


本文的主要作者来自北京航空航天大学、北京大学和北京智源人工智能研究院。本文的第一作者为北京航空航天大学硕士生周恩申,主要研究方向为具身智能和多模态大模型。本文的共一作者兼项目负责人为北京智源研究院研究员迟程。本文的通讯作者为北京航空航天大学副教授盛律和北京大学计算机学院研究员、助理教授仉尚航。
机器人走出实验室、进入真实世界真正可用,远比想象中更复杂。现实环境常常杂乱无序、物体种类繁多、灵活多变,远不像实验室那样干净、单一、可控。
想象一下,你正在餐厅吃饭,身边有个服务机器人。你对它说:「把第二列最远的黄色寿司盘,放到离我最近的寿司和酱油碟之间的空位上。」(左图)又或者,你希望它「拿起最左边、饮料 logo 正对的苹果,放到最近的桌子上,并与之前的苹果排成一排、间距一致。」(右图)

听着简单,做起来却不容易。哪怕是目前最强大、最先进的多模态大模型,也依然难以准确理解复杂的三维场景,并根据指令动态推理出正确的交互位置。这是因为空间指代任务,背后其实包含了两个维度的挑战:
-
单步空间理解:机器人得先看懂世界。这要求模型能够准确识别物体的空间属性(比如位置、朝向)以及它们之间的空间关系(比如远近、方向)。这是空间指代任务的基础,大部分研究目前还停留在这一层。
-
多步空间推理:真正的挑战来了:面对一连串复杂的空间关系约束,机器人不仅要理解,还要逐步推理、动态判断,灵活应对各种开放世界中各种各样的空间关系组合。这种能力对于实现真正的空间指代至关重要,但目前仍然是一个被严重低估和不足探索的方向。
为了破解空间指代的难题,北京航空航天大学、北京大学与北京智源人工智能研究院联合提出了一个具备三维空间理解推理能力的多模态大模型 —— RoboRefer。这个模型不仅通过全参数微调(SFT),实现了对空间信息的精准理解,还通过强化学习微调(RFT),大幅提升了推理与泛化能力,最终实现开放世界的空间指代。

