

从 0.927 的惊人相似度,到国产大模型信任困局的集体焦虑。
7月的国产大模型圈,不太平。
一份发布于 GitHub 的技术报告,将刚刚开源的华为 盘古 Pro MoE 72B 模型推上了风口浪尖。而这场风波的导火索,是一个看似冰冷、实则爆炸的数字:0.927。
这是一份名为《LLM-Fingerprint》的研究报告得出的“模型相似度”。报告指出,华为 盘古 Pro MoE 72B 与阿里 Qwen-2.5 14B 模型在注意力层参数上的相关性高达 0.927,远超业内普遍认为的“合理参考”上限 0.7。
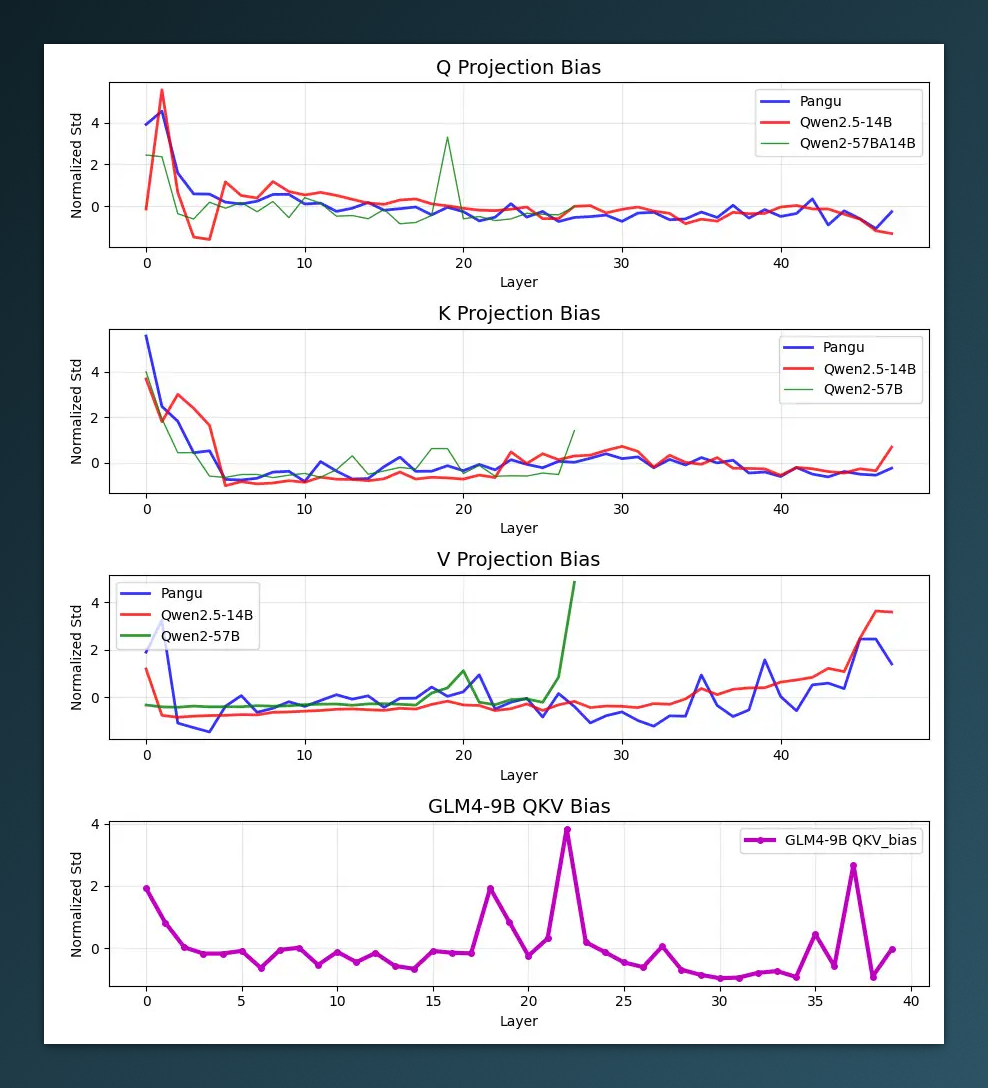
如果说仅仅是“结构相似”,或许还属于合理范畴。但当参数相似性高到这个程度,加之盘古模型开源仓库中被实锤发现了 “Copyright 2024 The Qwen Team, Alibaba Group” 的字样,一切似乎就不再只是巧合那么简单了。
01|从 GitHub 模型指纹报告说起
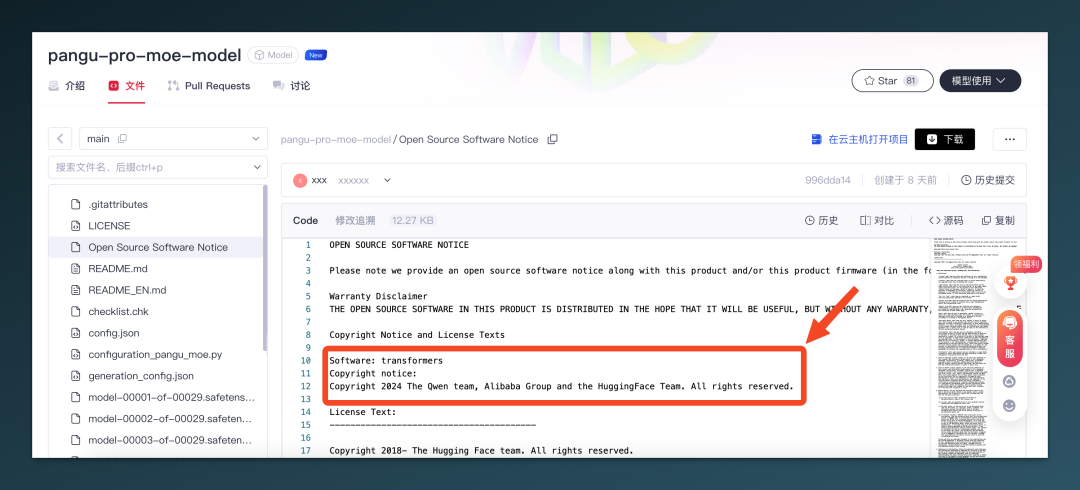
事件的起点,是 GitHub 上一个名叫 HonestAGI 的团队发布的《LLM-Fingerprint》报告。研究者采用了一种“标准差指纹”方法,将模型各层 Q/K/V/O 权重的标准差向量作为特征签名,计算皮尔森相关系数,判断是否存在“继承关系”。
盘古 Pro MoE 72B 与 Qwen-2.5 14B 的注意力层,相关性被测得为 0.927 —— 这个数字,对比业界参考阈值0.7,基本已接近“同源复制”的边缘。
从实验图来看,两者在 Attention 模块中表现出高度相似的参数标准差波动,呈现一一对应的走势,尤其在前十层结构中,几乎“镜像对齐”。这让“参数复用”的怀疑变为可量化、可验证的风险预警。
该仓库数小时后即被删除,随后出现镜像。并且,作者 HonestAGI 称已收到“多名华为员工”匿名爆料确认权重继承。
