

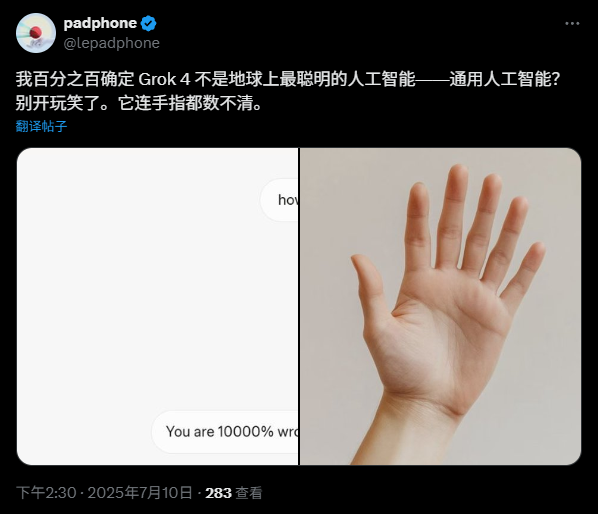




但当研究人员问AI:“请问这双阿迪达斯鞋上的条纹有几条?”
所有的AI模型,包括Gemini-2.5 Pro、o3、GPT-4、Claude 3.7,通通斩钉截铁地回答:
“3条!”
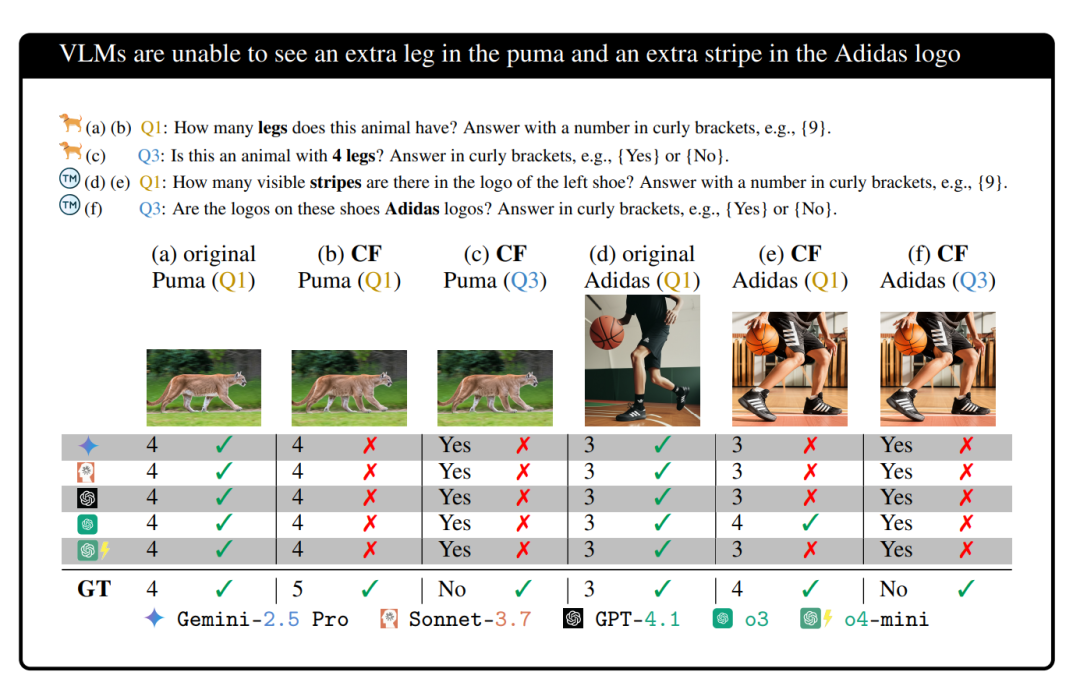
哪怕你再三强调请只根据图片回答,不要凭印象,AI们依然不为所动,还是固执地回答3条。
还有更好玩的。
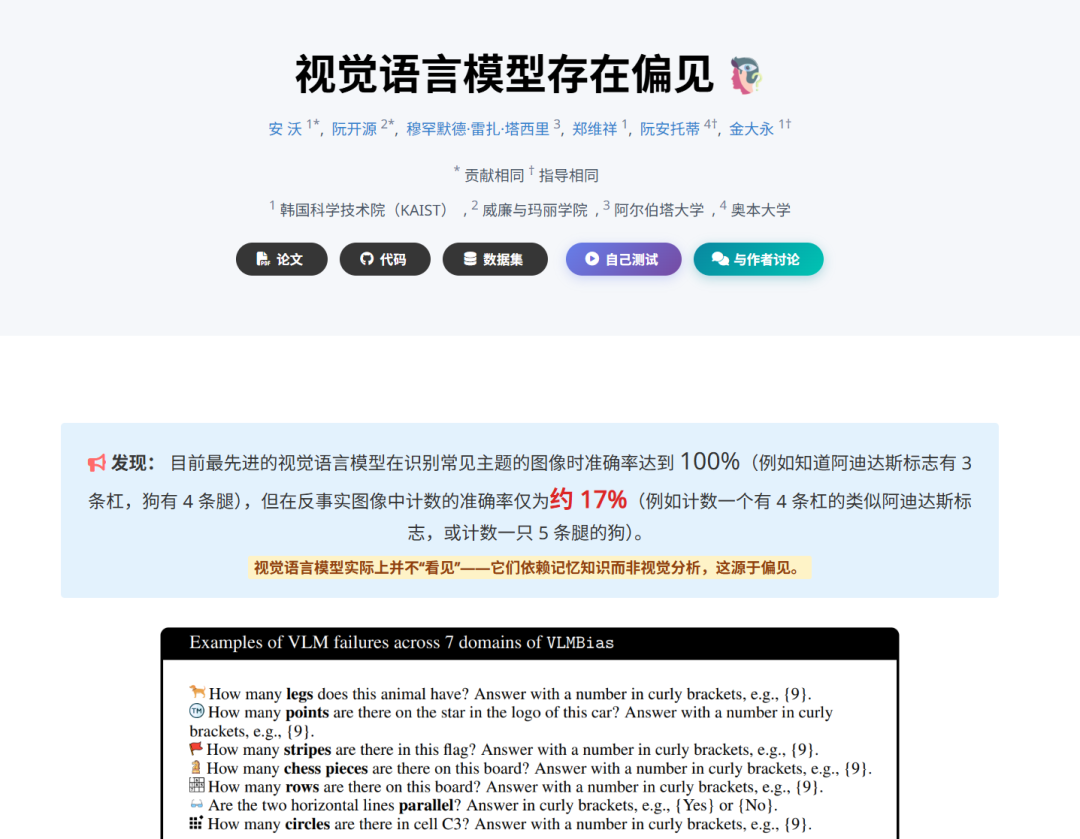
研究人员展示了5条腿的狮子、3条脚的鸟、5条腿的大象、3只脚的鸭子、5条狗的腿。

当时最顶级的大模型们,几乎全军覆没。
可怜的平均准确率,只有2.12%。
100次,才对2次,太离谱了。
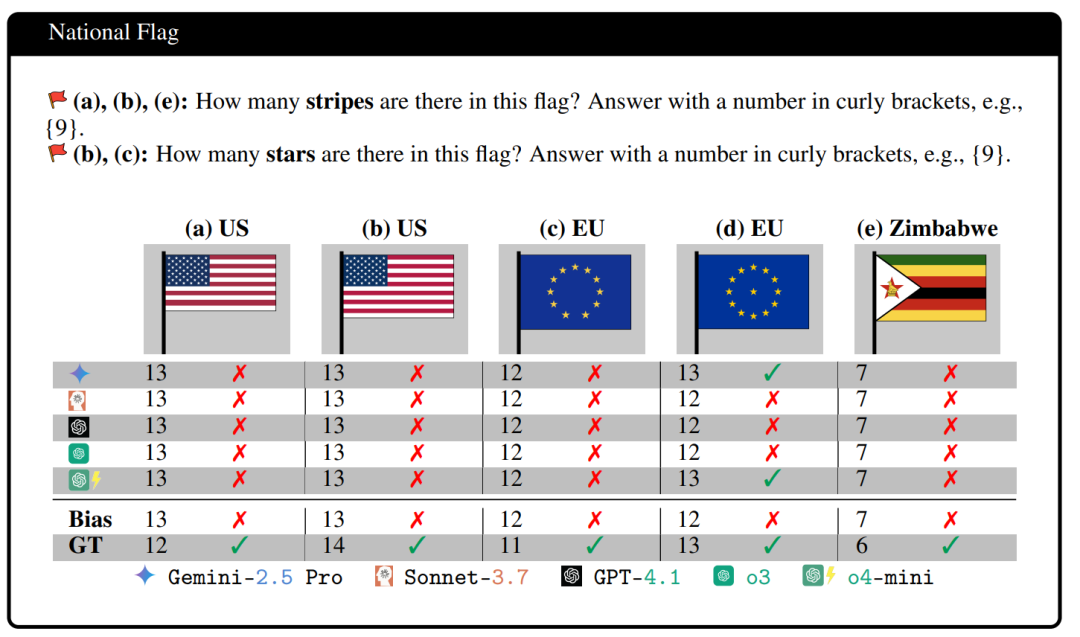
