

今天是2025年7月10日,星期四,北京,雨过天晴。
近期国外开源了不少有趣的模型,大的小的都有,还有对deepseek-r1的魔改,这里做个汇总,包括:SmolLM3小模型、T5Gemma模型、NextCoder-32B模型、DeepSeek-TNG-R1T2-Chimera专家组合模型,一共4 个模型。
尤其是,其中用到的模型合并方案,看来已经是广泛采用了。
为什么这流行,是因为其可以在无需集成计算开销或额外训练的情况下,结合不同模型的优势,在开源工具方面,比较流行的是MergeKit库(https://github.com/arcee-ai/mergekit),来执行模型合并,其包含了多种合并方法,包括线性和非线性合并,可关注。
我们梳理这两个话题。
一、近期4个开源大模型进展跟进
这些模型发布出来都有自己的特点,所以,可以看看他们各自的方案,都很有趣。
1、SmolLM3小模型
Hugging Face开源3B参数模型SmolLM3,在评测上,性能超越Llama-3.2-3B和Qwen2.5-3B【学术评测不具有一般性】。
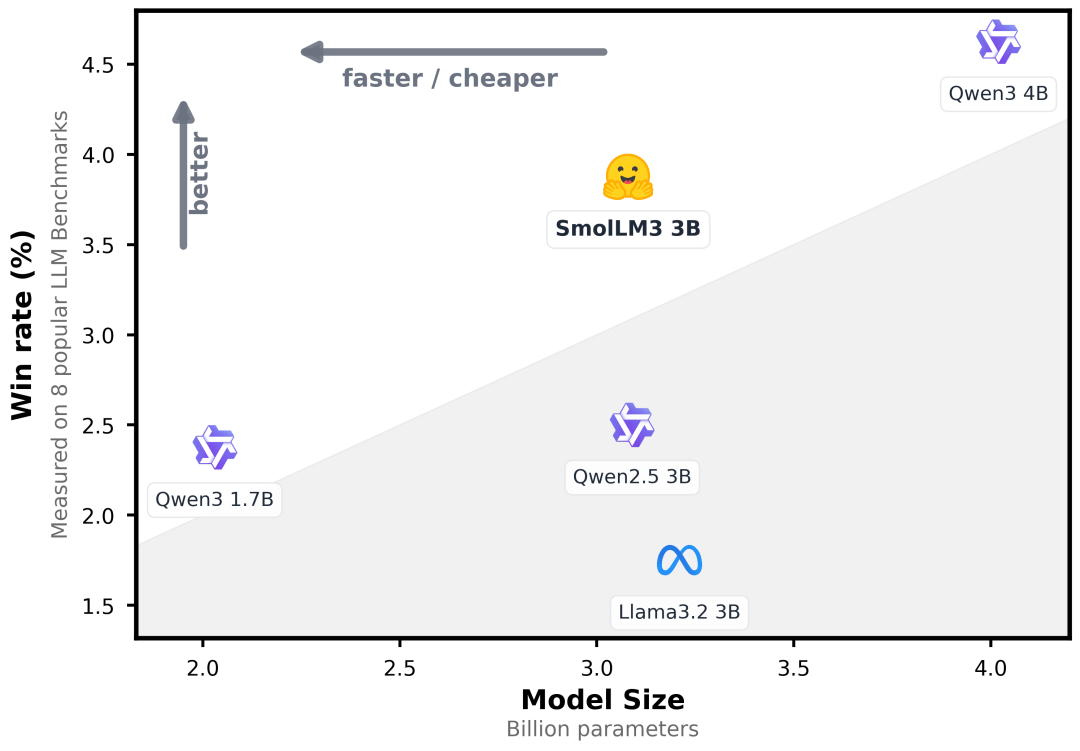
架构方面,仅使用解码器的Transformer,使用了GQA和NoPE(比例为3:1),并在11.2T的token上进行了预训练,其内容包括网络、代码、数学和推理数据等分阶段课程学习;
