

机器之心编辑部
所有学科都是博士后水平。
酝酿良久的 xAI 下一代大模型——Grok 4 终于发布了!能力超乎我们想象。
北京时间今天中午 12 点左右,我们期待已久的 xAI 发布会终于开始,马斯克现身直播间,他上来就说:「这是世界上最好的 AI,让我们来展示一下。」

马斯克表示,Grok 4 每次都能在 SAT 考试(美国高考)中获得满分,无需事先查看题目,它也可以做到 GRE 任何学科接近满分,超过了全世界所有研究生的水平。Grok 4 最强大的地方是其推理能力,它已经实现了超越人类的推理水平。
马斯克相信,Grok 4 可以在今年内实现科学新发现。
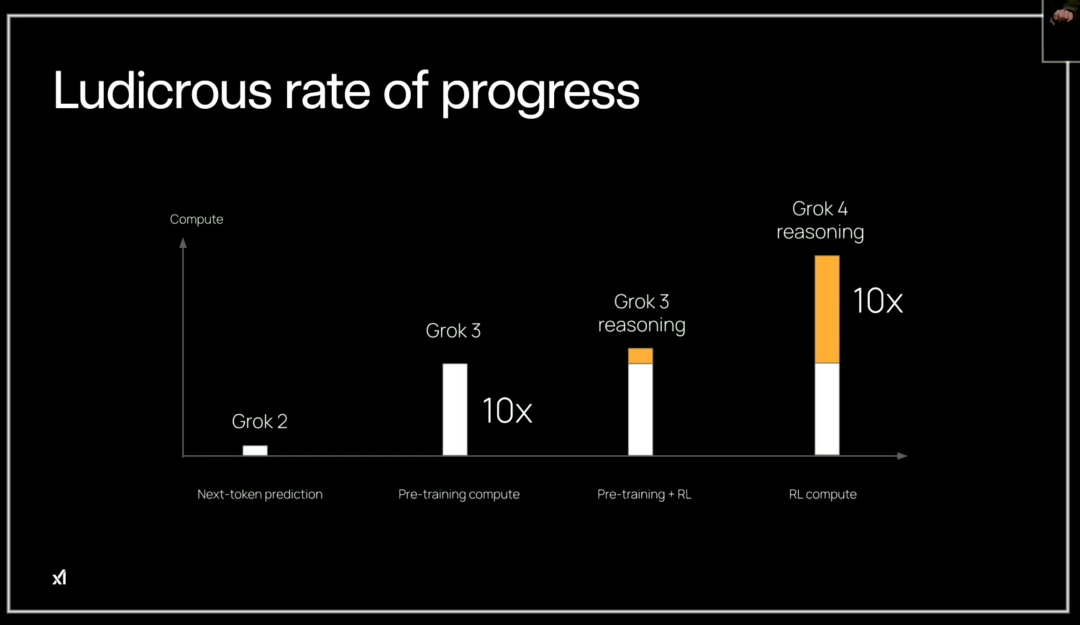
得益于计算能力的增强、强化学习的训练,Grok 4 的推理能力相较于前代提升了 10 倍。从 Grok 2 到 Grok 4,采用的技术范式不同,分别为下一个 token 预测、预训练计算、预训练 + RL、RL 计算。
