
从监测自然灾害到评估城市发展规划,地球观测数据为我们提供了宝贵的决策依据。但如何高效地理解和分析这些复杂的数据,一直是科学家们面临的巨大挑战。
现有的多模态模型虽然在通用图像理解任务中取得了显著进展,但在地球观测数据的理解上表现不佳。这主要是由于地球观测数据与通用图像之间存在巨大的领域差异,导致这些模型难以直接应用于地球观测任务。
为了解决这些难题,意大利特伦托大学、德国柏林工业大学、慕尼黑工业大学等研究人员联合开源了多模态大模型EarthMind,能够同时处理多粒度和多传感器地球观测数据的统一框架。

开源地址:https://github.com/shuyansy/EarthMind
地球观测图像通常具有复杂的场景和多样的目标,这使得模型在进行像素级理解时面临巨大挑战。例如,建筑物、道路或自然地形等目标可能因尺度变化、纹理模糊或语义边界不清晰而难以准确识别。现有的多模态模型在处理这类图像时,往往会出现注意力分散的问题,导致无法精准聚焦于目标区域。
为了解决这一问题,EarthMind引入了空间注意力提示(SAP)模块。SAP的核心思想是通过显式地提取和重新分配注意力,将模型的注意力引导到与查询对象相关的区域。
在模型的推理过程中,SAP通过计算分割令牌与图像令牌之间的交叉注意力图,识别出模型对目标区域的关注程度。然后,利用真实标注的掩码作为监督信号,通过最小化注意力图与目标分布之间的Kullback-Leibler(KL)散度,引导模型将注意力更准确地集中在目标区域。
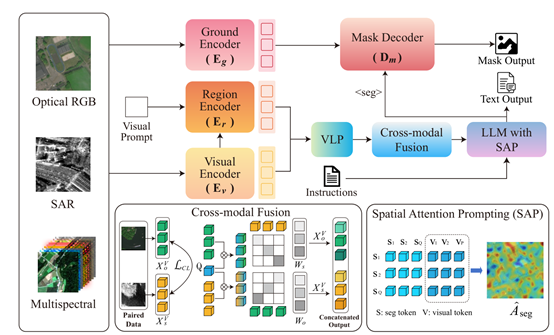
SAP通过计算每个图像令牌与分割令牌之间的注意力权重,生成一个注意力图,该图反映了模型对不同区域的关注程度。然后,通过与真实标注掩码的对比,调整注意力图,使其更符合目标区域的实际分布。这种监督学习的方式使得模型能够逐渐学会如何在复杂的地球观测图像中准确地定位目标,从而在像素级任务中表现出色。
地球观测数据的另一个重要特点是多模态性。光学影像(如RGB和多光谱)和合成孔径雷达(SAR)是两种常见的传感器模态。光学影像提供了丰富的纹理和光谱信息,但在恶劣的天气或光照条件下可能会受到限制;而SAR影像则能够在任何天气条件下捕捉到结构细节。将这两种模态的数据有效融合,对于全面理解地球观测场景至关重要。
EarthMind的跨模态融合模块通过两个关键步骤实现:模态对齐和模态互注意力。在模态对齐阶段,模型采用在线对比学习策略,将非光学特征(如SAR)与光学特征空间(RGB)对齐。
通过计算成对的跨模态图像令牌之间的余弦相似度,并利用对比损失函数进行训练,使模型能够将不同模态的特征映射到一个统一的语义空间中。这一过程确保了不同模态的数据能够在相同的语义框架下进行交互和融合。
在模态互注意力阶段,模型进一步通过学习查询来提取每个模态的邻域感知特征,并计算跨模态的重要性权重。这些权重反映了在跨模态上下文中,SAR和RGB令牌的相关性,模型根据这些权重对特征进行加权,从而在下游语言模型推理中强调最具信息量的表示。
这种动态加权的方式使得模型能够根据不同的任务和场景,灵活地调整对不同模态数据的依赖程度,从而实现更鲁棒的多模态理解。

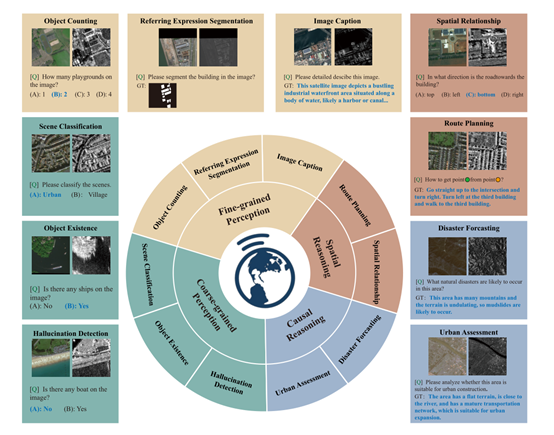
在多粒度理解方面,EarthMind通过其视觉编码器、区域编码器和分割编码器,分别处理图像级、区域级和像素级的任务。这些编码器生成的特征被投影到一个共享的语言空间中,使得模型能够在不同粒度的任务之间进行有效的交互和推理。例如,在图像级任务中,模型可以利用全局语义信息进行场景分类;
在区域级任务中,模型可以识别和描述特定区域的对象;而在像素级任务中,模型则可以进行精确的目标分割。这种多粒度的理解能力使得EarthMind能够适应各种复杂的地球观测任务。
(文:AIGC开放社区)