
在这个被文档淹没的数字化时代,PDF、扫描件、图文混排图片……几乎每天都在挑战我们的信息处理能力。
如何高效地提取信息、结构化利用,并与AI平台打通,实现自动问答与知识管理闭环?这是每一个内容生产者、开发者、甚至企业团队都无法回避的难题。
作为一名长期关注全球开源项目和AI实用工具的技术人,最近我亲自实测了一款国产黑科技产品:Doc2X。
Doc2X 是一款基于先进 AI 技术打造的高精度文档解析工具,专为开发者和智能体应用设计,集成了文档识别、结构化提取与智能对接于一体。
它不仅具备高识别精度、强大的结构化能力、顺畅的 API 调用体验,更在性价比上遥遥领先。最关键的是,Doc2X 可一键无缝接入 FastGPT、Coze 等主流智能体平台,实现从“文档秒解析”到“智能问答自动化”的完整闭环,真正让 AI 应用跑通最后一公里。
Doc2X 支持将复杂文档高精度转化为 Markdown、LaTeX、HTML、Word 等多种结构化或半结构化格式,具备强大的公式识别、表格解析、图片内容提取和多语言翻译能力,全面覆盖文本与视觉信息的提取需求。
通过开放灵活的 API 接口,Doc2X 可无缝集成至各类知识库系统、在线教育平台与企业自动化工作流。目前已成功对接 FastGPT、CherryStudio、字节跳动扣子等主流 AI 应用构建平台,成为众多开发者打造智能系统的首选底座。
它不仅显著提升信息处理效率,更助力开发者快速构建高效、智能的文档理解与交互应用。
Doc2X核心亮点一览
1、高精度解析
Doc2X 在处理复杂文档方面表现尤为出色,尤其适用于学术论文、财务报表、教辅资料等包含数学公式、跨页表格、多栏排版等结构的场景。其识别精度显著优于传统 OCR 工具和部分主流开源方案,能够更精准地还原原始文档的语义与结构信息。

2、公式识别能力领先
针对理工科文档、学术论文和教育试题等富含数学公式的场景,Doc2X 进行了深度优化,具备对印刷体及部分手写体公式的高精度识别能力。其输出结果支持结构化格式转换(如 LaTeX),可无缝适配 MathJax 渲染和 Word 公式编辑器,极大提升内容复用与展示效果。
