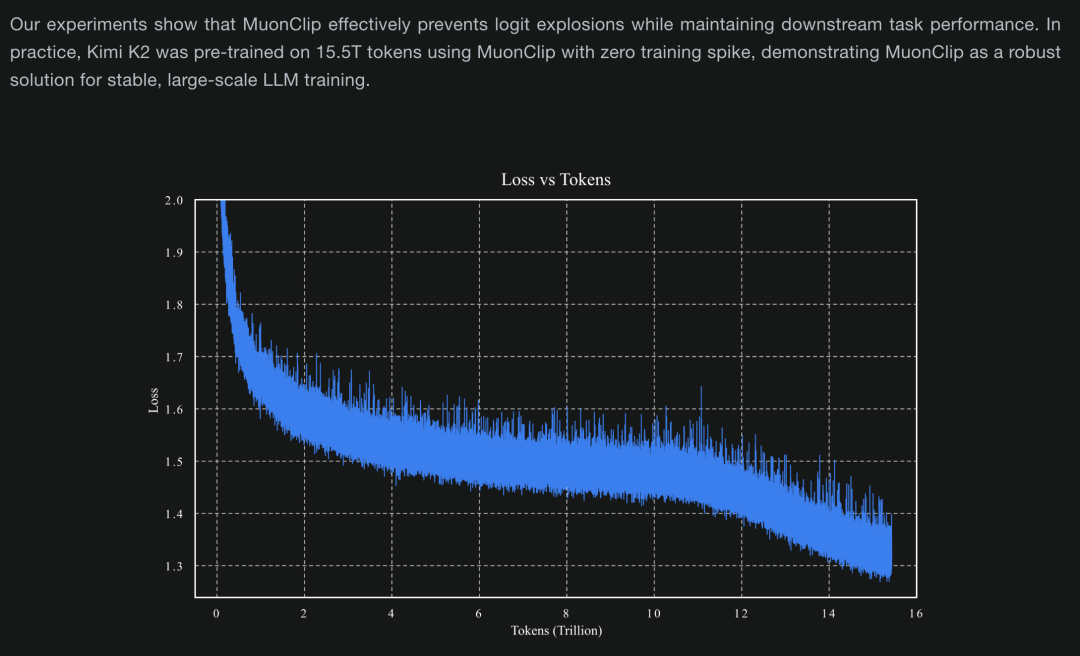
技术博客显示,他们在训练万亿参数大模型时,摒弃传统的 Adam 优化器,改用自研的 Muon 体系,并引入 MuonClip 机制,有效缓解 attention logits 过大的问题,从而确保模型在 15.5T token 训练过程中无一次 loss spike,训练稳定性和 token 使用效率双双提升。
同时,团队还构建了一条可大规模生成多轮工具使用场景的数据合成 pipeline,覆盖数百领域、数千种工具,并且,训练样本则由 LLM 自动筛选评估,确保数据质量。
在训练策略上,Kimi K2 进一步强化了通用强化学习能力,不仅在代码、数学等可验证任务上进行强化学习,还通过「自我评价」机制解决奖励稀缺问题,显著增强了模型的泛化能力。
开源层面,Kimi K2 的 Instruct 模型及 FP8 权重文件已上传至 Hugging Face,(传送门:https://huggingface.co/moonshotai/Kimi-K2-Instruct)根据官方部署说明,Kimi