


在人工智能领域,推理模型的性能与效率一直是研究者和开发者关注的焦点。蚂蚁技术团队推出的Ring-lite,作为一款基于MoE架构的轻量级推理模型,凭借其创新的C3PO强化学习训练方法和高效的多领域推理能力,为轻量级推理模型的发展树立了新的标杆。

一、项目概述
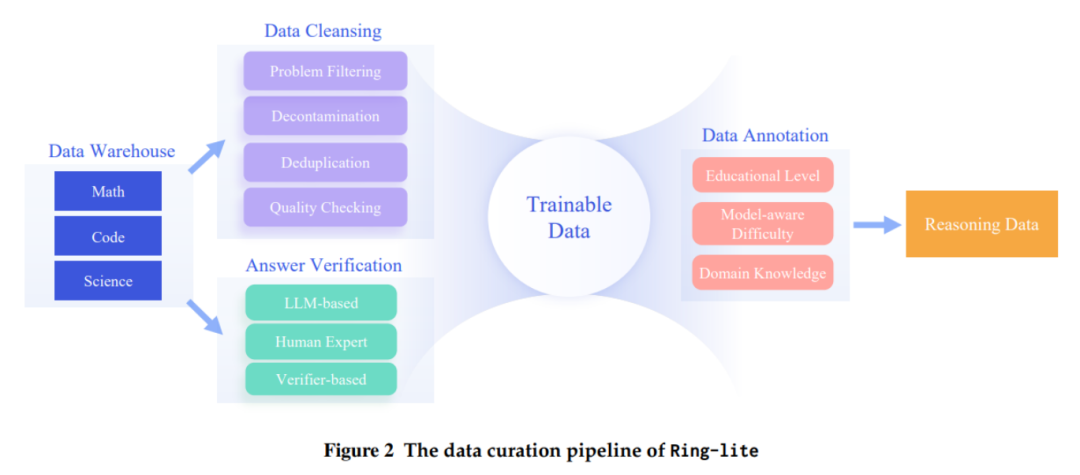
Ring-lite是蚂蚁技术AntTech团队基于MoE架构推出的轻量级推理模型,以Ling-lite-1.5为基础,采用独创的C3PO强化学习训练方法,在多项推理Benchmark上达到SOTA效果,仅用2.75B激活参数。该模型通过稳定强化学习训练、优化Long-CoT SFT与RL的训练比重、解决多领域任务联合训练难题等技术创新,实现了高效推理,并开源了技术栈,包括模型权重、训练代码、数据集等,推动轻量级MoE推理模型的发展。
二、技术原理
(一)MoE架构
Ring-lite基于Mixture-of-Experts(MoE)架构,该架构通过多个专家网络的组合来处理输入数据。每个专家网络负责处理特定的子任务或数据特征,从而提高模型的推理能力和效率。这种架构的优势在于能够根据输入数据的不同特征,动态地选择最合适的专家网络进行处理,实现资源的高效利用和推理性能的提升。
(二)C3PO强化学习训练方法
C3PO(Constrained Contextual Computation Policy Optimization)是Ring-lite的创新强化学习训练方法。它通过固定每个训练步骤的总训练token数,消除由于生成回复长度波动带来的优化不稳定和吞吐波动问题。C3PO基于熵损失(entropy loss)的策略选择合适的起点模型,进一步稳定训练过程。这种方法有效解决了传统强化学习训练中的不稳定性问题,提高了训练过程的稳定性和效率。
(三)Long-CoT SFT与RL的结合
Ring-lite采用Long-CoT(长推理链)监督微调(SFT)和强化学习(RL)相结合的两阶段训练方法。Long-CoT SFT使模型能够学习到复杂的推理模式,而RL则让模型在特定任务上进一步优化性能。Ring-lite通过实验确定最佳的SFT和RL训练比重,在token效率和性能之间取得平衡,充分发挥了两种训练方法的优势。
(四)多领域数据联合训练
Ring-lite在训练过程中采用数学、编程和科学等多个领域的数据。通过分阶段训练的方法,在数学任务上进行训练,然后在代码和科学任务上进行联合训练,有效地解决了多领域数据联合训练中的领域冲突问题。这种训练方式不仅提高了模型在不同领域的推理能力,还增强了模型的泛化能力。
三、主要功能
(一)高效推理
Ring-lite能在多项复杂的推理任务中实现高效推理,如数学推理、编程竞赛和科学推理等。其高效的推理能力得益于MoE架构和C3PO强化学习训练方法的结合,使得模型在处理复杂问题时能够快速准确地给出推理结果。
(二)轻量级设计
Ring-lite的总参数量为16.8B,激活参数仅为2.75B,在保持高性能的同时,具有较低的计算资源需求。这种轻量级设计使得Ring-lite适合在资源受限的环境中使用,如移动设备、边缘计算设备等,为推理模型的广泛应用提供了可能。
(三)多领域推理
Ring-lite能处理多个领域的推理任务,包括数学、编程和科学等。它通过联合训练和分阶段训练的方法,实现在不同领域之间的协同增益,提高模型的泛化能力。这种多领域推理能力使得Ring-lite能够应用于多种场景,满足不同领域的推理需求。