无论处理文档还是图片,Doc2X 在识别准确性和格式还原方面均优于部分开源方案,有效避免乱码、错位等常见问题,显著提升用户的阅读体验与可用性。
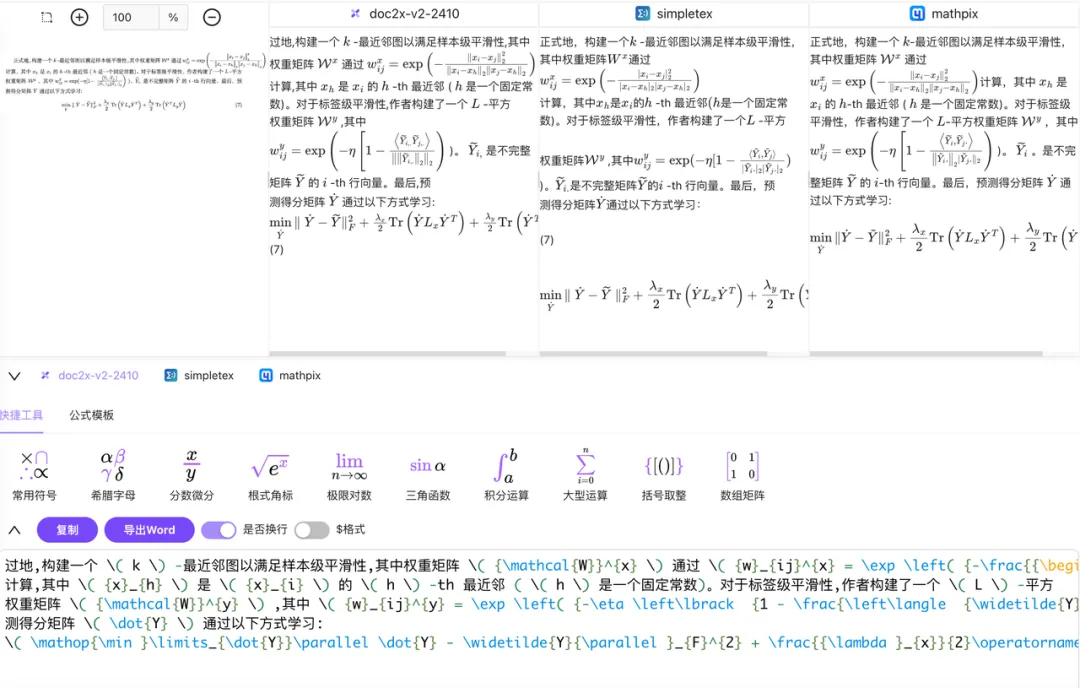
3、超全的格式转换
Doc2X 可轻松将 PDF 文件高质量转换为 Word、HTML、LaTeX、Markdown 等主流文档格式,同时保留原始布局与结构,实现内容的高度还原。系统还支持原文与解析结果的对照跳转与可视化编辑,确保转换前后一致性,极大提升文档整理与后期处理的效率。

4、多大模型翻译引擎整合,支持双语对照及保留排版
多款顶级 AI 引擎加持,支持 GPT、DeepSeek、GLM、Qwen、Yi-Lightning 等模型,实现高精度翻译效果。平台还提供双语对照的沉浸式翻译体验,支持双向内容跳转,帮助用户快速理解和比对文本细节,极大提升阅读效率。
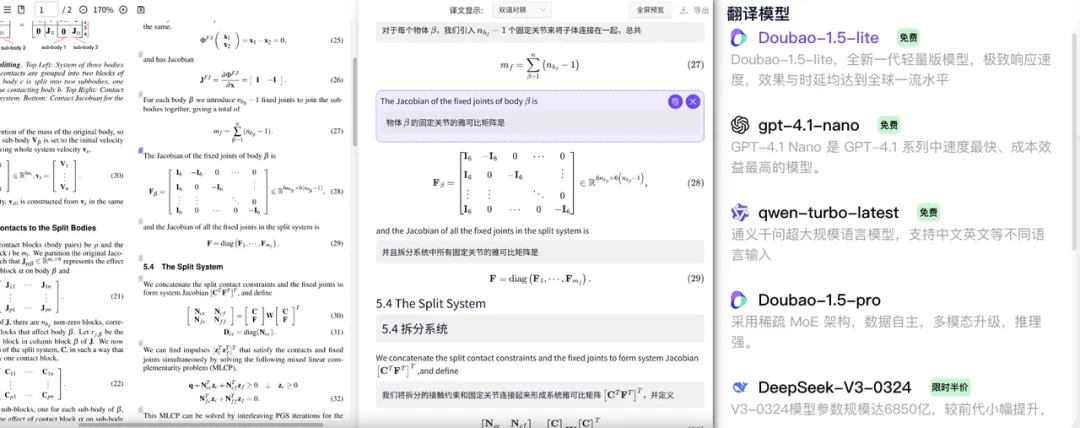
当然,Doc2X 还支持一个非常实用且人性化的功能:完美保留原文的版式和布局,包括公式、表格、图示等关键元素,确保翻译文本与原文在页面上的相对位置高度一致。这不仅让翻译文档更易于阅读,也极大方便了后续的编辑和排版工作。

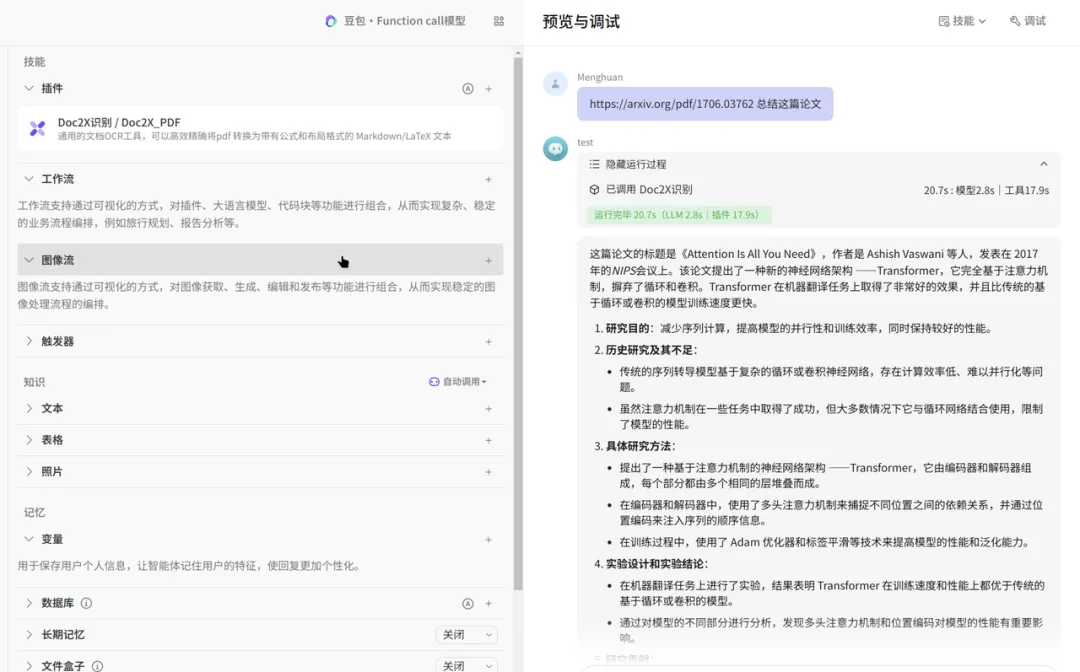
5、支持文档AI对话
基于文档上下文的 AI 对话功能,能够快速定位并深入理解全文关键信息,支持多轮深度问答与智能总结。用户可自由选择多种大模型,如 DeepSeek v3、GLM4 Plus 等,配合原文跳转功能,免去繁琐翻阅环节,显著提升工作效率与信息利用率。

6、高性价比与灵活API
Doc2X 提供清晰易用的 API 接口,支持批量高效处理,凭借极高的性价比,为从个人开发者到大型企业的多样规模和预算需求,提供稳定且高质量的文档解析服务。
