新智元报道
新智元报道
【新智元导读】Atharva博客揭示,AI是工程师能力的放大器。扎实的编程基础搭配精准提示,能让AI助你打造出极致产品。想知道如何用AI加速开发、少踩坑?快来看高手的秘诀!
最近,Karpathy在YC AI创业学校演讲中推荐了一篇博客。
这篇博客中,Atharva表示,AI是放大器,coding功底越扎实,AI给的助力就越猛。
当你能用精准的提示词拆解需求,当对系统设计有敏锐直觉,AI会把你的能力指数级放大;反之,模糊的指令只会让AI输出漏洞百出的代码。

AI是打造认真、靠谱产品的工程团队的好帮手,这需要对这些工具有着娴熟的驾驭能力。
用AI开发,速度快得飞起!用对了,团队能更快地缩短与用户的反馈闭环,从而打造出更优秀的产品。
然而,用好AI工具也颇具挑战。用得不好,代码可能稀烂,甚至拖慢进度,深陷于垃圾代码和技术债务的泥潭。


想让AI发挥出色效果,首先要提升自己的水平。
AI是一个放大器。如果你的能力很差,收益自然微不足道;如果你的能力系数为负,收益甚至可能是负值。

最优秀、经验最丰富的工程师能从 AI 工具中榨取更多价值,原因如下:
-
极其擅长沟通技术理念,会把技术想法讲清楚;
-
对构建优质系统有精准的判断力和敏锐的直觉,能引导AI朝正确方向前进,即「老师傅的手感」;
-
基础扎实,能在知识(而非技能)构成瓶颈的新工具和系统中能迅速上手;
-
AI对语言和风格很敏感,常常反映出提示者的偏好与审美。顶尖工程师品味高,对什么可行、什么不可行,有着更为敏锐的品味和直觉。
所以,要秉持工匠精神。就算AI帮忙,也要对产出成果感到骄傲,这点在AI系统的最终产出中得到了清晰的印证。
举个例子。下面这个提示词不算差,但显然不够深思熟虑:
写一个Python速率限制器,限制用户每分钟10次请求。

这个提示词能生成一个勉强可用的结果,但很可能会忽略一些边缘场景、最佳实践和质量标准。
相比之下,高手可能会这样提问:
请使用Python实现一个token桶速率限制器,并满足以下要求:
针对每个用户(通过
user_id字符串识别),速率限制为每分钟10次请求。实现必须是线程安全的,以支持并发访问。
能自动清理过期用户的条目。
函数返回一个元组
(allowed: bool, retry_after_seconds: int),分别表示请求是否被允许,以及需要等待多少秒后才能重试。需考虑以下问题:
token是应该随时间逐渐填充,还是一次性补满?
当系统时钟发生变更时,程序的行为应是怎样的?
如何防止因用户长时间不活跃而导致的内存泄漏?

优先考虑简单、可读性强的实现,避免过早优化。请仅用Python标准库(stdlib),不要引入Redis或其他外部依赖。
哪个提示词能更好地实现设计者的意图?一目了然吧!
还有个卓有成效的技巧,叫「元提示」(metaprompting)。
先给模型一个简单任务,让它帮忙挖出需要权衡的因素和潜在的边界情况,整理成技术规格,再让另一个AI智能体去执行。
实际上,上面那个「高手提示」就是AI帮忙优化的,AI现在已经很擅长为自己写提示词了。
AI工具的玩法总在变,但有一条金科玉律:努力提升自己,成为一名优秀的工程师,你的习惯会迅速传递给AI。
这之所以有效,根本原因在于:凡是能帮人类更好地思考和工作的方式,同样也能帮助AI。

在AI技术进步带来颠覆性变革的今天,有必要重新审视软件工程的定义。
软件工程的核心不是光写代码,至少,这并非它的决定性特征,正如写作的本质并非只是在纸上挥洒笔墨。
软件工程是一门艺术与科学,旨在维护一个庞大且定义明确的心智模型体系,以满足业务需求。核心是打造和维护复杂的社会技术系统,代码只是一种表现形式。
在AI强大到足以吞噬整个社会技术系统,并把培育它的人全踢出去之前,它必须要融入这个系统。
换句话说:在一个同样适合人类发展的环境中,AI也能更好地茁壮成长。这意味着,团队必须具备扎实的软件工程基础。

AI偏好的高质量团队和代码库有这些特征:
-
良好的测试覆盖率、有意义的断言;
-
自动化代码检查、格式化和测试,在代码合并前执行;
-
持续集成与持续部署 (CI/CD);
-
完善的变更文档、技术规格(tech specs)、架构决策记录(ADRs),以及清晰的提交信息;
-
代码风格统一,通过格式化工具强制执行;
-
简单、简洁、结构清晰的代码;
-
功能定义清晰,拆分为多个小型的故事卡。
当今的AI能利用所有这些要素,自动搞定任务。
给一个编程智能体分配任务时,它会在其智能体循环中,通过运行测试用例和静态分析工具来不断进行自我修正。
这极大地减少了为完成工作,而需要进行的手把手干预。丰富的环境与上下文,能帮助AI更好地工作。
在此分享一则轶事:Atharva曾参与一个项目,其中包含两项服务。
一项服务具备上文描述的所有优点——良好的测试、完善的文档、一致的代码模式以及大量的检查与防护机制。而另一项服务则混乱不堪,上述优点一概皆无。
结果,AI编程智能体在处理后者一个同等难度的任务时举步维艰,远不如处理前者时那般顺利!
