


新智元报道
新智元报道
【新智元导读】清华大学朱军教授团队提出SageAttention3,利用FP4量化实现推理加速,比FlashAttention快5倍,同时探索了8比特注意力用于训练任务的可行性,在微调中实现了无损性能。
注意力机制是大模型的核心,能够很好地捕捉上下文信息,但其复杂度会随输入长度呈二次方增长,导致了现有的生成式模型受到上下文窗口的限制,无法高效处理长文本。
量化(Quantization)可以对模型推理过程进行加速,用更低的权重精度换取计算效率,比如在英伟达新一代Blackwell架构GPU中,FP4张量核心比FP16的计算性能要快得多。
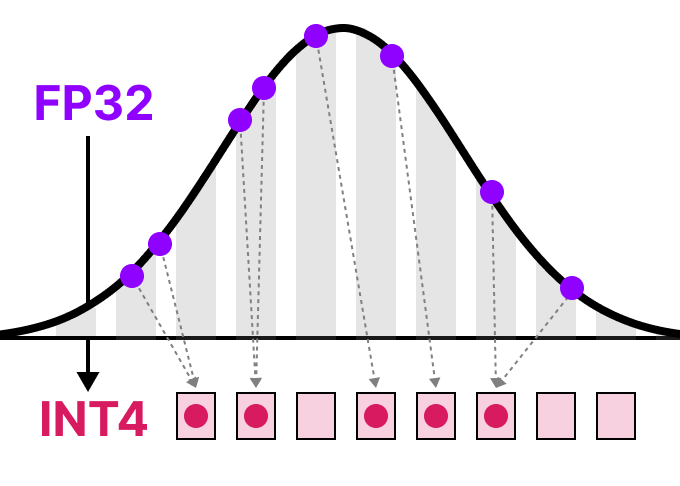
不过FP4量化只有15个可表示的值,无论是按「张量量化」还是按「token量化」,都无法有效保留模型的准确性。
注意力图中的小值集中在[0, 1]范围内,直接量化为FP4会导致缩放因子(scaling factors)的动态范围极其狭窄,硬件上要求量化因子是FP8数据类型,会导致准确率损失下降明显。
现有的研究方向局限于「推理加速」,在训练过程中使用8比特注意力时,注意力图的梯度特别容易受到量化误差的影响,从而导致输入梯度中累积误差。
针对量化加速特性,清华大学朱军教授团队发布了首个可用于推理的FP4注意力机制SageAttention3,也是首次探索「低比特注意力」在大型模型阶段中加速的可行性。

论文链接:https://arxiv.org/pdf/2505.11594
代码链接:https://github.com/thu-ml/SageAttention
SageAttention3将量化组大小限制为1×16,而不是按张量或通道进行量化,可以有效避免块内异常值的影响,同时提高FP4量化的精度。
然后采用两级量化方法,先通过按token量化将每个token的值范围归一化到[0, 448×6],然后使用FP4微缩(microscaling)量化以提高精度,充分利用FP8缩放因子的表示范围。

在反向传播的五个矩阵乘法中,识别出最敏感的矩阵乘法,并将其精度保持在FP16,从而避免因量化误差导致的精度损失。
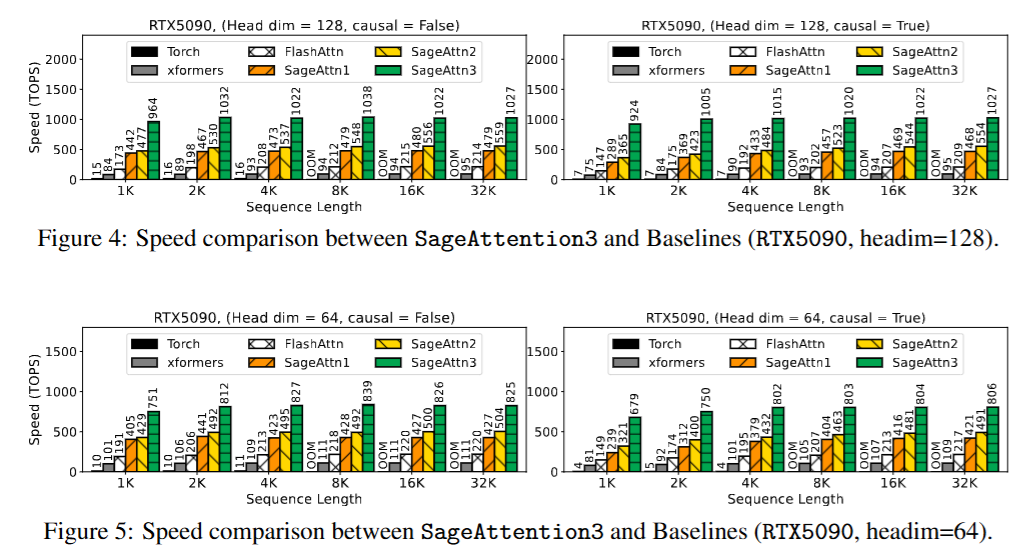
SageAttention3,在RTX5090上实现了1038万亿次每秒运算(TOPS),比FlashAttention快了5倍。
研究人员使用8比特可训练注意力机制(SageBwd)微调基础模型时,在性能上没有任何损失,但在预训练任务中并不适用。

