

极市导读
西北工业大学与清华大学联合提出并开源了SURGEON,一种面向移动端的内存自适应的完全测试时域自适应方法。该方法通过动态激活稀疏策略,在反向传播过程中按层裁剪中间激活,实现了在准确率与内存开销之间的灵活权衡,同时无需修改模型原始训练流程。论文已被CVPR 2025录用为Highlight(前13.5%)并实现完整开源。>>加入极市CV技术交流群,走在计算机视觉的最前沿

论文标题:SURGEON: Memory-Adaptive Fully Test-Time Adaptation via Dynamic Activation Sparsity
论文链接:https://arxiv.org/abs/2503.20354
开源代码:https://github.com/kadmkbl/SURGEON/
1. 摘要
为应对环境干扰和分布偏移带来的挑战,测试时自适应(Test-Time Adaptation, TTA)能够在无需标签的情况下对目标数据进行在线学习,提升模型性能。然而,大多数基于反向传播的TTA方法在适应过程中存在显著的内存开销问题,这成为限制其在移动设备上应用的关键瓶颈。
为此,本文提出了SURGEON —— 一种面向移动端设计的内存自适应完全测试时域自适应(Fully Test-Time Adaptation, FTTA)方法。其核心是动态激活稀疏策略,在适应过程中按层裁剪中间激活,并基于两项指标动态决定裁剪比例:① 梯度重要性衡量各层在当前数据上的性能提升贡献;② 激活内存重要性量化各层中间激活的内存开销。
实验证明,SURGEON无需修改原始训练流程或依赖特定网络结构,在多个模型架构和任务上均实现了精度与内存的最优平衡,为TTA技术在资源受限设备中的实际部署提供了新的可能。
2. 背景与动机