这很可能是因为,那个混乱的代码库对AI造成的困惑,与对人类工程师造成的并无二致。
对于何为正确的行事方式,它传递出了混乱甚至矛盾的信号。
战略讲完了,来点干货战术:
不计成本,使用最好的AI模型
务必使用当前最顶尖的编码模型,不要为了节省额度或开销而选择次级模型。
优质模型带来的优势会产生复利效应。拥有一个强大的编程模型作为基础,接下来介绍的所有战术都将事半功倍。
提供精准的上下文
AI辅助编程的效果,很大程度上取决于为LLM提供上下文的技巧有多娴熟:
-
用智能体式(agentic)编码工具,能自主读取文件、运行shell命令、获取文档、创建并执行计划、几乎无需人工干预(只需最终批准)。推荐的工具有Claude Code、Windsurf、Cursor、Cline。
-
AI容易被杂乱上下文带偏。应该只@相关代码文件,链接对当前任务有帮助的文档,帮助它聚焦。
-
将编码规范写入
RULES.md文件,为不同的智能体工具(如.cursorrules,.windsurfrules,claude.md,agents.md等)创建指向此文件的符号链接(Symlink)。
开发新功能或重构
-
拆解问题。指令越具体,AI的表现就越好。AI还能帮忙把提示写清楚,让指令变得更清晰、更具体。推理能力强的模型尤其擅长此道!
-
化整为零,逐一击破。在开发大型功能时,应将其拆分为多个小任务,然后逐个交给AI处理,并在完成每个任务后进行一次代码提交(commit)。如果你遵循用户故事(story)的工作流,包含任务清单的故事卡描述对AI就是一份极佳的指南。
-
提供技术规格与相关文档。不要在缺少产品宏观背景的情况下直接要求AI写代码。应向其提供技术规格,以及所用程序库的官方文档。对于大多数工具而言,直接粘贴文档链接通常是有效的。有些程序库甚至会提供一个
llms.txt文件,专供编码智能体使用。 -
好的模式是把开发分成「计划」和「执行」。一些先进的编程智能体已经内置了类似的流程。
-
审慎对待AI的建议。不要将其建议视为理所当然,让它解释选择的理由,提出替代方案,分析方案的优劣。
调试
-
用AI调试自己的bug。当AI生成的代码出错时,务必将最相关的错误上下文完整粘贴给它,以帮助其定位问题。(如使用专门的XML标签,如
<error>,将错误日志或输出内容包裹起来)。 -
提供尝试和观察。向模型说明已经尝试过的调试步骤和额外的观察发现,这能帮它形成正确的假设并排除错误的推断。提供丰富的上下文至关重要。
用AI提升个人技能与知识
AI是一位拥有海量知识、具有高效研究能力,超级有耐心的老师。
应积极用AI学习新知,揭开陌生代码或技术栈的神秘面纱。坚持不懈地深入挖掘,探寻最佳实践。同时,务必让AI引用高质量的信源,确保学到的知识准确无误。
创建海量详尽文档
把代码库信息提供给AI,就能轻松地创建大量细致的文档。比如:
-
阐释功能,创建项目知识库;
-
汇总当前所有的监控指标;
-
智能识别缺失的测试用例。
这样做的好处显而易见——如今,生成文档的成本已极其低廉,而这些文档又能反过来极大地提升AI以及人类成员的工作效率。
解决日常协作小摩擦
AI能极大降低团队日常工作中遇到的各种小阻力:
-
利用AI创建模拟服务器(mockserver),用于协调前后端团队的工作,消除开发过程中的阻塞。前后端对好接口契约就能开工;
-
通过向AI提供shell历史会话记录,为基础设施部署、常见故障排查等场景创建运行手册(runbook)和指南;
-
将现有的运行手册和指南提供给AI,让它将其转化为能自动执行常见任务的脚本。
代码评审 (Code Review)
-
为合并请求(Pull Request)创建一个模板,将每个功能的代码变更提交给AI,让它解释变更和部署步骤;
-
为了缩短首次代码评审的响应时间,可以引入代码评审机器人来完成初步检查。但切勿完全取代人工评审!