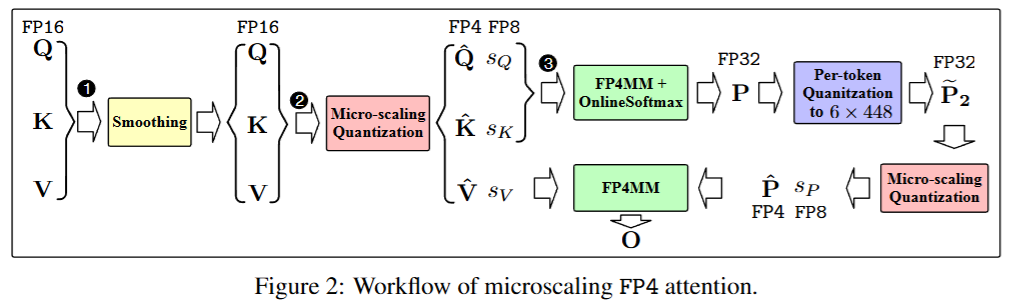

对一个矩阵进行量化处理,将其转换为FP4格式,并使用FP8格式的缩放因子矩阵。
具体操作是:将矩阵X划分为多个小块,每个小块对应一个缩放因子。
量化(Quantization)过程是将矩阵的每个值除以缩放因子后进行舍入,得到量化后的值;
反量化(Dequantization)则是将量化后的值乘以缩放因子,恢复为近似的原始值。
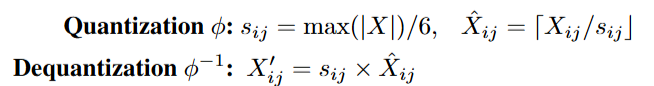
在矩阵乘法中,利用FP4微缩比例量化来加速计算:与传统的FP16精度矩阵乘法(200 TOPS)相比,FP4微缩比例矩阵乘法的速度(1600TOPS)可以提升8倍。
实现方式为FP4MM乘法指令,输入为两个量化后的矩阵和两个缩放因子,输出为矩阵乘法的结果。
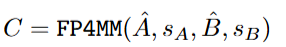
在注意力计算时,研究人员通过将FP4微缩比例量化应用于「查询矩阵和键矩阵的乘法」和「中间矩阵P和值矩阵的乘法」来加速注意力计算。

先将查询矩阵和键矩阵分别量化为FP4格式,并计算缩放因子;使用FP4微缩比例矩阵乘法指令计算查询矩阵和键矩阵的乘积,得到中间结果;对中间结果应用在线softmax操作,得到中间矩阵P;
将P矩阵和值矩阵分别量化为FP4格式,并计算缩放因子;再次使用FP4微缩比例矩阵乘法指令计算P矩阵和值矩阵的乘积,得到最终的输出。

