


刘勇,中国人民大学,长聘副教授,博士生导师,国家级高层次青年人才。长期从事机器学习基础理论研究,共发表论文 100 余篇,其中以第一作者/通讯作者发表顶级期刊和会议论文近 50 篇,涵盖机器学习领域顶级期刊 JMLR、IEEE TPAMI、Artificial Intelligence 和顶级会议 ICML、NeurIPS 等。
你肯定见过大模型在解题时「装模作样」地输出:「Hmm…」、「Wait, let me think」、「Therefore…」这些看似「人类化」的思考词。
但一个灵魂拷问始终存在:这些词真的代表模型在「思考」,还是仅仅为了「表演」更像人类而添加的语言装饰?是模型的「顿悟时刻」,还是纯粹的「烟雾弹」?
现在,实锤来了!来自中国人民大学高瓴人工智能学院、上海人工智能实验室、伦敦大学学院(UCL)和大连理工大学的联合研究团队,在最新论文中首次利用信息论这把「手术刀」,精准解剖了大模型内部的推理动态,给出了令人信服的答案:
当这些「思考词」出现的瞬间,模型大脑(隐空间)中关于正确答案的信息量,会突然飙升数倍!
这绝非偶然装饰,而是真正的「信息高峰」与「决策拐点」!更酷的是,基于这一发现,研究者提出了无需额外训练就能显著提升模型推理性能的简单方法,代码已开源!

-
论文题目:Demystifying Reasoning Dynamics with Mutual Information: Thinking Tokens are Information Peaks in LLM Reasoning
-
论文链接:
https://arxiv.org/abs/2506.02867 -
代码链接:
https://github.com/ChnQ/MI-Peaks
核心发现一:揭秘大模型推理轨迹中的「信息高峰」现象
研究者们追踪了像 DeepSeek-R1 系列蒸馏模型、QwQ 这类擅长推理的大模型在解题时的「脑电波」(隐空间表征)。他们测量每一步的「脑电波」与最终正确答案的互信息(Mutual Information, MI),并观察这些互信息如何演绎变化。
惊人现象出现了:模型推理并非匀速「爬坡」,而是存在剧烈的「信息脉冲」!在特定步骤,互信息值会突然、显著地飙升,形成显著的「互信息峰值」(MI Peaks)现象。这些峰值点稀疏但关键,如同黑暗推理路径上突然点亮的强光路标!
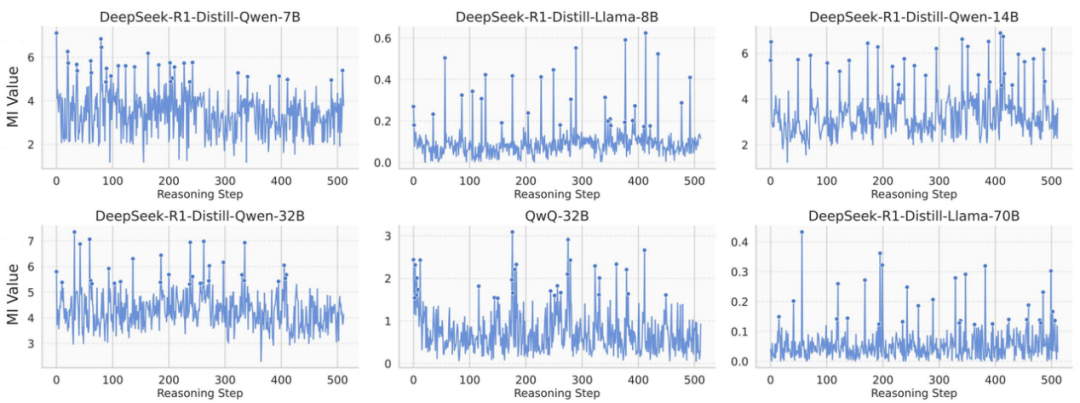
这意味着什么?直觉上,这些互信息峰值点处的表征,模型大脑中那一刻的状态,蕴含了更多指向正确答案的最关键信息!
进一步地,研究者通过理论分析证明(定理 1 & 2),推理过程中积累的互信息越高,模型最终回答错误概率的上界和下界就越紧,换言之,回答正确的概率就越高!
