
在文档数字化和自动化工作流中,离线 OCR 工具因其隐私性和高效率备受青睐。
这两天在GitHub上发现了一个开源、离线、中文识别率极高的 OCR 工具:TrWebOCR。
基于开源项目Tr(一款针对扫描文档的离线文本识别SDK)构建,是一款专为中文设计的离线OCR工具,识别率媲美商业大厂。
结合Tornado框架提供Web界面和API接口,支持快速文字识别和一定角度的文本旋转检测,方便日常使用和程序集成。
核心亮点
-
• 离线运行:本地运行,无需联网,保护数据隐私。 -
• 中文识别精准:识别准确率接近大厂OCR,特别适合中文文档。 -
• 简单易用:提供Web界面,支持拖拽/粘贴上传图片,无需写代码。 -
• API 接口支持:提供标准 Web API,可集成到其他项目中。 -
• 一键部署:提供 Docker 镜像,3 分钟启动本地服务。 -
• 并发支持:通过Tornado多进程实现有限并发,性能依硬件而定。
快速入门
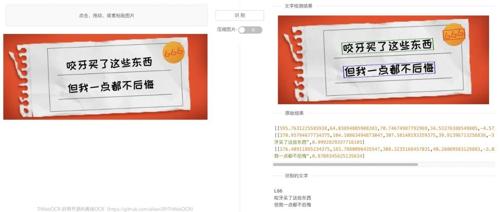
网上也有一个体验地址可以用,就是识别速度慢了些,随手上传了一个带文字的图片。
体验地址:https://trwebocr.haohe.fun
TrWebOCR通过Docker部署,简单高效,以下是快速上手指南:
① 克隆项目
git clone https://github.com/alisen39/TrWebOCR.git
cd TrWebOCR② 使用 Dockerfile 构建(方式一)
# dockerfile 构建
docker build -t trwebocr:latest .
# 运行镜像
docker run -itd --rm -p 8089:8089 --name trwebocr trwebocr:latest ③ 直接 Pull镜像(方式二)
# 从 dockerhub pull
docker pull mmmz/trwebocr:latest
# 运行镜像
docker run -itd --rm -p 8089:8089 --name trwebocr mmmz/trwebocr:latest 这里是把容器的8089端口映射到了物理机的8089上,但如果你不喜欢映射,去掉run后面的-p 8089:8089 也可以使用docker的IP加8089来访问。
同时TrWebOCR它也是支持API接口调用的,下面是一些接口调用示例:
Python 使用File上传文件
