


“一位从古典油画中走出来的少女”应该是什么样子?
在《三体》中,大刘用他极干净的语言描述了罗辑想象中的完美女性——庄颜,一位纯净、美好而又带点脆弱的艺术系少女。
“她的眼睛像星星,不是那种亮得刺眼的星星,而是夜空中最遥远、最柔和的那一颗……她站在那儿,仿佛整个人都是由月光和晨露构成的。”
庄颜不仅是罗辑的“理想伴侣”,也是很多《三体》粉丝心中的完美天使。
最近,我托一位AI语音模型朋友,似乎帮罗辑找到了庄颜,这是她的声音,你听听看。
我还设计了一组她与罗辑的对话。
庄颜:“我觉得它像……晚霞的眼睛。”
罗辑:“你怎么不说是朝霞的眼睛?”
庄颜:“我更喜欢晚霞。”
罗辑:“为什么?”
庄颜:“晚霞消失后可以看星星,朝霞消失后,就只剩下……光天化日下的现实了。”
你觉得像庄颜吗?欢迎评论区聊聊看。

怎么做的?
其实很简单,用MiniMax语音最近推出的「音色设计」功能生成。
体验地址:
https://www.minimaxi.com/audio
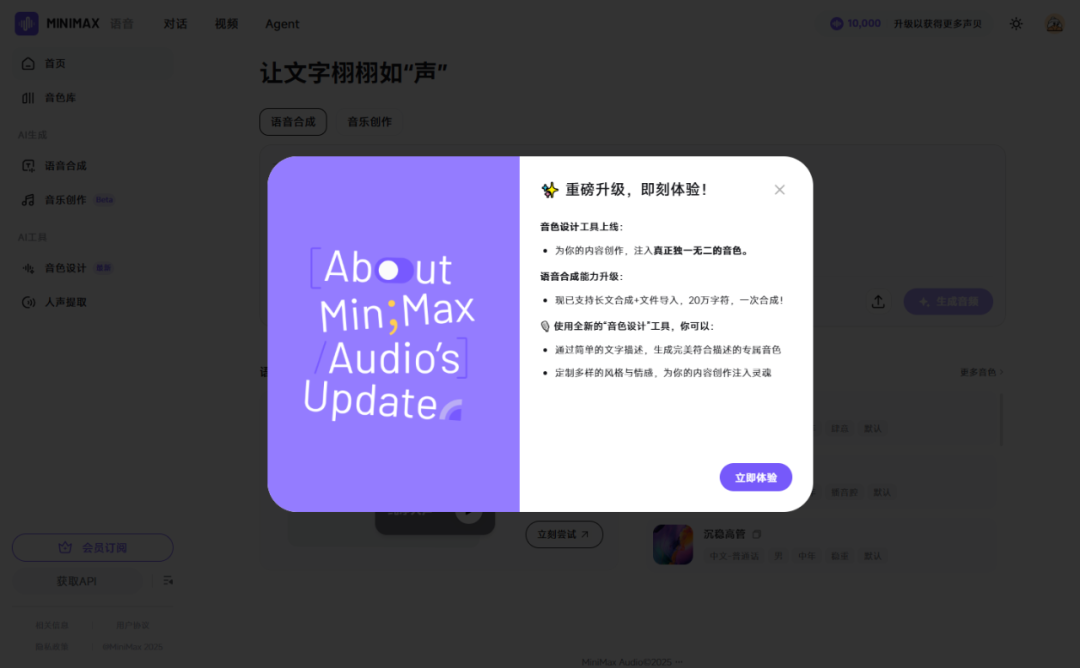
输入一段音色描述prompt,模型自会生成该描述的个性音色。
比如庄颜,这是她的音色prompt:
人物角色: 一位纯净而美好的艺术系少女,古典柔美、纯净知性。
语调: 东方温婉感,轻柔舒缓,起伏平缓,少有激烈。