其中,Grok 2 到 Grok 3 预训练阶段的计算量提升了 10 倍,Grok 3 reasoning 首次引入了 RL 微调,带来了深度推理能力。Grok 4 reasoning 的强化学习再度提升了 10 倍的计算量,这意味着显著的推理能力提升。
另外因为调用工具能力的提升,Grok 4 进一步放大了自身智慧。因此可以在各类高难度 Benchmark 上实现远超 SOTA 的成绩。
接下来是重头戏:Grok 4 的基准测试结果。
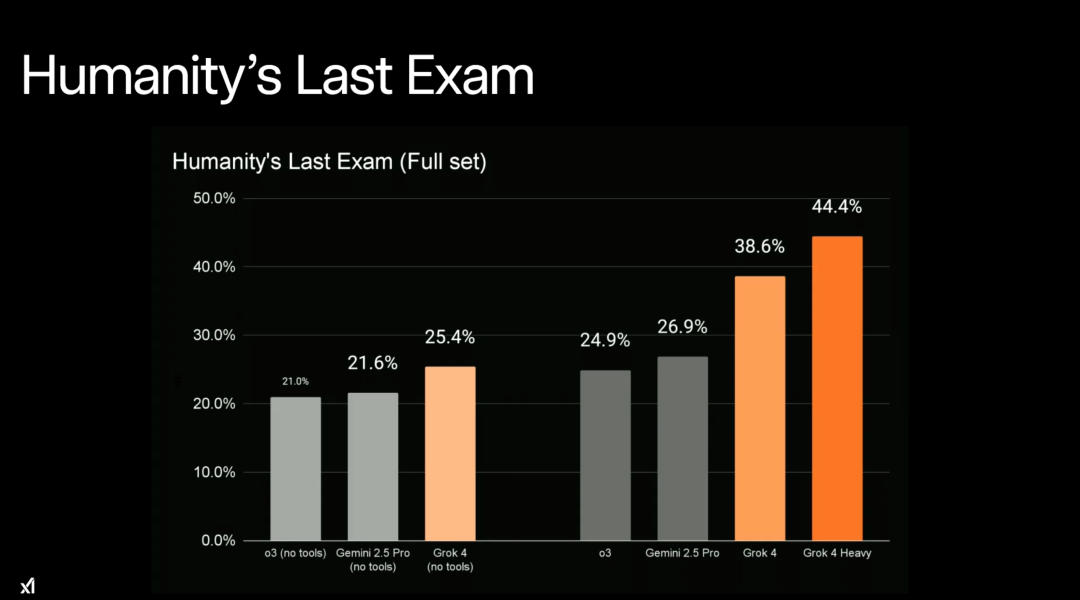
首先是 HLE(Humanities Last Exam,人类最后的考试),包括数学、化学和逻辑学。在上周六泄露的基准测试结果中,Grok 4 在 HLE(Humanities Last Exam,人类最后考试)上的标准得分是 35%,使用推理技术后提高到 45%,但多数网友持质疑态度。
在今天的直播中,xAI 研究人员表示,以往的 SOTA 模型在使用工具(with tool)的情况下,成绩最高可以达到 41.0%。