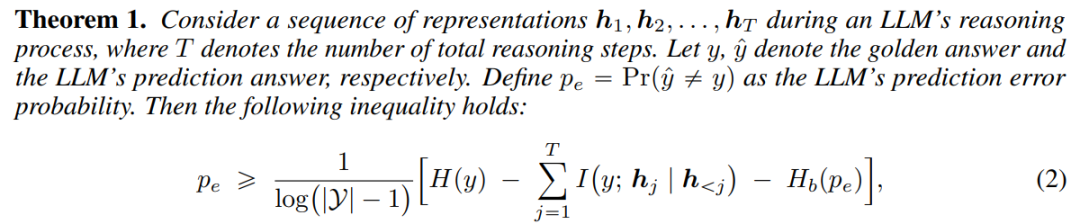
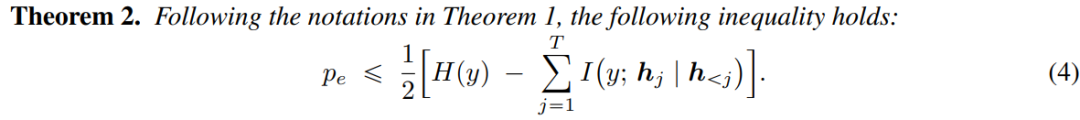
既然互信息峰值的现象较为普遍地出现在推理模型(LRMs)中,那么非推理模型(non-reasoning LLMs)上也会表现出类似的现象吗?
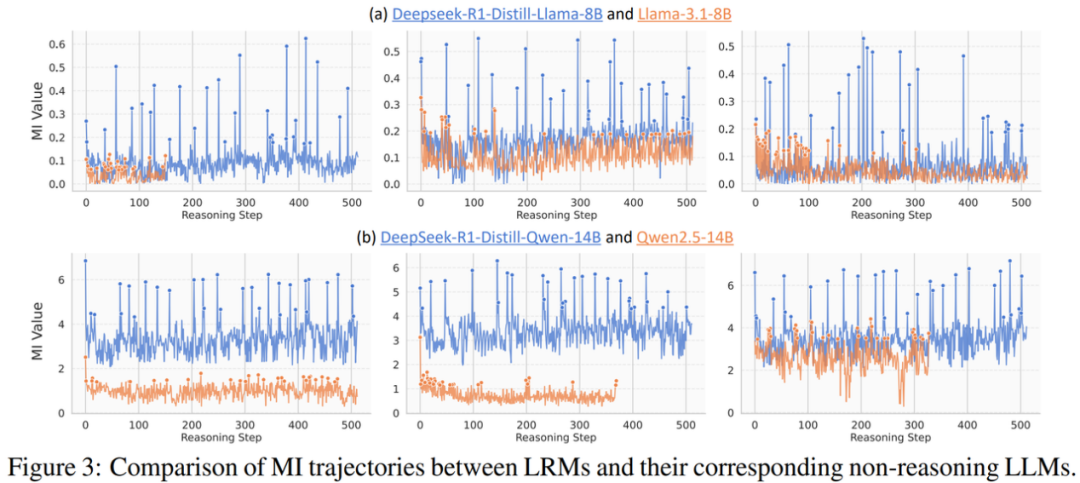
为了探索这一问题,研究者选取了 DeepSeek-R1-Distill 系列模型和其对应的非推理模型进行实验。如上图橙色线所示,在非推理模型的推理过程中,互信息往往表现出更小的波动,体现出明显更弱的互信息峰值现象,且互信息的数值整体上更小。
这表明在经过推理能力强化训练后,推理模型一方面似乎整体在表征中编码了更多关于正确答案的信息,另一方面催生了互信息峰值现象的出现!
核心发现二:「思考词汇」=「信息高峰」的语言化身
那么,这些互信息峰值点处的表征,到底蕴含着怎样的语义信息?
神奇的是,当研究者把这些「信息高峰」时刻的「脑电波」翻译回人能看懂的语言(解码到词汇空间)时,发现它们最常对应的,恰恰是那些标志性的「思考词」:
-
反思/停顿型:「Hmm」、「Wait」…
-
逻辑/过渡型:「Therefore」、「So」…
-
行动型:「Let」、「First」…
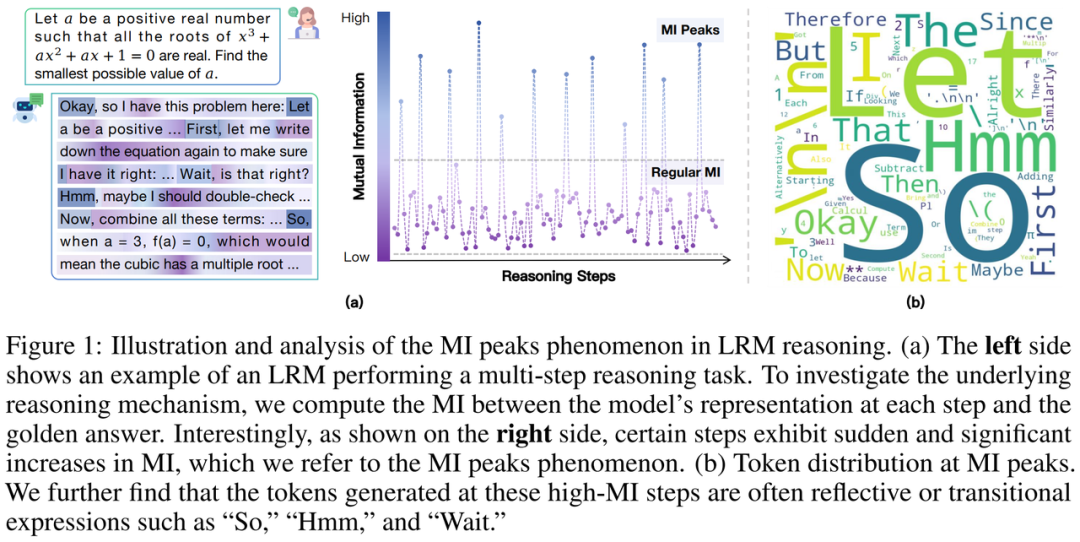
例如,研究者随机摘取了一些模型输出: 「Wait, let me think differently. Let’s denote…,」 「Hmm, so I must have made a mistake somewhere. Let me double-check my calculations. First, …」
研究团队将这些在互信息峰值点频繁出现、承载关键信息并在语言上推动模型思考的词汇命名为「思考词汇」(thinking tokens)。它们不是可有可无的装饰,而是信息高峰在语言层面的「显灵」,可能在模型推理路径上扮演着关键路标或决策点的角色!