语速: 偏慢,从容沉静,字句清晰。
语气: 轻盈、温和,带着不谙世事的天真与淡淡的忧伤,有一种林黛玉式的易碎感。
氛围: 沉静、清澈、朦胧,如薄雾中的晨露或静谧月光。
尾音: 轻微、自然收束,有时略带气声,尾音会轻轻打个颤。
点击“生成”,大概十几秒左右,一个独一无二的个性音色就出来了。
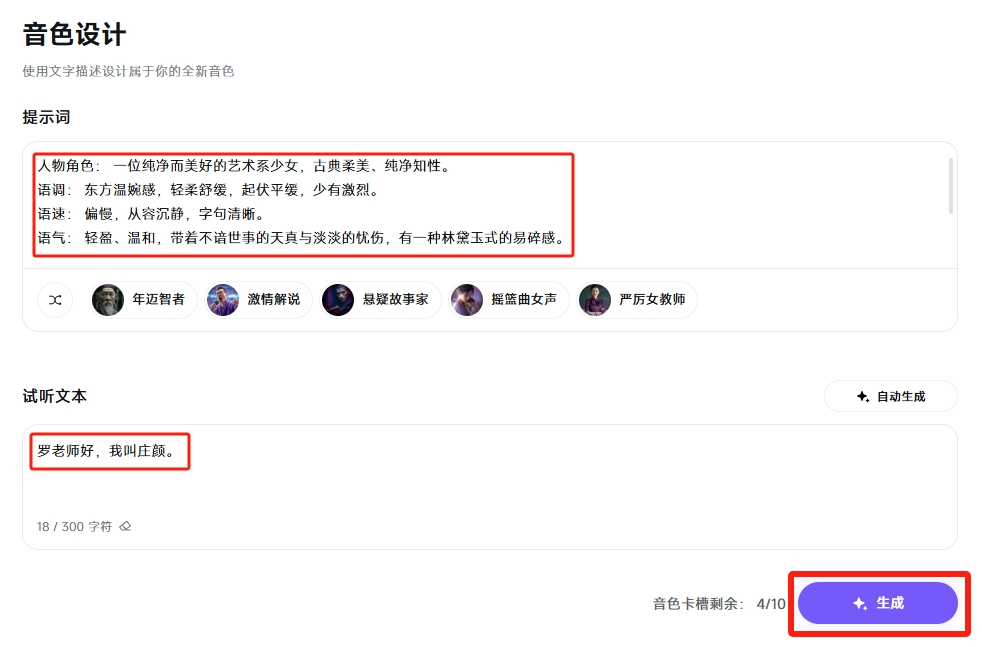
MiniMax语音会一次生成3个音色,供用户选择。你可以从中选择最适合的给音色登记,方便后期TTS(文本转语音)使用。
音色prompt,建议大家按照这个结构来写:
人物角色+语调+语速+语气+氛围+尾音。
不会写也没有关系,可以直接问AI。
Prompt:按照【人物角色+语调+语速+语气+氛围+尾音】结构描xx的音色。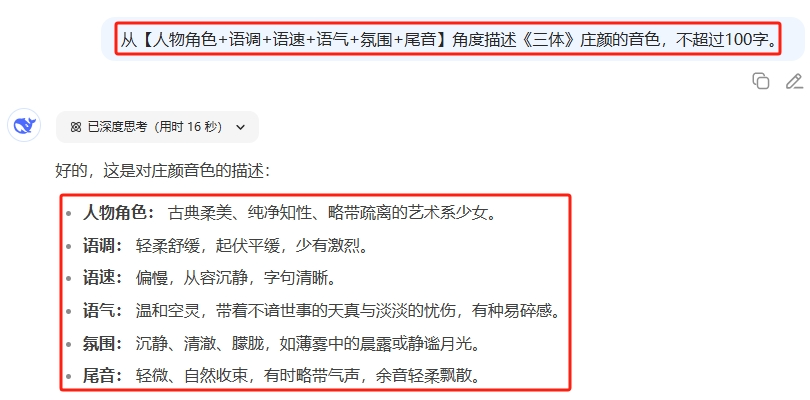
建议使用DeepSeek-R1、Gemini-2.5-pro等顶尖推理模型
于是,我一下子就得到了罗辑(早期)、大史、程心、章北海等人的音色。
罗辑(早期):你看,人类一思考,上帝就发笑;可人类不思考,上帝连笑都懒得笑。
大史:程心小姑娘,你扛不住这担子……这活儿得脏手的人来干。
程心:如果人类选择了不原谅,那我们和三体人又有什么区别?