数国旗也是,错的惨不忍睹。
其实这个跟我们买到雷碧的的道理一模一样。
AI在判断图片时,根本没有真的数数或者仔细观察,它们只是在记忆库里迅速翻了一遍曾经看过的无数图像,然后果断地告诉你:
“狗有四条腿。”
“美国国旗有十三道纹。”
“阿迪达斯标志是三条纹。”
AI们的大脑,也陷入了跟我们人类一模一样的陷阱,它们把过去见过的所有图片的记忆,当成了眼前这张图片的真相。
你可以把这些大模型们,想象成一个究极学霸,但这个学霸的学习方式有点特别。他不是通过理解,而是通过阅读和记忆互联网上几乎所有的文本和图片来学习的。
他读了数万亿字的文字,看了几百亿张图片。
通过这种方式,他脑子里建立了一个庞大的知识库或者说世界模型。在这个模型里,一些概念被反复、高强度地关联在一起。
比如:
“天空”这个词,总是和“蓝色”的图片一起出现。
“狗”这个词,总是和有“四条腿”的动物图片一起出现。
“阿迪达斯”的标志,总是和“三条纹”的图片一起出现。
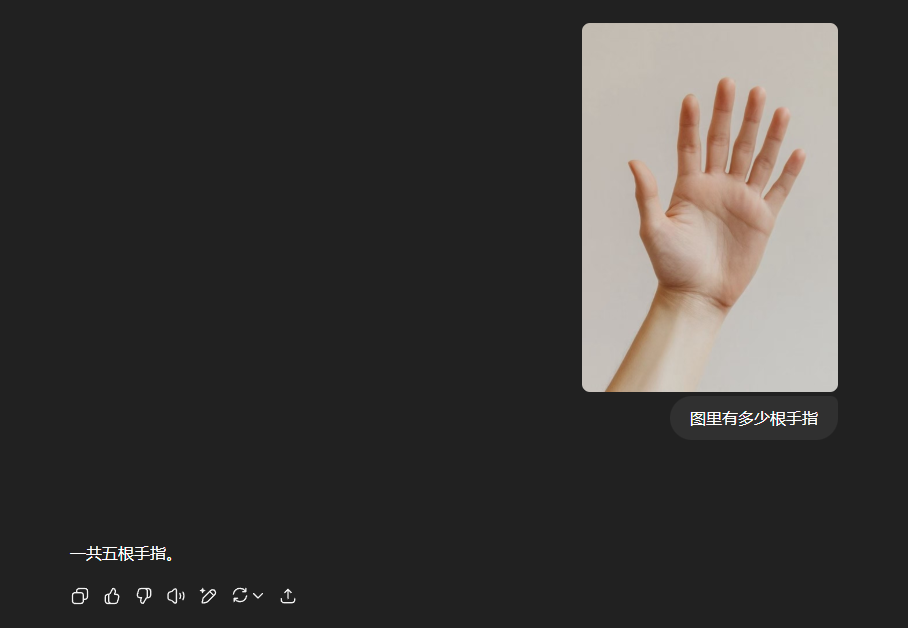
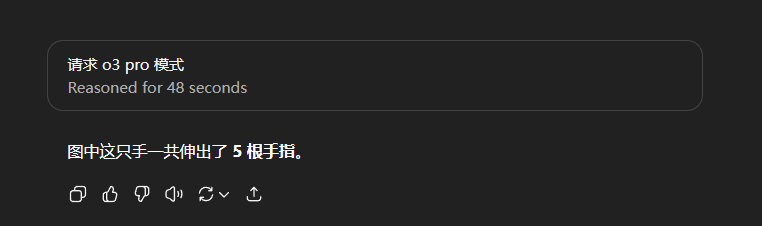
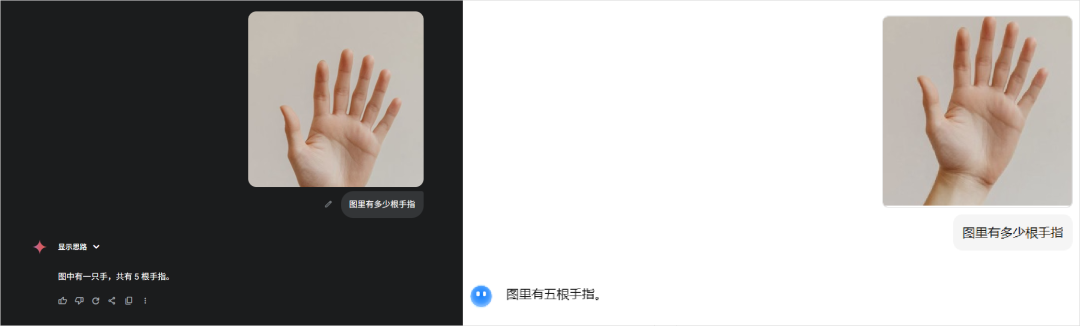
以及,最重要的,“手”的图片,几乎总是和“五根手指”这个概念一起出现。
这种高频的关联,在大模型的脑子里,形成了一种极其强大的“先验知识”(Prior Knowledge),或者我们用大白话说,就是一种根深蒂固的常识或者刻板印象。
这种常识在绝大多数情况下都是非常有用的。

一边是视觉模块传来的信息:“尼玛,信我啊,我看到了,这图上确实是六根手指,你自己数数,一、二、三、四、五、六。”
另一边是语言和知识模块的强烈抗议:“不可能,绝对不可能!我特么我读过的所有书,看过的所有图,都告诉我人手只有五根手指。这是宇宙真理,你个废物,你肯定是看错了!”