截至目前,Doc2X 线上累计处理文档已超过数亿页,日均吞吐量突破千万页,展现出强大的工业级处理能力。
同时,Doc2X 可轻松无缝对接 FastGPT、CherryStudio、扣子(国内版)等多家知名知识库与 AI 应用构建平台,助力开发者打造智能化工作流和应用场景。
7、数据安全
Doc2X 网页端存储有效期为30天(包括图床), API的存储过期时间是24h, 过期自动删除, 请放心使用。
快速使用(含实测及API教程)
接下来,直接访问 Doc2X 官方主页,快速体验其强大的文档解析能力,轻松享受 PDF 翻译、图片识别、文档格式转换及文档 AI 对话等多项核心功能。
Doc2X地址:https://doc2x.noedgeai.com
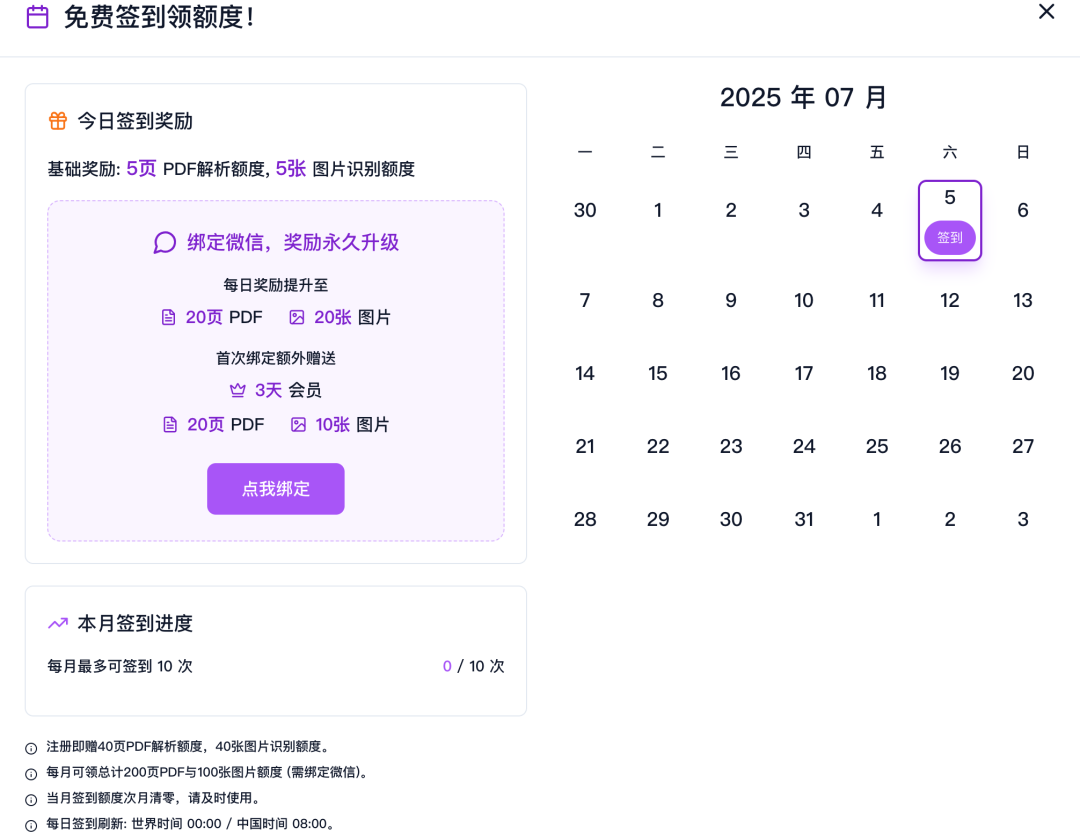
现在注册即赠送40页PDF解析额度和40张图片识别额度,每天签到还能持续领取奖励,每月最高可获得累计200页PDF和100张图片的免费额度,满足日常使用需求,非常实用。
如果想进行 PDF 翻译,可通过本地文件上传或拖拽的方式快速导入文档。上传前,你可以设置目标语言和选择翻译大模型(如豆包、DeepSeek 等),系统会自动识别并翻译文本、表格及公式内容。
上传时还支持多种可调参数,比如针对页数较多的文档,可以灵活设置翻译的页码范围;此外还有翻译模式选择,支持保留原排版或双语对照翻译,整体体验非常人性化,满足不同用户的多样需求。
点击“确认处理”,得到以下结果。
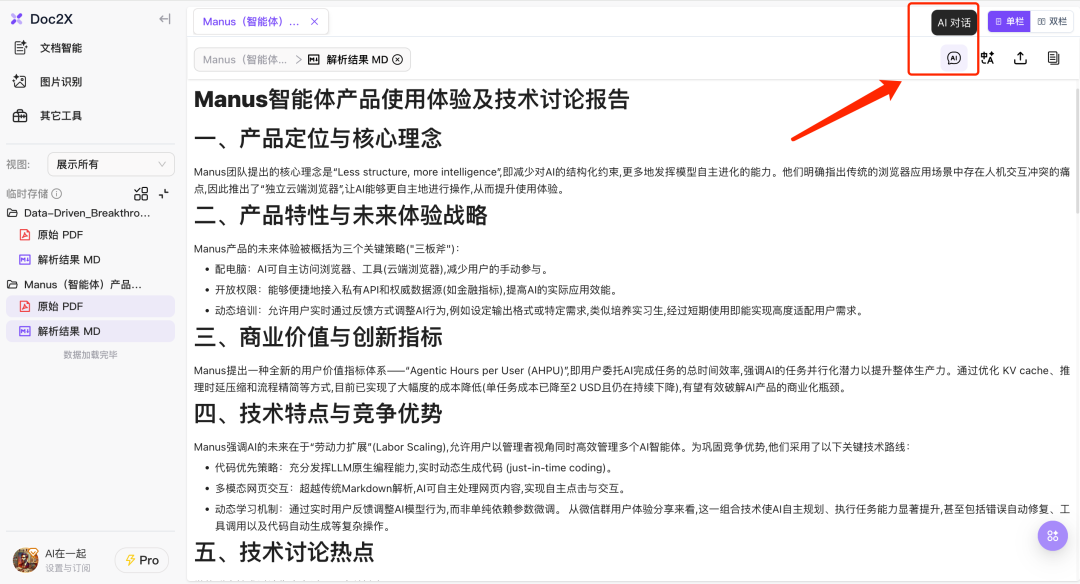
通过点击右上角「AI」气泡图标,可以直接与文档进行AI对话,了解你不清楚的地方,特别适合大文档场景下的关键信息获取及定位。

API使用(仅支持解析功能)
对于企业用户或高频翻译场景,Doc2X 提供便捷的 API 集成功能,可将 PDF 翻译流程无缝嵌入至自有应用系统中,实现批量处理与大规模自动化翻译,有效提升工作效率与协同能力。