硬件实现基于FlashAttention技术,并采用平滑技术来提高注意力的准确性。
FP4数据类型中,研究人员选择NVFP4,因为其在注意力量化中的精度远高于MXFP4;通过实验验证,NVFP4在CogVideoX模型的所有层中表现出了更高的精度。
直接对中间矩阵P使用FP4微缩比例量化会导致精度损失,因为缩放因子需要从FP32转换为E4M3格式,会降低精度。
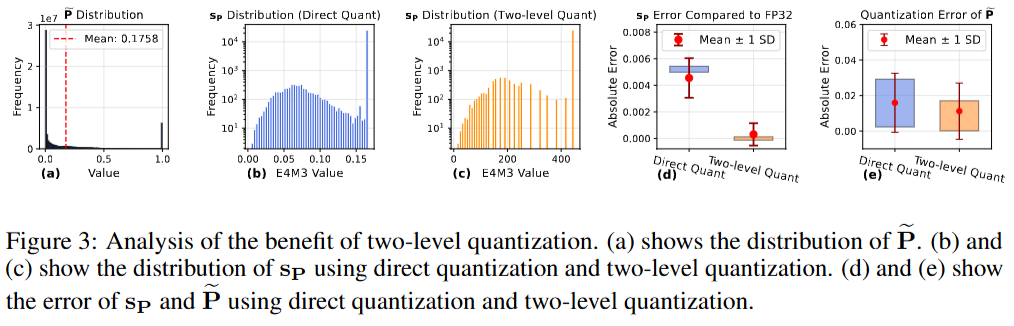
先将矩阵P的每一行的值范围扩展到一个更大的区间,以充分利用E4M3的表示范围,然后对扩展后的矩阵使用标准的FP4量化。
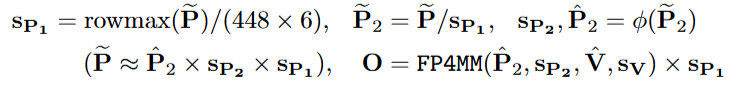
通过这种两级量化方法,能够减少缩放因子的数值表示误差和矩阵的量化误差,从而提高整体精度。
在FP4矩阵乘法(MatMul)中,FP32累加器的内存布局和操作数A的寄存器布局不一样,如果强行对齐,会降低内核的性能。


研究人员的解决办法是调整P块的列顺序,同时为了保证矩阵乘法的正确性,也相应地调整了K的列顺序,整个过程可以和量化操作一起完成。

在对P进行微缩比例量化时,需要找到16个连续行元素的最大值,但这16个元素分布在四个线程中,需要先在每个线程内进行最大值计算,然后在线程之间进行shuffle操作,会显著降低内核的速度。
通过将量化与在线softmax操作融合可以优化该过程,先计算S矩阵中16个元素的最大值,并在后续的softmax最大值计算中重用最大值,可以减少50%的冗余shuffle和最大值计算操作,可以实现大约10%的整体内核加速。
低比特量化注意力机制(例如FlashAttention3和SageAttention)目前主要用于推理阶段,研究人员提出了一种适用于训练阶段的INT8注意力机制(SageBwd),可以将注意力机制中的七个矩阵乘法中的六个量化为INT8格式,同时在微调任务中没有性能下降。
前向
在注意力机制的前向传播过程中,有两个关键的矩阵乘法操作。
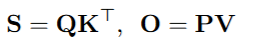
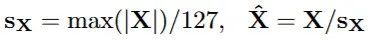
对P采用逐token量化(每个token单独量化),对V采用逐块量化,可以提高注意力机制的精度;利用在线softmax计算过程中已经得到的最大值,可以避免重复计算最大值。
简单来说,对于每个FlashAttention块,先找到块中所有数值的最大绝对值,然后除以127,得到缩放因子;再用该缩放因子去量化块中的值。

后向
对关于值(V)的梯度部分进行量化,会对查询(Q)和键(K)的梯度精度产生很大影响,主要是因为操作的精度直接影响到后续的计算,而误差会在反向传播的过程中不断累积,尤其是当处理很长的序列时,误差会越来越大。
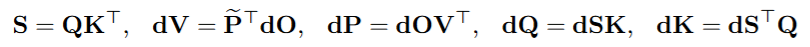
为了避免这个问题,研究人员决定不对该操作进行量化,而是保持其使用更高精度的格式(FP16),同时对其他四个操作使用低精度(INT8)量化来加速计算。

