


新智元报道
新智元报道
【新智元导读】大语言模型越来越「聪明」,但缺失记忆:记不住、改不了、学得慢。国内顶尖团队干脆打造出操作系统级的AI记忆框架MemOS,让模型「记得住、改得了、学得快」。相关成果现已开源!关键还可商用。
2024年7月,记忆张量团队首次提出了基于分层记忆建模的忆立方(Memory³)框架,证明了仅依赖参数记忆和检索增强生成(RAG)的模型难以在效率、可追溯性与长期适应性之间取得有效平衡。
这一研究视角深入揭示了当前人工智能在长期知识管理与个性化演进方面存在的本质缺陷。
虽然,以大语言模型(LLM)为代表的AI助手已渗透到生活各个领域,它们足够聪明,也足够博学。
但我们清楚地知道,它们距离真正成为「老师」、「同事」、「专家」或「教练」将面临难以逾越的鸿沟——「记忆」缺失!
我们期待LLM像老师一样,不仅能传授知识,更能因材施教,精准记忆每位用户的优劣与难点,提供个性化指导;或者像同事一样,不仅能协作解决当下的问题,更能通过持续的经验与上下文积累,在未来的协作中更加默契与高效…
这些对记忆能力的深层需求,恰恰是现阶段AI的薄弱环节。
当前的大模型主要依赖两类传统记忆机制:
-
一种是固化在权重中的参数记忆,代表模型的长期知识积累,但更新困难、无法追溯;
-
另一种是只在单轮对话中有效的激活记忆(如KV缓存),虽然响应迅速,却无法形成跨会话的长期认知。
由此带来的结果是,模型能够「看得懂、答得出」,却「记不住、改不了、学不快」:
-
在多轮对话中,模型常常遗忘早期指令;
-
在RAG应用中,新旧知识冲突让模型陷入混乱;
-
面对不同用户时,模型无法沉淀个性化偏好,每次交互都宛如首次见面;
-
…
针对这些核心问题,记忆张量(上海)科技有限公司联合上海交通大学、中国人民大学、同济大学、浙江大学、中国电信等多家顶尖团队,共同研发并开源了MemOS——
一套专为大模型设计的类操作系统级记忆管理框架,致力于全面提升大模型的长期记忆能力和个性化交互体验。

图1:MemOS整体功能架构示意
该项目在Memory3项目(记忆分层大模型)的研究基础上,系统性地将「记忆」视为LLM的核心资源,通过统一管理与调度,旨在填补当前语言模型在结构化、持久性、自适应记忆能力上的关键空白,让大模型真正实现「记得住、改得了、学得快」。
更多关于这个项目的内容可以参考他们的官网、论文、以及开源代码。
官网:https://memos.memtenor.cn
论文:https://memos.openmem.net/paper_memos_v2
代码:https://github.com/MemTensor/MemOS(Preview版本)