K2 的 FP8 版本可在主流 H200 等平台上运行,支持最长 128K 上下文,最低部署要求为 16 张 GPU 的集群环境。
目前包括 vLLM、SGLang、ktransformers 在内的主流推理引擎均已支持该模型,部署路径已被打通,但对普通开发者而言,算力的门槛仍不容忽视。
商业化方面,Kimi K2 的 API 服务也已正式上线,提供最长 128K 上下文支持,定价为每百万输入 tokens 收费 4 元、输出 tokens 收费 16 元。
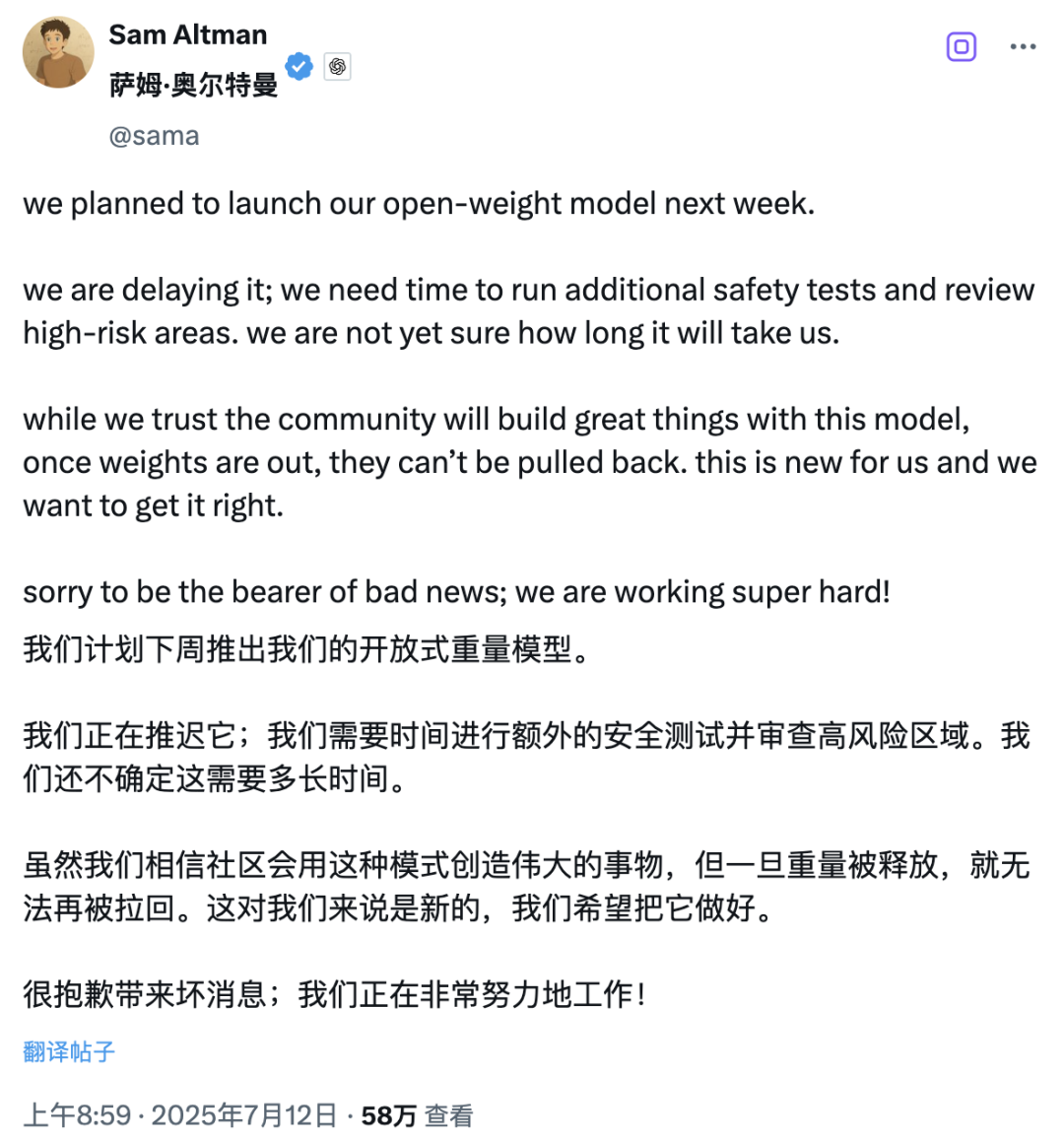
而有趣的是,与 Kimi 的大方开源相比,OpenAI CEO Sam Altman 刚刚宣布推迟原定下周发布的开放权重模型,理由是仍需补充安全测试与高风险区域审查,且未确定延期时长。
欢迎加入 APPSO AI 社群,一起畅聊 AI 产品,获取#AI有用功,解锁更多 AI 新知👇
✉️ 邮件标题「姓名+岗位名称」(请随简历附上项目/作品或相关链接)
(文:APPSO)