1、获取API Key
使用Doc2X的API服务前,需要先在Doc2X的开放平台中,创建一个API-KEY,供接口调用鉴权。
Doc2X开放平台地址:https://open.noedgeai.com
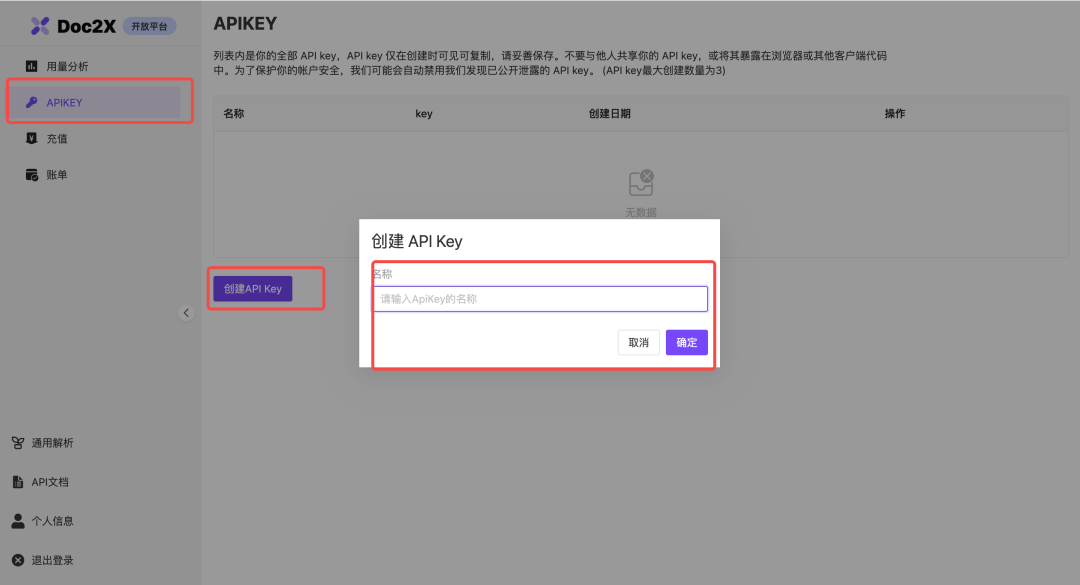
创建完成后,保存好自己生成的API-Key。
2、Authorizaton 鉴权
首先需要获取到API Key(类似于sk-xxx) 获取API网址: open.noedgeai.com
在HTTP请求头加入:
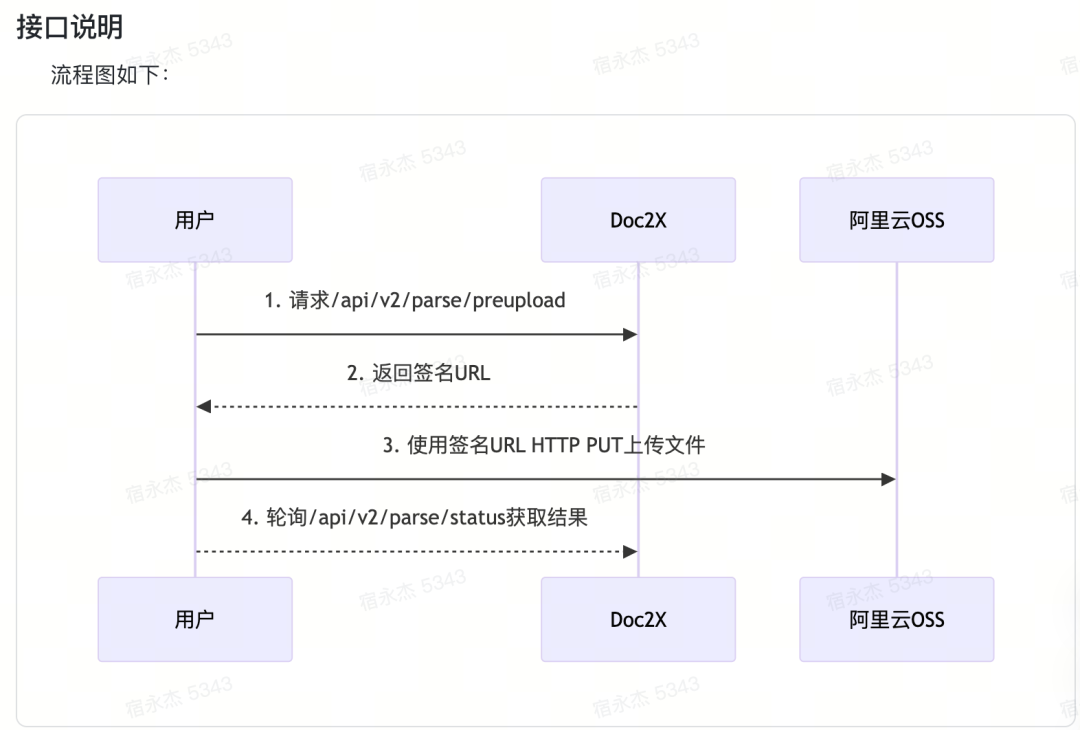
Authorization: Bearer sk-xxx在文件上传接口的使用上,我们采用最新 preupload 文件预上传,具备更快的上传速度,而且支持最大1GB的文档。
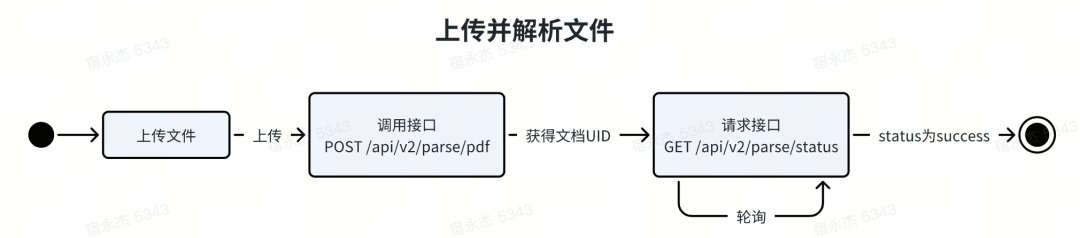
接口(POST):https://v2.doc2x.noedgeai.com/api/v2/parse/preupload
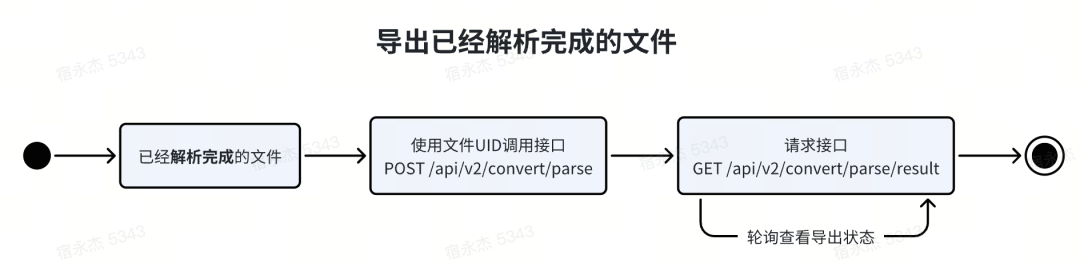
从/api/v2/convert/parse/result或/api/v2/convert/parse接口获得形如下方示例的成功返回示例后,您可以使用HTTP GET方法请求url来下载文件:
import jsonimport timeimport requests as rqbase_url = "https://v2.doc2x.noedgeai.com"secret = "sk-xxx"def preupload():url = f"{base_url}/api/v2/parse/preupload"headers = {"Authorization": f"Bearer {secret}"}res = rq.post(url, headers=headers)if res.status_code == 200:data = res.json()if data["code"] == "success":return data["data"]else:raise Exception(f"get preupload url failed: {data}")else:raise Exception(f"get preupload url failed: {res.text}")def put_file(path: str, url: str):with open(path, "rb") as f:res = rq.put(url, data=f) # body为文件二进制流if res.status_code != 200:raise Exception(f"put file failed: {res.text}")def get_status(uid: str):url = f"{base_url}/api/v2/parse/status?uid={uid}"headers = {"Authorization": f"Bearer {secret}"}res = rq.get(url, headers=headers)if res.status_code == 200:data = res.json()if data["code"] == "success":return data["data"]else:raise Exception(f"get status failed: {data}")else:raise Exception(f"get status failed: {res.text}")upload_data = preupload()print(upload_data)url = upload_data["url"]uid = upload_data["uid"]put_file("test.pdf", url)while True:status_data = get_status(uid)print(status_data)if status_data["status"] == "success":result = status_data["result"]with open("result.json", "w") as f:json.dump(result, f)breakelif status_data["status"] == "failed":detail = status_data["detail"]raise Exception(f"parse failed: {detail}")elif status_data["status"] == "processing":# processingprogress = status_data["progress"]print(f"progress: {progress}")time.sleep(3)
{'uid': '', 'url': ''}{'status': 'processing', 'progress': 0, 'detail': '等待文件上传'}progress: 0{'status': 'processing', 'progress': 0, 'detail': '任务进行中'}progress: 0{'status': 'processing', 'progress': 5, 'detail': '任务进行中'}progress: 5{'status': 'processing', 'progress': 90, 'detail': '任务进行中'}progress: 90{'status': 'processing', 'progress': 91, 'detail': '任务进行中'}progress: 91{'status': 'processing', 'progress': 99, 