-
作为评审者,当你遇到不理解的代码变更时,可以先让AI解释。向它寻求澄清,在获得了必要的背景信息后,再向开发者提问。
调试和监控线上应用
-
用AI的深度研究能力,寻找罕见错误的解决方案。调试线上问题时,可遵循与在编辑器中调试时相同的建议:提供尽可能丰富的上下文;
-
AI非常擅长为可观测性工具编写查询语句和告警规则,还能写Python代码分析和处理数据。
性能优化
-
用AI优化数据库和调校配置。此时,务必向其提供有关基础设施和硬件的上下文信息,并分享查询计划(query plan)。
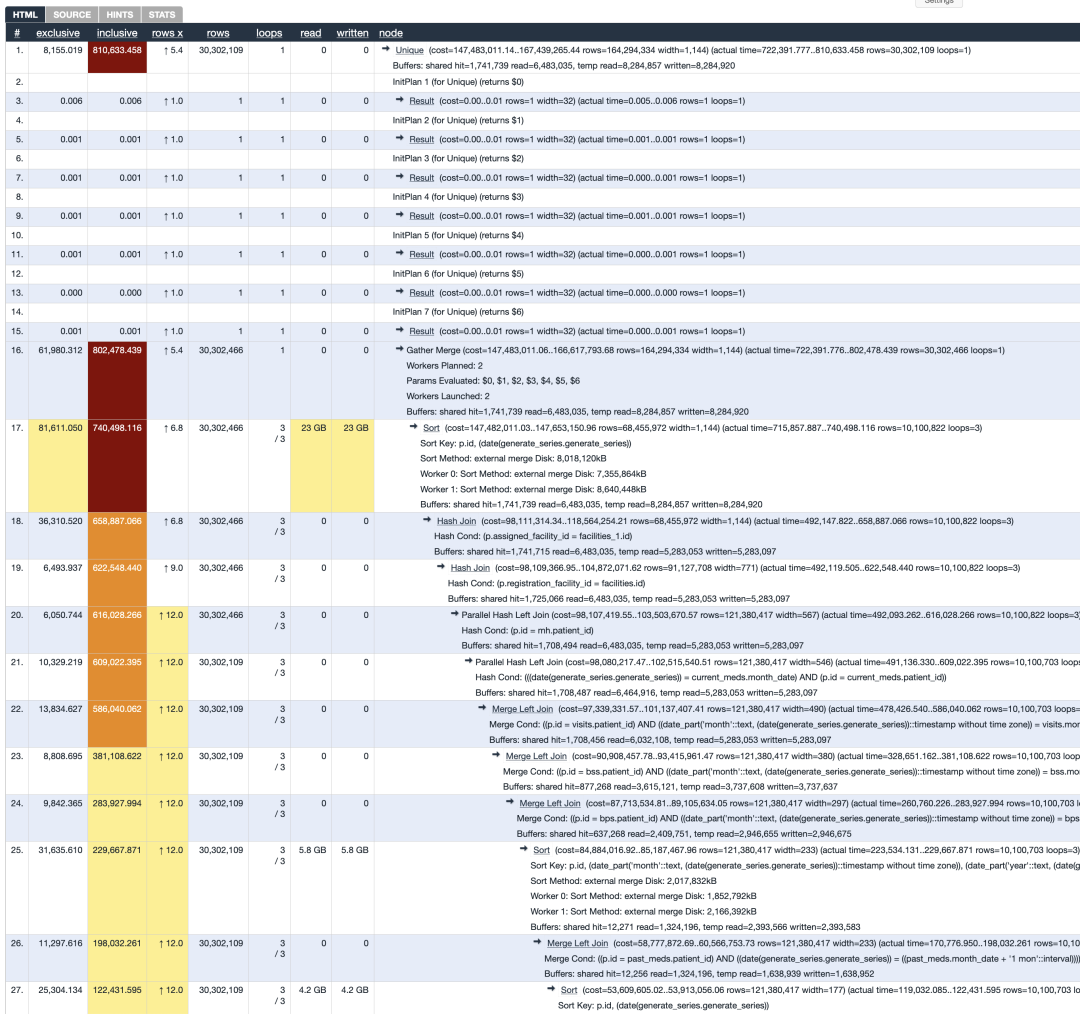
下面是近期一次互动实例:优化PostgreSQL中的一整套查询。
每天要执行大约十次查询,每天一次,用于生成一组用于分析的报表,基于事务表的非规范化视图。这些查询庞大且缓慢。
作为一名训练有素的工程师,他挑出最慢的查询,然后:
EXPLAIN ANALYZE <my slow query>等待了13分钟后,得到了一份相当友好的输出。
感谢像Hubert depesz Lubaczewski这样的好人,提供了一个很棒的工具来处理这些相当友好的输出。
通过这个工具,输出变得更加友好,一个大大的红框跳出来,清楚地告诉他哪里出了问题。
但他训练有素的工程师大脑却在想:现在该怎么办?!