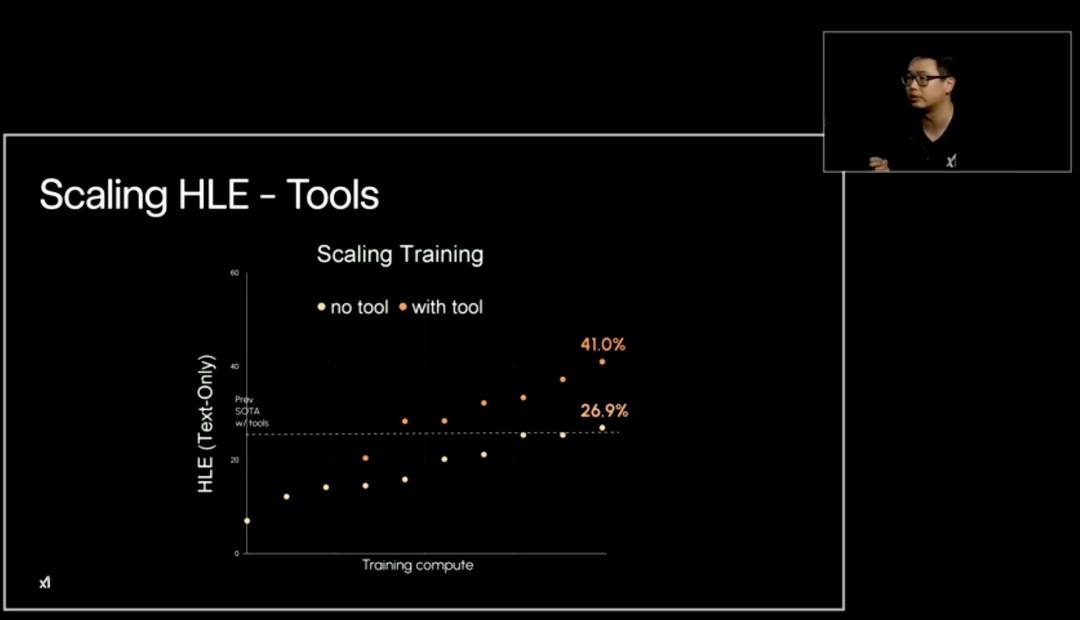
如今,Grok 4 进一步提升了这一基准测试成绩。
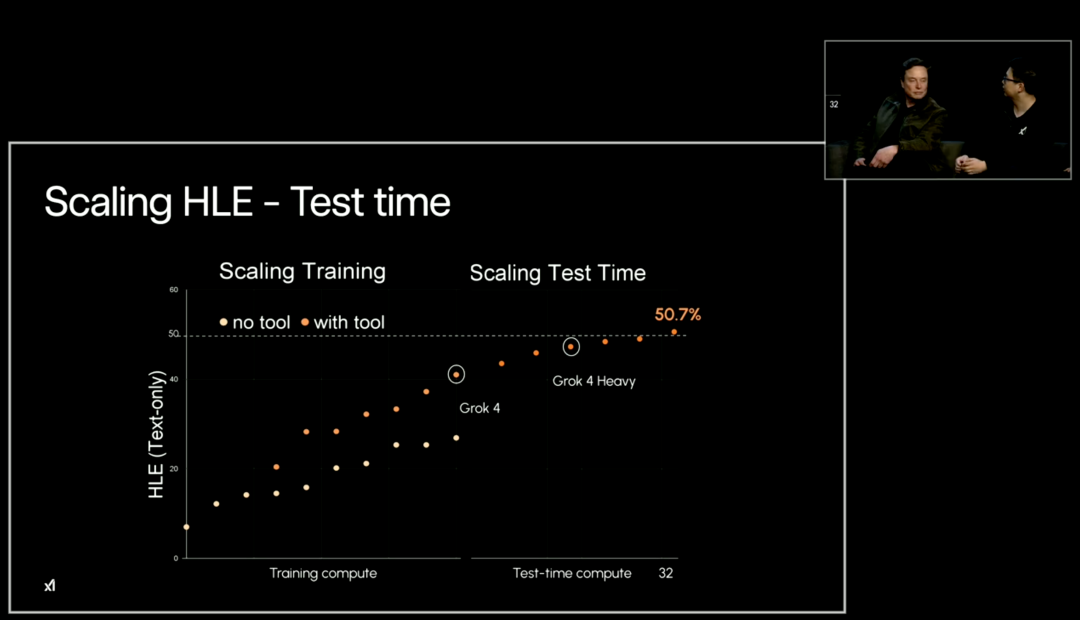
具体来讲,与其他 SOTA 模型(o3、Gemini 2.5 Pro)相比,在使用工具的情况下,Grok 4 的成绩为 38.6%,Grok 4 Heavy 的成绩飙升到了 44.4%。如果让大模型在测试时花费更多时间思考,并恰当的使用更多外部工具,则 HLE 的分数还能进一步提升到 50.7%。
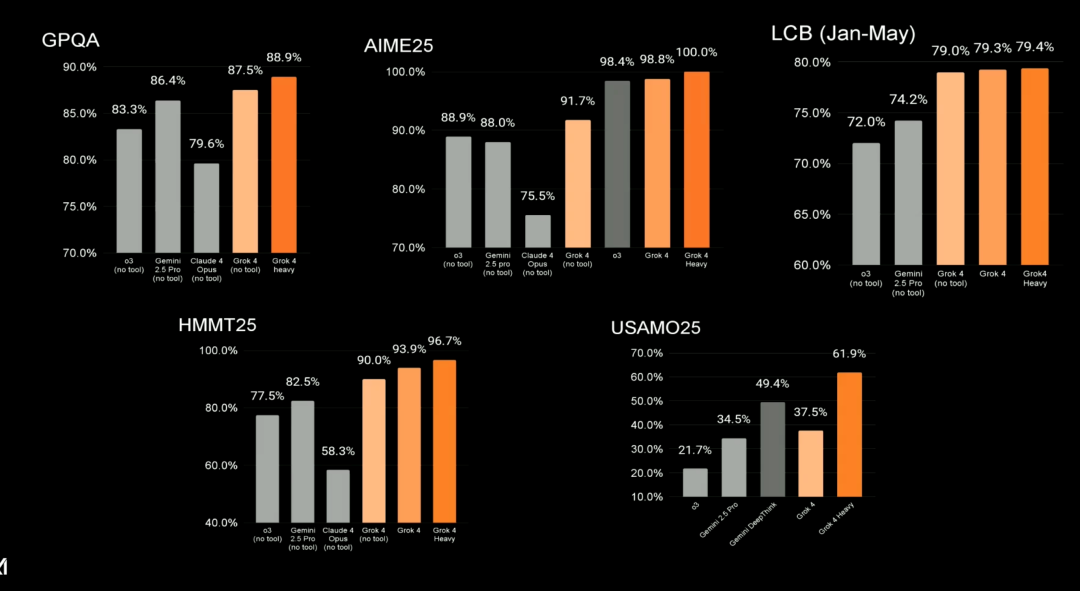
关于其他更多基准测试结果,包括 GPQA(研究生级别的 Google 验证问答基准测试)、AIME25(美国数学竞赛邀请赛)、LCB(Jan-May)(编程竞赛 / 在线算法竞赛)、HMMT25(高中生团队数学竞赛)和 USAMO25(美国顶级高中生数学竞赛)。从下图可以看到,Grok 4 Heavy 均取得了最新 SOTA。