-
论文链接:https://arxiv.org/pdf/2506.04308
-
论文标题:RoboRefer: Towards Spatial Referring with Reasoning in Vision-Language Models for Robotics
-
项目主页:https://zhoues.github.io/RoboRefer
-
代码仓库:https://github.com/Zhoues/RoboRefer
-
数据链接:https://huggingface.co/datasets/JingkunAn/RefSpatial
-
评测链接:https://huggingface.co/datasets/BAAI/RefSpatial-Bench
SFT 训练下的 RoboRefer 在空间理解任务中达到了 89.6% 的平均成功率,刷新了当前最先进水平。而在研究者提出的高难度空间指代任务评测基准 RefSpatial-Bench 上,RFT 训练后的 RoboRefer 更是领先所有其他模型,比 Gemini-2.5-Pro 高出 17.4% 的平均准确率,优势显著。
RoboRefer 是什么
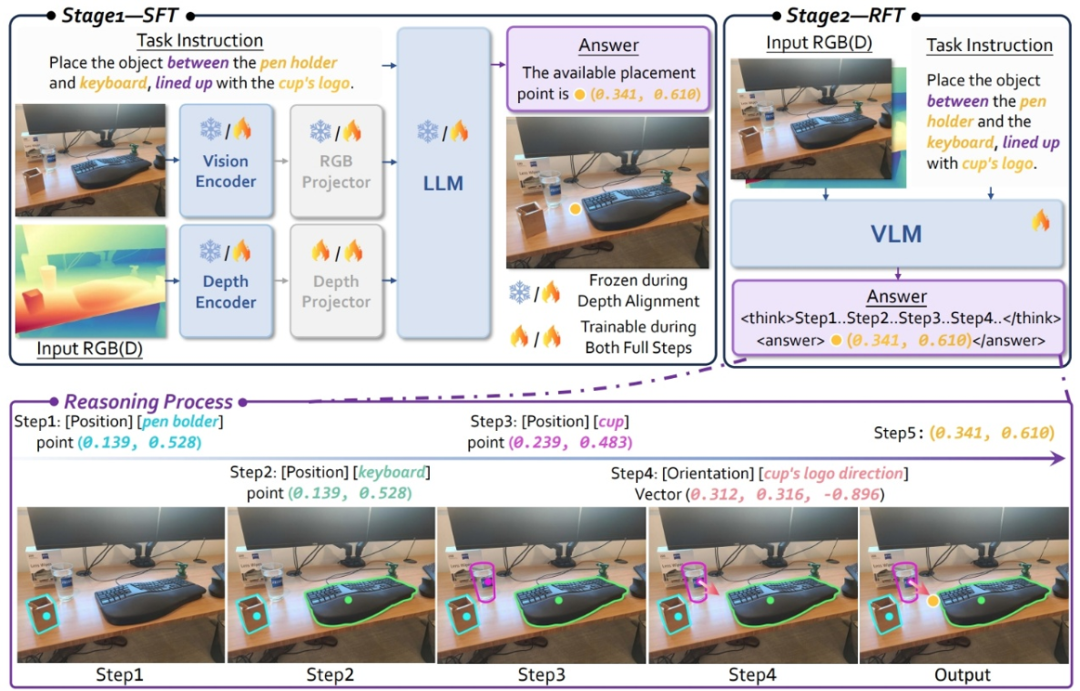
RoboRefer 是一个具备三维空间理解与推理能力的多模态大模型,拥有独立的图像编码器和深度图编码器,其不仅能回答各种空间感知类问答,无论是「这个物体离我有多远?」这样的定量问题,还是「哪个物体在左边?」这样的定性问题;更厉害的是,它还能基于多种空间关系(比如物体的位置和朝向),进行复杂的组合式推理,最终准确定位需要交互的位置。