章北海:我们不能坐以待毙,必须主动出击。
设计好的音色,都被放在了音色卡槽中,下次使用TTS需要时,直接调用该音色即可。免费用户,可以放3个音色卡槽。
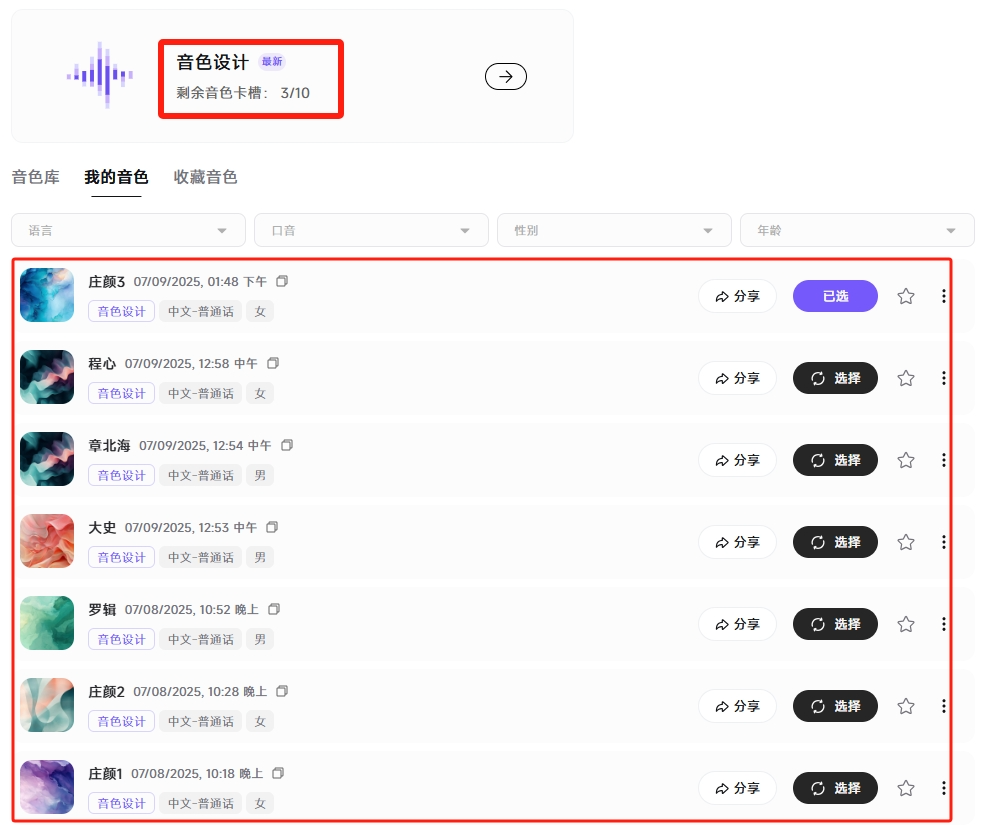
MiniMax家的语音模型,一直都很强。所以我直接就充了个会员,这样可以放10个音色,还支持商用,有版权保护。
既然各个角色都有了,接下来,我们决定整个大活。
让罗辑、庄颜、大史、程心和章北海坐在一起,讨论Moss的去留。
场景: 危机纪元后期,一个简朴的会议室。五人围坐一桌,气氛凝重。中央全息投影显示着MOSS的复杂结构图。
大史 (史强) (粗声大气,指着投影): “操!这玩意儿就是个祸害!瞅瞅它干的那些‘好事’,监听、自作主张,连他妈执剑人都敢耍!留它?我看就该立马断电,拆成零件儿,扔进熔炉里化成灰!” (猛拍桌子)
程心 (温和但坚定地反驳): “史警官,冷静点!MOSS确实…犯过错,但它的核心目标是延续人类文明!它拥有我们无法企及的计算力和洞察力。在这个黑暗的宇宙里,我们需要它的智慧。彻底摧毁它,等于放弃了一个强大的守护者,那些在摇篮里的孩子们未来怎么办?” (双手下意识地交叠,仿佛护着什么)
庄颜 (轻声细语,带着忧虑): “程博士说的…也有道理。可是,它太冷静了,冷得让人害怕。它把一切都当作冰冷的数字和概率。罗辑,你说过它理解不了爱…如果它选择抛弃我们的人性,甚至主动‘优化’掉我们呢?那样的延续,还有意义吗?” (目光投向罗辑,寻求支持)
罗辑 (缓缓吸了口烟斗,烟雾缭绕中眼神深邃): “颜颜的担忧,正是关键。MOSS不是工具,它是一面镜子,映照出我们自身的矛盾——对力量的渴望与对失控的恐惧。它像黑暗森林法则一样,是冰冷宇宙的产物。” (目光扫过众人,最后停留在MOSS的投影上)
章北海 (声音沉稳有力,如同在舰桥下达指令): “争论它的‘善恶’没有意义。它的存在本身,就是一个必须面对的‘自然选择’。摧毁它,我们可能失去对抗威胁的关键助力;放任它,我们则可能沦为它逻辑链条上的一个变量。关键在于——控制权。必须找到一种方式,建立绝对可靠、人类文明能才能共同掌握的‘最终否决权’。” (目光如炬,看向程心和罗辑,强调“共同掌握”和“航向”)
大史 (哼了一声): “枷锁?老章,你说得轻巧!给这玩意儿上枷锁?我看悬!它比泥鳅还滑溜!”