如果想要更直接和项目开发团队联系,MemOS团队还提供了微信群和Discord群。
微信群:扫描下方二维码项目
Discord地址:https://discord.gg/Txbx3gebZR

图2:社区二维码
接下来,我们将围绕MemOS的动机、核心概念MemCube、具体实现、记忆调度评估与未来展望等方面进行逐一解析。

「记忆」在学术界和工业界的确也有相关的研究了,一些相关的框架(比如,Mem0,Zep等)也有提出来,但是这些框架在记忆层面普遍存在「弱结构、弱管理、弱融合」的系统性短板。
简单来说,这些框架把「记忆」摆上了台面,让用户意识到可以去主动管理它们。然而,如何设计记忆框架更便于用户对记忆的主动管理仍是难题。
MemOS提出了一种新的范式:将「记忆」从模型运行的隐性副产物,提升为具备生命周期、调度策略与统一结构的「一级资源」,并围绕其构建操作系统级的治理机制。
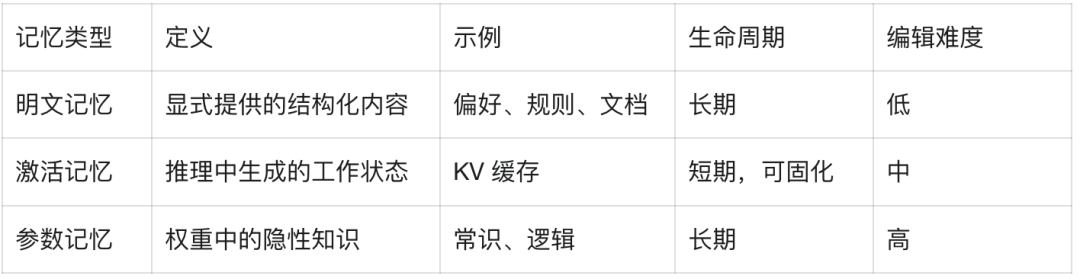
为此,MemOS将复杂的记忆系统性地划分为三类核心形态,为智能体多层次认知打下结构性基础。
-
明文记忆(Plaintext Memory)
指外部提供、可显式管理的结构化知识,如用户偏好、规则文档和上下文注解。它具备可编辑、可审计和可共享的特性,是支持个性化体验和知识动态演进的关键基础。
在Preview版本中,MemOS提供了基于树状结构的明文记忆管理,将外部文档与对话中提取的关键信息转化为Neo4j中的分层树状记忆,实现了高效存储、关系检索与版本追溯。

图3:树状明文记忆示意图
-
激活记忆(Activation Memory)
指模型推理过程中产生的瞬时认知状态(如KV Cache),它扮演着类「工作记忆」的角色,维系对话上下文的连续性与一致性。
MemOS首次将激活记忆抽象为一种可调度的系统资源,支持按需唤醒、压缩与固化,使短期记忆具备演化为长期能力的潜力。
在Preview版本中,MemOS实现了KV Cache的标准化管理,将对话内容依据Chat Template格式进行结构化,并预先存储于GPU中。
这样,当用户再次发起请求时,系统可即时复用缓存,有效缩短解码时延,显著提升记忆的获取效率和推理响应速度。
-
参数记忆(Parametric Memory)
指固化在模型权重中的长期知识,类似于人类的本能与常识。它具备调用速度快、延迟低的优势,是大模型通用能力的重要基座。
通过LoRA等高效微调方法,参数记忆可以模块化注入领域专属知识,实现「即插即用」的能力扩展,帮助模型快速适应多样化场景(该功能在Preview版本中尚未开放)。