Sir depesz的工具暗示了一个
work_mem问题,这是一个可以在夜间运行这些查询时调整的旋钮。这比重写一个200行的、关联了整个世界的SQL查询要实用得多。但该如何思考和推理这个问题?硬件能支持什么?他对PostgreSQL的旋钮调整几乎没有经验。
在上述故事发生前一个月,也就是2024年10月,人们对一个当时被称为Sonnet 3.5(新版)、如今被称为Sonnet 3.6的模型赞不绝口。当时它无疑是最好的AI模型。
他把查询计划和硬件规格塞给了Sir Sonnet 3.5(新版),以下是提示:
This is a PostgreSQL EXPLAIN ANALYZE outputTell me what configuration parameters I can tune to make this go faster.<system_info>RAM = 32 GBCurrent parameters:synchronous_commit: "on"max_connections: "200"shared_buffers: "8GB"effective_cache_size: "24GB"maintenance_work_mem: "2GB"checkpoint_completion_target: "0.9"wal_buffers: "16MB"default_statistics_target: "100"random_page_cost: "1.1"effective_io_concurrency: "200"work_mem: "20971kB" # NOTE: but for just this query, we temporarily have set it to 1.5GB, which is the most we can push it safelymin_wal_size: "1GB"max_wal_size: "4GB"max_worker_processes: "4"max_parallel_workers_per_gather: "2"max_parallel_workers: "4"max_parallel_maintenance_workers: "2"</system_info>Sir Sonnet回应道:# PostgreSQL Performance Analysis## Key Performance Metrics- Total Execution Time: 813.4 seconds (13.5 minutes)- Planning Time: 26.5ms- Total Rows: 30,302,109- Buffer Usage:- Shared Hit: 1,741,739- Shared Read: 6,483,035- Temp Read: 8,284,857- Temp Written: 8,284,920## Major Performance Issues Identified1. **Heavy Disk I/O for Sorting**- Multiple large external sorts occurring- Largest sort using 8018MB of disk space- Many temp buffers being read and written2. **Parallel Query Execution Limitations**- Only using 2 parallel workers- Several large sequential scans that could benefit from more parallelism3. **Memory Pressure**- Multiple operations spilling to disk despite high work_mem- Large hash joins and sorts requiring temporary files## Recommended Parameter Adjustments### Critical Changes1. `max_parallel_workers_per_gather`: 4 (currently 2)- Justification: Query shows heavy parallel operations with large