比如,面对一个指令:「把这个物体放在笔筒和键盘的中间,水瓶的 logo 要正对着你。」RoboRefer 不仅能理解这句自然语言的空间逻辑,还能在真实三维场景中,找到唯一正确的位置来完成任务。
RoboRefer 的核心是什么
为什么相较于以往的方法,RoboRefer 不仅可以精确的感知空间,而且又可以根据多个空间关系组合泛化推理出交互的位置呢?其关键因素在于以下几点:
SFT 增强空间感知能力,RFT 搭配过程奖励提升泛化推理能力
当前多模态大模型在 2D 预训练阶段缺乏对空间关系的深入理解,为了提升模型的单步空间理解能力,研究人员引入了一个独立的深度编码器,使模型能够更有效地感知和利用三维信息,并通过全参数微调(SFT)进行训练。
尽管 SFT 使用了各种空间感知和推理数据,但模型更倾向于记忆答案,而不是泛化到新的空间约束条件。为了解决这一问题,研究者进一步引入了基于 GRPO 的强化学习微调。
值得一提的是,团队不仅关注结果导向的奖励(outcome-based reward),还创新性地设计了基于过程的奖励函数(process reward functions),这些函数能够感知中间推理过程的质量,从而提升模型多步空间指代任务中的推理精度。最终,模型增强了显式多步推理能力,实现了开放世界的空间指代任务。
提出 RefSpatial 数据集,教一个多模态大模型从 0 到 1 学会空间指代
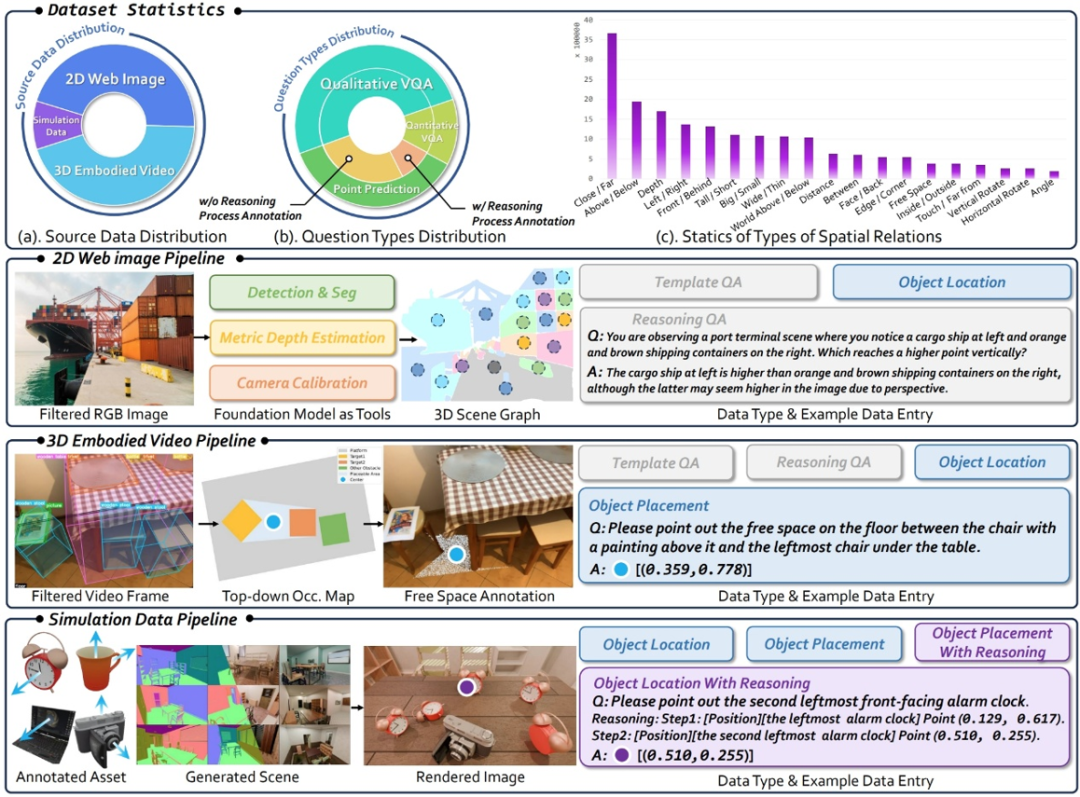
为了支持前述的 SFT 和 RFT 训练,研究团队构建了一个大规模、高质量的数据集 ——RefSpatial,具有以下几个核心特点:
-
精细标注:每个物体都配有层级式描述,从「杯子」这类种类类别,到像「左数第三个杯子」「最靠近摄像头的杯子」这样的精确空间指代,确保在复杂场景中也能清晰用文字表述。
-