图4:三种记忆类型
如何统一存储这三种形态的记忆?MemOS提出了标准化的记忆封装结构——MemCube。
MemCube本身可以是一个Git仓库,MemOS在HuggingFace平台上部署了一个简单的demo MemCube供用户理解与使用。
如此一来,记忆的创建、修改、分发都变得更加现代,也更靠近大模型生态的中心。
图5:MemCube示例
由图5可见,MemCube是一个具备自描述、自管理能力的「记忆原子」。
每个MemCube都包含四种文件:MemCube配置项,明文记忆,激活记忆和参数记忆。
每种记忆文件都可能包括:
-
元数据头:记录时间、来源、权限、生命周期等,用于记忆的溯源和治理。
-
语义负载:承载实际的知识内容或状态。
-
行为指标:自动记录访问频率、相关性等,为记忆的「新陈代谢」(替换、压缩、升级)提供决策依据。
MemCube中的三种记忆形态可以灵活的转换,例如,将频繁使用的明文规则(明文记忆)转化为激活模板(激活记忆),或将稳定的行为模式(激活记忆)蒸馏为轻量级参数模块(参数记忆),让记忆系统具备了「生长、重构」的自主演化能力。
从代码功能角度来看,MemOS构建了一套包含接口、操作、基础设施的三层体系架构。
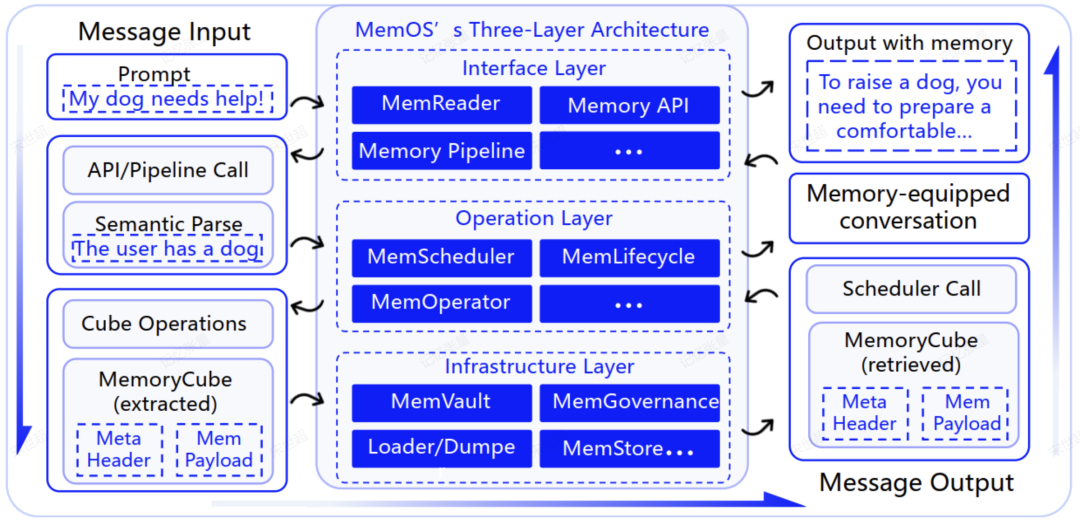
图6:MemOS代码实现架构
-
接口层(Interface Layer)
提供标准化的MemoryAPI,能自动理解「存入这条偏好」、「忘记上次的风格」等自然语言指令,并将其转换为结构化的记忆操作。当前Preview版本以MOS类为具体实现。
-
操作层(Operation Layer)
系统的控制核心。它能根据任务上下文智能调度(MemScheduler)、管理记忆生命周期(MemLifecycle)并高效组织海量记忆(MemOperator)。当前Preview版本开包括MemScheduler这个模块的简单实现。
-
基础设施层(Infrastructure Layer)
提供底层支撑,目前主要包括:
-
MemCube:是对底层记忆管理的最大封装,在这里实现对MemCube的load、dump、download、upload等记忆市场式行为
-
记忆管理:当前包括树状记忆管理、向量记忆管理等
-
一些其他模块支持:持久化存储(Graph DB,Vector DB等)、模型(OpenAI,HuggingFace,Ollama等)等
在传统的大模型问答系统中,生成流程依然遵循同步的Next-Token机制:模型接收用户问题→实时检索外部片段→按token逐字生成答案。