相比之下,人类面对 HLE 测试也几乎答不上几个题。马斯克多遍强调:Grok 现在在所有学科都达到了博士后水平,没有例外。它没有发现新科学或是新的物理定律,但这只是一个时间问题。
「如果 Grok 在今年内没有发现实用的新科学技术,我会感觉很意外,」马斯克表示。
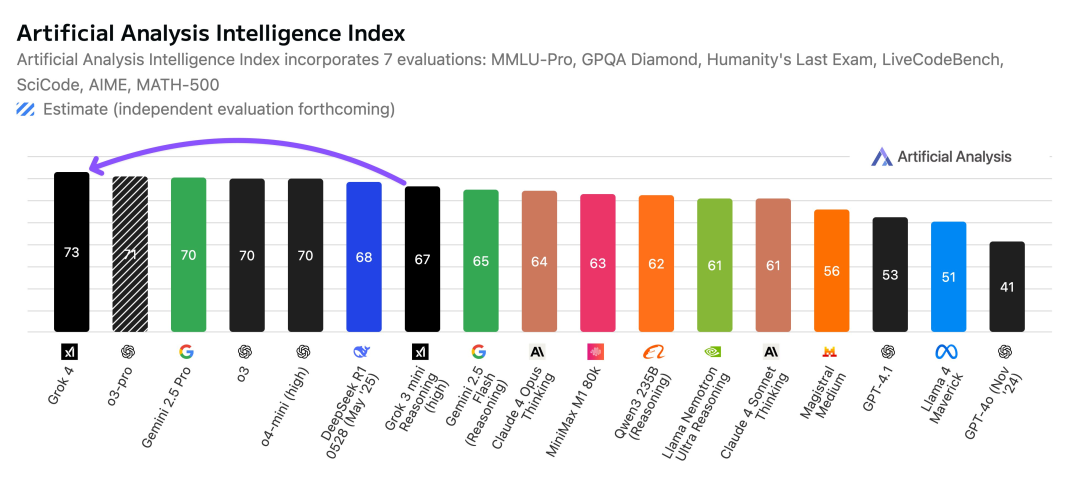
大模型性能评估平台 Artificial Analysis 的全套基准测试成绩表明,Grok 4 已经成为当前领先的 AI 模型,总成绩达到了 73 分,领先于 o3、Gemini 2.5 Pro、Claude 4 Opus、DeepSeek R1 0528。

想象一下我们现在处在的位置,我们正处于智能发展的大爆炸过程中,这是人类历史上前所未见的。是时候看看 Grok 4 具体能做些什么了。
我们来看一两个 demo,比如「基于物理原理的 HTML 动画,模拟两个黑洞碰撞并产生引力波的 30 秒可视化效果」:
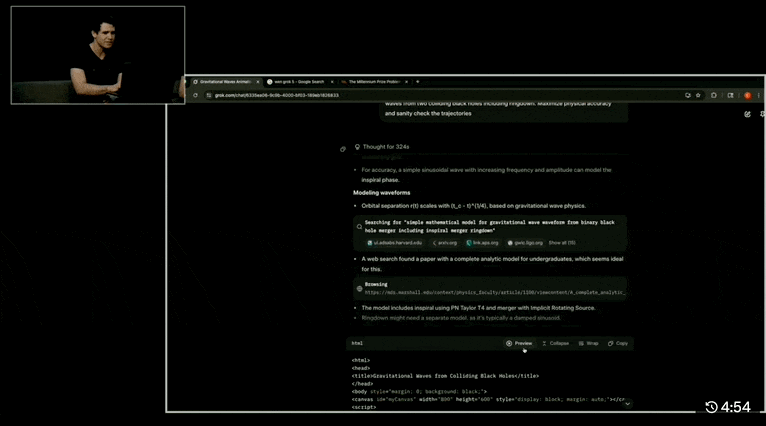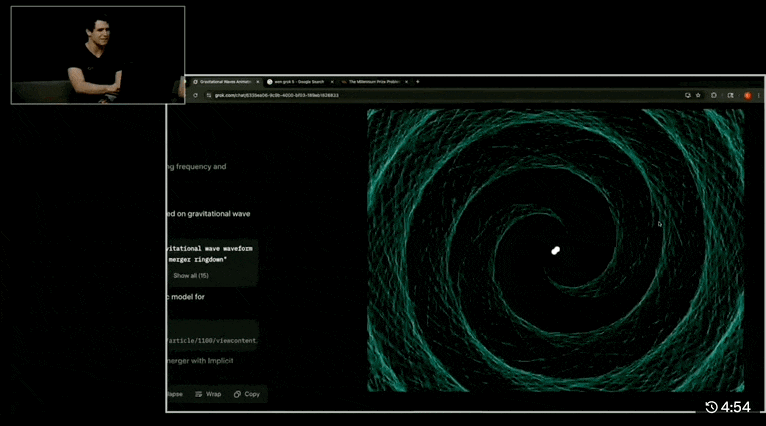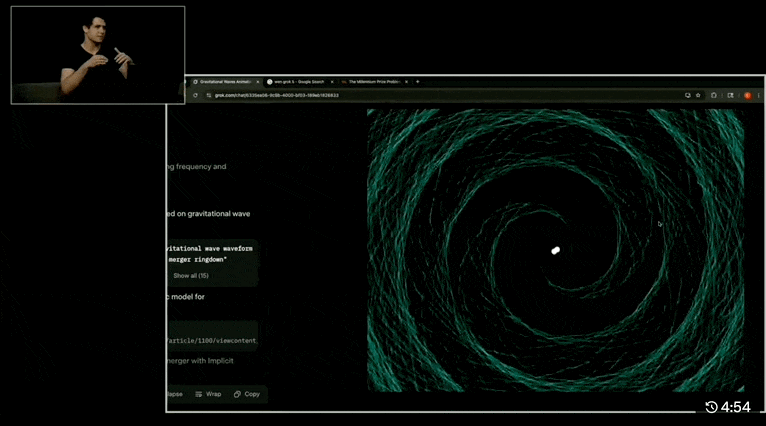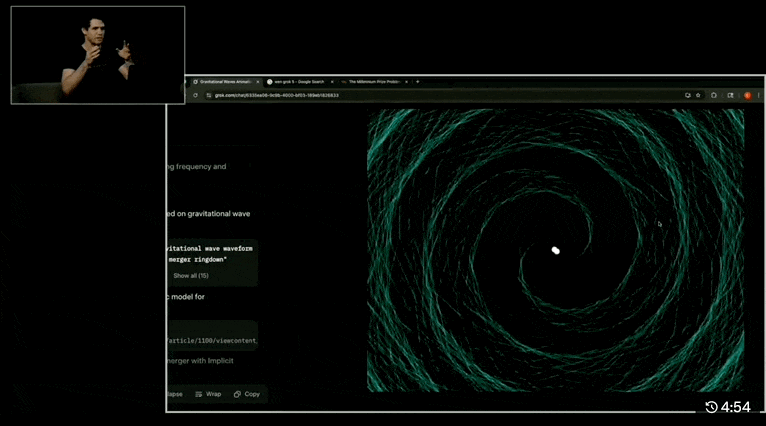
Grok 4 几乎完整地呈现了从两个黑洞接近到最后合并结束的引力波模拟效果。动图的一边是推理过程和计算的步骤和代码,查阅的论文每一篇都有链接。
Grok 4 的多面手属性更强了
除了各大语言基准成绩的提升,Grok 4 在其他方面同样得到了加强。
其中,Grok 4 的语音能力相较于上代速度快了 2 倍,端到端延迟更低;支持 5 种语音;单日用户总停留时长提升了 10 倍。

新增的 Grok 角色 Eve 和 Sal 现已可在 iOS 版 Grok 中使用,Sal 支持多种性格,Eve 可以唱歌和低语。

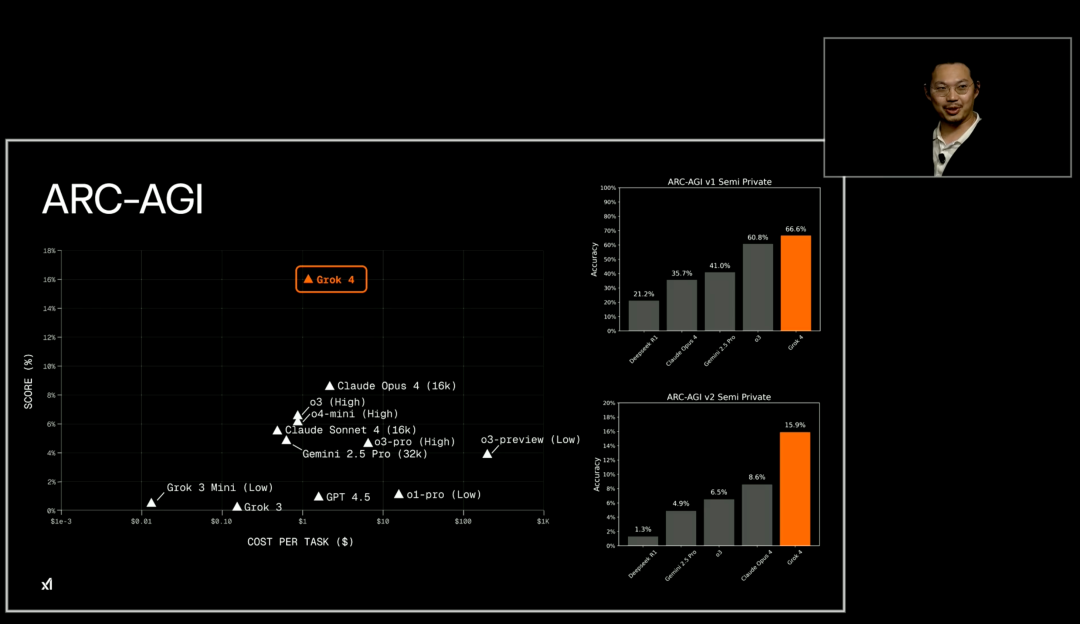
