


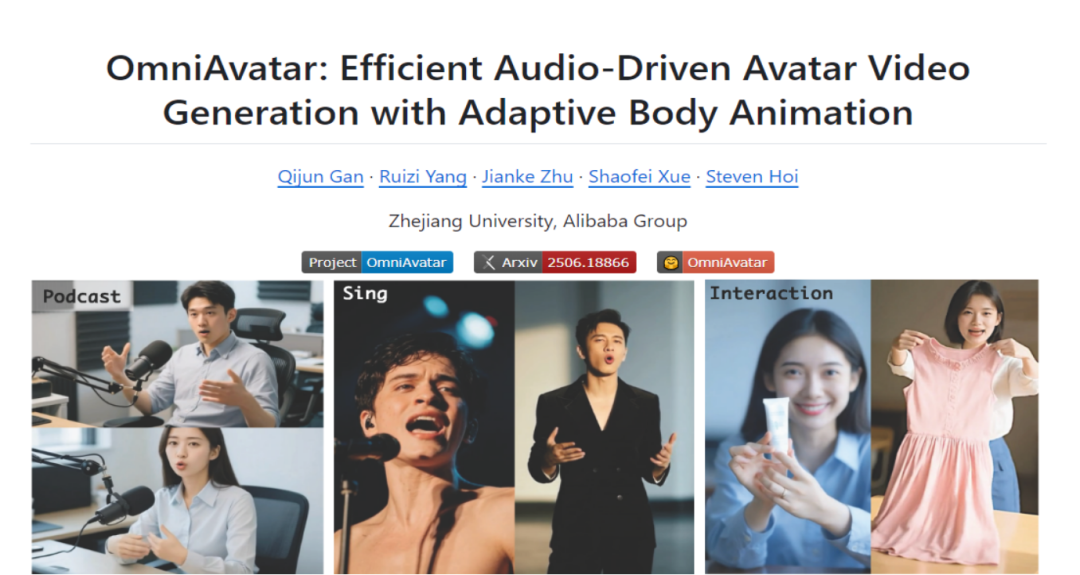
在人工智能技术飞速发展的今天,虚拟形象的生成与应用成为了研究热点之一。浙江大学联合阿里巴巴集团推出的OmniAvatar 模型,为音频驱动全身视频生成领域带来了新的突破,有望在众多领域发挥重要作用,本文将深入探讨这一前沿技术成果。
一、模型概述
OmniAvatar 是浙江大学和阿里巴巴集团共同推出的音频驱动全身视频生成模型。它能够根据输入的音频和文本提示,生成自然、逼真的全身动画视频,人物动作与音频完美同步,表情丰富。该模型基于像素级多级音频嵌入策略和 LoRA 训练方法,有效提升唇部同步精度和全身动作的自然度,并支持人物与物体交互、背景控制和情绪控制等功能,可广泛应用于播客、互动视频、虚拟场景等多种领域。
二、技术原理
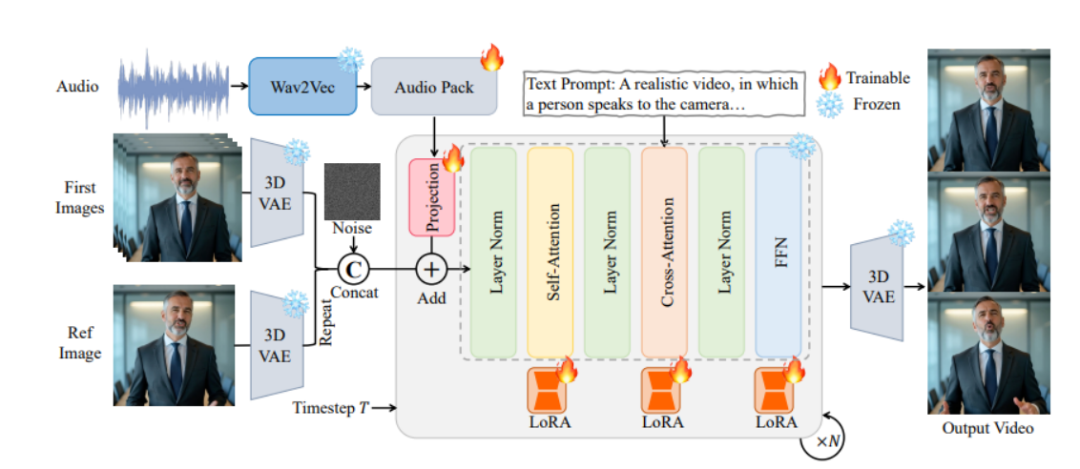
(一)像素级多级音频嵌入策略
OmniAvatar 将音频特征映射到模型的潜在空间,并在像素级别上进行嵌入。这种策略让音频特征能够更自然地影响全身动作的生成,从而提高唇部同步的精度和全身动作的自然度。通过多级嵌入,模型能够在不同层次上捕捉音频特征,更好地适应各种复杂场景和动作变化。
(二)LoRA 训练方法
基于低秩适应(LoRA)技术对预训练模型进行微调。通过在模型的权重矩阵中引入低秩分解,减少了训练参数的数量,同时保留了模型的原始能力。这不仅提高了训练效率,还提升了生成视频的质量,使模型能够更有效地学习音频与视频之间的关联。
(三)长视频生成策略
为生成长视频,OmniAvatar 采用了参考图像嵌入和帧重叠策略。参考图像嵌入确保视频中人物身份的一致性,而帧重叠则保证视频在时间上的连贯性,避免动作的突变。这两种策略相结合,使得生成的长视频在视觉上更加流畅自然。
(四)基于扩散模型的视频生成
OmniAvatar 以扩散模型(Diffusion Models)作为基础架构,通过逐步去除噪声来生成视频。这种模型能够生成高质量的视频内容,并且在处理长序列数据时表现出色,为生成复杂且连贯的全身视频提供了有力支持。
(五)Transformer 架构
在扩散模型的基础上,引入Transformer 架构能够更好地捕捉视频中的长期依赖关系和语义一致性。这进一步提升了生成视频的质量和连贯性,使人物的动作和表情更加符合语言描述和音频节奏。
三、主要功能
(一)自然唇部同步
OmniAvatar 能够生成与音频完美同步的唇部动作,即使在复杂场景下也能保持高度准确性。这一功能对于生成自然逼真的虚拟形象至关重要,无论是播客、视频博主还是虚拟教师等应用场景,都能让观众感受到仿佛真人说话般的自然效果。
(二)全身动画生成
该模型支持生成自然流畅的全身动作,使动画更加生动逼真。全身动作的自然度对于提升虚拟形象的真实感和吸引力起到了关键作用,让观众不再局限于人物的面部表情,而是能够欣赏到完整的人物动态。
(三)文本控制