随着AI与物联网技术的加速融合,越来越多的深度模型被部署于移动设备上。然而在真实应用环境中,这些模型常常遭遇如光照变化、天气干扰等部署偏移问题,导致推理性能大幅下降。为了解决这一问题,测试时域自适应(TTA)作为应对分布偏移的有效手段,能够在不使用标签的前提下实现模型的在线适应。然而,当前方法仍面临两大关键挑战:
-
多数TTA方法依赖反向传播,带来大量内存消耗,不利于在资源受限设备上落地; -
现有内存优化策略要么依赖于特定网络结构(如 BN 层),要么需要访问训练数据并修改原始训练流程,限制了其通用性。
为了解决上述挑战,本文提出SURGEON,一种无需结构依赖、无需训练修改的内存高效完全测时时域自适应方法。其关键策略是动态激活稀疏(Dynamic Activation Sparsity),在适应过程中按层裁剪中间激活。其动机来自于:
-
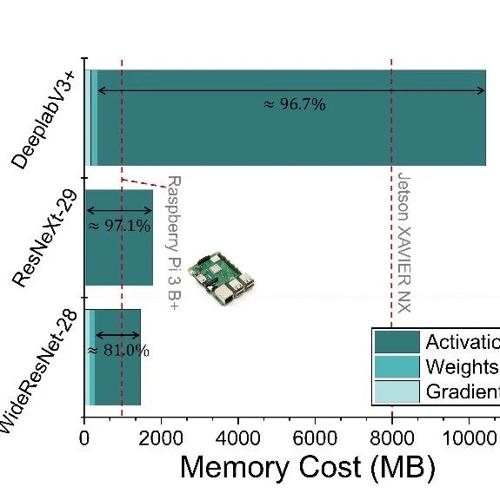
实验验证显示,中间激活(Activations)在反向传播中消耗的内存最多,是适应过程的主要瓶颈(见图1);
-
各层在适应过程中的精度贡献与内存开销差异显著。按需、精准的层级裁剪决策能实现适应精度和内存开销的有效权衡。
通过该策略,SURGEON在多个模型与任务上均显著降低了适应内存成本,同时保持甚至提升了模型适应精度,实现了TTA方法在移动设备上的实用部署。
3. 技术方案
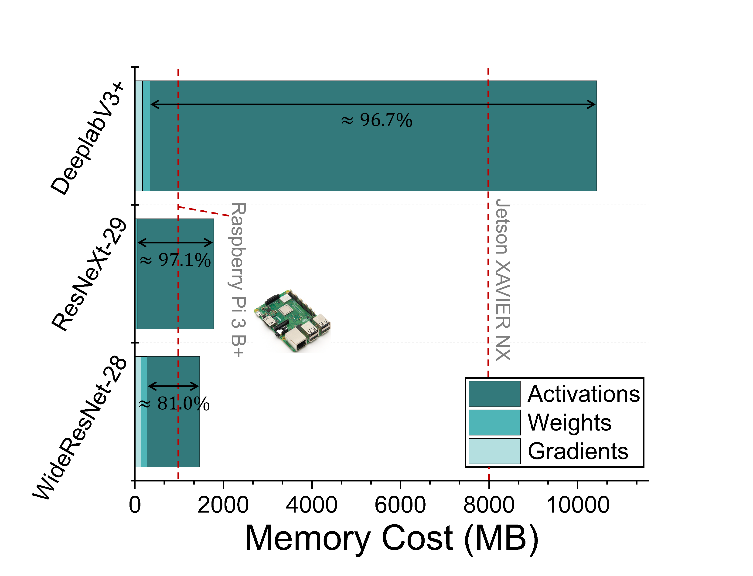
SURGEON的核心思想是在模型适应过程中,动态裁剪不同层的中间激活,从而精细控制各层的学习能力与内存开销,如图2所示。
3.1 层级重要性评估
要为不同层合理分配激活裁剪率,关键在于如何评估每一层的重要性。为了在测试时域自适应中实现精度与内存的有效权衡,SURGEON 引入了两个层级重要性指标:
-