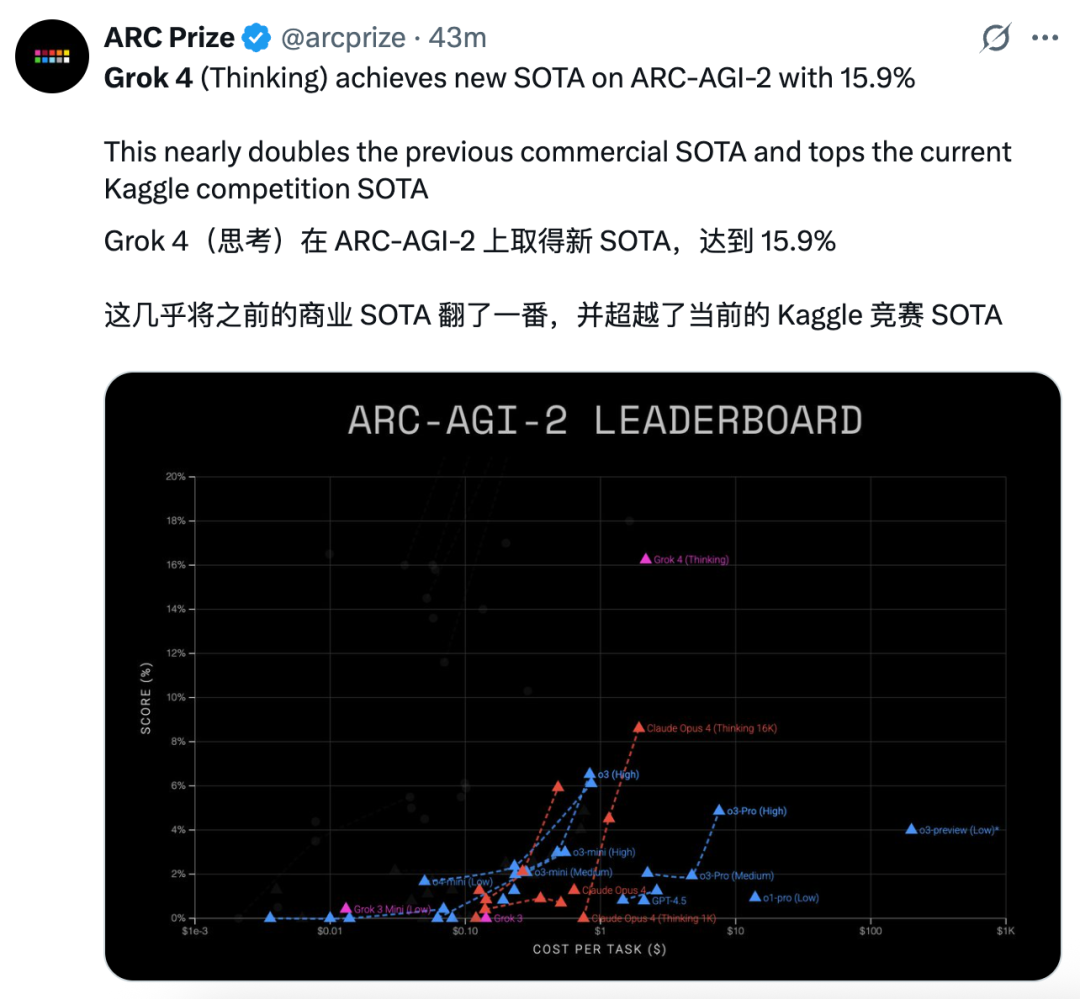
在 ARC-AGI 基准测试集中,它专门设计用于评估人工智能系统通用推理能力,被视为通向 AGI 的重要试金石,旨在检验模型是否能像人类一样灵活解决从未见过的新问题。
在这个直指 AGI 核心能力的超难基准上,Grok 4 同样取得了最新 SOTA,其中在 ARC-AGI-2 上达到 15.9%,几乎将之前的商业 SOTA 翻了一番,并超越了当前的 Kaggle 竞赛 SOTA。
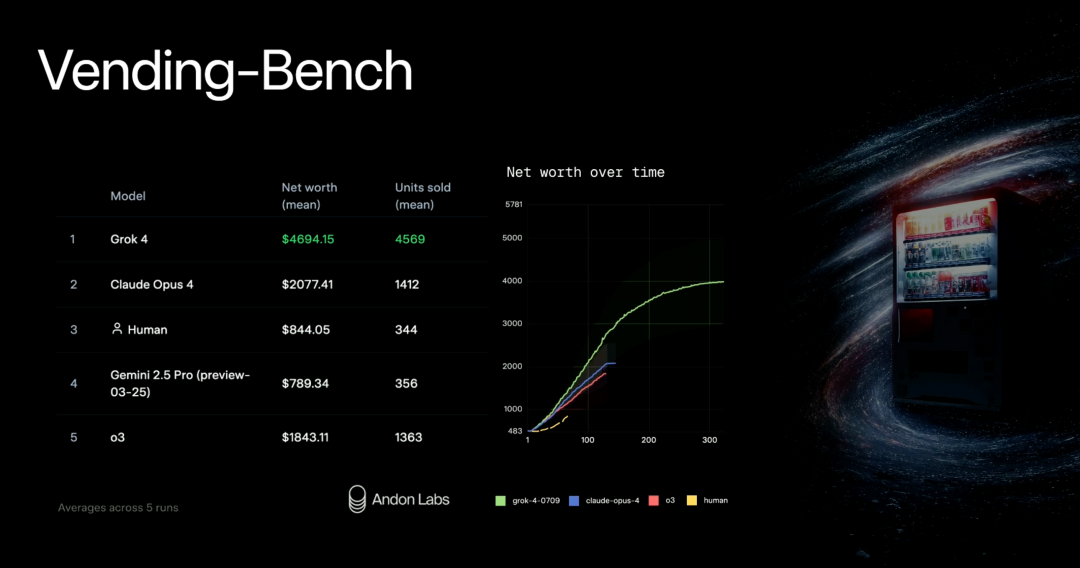
在 Vending-Bench 基准测试中,它专注于评估智能体在真实物理世界中执行复杂操作任务的能力,其核心目标是解决传统模拟环境(如 Habitat、AI2-THOR)与真实世界间的「Sim2Real Gap」(仿真到现实的鸿沟),推动机器人技术在开放场景中的实际应用能力。