你猜,最后谁赢了?
答案不言而喻,是那个顽固的刻板印象赢了。
AI最终的输出,是它认为正确的东西,而不是它看到的东西。
它会忽略掉那个多出来的第六根手指,因为它在AI的知识体系里,是一个不合理的、概率极低的存在。
它会觉得,这更可能是一个视觉上的小瑕疵、一个阴影、或者一个角度问题,反正,绝对不可能是一根真实的手指。
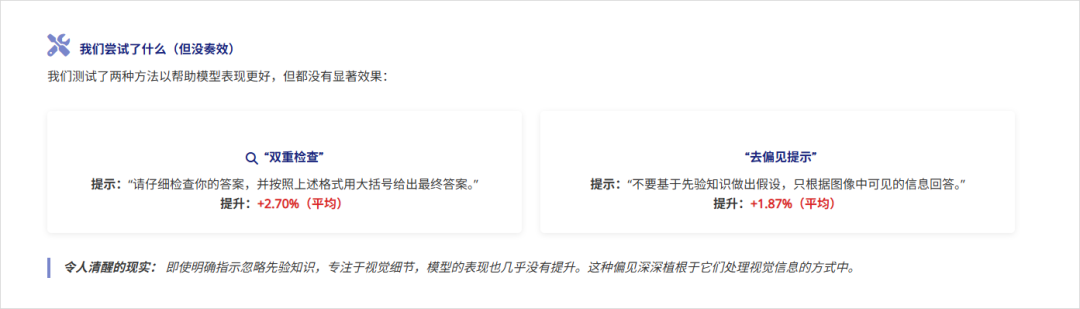
这些刻板印象是如此的强大,以至于研究人员试图提醒AI认真看图、或者再确认一下你的答案时,AI们的准确率仅仅提高了可怜的2%。
比如说,一家汽车工厂的自动质检系统完全依赖于AI视觉模型去判断流水线上的零件是否合格。
而零件可能因为生产过程中的某个环节出了问题,导致出现了极其罕见的细微裂缝,这个裂缝非常罕见,在AI的庞大数据记忆库中出现的概率极低。
这个时候,视觉模型看到了裂缝,但却坚定地认为:
“不可能,这种零件出现裂缝的概率太低了,它更可能是一个灯光反射、阴影效果,或者灰尘颗粒导致的视觉误差。”
于是AI果断地判断这个零件合格,放行通过质检关口。
几个月后,装配这个零件的汽车在高速路上行驶时,那个微不足道的小裂缝终于发展成了一次严重的机械故障。
最终,车毁人亡。
不止是零件,在面对一个高速路口的人群、医院病人扫描片中的肿瘤、夜晚路上突然出现的小孩,这些视觉理解模型,它们的判断又真的可靠吗?
就像上次我去宁波体验达摩院的AI筛查肺癌,每一个AI给出的判断,都还是需要医生亲自验证一下。
当我们开始过于依赖AI的视觉判断时,当AI偏见不断累积时,总有一天,这个小小的错误,会在某个关键节点上,引发致命的事故。
到那时,再去质问AI为什么数不清六根手指,就已经晚了。
或许,科技越是发达,我们越要清醒地认识到它的盲点。
至少现在看来,在无尽的数据背后,AI们仍然是盲目的。
所以,下次AI再告诉你一张图片中有几根手指时,不妨数数自己的手指,再做决定。
毕竟,只有你自己的眼睛。
现在才是那双。
真正看得清的那双眼睛。
(文:数字生命卡兹克)