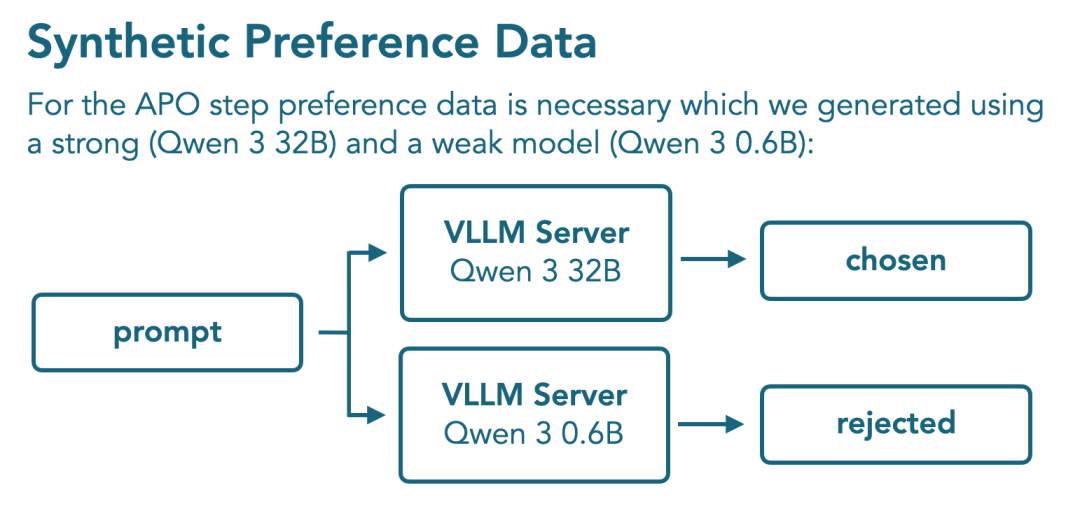
后期训练包括使用140B推理token进行中期训练,然后通过锚定偏好优化(APO)进行监督微调和对齐。
特点方面,支持128K上下文窗口及6种语言;模型采用双模式系统,用户可通过标志在深度思考和非思考模式间灵活切换;
采用三阶段混合训练策略,在11.2万亿tokens上训练,并开放架构细节、数据混合方式等全部技术细节,细节地址在:https://huggingface.co/blog/smollm3
然后,在模型合并方面,取每个APO检查点并创建一个模型“混合体”,将模型混合体与具有强大长内容性能的中期训练检查点相结合。对于APO模型混合体和中期训练检查点,分别使用0.9和0.1的权重进行线性合并,取得了最佳性能。
地址方面,基础模型在:https://huggingface.co/HuggingFaceTB/SmolLM3-3B-Base;推理模型在https://huggingface.co/HuggingFaceTB/SmolLM3-3B
2、T5Gemma模型
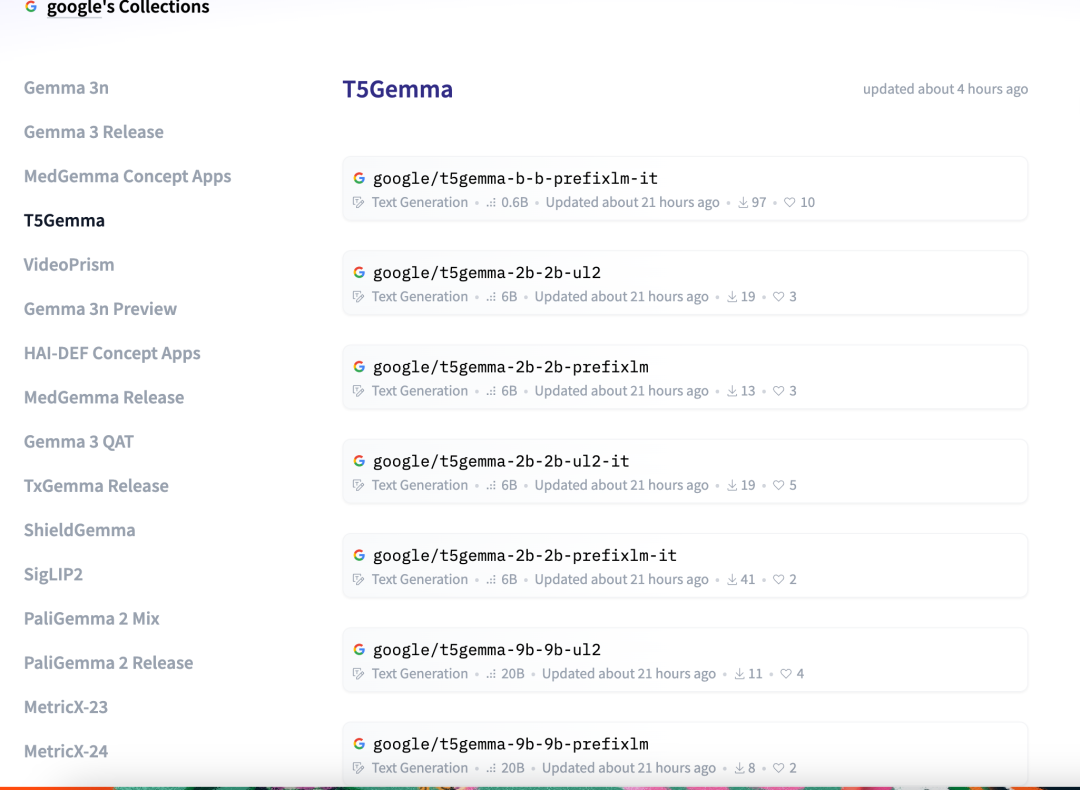