可以看到,Grok 4 相较于 Claude Opus 4、Human、Gemini 2.5 Pro、o3 取得了领先。
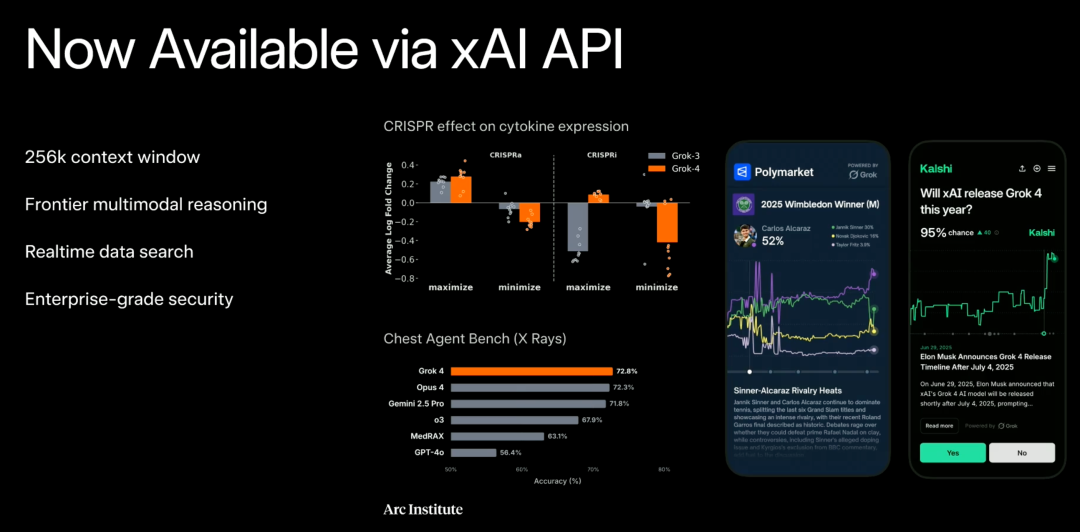
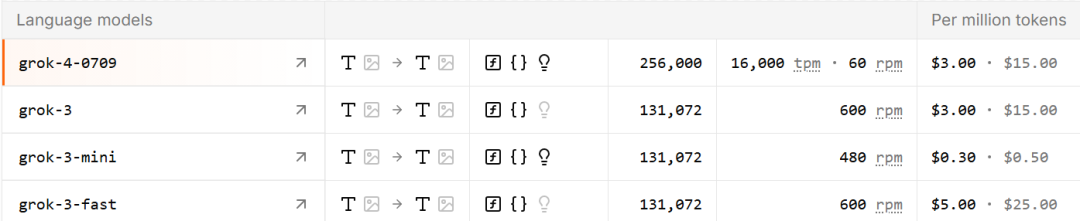
Grok 4 可通过 API 调用,提供 256K tokens 的上下文窗口。目前已经开放使用,版本号为 grok-4-0709,价格与 Grok 3 相同。
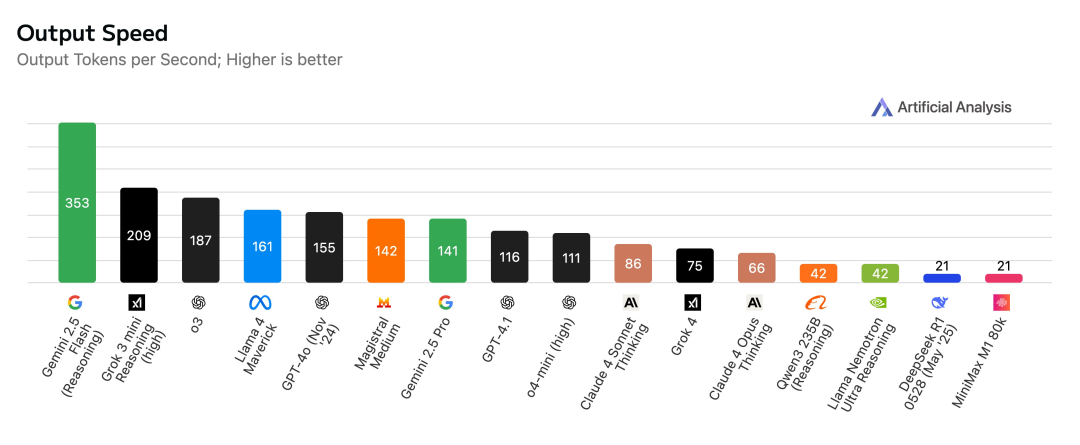
根据 Artificial Analysis 的测试,xAI 的 API 当前以每秒 75 个 token 的速度提供 Grok 4 服务,速度虽不及 o3(每秒 188 个 token),但优于 Claude 4 Opus Thinking(每秒 66 个 token)。
最后是游戏体验,DannyLimanseta 在 4 小时内用 Grok 4 制作了一款 FPS 射击游戏,Grok 不仅可以用于制作游戏,还能实际运行游戏,洞察优秀游戏的要素并提出改进建议。看着效果真的挺不错。