基于文本提示,用户可以精确控制视频内容,包括人物动作、背景、情绪等,实现高度定制化的视频生成。这种文本控制能力极大地增强了模型的灵活性和适用性,满足不同用户在不同场景下的个性化需求。
(四)人物与物体交互
OmniAvatar 支持生成人物与周围物体互动的场景,如拿起物品、操作设备等。这一功能拓展了音频驱动数字虚拟形象的应用范围,使其能够更好地融入各种虚拟场景,与环境进行自然的交互,为用户带来更加沉浸式的体验。
(五)背景控制
用户可以通过文本提示改变背景,使生成的视频能够适应各种不同的场景需求。背景控制功能为视频创作提供了更多的创意空间,无论是现代都市、自然风光还是科幻场景,都能轻松实现,进一步提升了视频的视觉效果和表现力。
(六)情绪控制
基于文本提示,OmniAvatar 还能够控制人物的情绪表达,如快乐、悲伤、愤怒等,从而增强视频的表现力。情绪控制让虚拟形象能够更好地传达情感,使观众更容易产生情感共鸣,提升了视频内容的感染力和吸引力。
四、应用场景
(一)虚拟内容制作
在虚拟内容制作领域,OmniAvatar 可以用于生成播客、视频博主等的虚拟形象,降低制作成本的同时,丰富内容的表现形式。通过简单的音频输入和文本描述,就能创造出具有独特风格和个性的虚拟形象,为观众带来全新的视觉体验。
(二)互动社交平台
对于互动社交平台而言,OmniAvatar 能够为用户提供个性化的虚拟形象,实现自然的动作和表情互动。用户可以根据自己的喜好定制虚拟形象,并在社交互动中展现出更加真实自然的动态效果,增强社交体验的趣味性和沉浸感。
(三)教育培训领域
在教育培训领域,OmniAvatar 可以生成虚拟教师形象,基于音频输入讲解教学内容,提高教学的趣味性和吸引力。虚拟教师能够根据教学内容和场景进行自然的动作和表情展示,使学生更容易集中注意力,提高学习效果。
(四)广告营销领域
在广告营销领域,OmniAvatar 可以生成虚拟代言人形象,根据品牌需求定制形象和动作,实现精准的广告宣传。虚拟代言人能够以更加生动形象的方式展示产品特点和优势,吸引消费者的关注,提升品牌知名度和产品销量。
(五)游戏与虚拟现实
在游戏与虚拟现实领域,OmniAvatar 能够快速生成具有自然动作和表情的虚拟游戏角色,丰富游戏内容,提升虚拟现实体验的逼真度。通过音频驱动的角色动作和表情生成,玩家能够获得更加真实的游戏体验,增强游戏的沉浸感和趣味性。
五、快速使用
(一)安装环境
1. 克隆项目仓库
git clone https://github.com/Omni-Avatar/OmniAvatar.gitcd OmniAvatar
2. 安装依赖
pip install torch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 --index-url https://download.pytorch.org/whl/cu124pip install -r requirements.txt# Optional to install flash_attn to accelerate attention computationpip install flash_attn