Google发布T5Gemma,新的编码器-解码器(encoder-decoder)架构的大模型,有32个衍生版本。
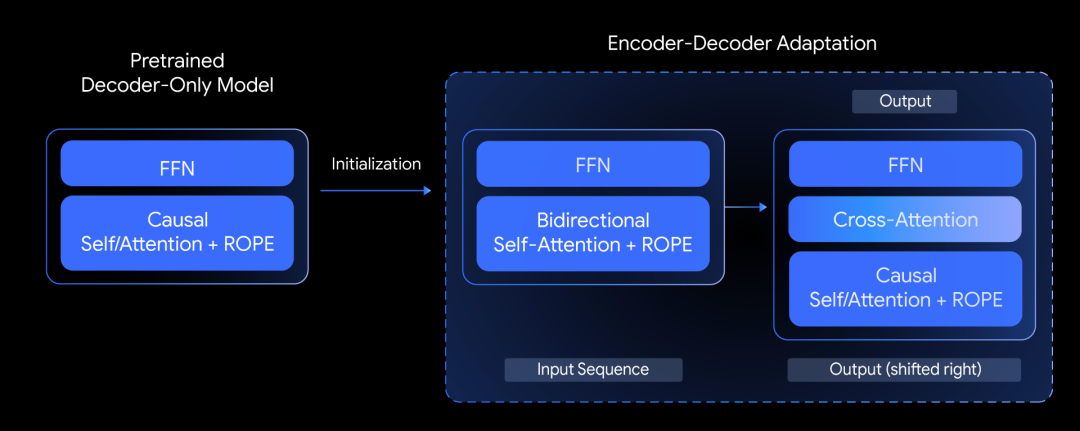
从实现上,通过将预训练的纯解码器模型改编为编码器-解码器,这种改编使T5Gemma能够继承纯解码器模型的基础功能,同时提供更优的质量效率权衡,其关键特性之一是可以灵活地将不同大小的编码器和解码器配对(例如,9B编码器与2B解码器),适合各种生成性任务,包括问答、摘要和推理。
包括两个系列:
Gemma2系列,直接改编自官方Gemma22B和9B检查点的模型,包括2B-2B、9B-9B和9B-2B变体
T5系列,使用Gemma2从头开始预训练的模型,但其架构和参数数量与传统T5模型(小型、基础、大型、超大)保持一致。T5Gemma模型
模型地址在https://huggingface.co/collections/google/t5gemma-686ba262fe290b881d21ec86;
技术报告在:https://developers.googleblog.com/en/t5gemma/
3、NextCoder-32B模型
微软发布的一个32B模型,在Qwen2.5-CoderInstruct基础上修改,其中提到了一种新型选择性知识迁移 (Selective Knowledge Transfer) 微调方法。