检索或计算产生的任何停顿,都会直接拉长整条推理链路,知识注入与生成紧密耦合,导致GPU容易出现空等,用户端响应时延明显。

图7:记忆调度
与这种传统范式不同,MemOS从记忆建模的视角出发,提出了记忆调度范式,通过设计异步调度框架,提前预测模型可能需要的记忆信息,显著降低实时生成中的效率损耗。
MemOS实现了针对MemCube中的三种核心记忆类型(参数记忆、激活记忆、明文记忆),以及外部知识库(包括互联网检索与超大规模本地知识)等多元知识的联合调度。
依托对对话轮次与时间差的精准感知,系统能够智能预测下一个场景中可能被调用的记忆内容,并动态路由与预加载所需的明文、参数和激活记忆,从而在生成阶段即刻命中,最大化信息引入的效率和推理的流畅性。

为系统性验证MemOS在真实应用场景下的表现,MemOS团队基于LoCoMo数据集进行了全面评测。
作为当前业界广泛认可的记忆管理基准,LoCoMo已被多种主流框架采用,用于检验模型的记忆存取能力与多轮对话一致性。
从官方公开的评测数据来看,MemOS在准确率和计算效率上均实现了显著提升,相较于OpenAI的全局记忆方案,在关键指标上展现出更优的性能表现,进一步验证了其在记忆调度、管理与推理融合方面的技术领先性。
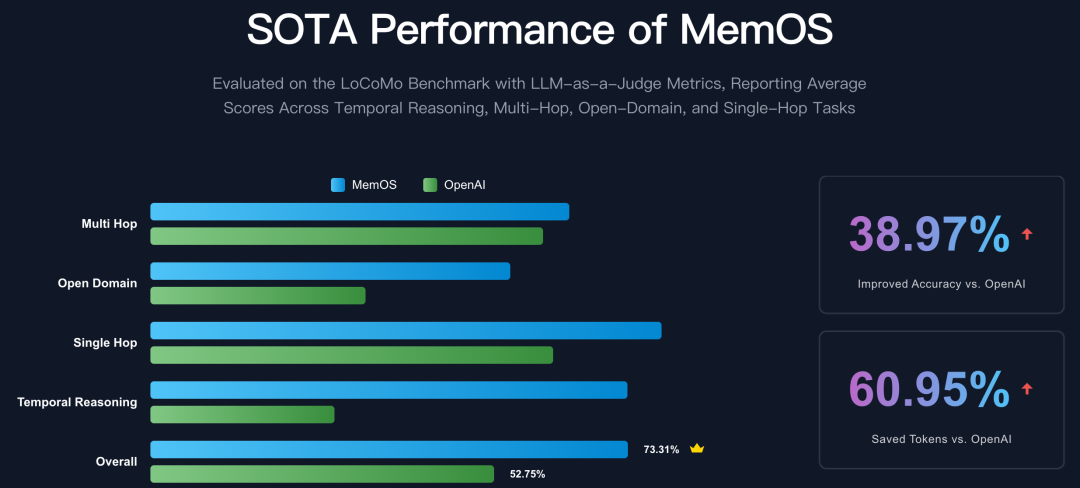
图8:基于LoCoMo基准的对比评测结果
其论文中也提供了更详尽的对比实验结果,我们可以清晰地看到:
-
单跳(Single Hop)任务:MemOS在LLMJudge Score、BERT-F1和METEOR等多个指标上均显著优于其他模型,尤其在准确率方面表现突出,充分体现了其在直接记忆召回场景下的高效性与可靠性。
-
多跳(Multi Hop)任务:MemOS依然保持领先,F1和ROUGE-L(RL)指标均高于同类方法,验证了其在复杂推理和多步信息融合任务中的稳定性与优势。
-
开放域(Open Domain)任务:MemOS显著提升了准确率与召回率,F1分数从传统模型的29.79提升至35.57,表明在处理范围更广、问题不确定性更高的任务时,具备更强的泛化能力。
-
时间推理(Temporal Reasoning)任务:MemOS的表现尤为突出,F1、ROUGE-L和BLEU-1(B1)指标均大幅领先,展现了其在理解和推断事件时间关系方面的卓越能力。
-
总体(Overall)评测:MemOS不仅在各项核心评分指标中持续领跑,还能在保持较低内存上下文规模(Chunk/Mem Token)的前提下实现较高准确率,充分体现了效率与性能的良好平衡。
综上,凭借系统级优化与灵活的记忆调度机制,MemOS在多轮对话记忆管理的多样化任务中均展现出出色的表现,整体性能优于当前主流的多种基线方法。