这种方式既提高了计算效率,又保证了梯度计算的准确性。

SageAttention3在RTX5090上的运行速度比FlashAttention快4到5倍,比xformers快8到11倍,同时在各种模型中保持了端到端的性能指标。
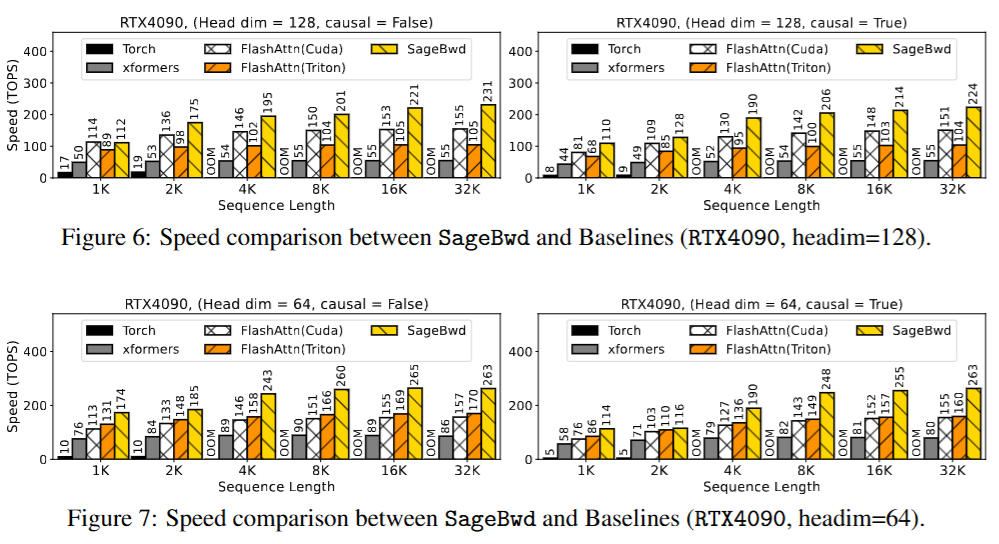
在RTX4090上,使用SageBwd和基线方法测试前向加反向传播速度,结果表明,SageBwd比FlashAttention2最多快1.67倍,比用Triton实现的FlashAttention2和xformers速度提升更高。
端到端性能损失
为了评估SageBwd在训练任务中的有效性,研究人员进行了两组实验。
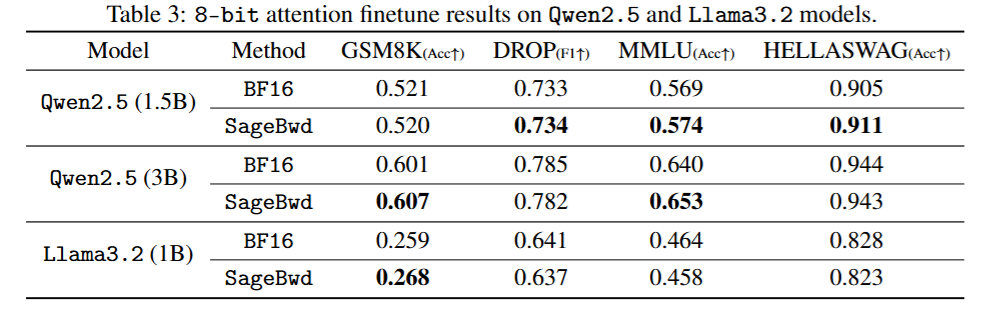
在GSM8K、DROP、MMLU和HELLASWAG数据集上对Qwen2.5(3B)和Llama3.2(1B的基础模型进行了微调,损失结果表明,SageBwd与BF16完全一致。
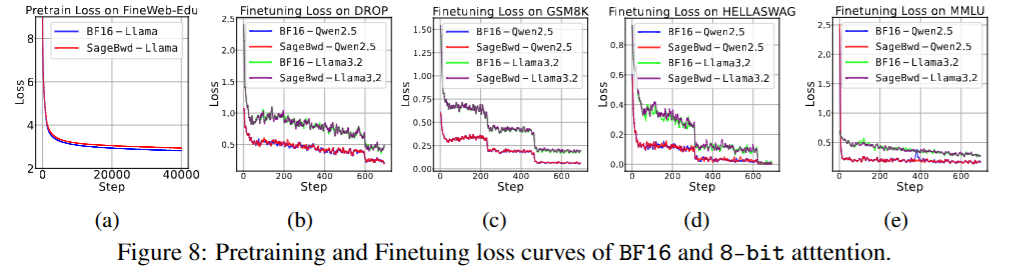
图(a)中,研究人员使用Llama(400M)模型在FineWebEdu数据集上进行了预训练任务,损失曲线表明,虽然SageBwd能够实现损失收敛,但其收敛速度相对较慢,限制了其在预训练任务中的适用性。
研究人员还在多个测试数据集上评估了微调模型的答案质量,结果表明SageBwd的性能与BF16相同。
SageAttention3在HunyuanVideo上进行视频生成和在Stable-Diffusion3.5上进行图像生成的对比表明,SageAttention3完全保持了生成质量。

端到端加速实验结果显示,SageAttention3在RTX5090上实现了大约3倍(HunyuanVideo)和2.4倍(CogVideoX)的端到端推理生成加速。

SageBwd在RTX4090上使用8K/16K token微批次时,将Llama(1B)的训练加速了大约1.15倍。
(文:新智元)