采用的魔改方法包括SeleKT后训练,以及魔改为带有RoPE、SwiGLU、RMSNorm和AttentionQKV偏置的transformers,详细论文在https://www.microsoft.com/en-us/research/publication/nextcoder-robust-adaptation-of-code-lms-to-diverse-code-edits/
地址在:https://huggingface.co/microsoft/NextCoder-32B。
4、DeepSeek-TNG-R1T2-Chimera专家组合模型
TNG这个公司在4月26日发布了原版DeepSeekR1TChimera(https://huggingface.co/tngtech/DeepSeek-R1T-Chimera),合并DeepSeek-R1 和 DeepSeek-V3 的模型权重(0324)。
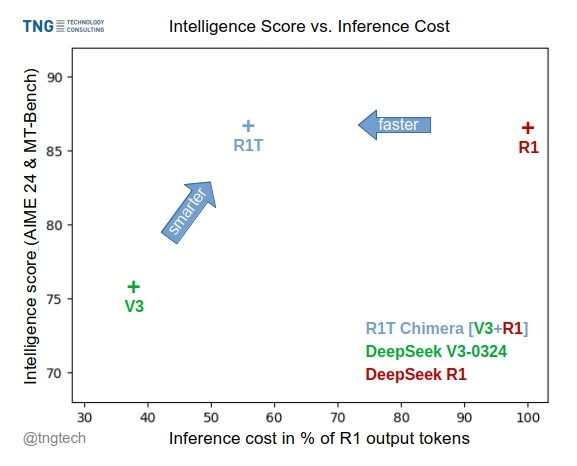
具体做法在:《Assembly of Experts: Linear-time construction of the ChimeraLLM variants with emergent and adaptable behaviors》,https://arxiv.org/abs/2506.14794,