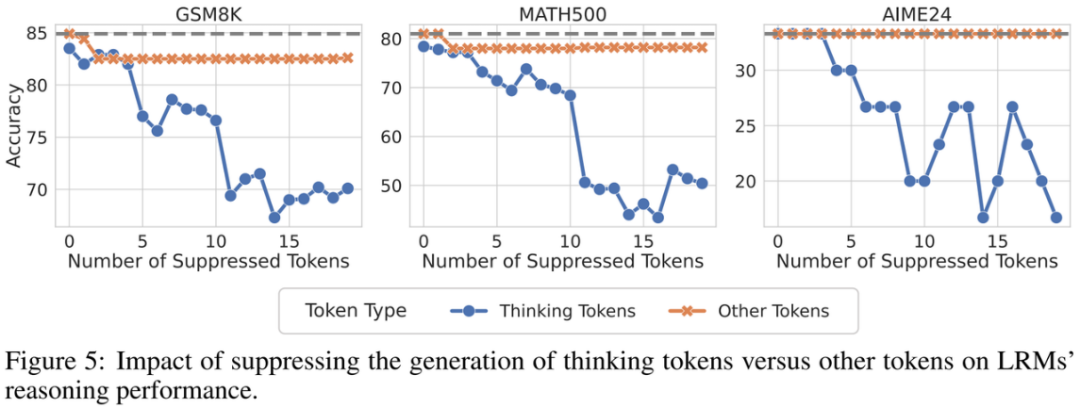
为了证明这些 tokens 的关键性,研究者进行了干预实验,即在模型推理时抑制这些思考词汇的生成。
实锤验证:实验结果显示,抑制思考词汇的生成会显著影响模型在数学推理数据集(如 GSM8K、MATH、AIME24)上的性能;相比之下,随机屏蔽相同数量的其他普通词汇,对性能影响甚微。这表明这些存在于互信息峰值点处的思考词汇,确实对模型有效推理具有至关重要的作用!
启发应用:无需训练,巧用「信息高峰」提升推理性能
理解了「信息高峰」和「思考词汇」的奥秘,研究者提出了两种无需额外训练即可提升现有 LRMs 推理性能的实用方法。
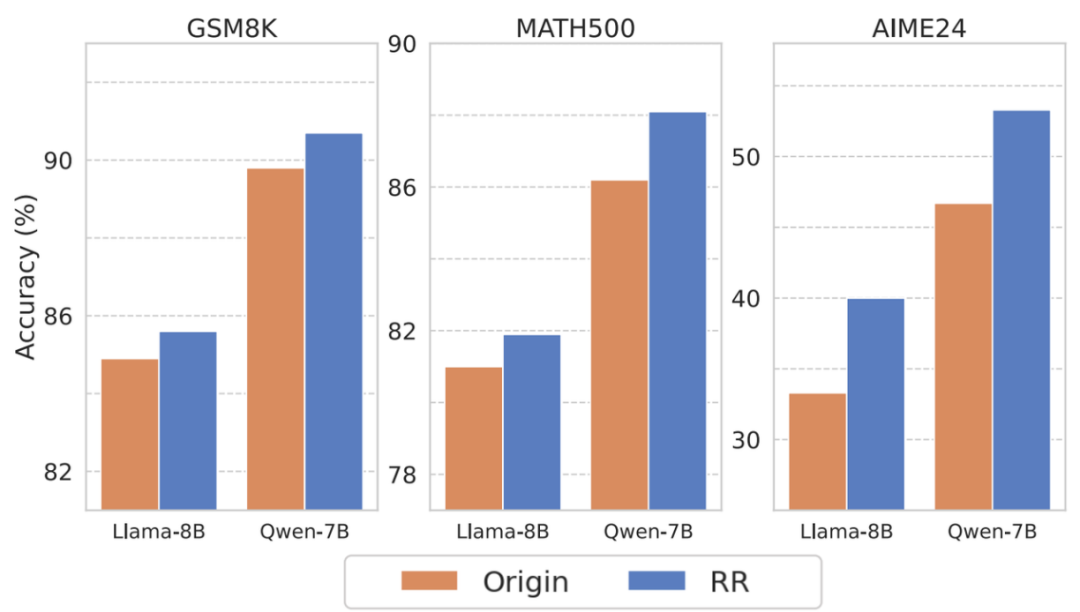
应用一:表征循环(Representation Recycling – RR)
-
启发:既然 MI 峰值点的表征蕴含丰富信息,何不让模型「多咀嚼消化」一下?