import requests
url = 'http://192.168.31.108:8089/api/tr-run/'
img1_file = {
'file': open('img1.png', 'rb')
}
res = requests.post(url=url, data={'compress': 0}, files=img1_file)Base64编码图片,提交识别
import requests
import base64
def img_to_base64(img_path):
with open(img_path, 'rb')as read:
b64 = base64.b64encode(read.read())
return b64
url = 'http://192.168.31.108:8089/api/tr-run/'
img_b64 = img_to_base64('./img1.png')
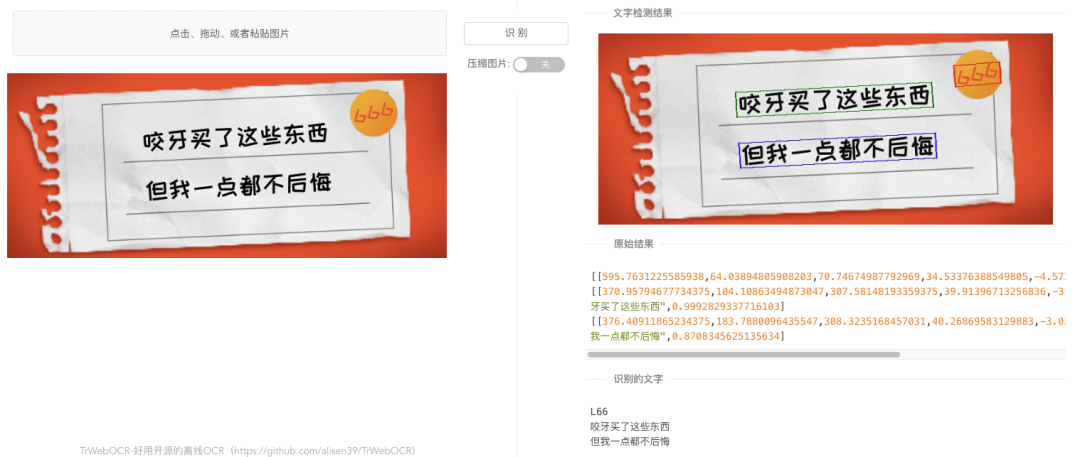
res = requests.post(url=url, data={'img': img_b64})效果展示:
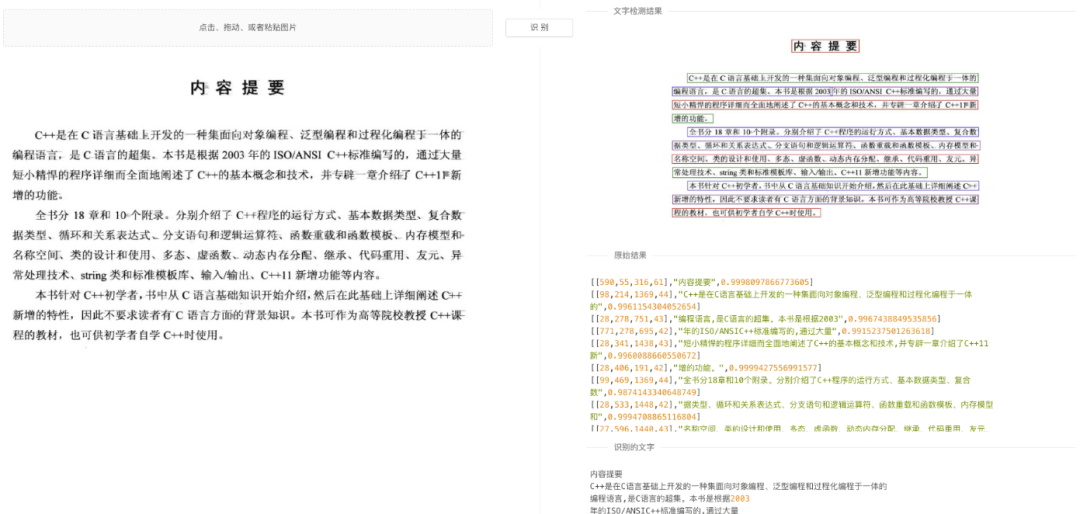
适用场景
-
• 文档扫描:发票、合同、身份证OCR,输出结构化文本。 -
• 学术研究:PDF论文转文本,提取公式/表格。 -
• 企业自动化:API集成,批量处理扫描件。 -
• 隐私敏感:本地运行,适配医疗/法律文档。
写在最后
TrWebOCR 是真正意义上的离线OCR工具,部署完成后即可使用Web界面和API功能。
对开发者也相对友好,适合 Python / Node.js / Java 等环境接入,进行二次开发。
但目前该项目已有两年未更新,实际部署下来效用如何还有待验证,感兴趣的小伙伴可以去试试。
GitHub 项目地址:https://github.com/alisen39/TrWebOCR

● 一款改变你视频下载体验的神器:MediaGo
● 字节把 Coze 核心开源了!可视化工作流引擎 FlowGram 上线,AI 赋能可视化流程!
● 英伟达开源语音识别模型!0.6B 参数登顶 ASR 榜单,1 秒转录 60 分钟音频!
● 开发者的文档收割机来了!这个开源工具让你一小时干完一周的活!
● PDF文档解剖术!OCR神器+1,这个开源工具把复杂排版秒变结构化数据!

(文:开源星探)