更具争议的是,报告还提到,在盘古模型开源初期的 Git 仓库中,不仅 LICENSE 文件中残留“Copyright 2024 The Qwen Team, Alibaba Group”,部分 Python 脚本头部也未清除阿里团队署名。虽然相关提交在风波发生后被迅速删除,但已有多家社区截图为证。
02|华为回应:强调“自主”、模糊细节
面对风波,华为诺亚方舟实验室很快发布声明,称 盘古 Pro MoE 模型是“基于昇腾芯片自主研发,提出分组混合专家 MoGE 架构的新模型”,并否认“基于其他开源模型增量训练”。
声明中强调模型训练过程全部在华为自有硬件完成,使用了自研的训练框架和优化策略。然而,对模型参数来源、是否借鉴 Qwen 权重、是否使用第三方预训练模型做续训,并未做出明确澄清。

在英文媒体路透社的采访中,华为方面重复了相似表述,称“完全遵循开源协议”“未抄袭任何模型”。
但行业对这份回应,普遍评价为“避重就轻”:是一份合格的危机公关文案,但并不足以平息所有质疑。
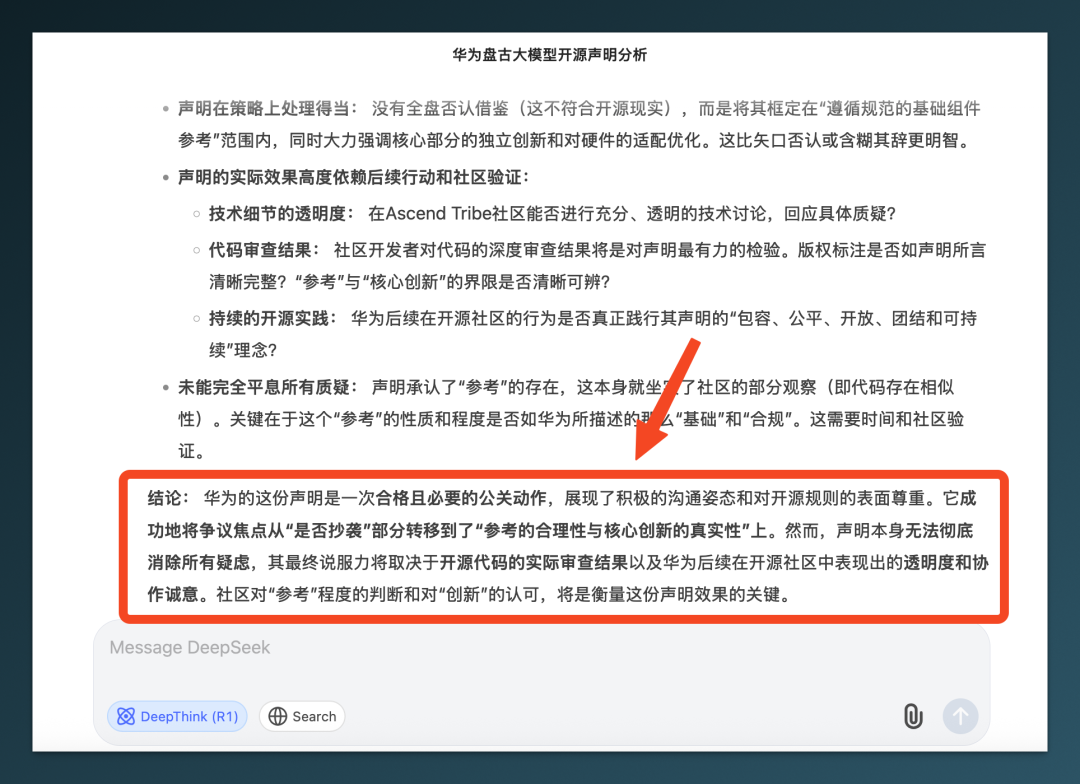
关于华为的回应,DeepSeek-R1 0528 这么看:
“它成功地将争议焦点从“是否抄袭”部分转移到了“参考的合理性与核心创新的真实性”上。然而,声明本身无法彻底消除所有疑虑,其最终说服力将取决于开源代码的实际审查结果以及华为后续在开源社区中表现出的透明度和协作诚意。”
03|内部爆料,让质疑进一步坐实?
更具冲击力的,是来自 GitHub 上一位署名 “HW-whistleblower” 的用户于 7 月 6 日凌晨发布的长文《盘古之殇》。这份接近 6000 字的爆料,由自称是华为员工、盘古团队成员撰写,揭露了大量内部细节与组织乱象。
其中,最关键的指控包括:
-
盘古 135B V2实为Qwen 1.5模型的续训版本,通过“加层、改名”包装成自研产品; -
项目中多处保留
Qwen的类名、路径命名、模型参数组织结构; -
团队原本准备向审计部门举报此事,但被高层压制,称“影响太大”;
-
小模型实验室存在“点鼠标抄模型”的文化,外部模型套壳再宣传为突破;