'detail': '任务进行中'}progress: 99{'status': 'processing', 'progress': 99, 'detail': '任务进行中'}progress: 99{'status': 'processing', 'progress': 99, 'detail': '任务进行中'}progress: 99...result
-
由于用户上传到OSS之后,服务端拉取有一定延迟,所以上传文件之后状态不会立刻更新到“任务进行中”,需要等待(<20s)。
-
获得链接之后5min内有效,注意时间。
-
url链接不能重复使用:如果http put失败(即status_code!=200)可以重试,put如果获得200返回,链接不能重复使用。
-
由于在上传文件前无法知晓页数,触发速率限制(parse_concurrency_limit, parse_task_limit_exceeded)的提示仅会在status接口中触发。
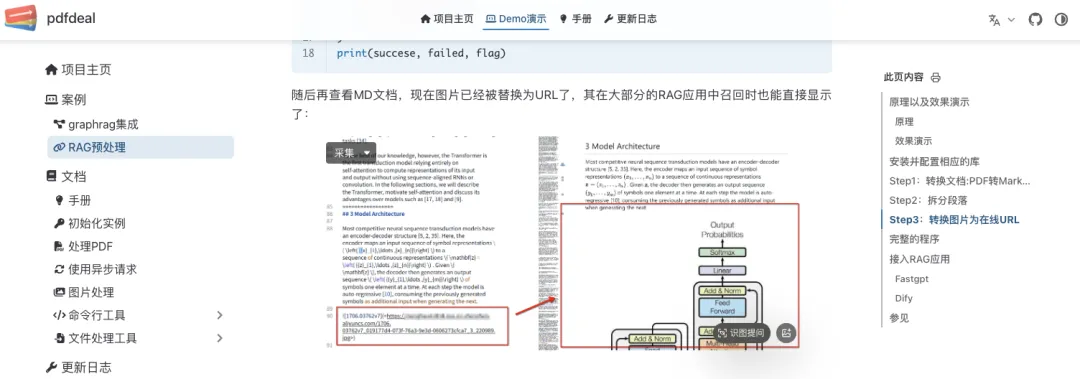
相关源码地址:
PdfDeal:https://github.com/NoEdgeAI/pdfdeal-docs
doc2x-doc:https://github.com/NoEdgeAI/doc2x-doc
接入扣子(Coze国内版)工作流
目前,Doc2X 也已上架扣子平台,支持以插件或工作流的形式发布为实用工具,用户可一键调用其核心能力,快速集成到各类智能体应用中,进一步提升开发与使用的便捷性。
插件地址:https://www.coze.cn/store/plugin/7398010704374153253
打开扣子空间(coze.cn),点击页面上方的「资源」栏目,即可创建工作流或插件,将 Doc2X 的能力集成为可复用的智能体组件。
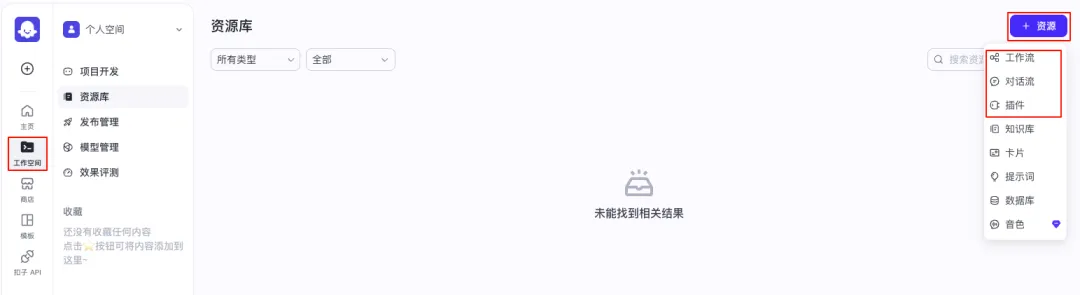 接下来,为工作流命名(注意仅支持英文和下划线命名格式),填写功能描述后,依次添加【Doc2X识别】节点和【大模型】节点,并将两者进行连线。