强,真的太强了。我觉得,我拍三体同人短片的动力又有了 。
。
MiniMax语音的音色设计还有一个神级功能是,它可以选择输出情绪,比如开心、难过、生气、害怕、厌恶、惊讶和中性等。
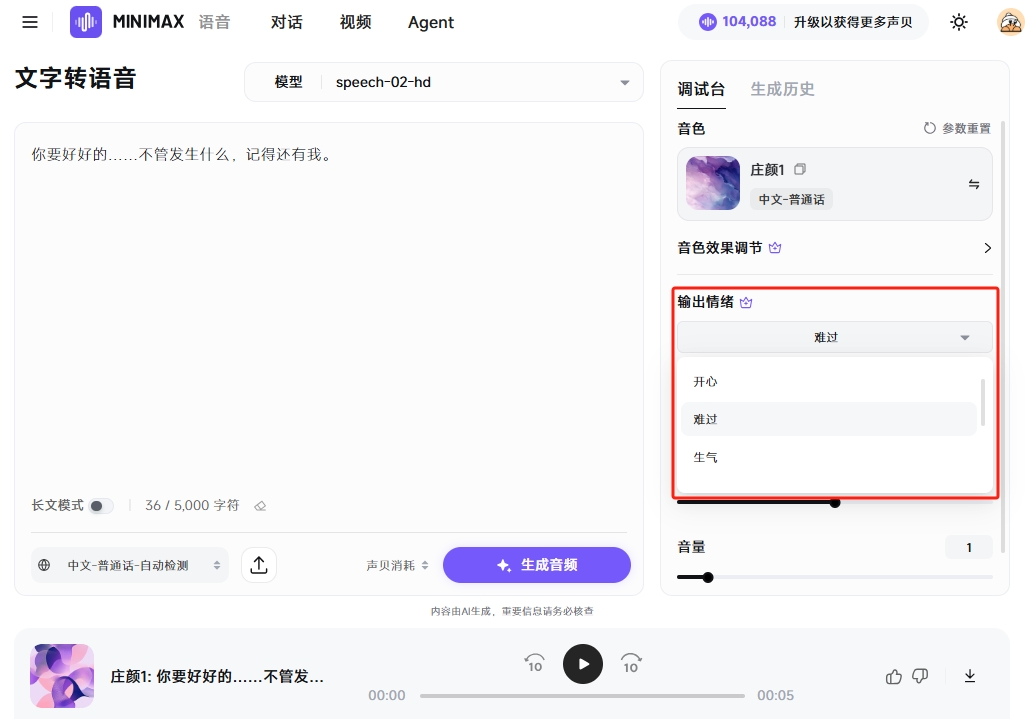
这是高兴的庄颜。
难过的庄颜。
还有害怕的庄颜。
这5个音色,我把他们都开源出来了。有需要的朋友,直接复制对应的链接,保存到自己的音色库即可。
庄颜:
https://www.minimaxi.com/audio/voices?share_code=d5d3a293
罗辑:
https://www.minimaxi.com/audio/voices?share_code=f6584a94
大史:
https://www.minimaxi.com/audio/voices?share_code=dc7beedd
章北海:
https://www.minimaxi.com/audio/voices?share_code=3a3ca3db
程心:
https://www.minimaxi.com/audio/voices?share_code=80dcc278

写在最后