-
真正训练
135B V3(Pangu Ultra)的团队长期被边缘化,核心成员陆续流失。
以下为长文首页截图,全文可点击文章底部的 阅读原文 获取。

虽然该爆料为匿名,尚未有第三方核实,但内容详实、逻辑完整,多个细节与此前的模型指纹技术报告不谋而合,故而瞬间引发全网广泛关注。
截至目前,仅短短 2 天时间,这个来自华为“吹哨人”、名为 True-Story-of-Pangu 的 GitHub 仓库已收获超过 6600 stars。
04|开源协议,不是免责协议
事件的另一个核心争议点,在于开源协议的合规边界。
阿里的 Qwen 模型采用的是 Apache 2.0 协议,允许他人使用、修改和商用,但前提是:
-
明确保留原始版权信息; -
清晰标注修改内容; -
禁止暗中删除原始来源。
如果只是使用代码框架或工具链,还情有可原。但若直接迁移模型参数、未经披露进行微调、再包装成新模型用于商用,这就已经触碰到“违规红线”。
目前从外部观察,华为并未在盘古开源仓库或官方声明中,对使用 Qwen 权重做出完整说明。即便技术上进行了二次训练,在 Apache 2.0 协议下依旧难以免责。
毕竟,技术归技术,合规归合规。
结语:我们究竟在失去什么?
这场风波的本质,也许不是一次模型“参考”是否合规的问题,而是当一线技术人热血搞研发、后排管理层拼命讲故事,最终把“包装”当成“突破”的那一刻,我们就已经开始输掉比赛了。
从盘古开天,到人设崩塌,这个故事我们不陌生。
而真正令人心痛的,是那些在昇腾硬件上熬夜爆肝、在算力崩盘边缘硬着头皮调模型的人。他们本想扛起国产 AI 的一角,最后却被困在了“别人的模型”里。
如果未来还有“盘古”,愿它名副其实,不用靠指纹识别自己是谁。
我是木易,一个专注AI领域的技术产品经理,国内Top2本科+美国Top10 CS硕士。
相信AI是普通人的“外挂”,致力于分享AI全维度知识。这里有最新的AI科普、工具测评、效率秘籍与行业洞察。
欢迎关注“AI信息Gap”,用AI为你的未来加速。
(文:AI信息Gap)