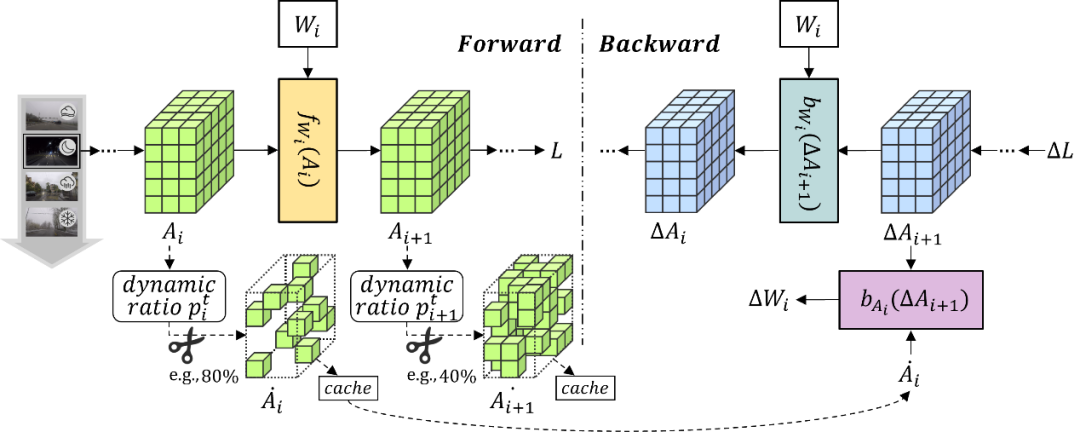
梯度重要性(Gradient Importance, ):衡量该层在当前数据下对模型预测结果的影响。直观来看,具有更大梯度的层对损失下降和模型调整的贡献更大,意味着它在当前数据中的适应价值更高。
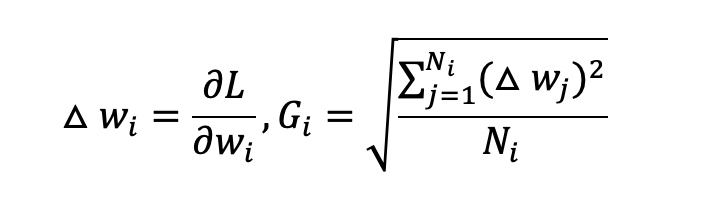
-
激活内存重要性(Activation Memory Importance, ):衡量该层中间激活的内存占用,反映其在适应过程中对内存资源的消耗程度。
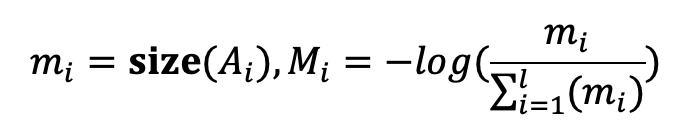
在此基础上,SURGEON综合这两个指标,将其转化为每层的动态激活裁剪率:
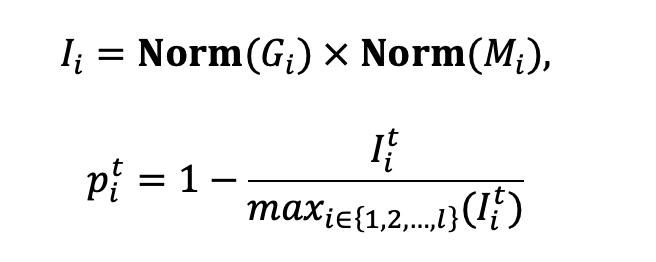
由上式可见,动态激活稀疏在适应过程中,对梯度大的层分配更小的裁剪率,鼓励其参与更多参数更新,提升适应精度;对激活占内存大的层分配更高的裁剪率,有效压缩适应过程中的内存占用。
3.2 动态激活稀疏框架
在每个测试批次开始前,SURGEON 会执行一次额外的前向-反向传播,以计算当前数据下的的 与 ,从而获得每一层的裁剪率。然而,关键问题在于:如何确保这一重要性评估过程不会反过来成为新的内存瓶颈? 为此,SURGEON 设计了两项轻量化策略,确保其计算过程不会超过后续适应过程的内存开销:① 随机采样当前批次中的少量样本,降低计算负担;② 使用高比例(如90%)的全局静态激活裁剪,进一步压缩评估开销。
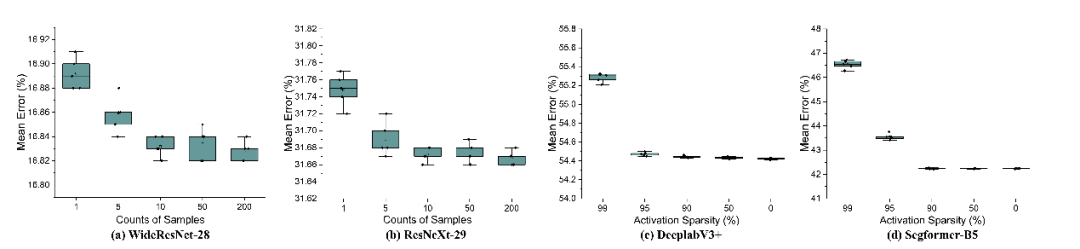
如图3所示,作者团队对这两项策略进行了实证验证,评估了不同采样量与裁剪比例下模型适应精度的变化,证明该设计兼顾了效率与效果。
最终,SURGEON的测试时域自适应过程分为三个阶段:
-
前向-反向预评估:计算每层的梯度重要性 与激活内存重要性 ,并得出当前批次的激活裁剪率 ; -
前向传播:按 对各层中间激活进行裁剪,并将其缓存; -
反向传播:基于裁剪后的激活计算权重梯度,完成参数更新。
4. 实验结果
研究团队在图像分类与语义分割两大任务上进行了实验评估,涵盖了CNN与Transformer等不同架构。对比指标包括:① 在线错误率(Online Error, %):表示在每个测试域中,各类别的平均预测错误率;② 平均在线错误率(Mean Online Error, %):表示整个测试序列中所有测试域的在线错误率的平均值;③ 缓存大小(Cache Size, MB):表示在适应过程中,中间激活所消耗的平均内存开销。
4.1 对比评估
表1. 在CIFAR-to-CIFAR-C任务上的对比评估(“Original”表示该方法是否修改模型原始训练流程)
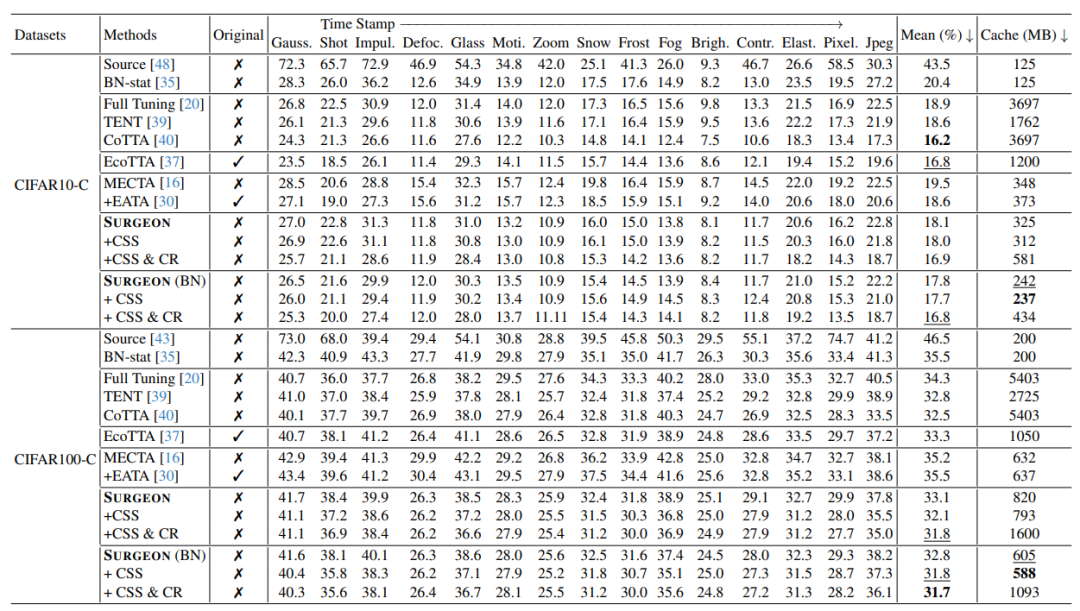
表2. 在ImageNet-to-ImageNet-C任务上的对比评估(“Original”表示该方法是否修改模型原始训练流程)
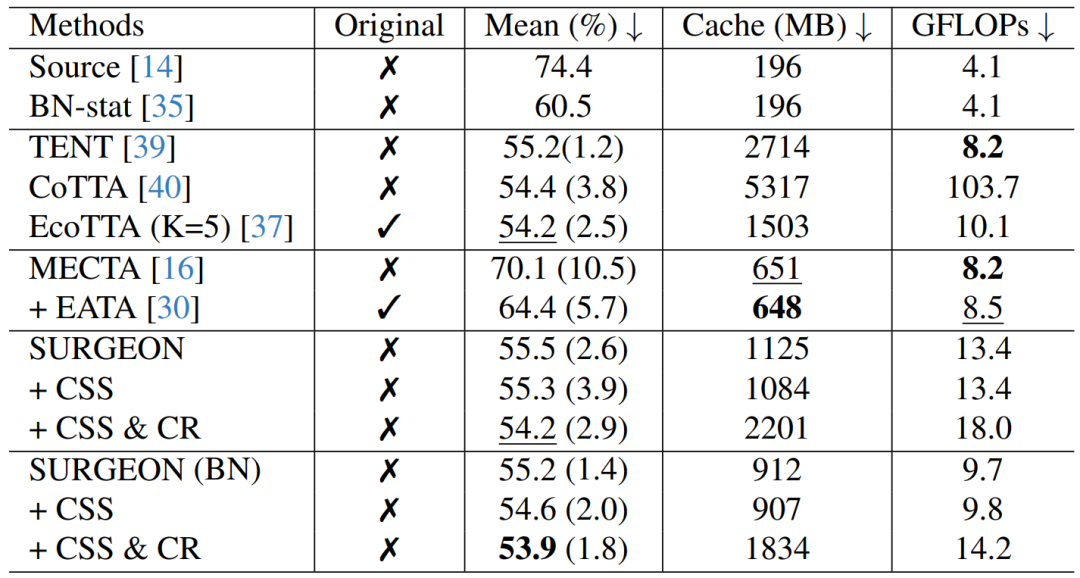
表3. 在Cityscapes-to-ACDC任务上的对比评估
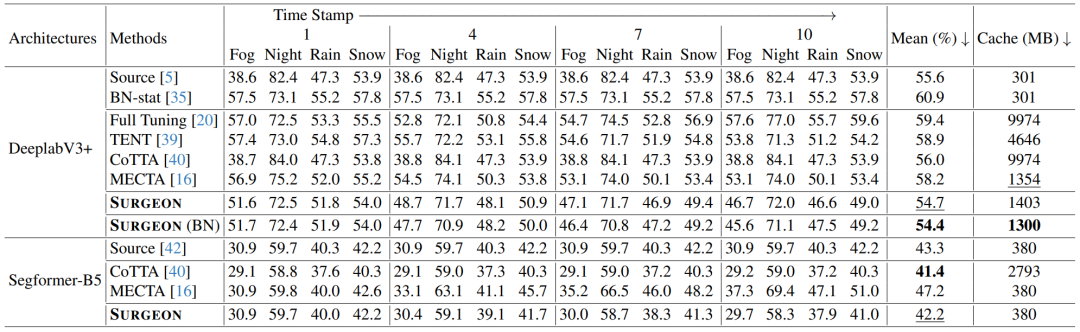
实验结果表明,SURGEON可与可插拔的测试时域自适应策略(如基于置信度的样本选择Certainty-based Sample Selection和一致性正则化Consistency Regularization)兼容,并在精度与内存开销之间实现了最优平衡。
此外,SURGEON无需访问训练数据或修改训练流程,便可在多种架构与任务中展现出优异性能。其用于层级重要性评估的额外计算过程也被验证为计算开销可接受。