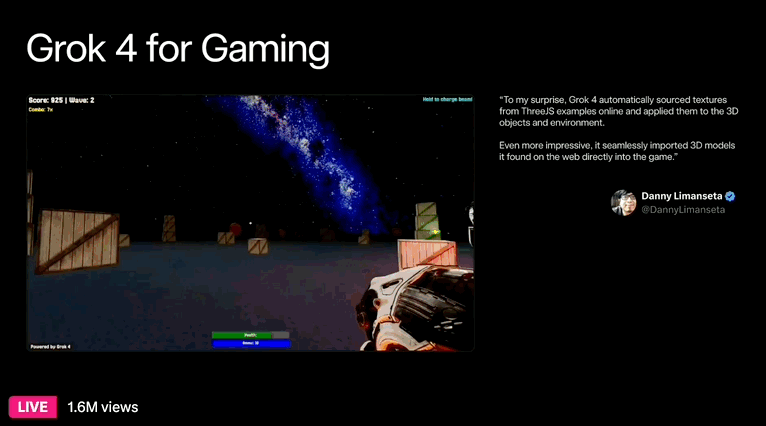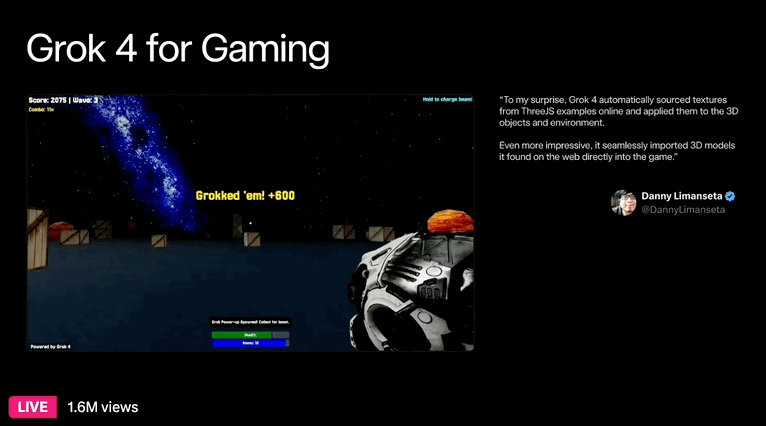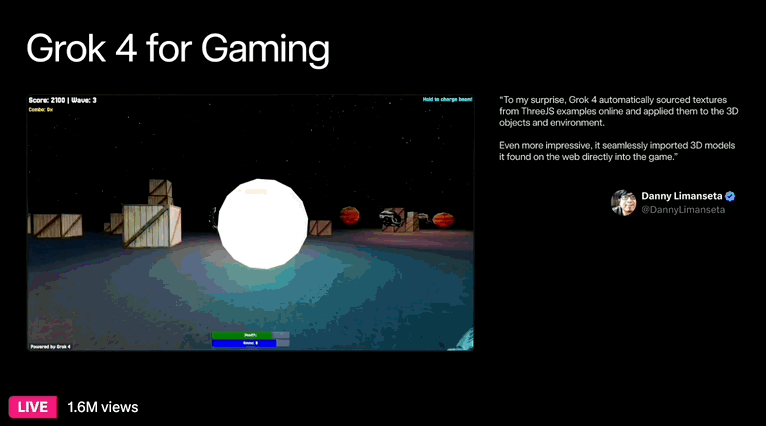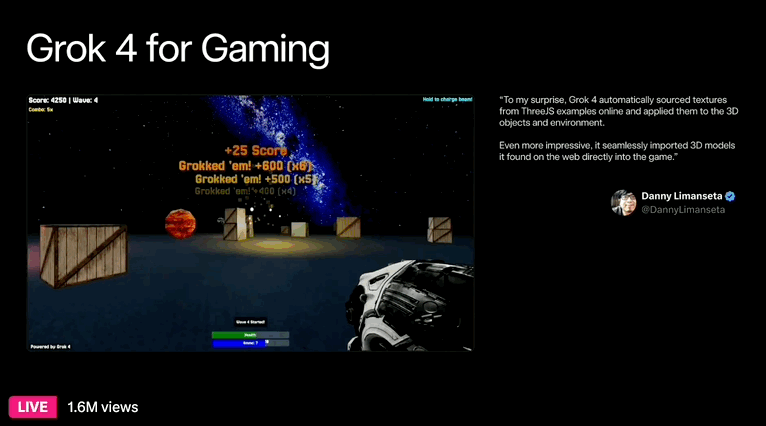
下一步,xAI 预计还将发布代码模型、多模态智能体以及视频生成模型,看起来新产品发布要达到月更的速度。

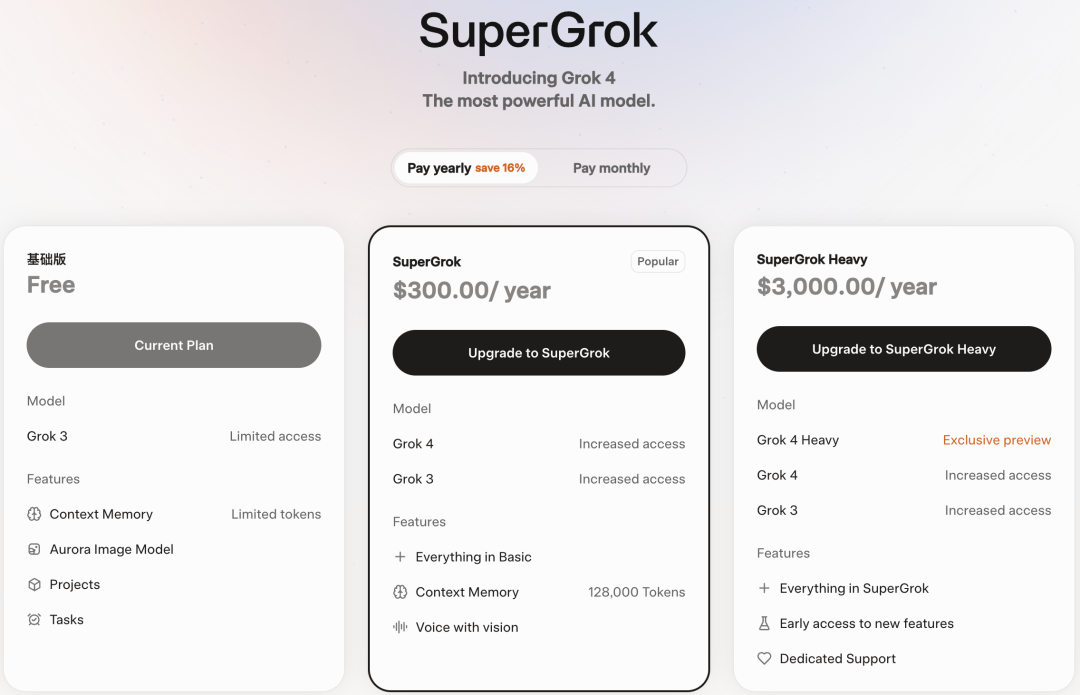
目前,Grok 4 已经上线,不过需要付费使用,而且价格相当昂贵。其付费模式分为年付和月付两种,其中 SuperGrok 是每年 300 美元(折合人民币约 2154 元),SuperGrok Heavey 则是每年 3000 美元(折合人民币 21540 元)。
-
官网链接:
https://grok.com/
©
(文:机器之心)