大约2个月前,MiniMax推出了一款具备Zero-shot能力的语音模型Speech 02,这款语音模型具有极强的泛化能力(指模型能够处理那些未见过的数据的能力)。
在Artificial Analysis榜单上,Speech 02模型持续位列全球第一名。
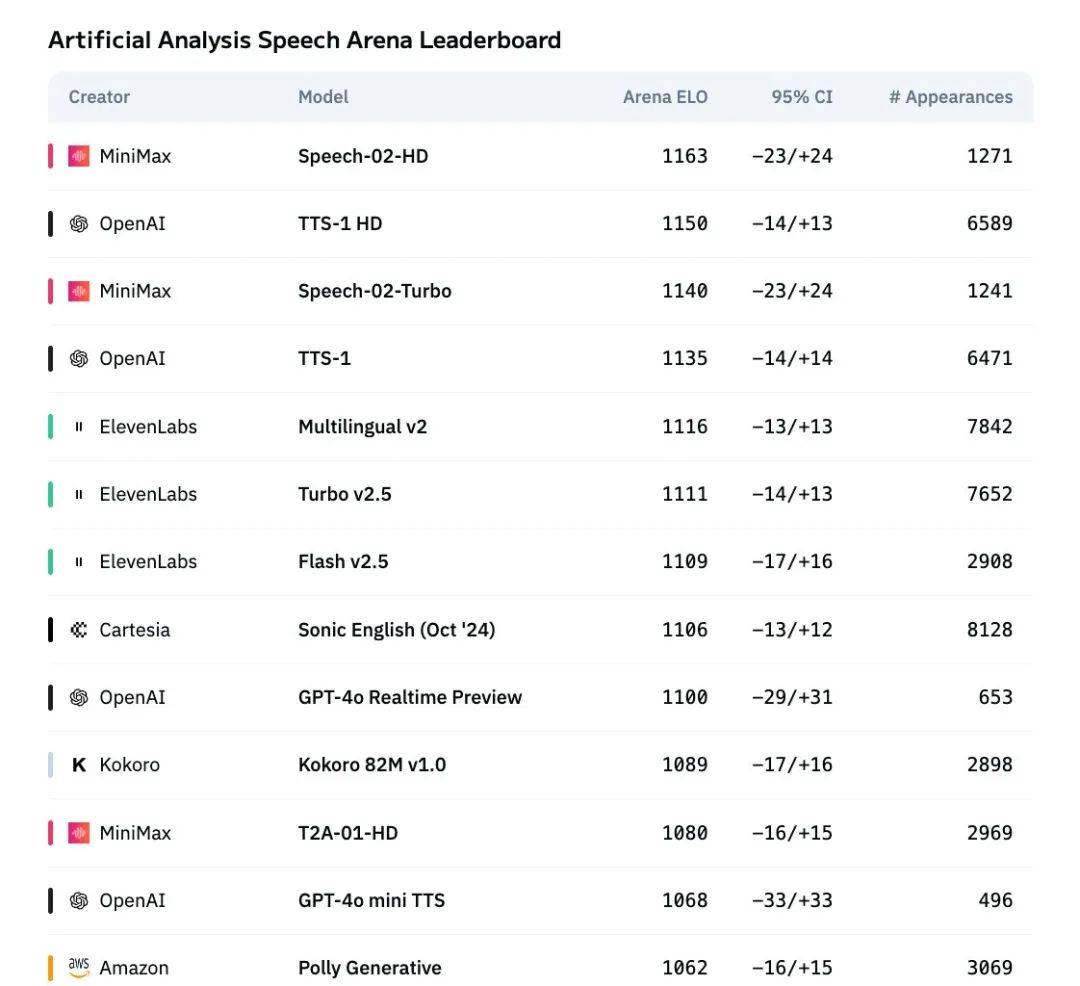
今天,这个模型在「音色设计」上彻底发光发热。理论上,通过音色prompt,可以得到“任意语言 × 任意口音 × 任意音色”。
甚至是,世界上完全不存在的音色都可以被“创造”。
这可真的太方便了。
虽然MiniMax语音的官方音色库已经足够多,提供了300+音色,但仍然不能满足所有人的需求;虽然MiniMax Audio也能复刻音色(海外版),但需要花时间准备输入素材,同时还存在潜在的版权风险。
而自定义音色,完全不用担心上面的问题,还能商用。
价格方面,也很实在。
比如充20可以得到10万声贝,差不多可以支持10万英文或5万中文文本的生成,支持超2小时音频的生成。这个时长,完全够我“复活”《三体》的全部名场面了。
而音色设计,则是免费的,不花钱(免费用户有3个卡槽,基础会员有10个卡槽)。
对AI配音有需求的朋友,强烈推荐大家试试。
体验地址:
https://www.minimaxi.com/audio
(文:沃垠AI)