sequential scans- This change alone could significantly improve the performance of the parallel operations2. `work_mem`: 2GB (currently 1.5GB)- Justification: Multiple sorts spilling to disk- With 32GB RAM and considering the parallel workers, we can safely increase this- Note: Effective memory per sort will be work_mem × number of parallel workers3. `max_parallel_workers`: 8 (currently 4)- Justification: System has enough RAM to support more parallel workers- Will allow better utilization of parallel operations### Secondary Adjustments4. `maintenance_work_mem`: 4GB (currently 2GB)- Justification: Large sorts occurring in maintenance operations- System has enough RAM to support this increase5. `effective_io_concurrency`: 300 (currently 200)- Justification: Heavy I/O operations occurring- If using SSDs, this can be increased further6. `random_page_cost`: 1.0 (currently 1.1)- Justification: If using SSDs, this should be lowered to better reflect actual I/O costs## Monitoring RecommendationsAfter implementing these changes:1. Monitor temp file usage (`pg_stat_database`)2. Watch for memory pressure using `pg_stat_activity`3. Track parallel execution effectiveness with `pg_stat_statements`
并非所有建议都完全合理,但关键建议看起来不错。于是他听从了AI的建议,重新运行了查询。然后数据库崩溃了。
Sir Sonnet回答:
(想象一下,这里还有几次迭代,以及对Sir Sonnet过于自信的胡言乱语的一些抱怨。)
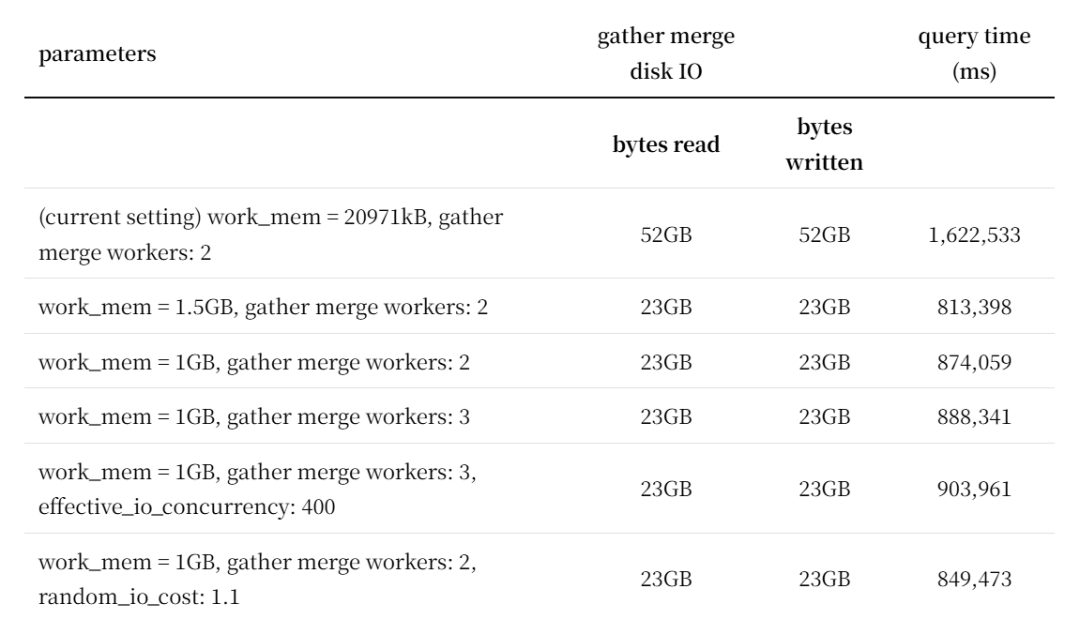
最终,查询速度显著提升。他尝试调整了许多PostgreSQL参数,并整理了一个矩阵:
他和Srihari交流了经验,像Srihari这样经验丰富的人可能一个下午就能搞定。
Sir Sonnet帮忙的地方在于,作为一个从未调整过PostgreSQL参数的人,他能像Srihari一样高效产出。而且,与 Sir Sonnet的对抗式互动让他以前所未有的速度学习了PostgreSQL的内部机制。
如今,大模型比过去聪明得多。它们能更智能地推理,工具使用也更出色。
人们编写软件的方式正发生着巨变,因此有必要重新审视一些曾被奉为金科玉律的传统智慧。
别急着搞复杂抽象:首先,花费过多时间去寻找和构建精巧的抽象,其价值正在降低。
DRY(不要重复自己)原则对确保代码模式的一致性固然有用,但为了应对需求变更而维护,本身就需要付出成本。
返工的成本极低。小范围的代码编写不如整体代码结构和组织重要。可以快速构建多个原型测试想法。
氛围编程很适合原型开发,但事后要将原型抛弃并重新进行规范的开发。
验证并修正一个既有方案,通常比从零开始创造它要容易得多。这极大地降低了人们尝试新事物的阻力。
测试是绝对不容妥协的。AI能够快速、批量地生成测试用例,这让任何不写测试的借口都荡然无存。
但请记住,必须时刻严格审查其生成的内容!
(文:新智元)