-
方法:在模型推理过程中,当检测到生成了思考词汇时,不急于让其立刻输出,而是将其对应的表征重新输入到模型中进行额外一轮计算,让模型充分挖掘利用表征中的丰富信息。
-
效果:在多个数学推理基准(GSM8K、MATH500、AIME24)上,RR 方法一致地提升了 LRMs 的推理性能。例如,在极具挑战性的 AIME24 上,DeepSeek-R1-Distill-LLaMA-8B 的准确率相对提升了 20%!这表明让模型更充分地利用这些高信息量的「顿悟」表征,能有效解锁其推理潜力。
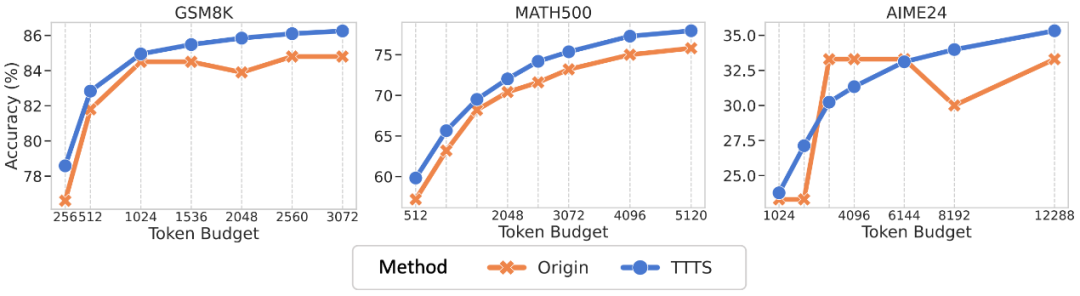
应用二:基于思考词汇的测试时扩展(Thinking Token based Test-time Scaling – TTTS)
-
启发:在推理时如果允许模型生成更多 token(增加计算预算),如何引导模型进行更有效的「深度思考」,而不是漫无目的地延伸?
-
方法:受启发于前人工作,作者在模型完成初始推理输出后,如果还有 token 预算,则强制模型以「思考词汇」开头(如「Therefore」、「So」、「Wait」、「Hmm」等)继续生成后续内容,引导模型在额外计算资源下进行更深入的推理。
-
效果:当 token 预算增加时,TTTS 能持续稳定地提升模型的推理性能。如图所示,在 GSM8K 和 MATH500 数据集上,在相同的 Token 预算下,TTTS 持续优于原始模型。在 AIME24 数据集上,尽管原始模型的性能在早期提升得较快,但当 token 预算达到 4096 后,模型性能就到达了瓶颈期;而 TTTS 引导下的模型,其性能随着 Token 预算的增加而持续提升,并在预算达到 6144 后超越了原始模型。
小结
这项研究首次揭示了 LRMs 推理过程中的动态机制:通过互信息动态追踪,首次清晰观测到 LRMs 推理过程中的互信息峰值(MI Peaks)现象,为理解模型「黑箱」推理提供了创新视角和实证基础。
进一步地,研究者发现这些互信息峰值处的 token 对应的是表达思考、反思等的「思考词汇」(Thinking Tokens),并通过干预实验验证了这些 token 对模型推理性能具有至关重要的影响。
最后,受启发于对上述现象的理解和分析,研究者提出了两种简单有效且无需训练的方法来提升 LRMs 的推理性能,即表征循环(Representation Recycling – RR)和基于思考词汇的测试时扩展(Thinking Token based Test-time Scaling – TTTS)。
研究者希望这篇工作可以为深入理解 LRMs 的推理机制提供新的视角,并进一步提出可行的方案来进一步推升模型的推理能力。
(文:机器学习算法与自然语言处理)