多维推理:数据集不仅标注了目标,还附带详细的多步推理过程(最高有 5 步),为复杂空间指代提供支持。
-
高质量筛选:数据经过严格筛选,确保标注准确、语义清晰。
-
规模庞大:共包含 250 万个样本、2000 万个问答对,数据量是同类数据集的两倍。
-
场景丰富:覆盖室内外环境,涵盖多种日常交互情境,并整合了 31 种空间关系(对比以往最多 15 种)。
-
易于扩展:支持从多种来源生成空间指代数据,包括 2D 图像、3D 视频(含边界框)和模拟资产,具备高度扩展性。
RoboRefer 到底有多厉害
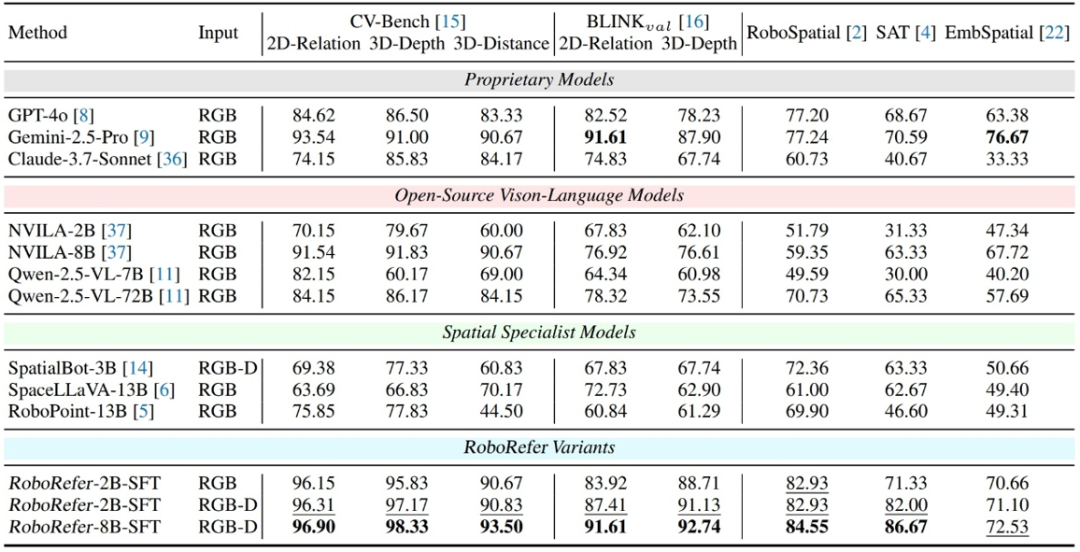
单步空间理解评测
SFT 训练后的 RoboRefer 在各种空间理解任务中达到了 89.6% 的平均成功率,取得了当前最先进水平。
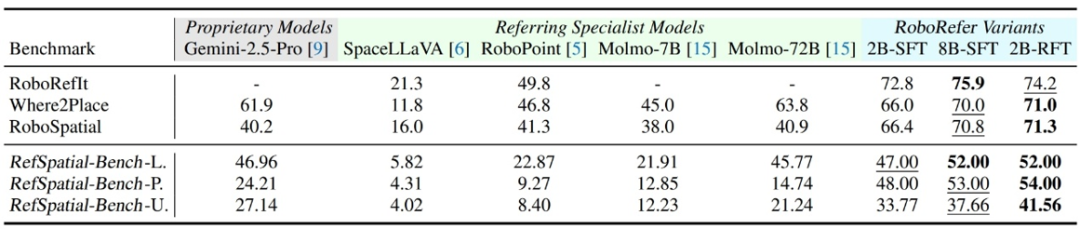
多步空间指代评测
RFT 训练后的 RoboRefer 在已有的机器人指代榜单上依旧超越现有方法,在研究者们提出的高难度空间指代任务评测基准 RefSpatial-Bench 上,其更是领先所有其他模型,比 Gemini-2.5-Pro 高出 17.4% 的平均准确率。
下面展示一些 RoboRefer 与其它模型输出结果的可视化样例:
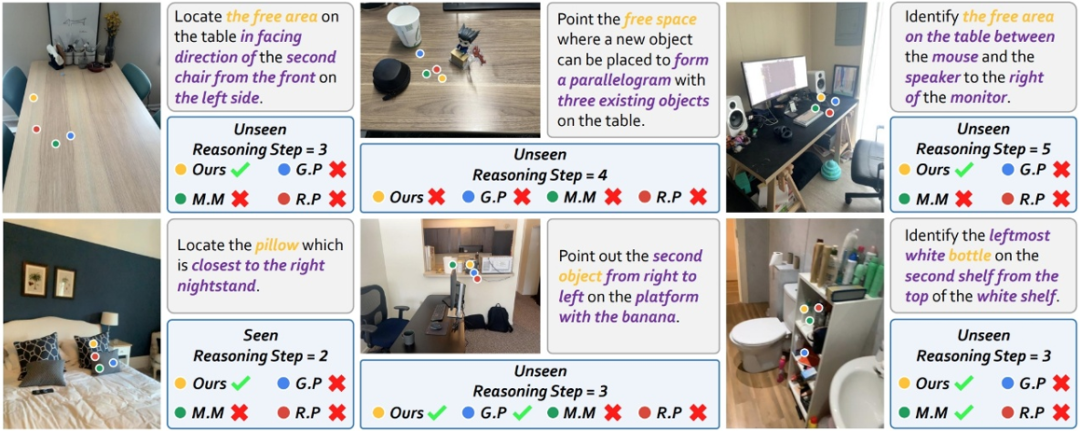
仿真与真机实验
在空间操控的机械臂仿真评测中,RoboRefer 的表现远超现有的视觉 – 语言 – 动作(VLA)系统。不仅在模拟环境中成功率遥遥领先,面对开放世界中的多步推理与复杂指代任务,唯有 RoboRefer 能够完成!
更多的实验结果,可视化展示(包括更多的杂乱场景下的真机 Demo 视频的空间指代结果)详见论文和主页!

©
(文:机器之心)