(二)下载模型
使用huggingface-cli 下载所需的模型文件:
mkdir pretrained_modelspip install "huggingface_hub[cli]"huggingface-cli download Wan-AI/Wan2.1-T2V-14B --local-dir ./pretrained_models/Wan2.1-T2V-14Bhuggingface-cli download facebook/wav2vec2-base-960h --local-dir ./pretrained_models/wav2vec2-base-960hhuggingface-cli download OmniAvatar/OmniAvatar-14B --local-dir ./pretrained_models/OmniAvatar-14B
(三)推理实践
1. 准备输入文件
在`examples/infer_samples.txt` 中按照 `[prompt]@@[img_path]@@[audio_path]` 的格式编写提示文本、参考图像路径和音频路径。例如:
A person speaking to the camera@@./examples/ref_image.jpg@@./examples/audio.wav2. 运行推理脚本
torchrun --standalone --nproc_per_node=1 scripts/inference.py --config configs/inference.yaml --input_file examples/infer_samples.txt根据需要,可以通过修改配置文件或命令行参数来调整推理过程中的参数,如`guidance_scale`、`audio_scale`、`num_steps` 等,以获得更好的生成效果。
六、结语
OmniAvatar 作为浙江大学联合阿里巴巴集团推出的一项创新成果,在音频驱动全身视频生成领域展现出了强大的性能和广泛的应用潜力。其先进的技术原理、丰富的功能特性以及便捷的使用方式,使其在虚拟内容制作、互动社交平台、教育培训、广告营销以及游戏与虚拟现实等多个领域都具有重要的应用价值。
七、项目地址
项目官网:https://omni-avatar.github.io/
GitHub 仓库:https://github.com/Omni-Avatar/OmniAvatar
HuggingFace 模型库:https://huggingface.co/OmniAvatar/OmniAvatar-14B
arXiv 技术论文:https://arxiv.org/pdf/2506.18866
(文:小兵的AI视界)