接下来,为工作流命名(注意仅支持英文和下划线命名格式),填写功能描述后,依次添加【Doc2X识别】节点和【大模型】节点,并将两者进行连线。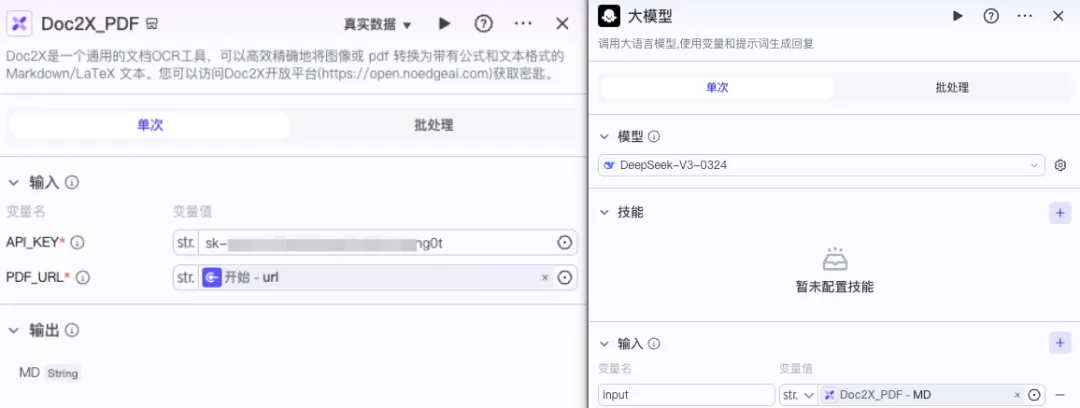
随后,通过 URL 方式输入一份论文 PDF,Doc2X 将自动进行内容解析,并将结构化结果传递给大模型节点,生成摘要或智能总结输出。整个流程无需手动干预,适合批量处理学术文档、技术报告等复杂资料。
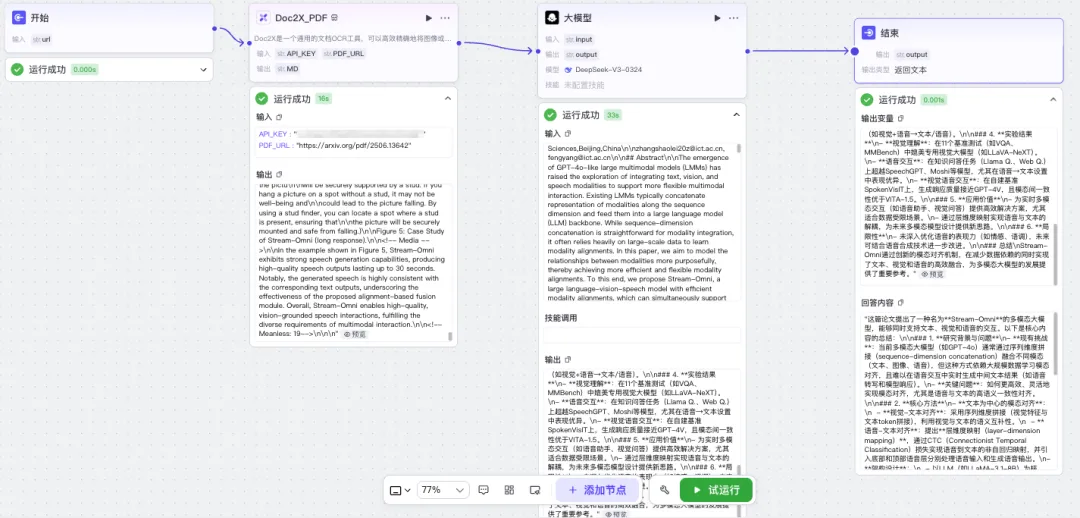
后续还可以将该工作流封装为一个扣子智能体进行发布,支持在对话窗口中实时调用,实现文档解析、总结问答等功能的一体化交互处理,打造专属的智能助手。
综合实测来看,Doc2X 在文档解析领域的表现堪称惊艳,具体表现如下:

从性价比到智能化,从开发体验到落地能力,Doc2X 不仅是工具,更是助力知识管理和 AI 能力部署的利器。

总的来说,Doc2X 无论是在网页端的可视化体验,还是在 API 层的灵活调用,都展现出了稳健的性能和出色的用户体验。在这个对效率和智能化要求越来越高的时代,Doc2X 不仅省时省力,更真正做到了“技术落地可用”。
不夸张地说,它是目前国产文档解析工具中少有的“全能型选手”。如果你正在寻找一款既精准又高效、既好用又能接入大模型的文档处理利器,Doc2X 值得你立刻试一试。体验过后,你可能也会和我一样,真心为它点赞。
我和团队成员亲自体验后,效果确实非常出色,因此申请了5个体验名额。具体体验流程如下:
-
打开官网:https://doc2x.noedgeai.com -
兑换流程:在主页点击,我的头像 → 账户管理 → 我的账户 → 输入兑换码; -
体验兑换码如下:uTnFGMMFda、WA3OHMqk3e、gv5HEjPro8、quSBj3q7KI、HEkZSwZwYW

(文:AI技术研习社)