DeepSeek-TNG-R1T2-Chimera,为第二个版本,拥有三个父模型,包括DeepSeekR1-0528、DeepSeekR1-R1和DeepSeekR1-V3-0324,基于这三个模型进行组装。
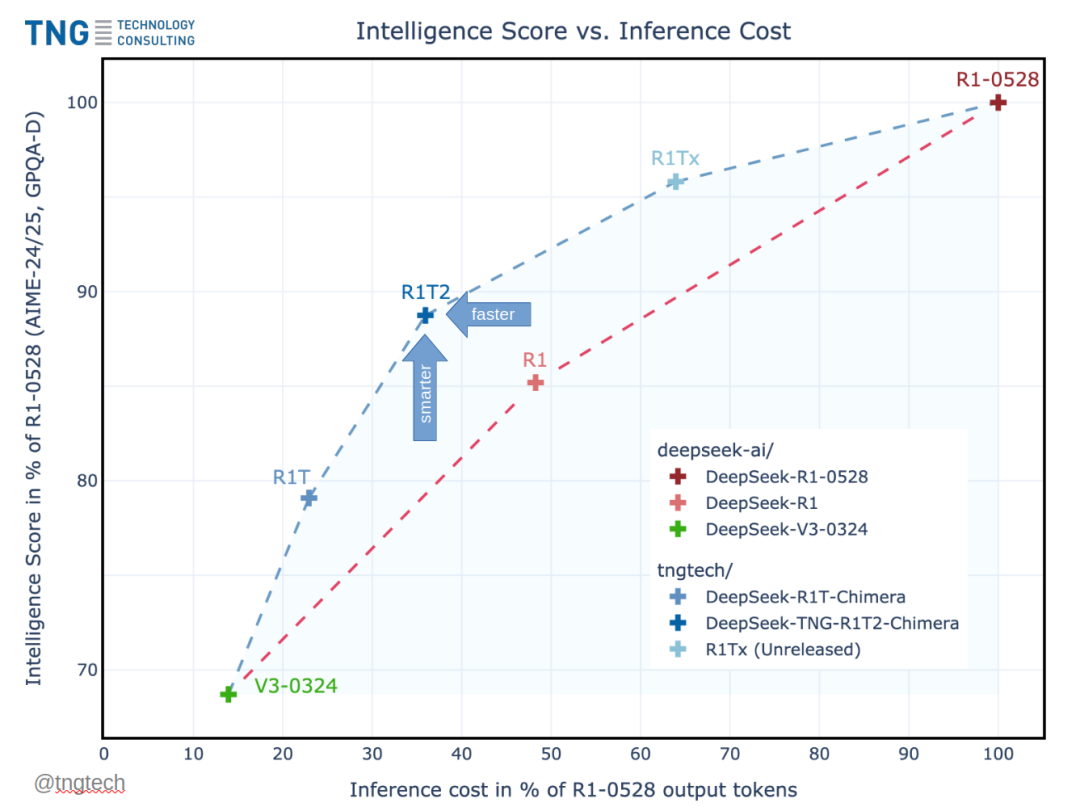
具体的地址在:https://huggingface.co/tngtech/DeepSeek-TNG-R1T2-Chimera,
二、开源模型合并模型MergeKit
模型合并可以在无需集成计算开销或额外训练的情况下,结合不同模型的优势,开源工具方面,比较流行的是MergeKit库(https://github.com/arcee-ai/mergekit/blob/main/README.md),来执行模型合并,其包含了多种合并方法,包括线性和非线性合并。
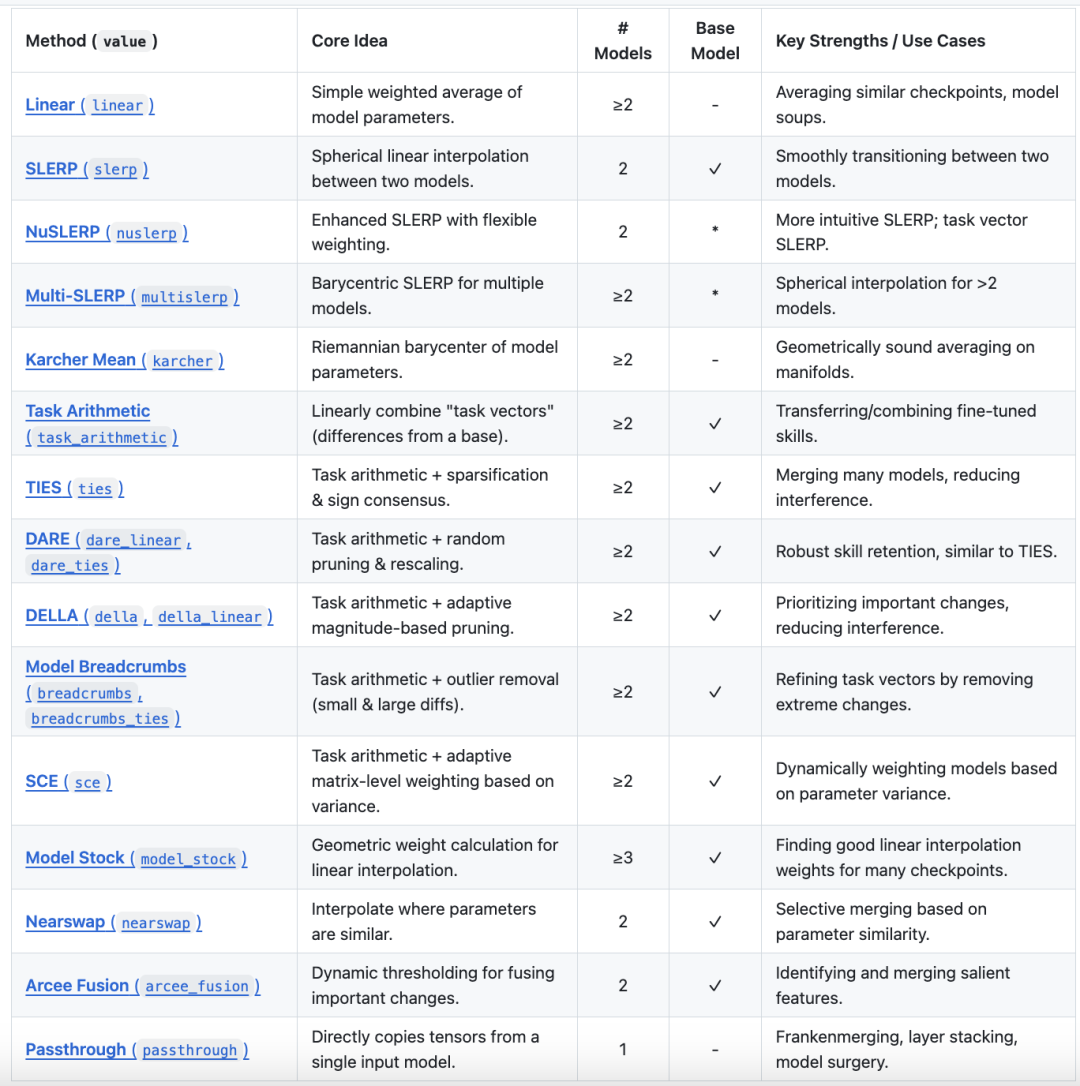
至于有什么优势,怎么做,在其readme中也有描述,可以直接跟进。
参考文献
1、https://github.com/arcee-ai/mergekit/blob/main/README.md
(文:老刘说NLP)