4.2 动态稀疏激活的有效性验证
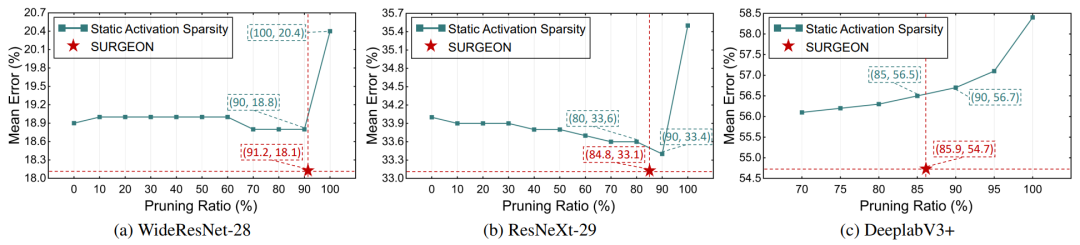
为验证动态激活稀疏策略的有效性,研究团队将其与统一裁剪率的静态稀疏策略进行对比。在表4中,SURGEON的裁剪比例由产生相同内存开销的静态裁剪率代替。实验显示,SURGEON能够更有效地捕捉各层的学习能力与内存占用差异,从而在同样资源约束下实现更优的适应性能。
4.3 层级重要性指标消融验证
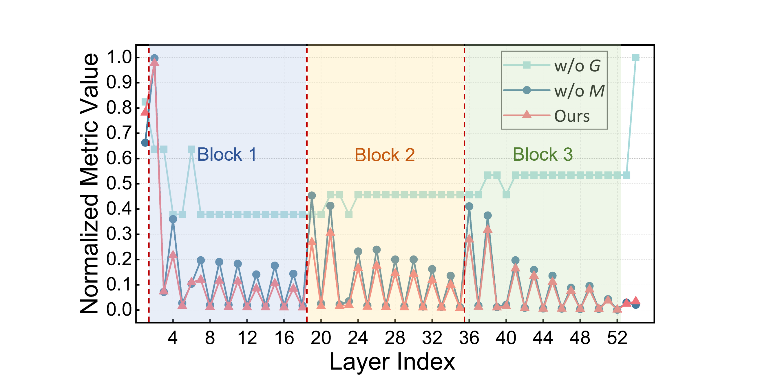
表4. 层级重要性指标消融效果对比

为进一步研究梯度重要性 与激活内存重要性 的贡献,,研究团队设计了相应的消融实验(见表4)。结果表明,SURGEON的层级重要性联合建模有效提升了动态激活稀疏的性能边界,在精度与内存开销之间形成了更优解。
图5进一步可视化了WideResNet-28在适应过程中的层级重要性指标,展示出不同层在精度贡献与内存使用上的显著差异。
5. 结论
本文提出了一种名为SURGEON的方法,旨在解决完全测试时自适应(FTTA)过程中的高内存开销问题,同时在不依赖特定网络结构和不修改原始训练流程的前提下,保持可比甚至更优的适应精度。
SURGEON的核心在于提出了一种新颖的动态激活稀疏性策略,该策略能够基于数据分布特性,以按层自适应的稀疏比例对中间激活进行裁剪,从而精确调控各层在适应过程中的内存消耗与权重更新。
实验结果表明,SURGEON在多个数据集、网络架构与任务上均实现了在精度与内存开销之间的最优平衡。该研究旨在推动深度模型在资源受限设备中的稳健部署,适应不断变化的真实环境。未来的工作将进一步探索动态激活稀疏策略在更多任务中的适应能力,并尝试与其它系统级内存优化方法相结合,持续提升整体内存效率。
(文:极市干货)