(四)稳定训练
基于C3PO强化学习训练方法,Ring-lite解决了传统强化学习训练中的不稳定性问题,提高了训练过程的稳定性和效率。稳定的训练过程不仅保证了模型性能的持续提升,还减少了训练过程中的资源浪费和时间成本。
四、应用场景
(一)教育领域
Ring-lite可以辅助学生解决复杂的数学和科学问题,提供详细的解题步骤和推理过程,帮助学生更好地理解和掌握知识。其多领域推理能力使得它能够覆盖多个学科,为学生提供全面的学习支持。
(二)科研领域
在科研领域,Ring-lite能够辅助研究人员验证和探索复杂的数学和科学问题,提供详细的推理步骤和解决方案,支持理论研究和实验设计。其高效的推理能力和稳定的训练过程为科研人员提供了可靠的工具,加速科研进程。
(三)工业和商业领域
Ring-lite可以处理和分析复杂的数据,提供推理过程和解决方案,用于金融、医疗和市场营销等领域的预测和决策支持。其轻量级设计使得它能够快速部署在各种商业环境中,为企业提供高效的推理服务。
(四)智能助手
集成到智能助手中,Ring-lite能够提供更智能的推理和解答能力,处理复杂的查询和任务,提升用户体验。其多领域推理能力使得智能助手能够更好地理解用户的需求,为用户提供更加精准和个性化的服务。
(五)医疗领域
在医疗领域,Ring-lite可以辅助医生和研究人员分析和处理复杂的医学数据,提供详细的推理过程和解决方案,支持疾病诊断和治疗方案制定。其高效的推理能力和稳定的训练过程为医疗行业提供了有力的技术支持。
五、性能评估
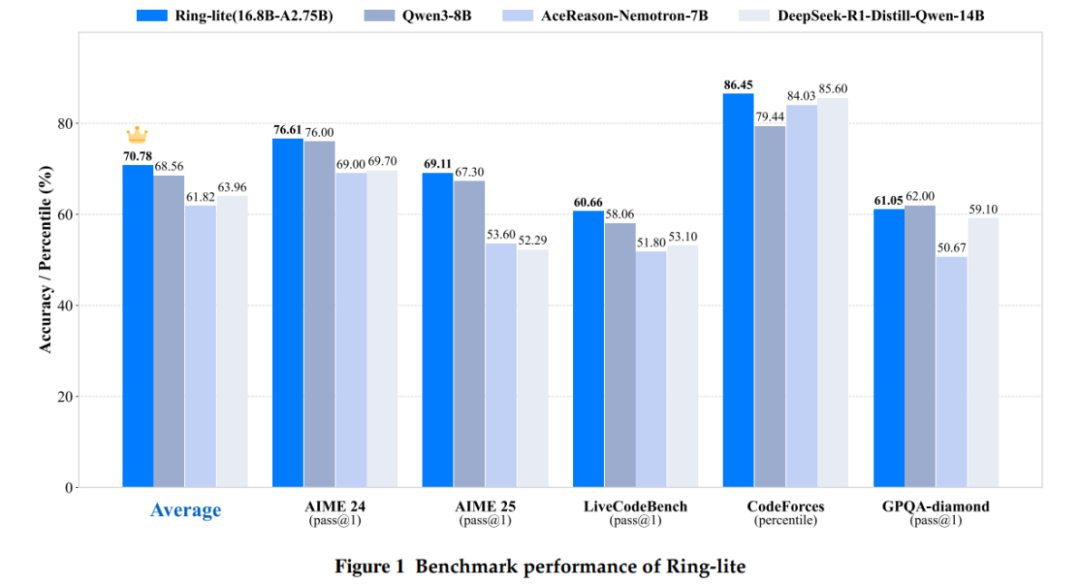
Ring-lite在多个推理Benchmark上达到了SOTA效果,仅用2.75B激活参数。
-
在数学推理方面,它在AIME2024和AIME2025两个具有挑战性的数学竞赛风格基准测试中分别取得了76.61%和69.11%的分数;
-
在编程竞赛方面,它在LiveCodeBench和Codeforces两个具有挑战性的编程竞赛基准测试中分别取得了60.66%和86.45%的分数;
-
在科学推理方面,它在GPQA-diamond研究生级别的科学问答基准测试中取得了61.05%的分数。
这些成绩表明,Ring-lite在多个领域的推理任务中均表现出色,性能可与甚至超过一些参数规模更大的模型。
六、快速使用
(一)环境准备
在开始使用Ring-lite之前,需要确保你的计算环境满足以下要求:安装Python 3.8或更高版本,安装PyTorch 1.10或更高版本,以及安装Transformers库。这些环境要求为Ring-lite的运行提供了基础支持。
(二)模型下载
你可以从HuggingFace模型库下载Ring-lite模型。访问[HuggingFace模型库](https://huggingface.co/inclusionAI/Ring-lite),下载完成后,将模型文件保存到本地目录中。
(三)模型推理
使用Transformers库加载下载的Ring-lite模型,并进行推理使用。以下是一个简单的代码示例:
# 导入必要的库# AutoModelForCausalLM 用于加载因果语言模型# AutoTokenizer 用于加载对应的分词器from transformers import AutoModelForCausalLM, AutoTokenizer# 指定模型名称,这里使用 inclusionAI/Ring-lite 模型model_name = "inclusionAI/Ring-lite"# 加载预训练模型# torch_dtype="auto" 表示自动选择合适的 PyTorch 数据类型# device_map="auto" 表示自动将模型分配到可用的设备(如 GPU 或 CPU)model = AutoModelForCausalLM.from_pretrained(model_name,torch_dtype="auto",device_map="auto")# 加载与模型对应的分词器tokenizer = AutoTokenizer.from_pretrained(model_name)# 定义用户输入的提示文本prompt = "Give me a short introduction to large language models."# 构建对话消息列表# 包含系统消息和用户消息# 系统消息用于设定模型的角色和行为# 用户消息是用户的输入messages = [{"role": "system", "content": "You are Ring, an assistant created by inclusionAI"},{"role": "user", "content": prompt}]# 使用分词器的 apply_chat_template 方法将对话消息转换为模型输入格式# tokenize=False 表示不进行分词# add_generation_prompt=True 表示添加生成提示,以便模型生成回复text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True)# 将文本转换为模型输入张量# return_tensors="pt" 表示返回 PyTorch 张量# 并将输入张量移动到模型所在的设备上model_inputs = tokenizer([text], return_tensors="pt").to(model.device)# 使用模型生成回复# max_new_tokens=8192 表示最多生成 8192 个新 tokengenerated_ids = model.generate(**model_inputs,max_new_tokens=8192)# 从生成的 token 中提取模型生成的部分# 去除输入部分的 token,只保留模型生成的 tokengenerated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)]# 将生成的 token 解码为文本# skip_special_tokens=True 表示跳过特殊 token(如 <pad>、<eos> 等)response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]# 输出生成的回复print(response)
七、相关资料
GitHub仓库:https://github.com/inclusionAI/Ring
HuggingFace模型库:https://huggingface.co/inclusionAI/Ring-lite
arXiv技术论文:https://arxiv.org/pdf/2506.14731
(文:小兵的AI视界)