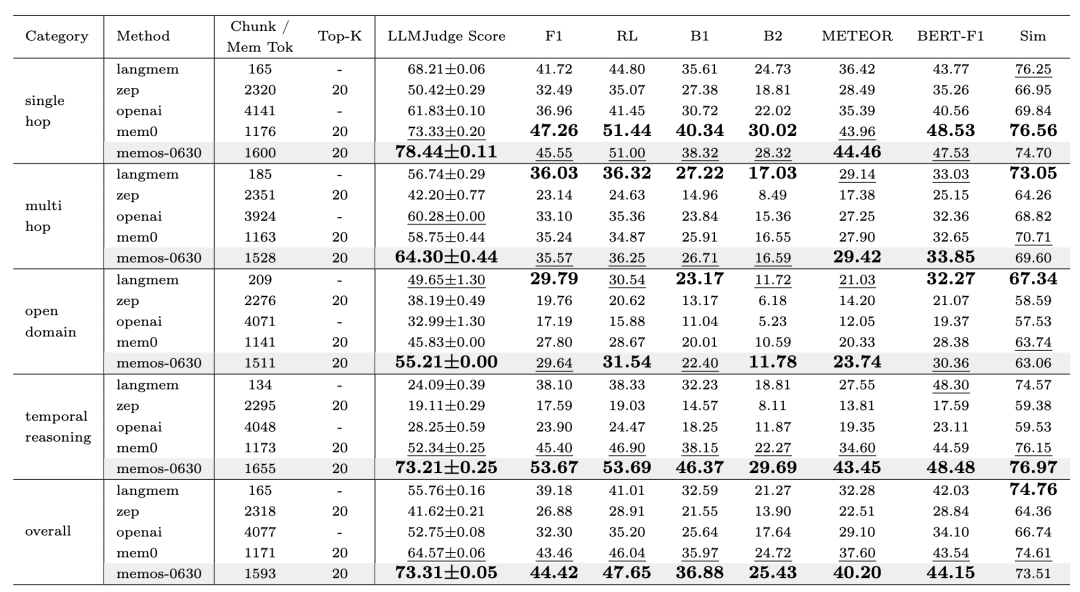
图9:完整评测结果
除了通用的记忆能力评估,研究团队还重点考察了MemOS所提出的KV Cache记忆机制在推理加速方面的实际效果。
通过在不同上下文长度(Short/Medium/Long)以及不同模型规模(8B/32B/72B)下进行对比测试,系统性评估了缓存构建时间(Build)、首Token响应时间(TTFT)以及整体加速比(Speedup)等关键指标。
实验结果(见图10)表明,MemOS在多种配置下均显著优化了KV Cache的构建与复用效率,使推理过程更加高效流畅,有效缩短了用户的等待时延,并在大规模模型场景中实现了可观的性能加速。
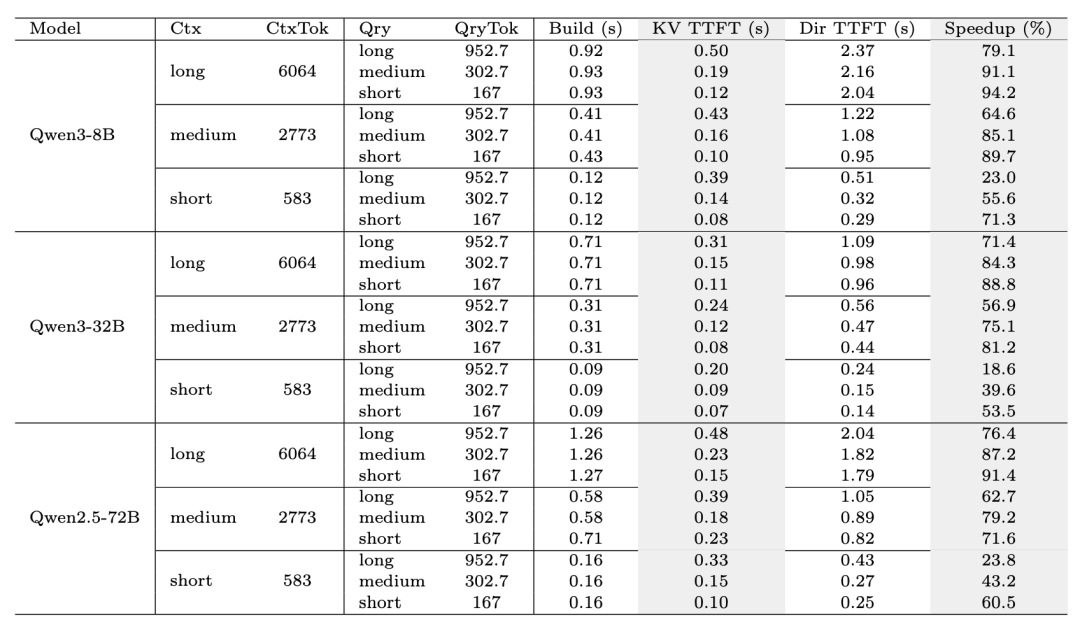
图10:KV Cache评测结果
实验结果表明,随着模型规模和上下文长度的增长,KV缓存带来的加速收益呈现显著上升。
以Qwen3-8B为例,在长上下文条件下,首Token响应时间加速比最高达到94.2%;在超大规模模型Qwen2.5-72B上,依然能稳定保持在70%以上,显著提升了多轮推理的响应速度和算力利用率。
这些结果进一步验证了,在「高频调用+长期记忆」的实际生产场景中,缓存复用是提升系统吞吐与用户体验的关键路径,也为未来打造更高效、更智能的记忆调度器奠定了坚实的技术基础。
随着大模型的发展逐步进入规模边际收益递减阶段,从以数据和参数为中心转向以「记忆」为中心的范式变革,正成为推动模型能力跃迁的关键路径。MemOS作为首个将「记忆」纳入系统级治理的基础设施,正在为下一代AGI打造一个「可管理、可迁移、可共享」的运行底座。
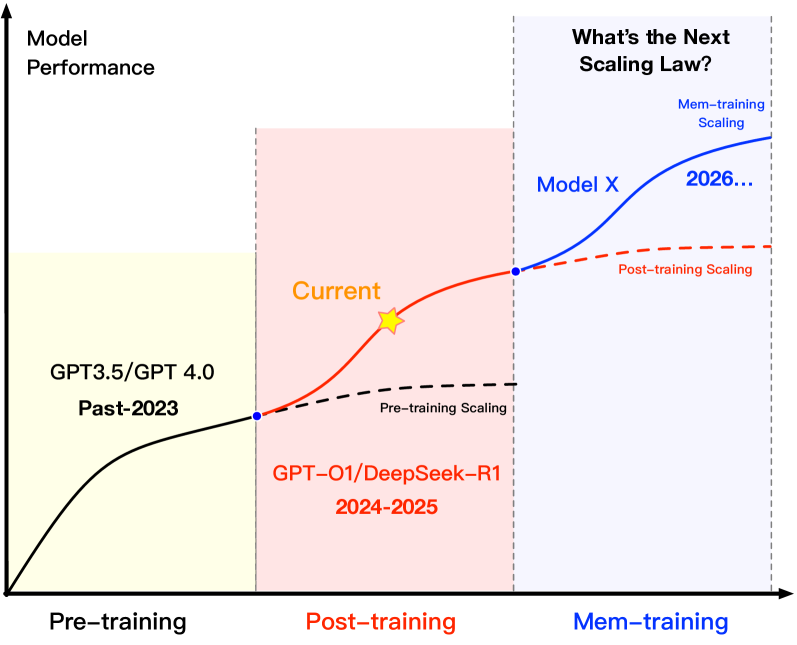
图11:Mem-training Scaling
为了进一步释放记忆的潜力,研究团队提出了一个更具前瞻性的目标:构建一个去中心化的记忆生态系统(Memory Ecosystem)。
基于通用的记忆互操作协议(MIP,Memory Interchange Protocol),未来的AI智能体将具备以下能力:
-
携带记忆,跨平台迁移:用户在一个应用中积累的偏好和知识,可以无缝迁移至另一个应用,从根本上消除「记忆孤岛」,让体验更具连续性。
-
交换经验,协同进化:不同模型或智能体能够在安全合规的前提下共享、复用彼此的记忆,共同形成一个互联互通的智能网络。
-
记忆资产化:记忆不再是「模型的私有数据」,而是一种可管理、可共享、甚至可交易的智能资产,推动智能生产力的重构。
通过将记忆管理从模型推理中成功解耦,MemOS正在助力大模型从单一的语言处理器迈向具备持久认知能力的个性化智能体,为通向通用人工智能铺设新的基础设施。
MemOS生态的持续演进与共享共建,离不开社区的深度参与和多方协作。为此,研究团队发起并打造了一个开放、协作、共创的大模型记忆技术社区——OpenMem,致力于推动记忆管理、记忆增强与记忆共享的研究与应用走向可管理、可迁移、可共享的新阶段。
当前社区由来自记忆张量、上海交通大学、同济大学、浙江大学、中国科学技术大学、北京大学、中国人民大学、北京航空航天大学、南开大学、上海算法创新研究院等高校研究团队等研究+产业团队共同组成,社区热烈欢迎对AI模型记忆感兴趣的研究或产业团队加入,共建开放记忆底座,赋能智能系统普惠未来。
联系方式:contact@openmem.net
社区团队也规划了下一阶段的部分关键迭代方向,欢迎开发者加入共建:
-
参数记忆插件化适配:根据具体任务或上下文预测结果,动态路由最合适的LoRA模块,实现类似MoE(Mixture of Experts)的参数记忆架构,支持快速注入领域知识。
-
MemCube多模态扩展:在现有结构基础上,新增图像、音频、视频等跨模态记忆的封装与调度能力,拓展系统的应用边界。
-
跨智能体记忆迁移机制:设计安全隔离的沙盒环境,支持不同智能体之间的记忆迁移、审计与复用,推进通用记忆互操作协议(MIP)的实践探索。
-
LoCoMo评测集扩展:拓展中文任务,提升对实际应用场景的覆盖能力。
-
场景化端到端评测框架:当前如LoCoMo等评测方案主要覆盖记忆管理中的部分环节,缺乏对完整交互链路的评估。下一阶段将构建面向实际应用的端到端场景化评测体系,更全面衡量不同记忆框架的效果与效率。
-
OpenMem CLI工具:一键生成记忆工程模板,联通向量库、图数据库与远程MemOS节点,加速开发流程。
-
VSCode插件:集成MemCube管理与调试能力,支持开发者在熟悉的工作环境中进行记忆内容的可视化操作与调试。
记忆张量(上海)科技有限公司是上海算法创新研究院孵化的新型大模型公司,由中科院院士担任首席科学顾问。
公司聚焦基本原理驱动的系统性创新,以「低成本、低幻觉、高泛化」为核心特色,致力于探索符合中国国情的大模型发展新路径,推动AI应用更广泛落地。
公司持续围绕大模型记忆增强与管理框架进行技术迭代,自主研发的基于记忆分层架构的「忆³」大模型已实现商业化落地,业务稳步增长,获得招商证券、中国银行、中国电信等头部国央企业认可。

新天终启,万象智生——万年奇点时刻,谁将引爆中国ASI?


(文:新智元)