


当通用大模型尚未内化行业 Know-how 时,业内专业数据训练的专家模型仍不可或缺,为切实解决细分领域问题设计的垂类 Agent 才是当前正解。
还记得当年高考填志愿我抱着一本厚厚的院校报考指南翻来覆去却无从下手,无奈寻求老师帮助,而即使在老师的指导下,上了一所不错的学校,但是最终却调剂到了不感兴趣的专业,甚至在录取结果出来的那一刻产生了强烈的复读想法。
面对海量的院校和专业数据,往往手足无措,不知从何查起。每所院校都有其特色专业和学科优势及特色的报考政策,且分数线每年都在波动,普通家庭很难全面掌握这些信息…等等这些问题,始终困扰着无数中国家庭。
这也因此养活了不少‘张老师’,一次动辄几千元的咨询费,家长们花的是一点不犹豫。若能换来负责任的个性化指导也算值得,但更多时候得到的只是流水线式的公式化服务 —— 所谓 “指导” 不过是机械套用数据模板,很难真正契合考生的兴趣与规划。
既恨当年没有夸克,更恨当下许多考生仍不知晓夸克。
其实,夸克早在 2019 年左右便开始为广大中国考生提供高考志愿填报信息服务。
而在今年 高考志愿填报季,夸克又推出了“志愿报告”这一全新功能。这是夸克将 AI Agent 的「深度研究」能力应用在志愿填报垂类场景的一次重要实践,要为每位考生提供一位个性化的志愿专家来辅助填报。
据官方披露的数据,今年“志愿报告” Agent 已累计为考生和家长生成超过 1000 万份专业志愿报告,是国内最大规模的一次深度研究应用。

使用夸克“志愿填报” Agent,考生完善 12 个信息点后,5-10 分钟便能获得包含填报策略、志愿表、院校专业推荐说明等内容的专业志愿指导报告。

当然,这时候有人要问了,AI 给的填报指导难道就不是“流水线作业”了吗?参考价值大吗?靠谱吗?
在最终的录取结果出来之前,对夸克 AI 给出的填报指导结果是不好去评判的,且每个考生自己的评判标准不同。我们倒不如来看看夸克的深度研究 Agent 是怎么给出志愿指导的,是不是有理有据且带着思考量。
正好我弟今年高考,拿他福建物化生 582 分的成绩进行一波测试。作为福建考生不爱去外省,偏爱厦大等特点,我也一同告诉了夸克。
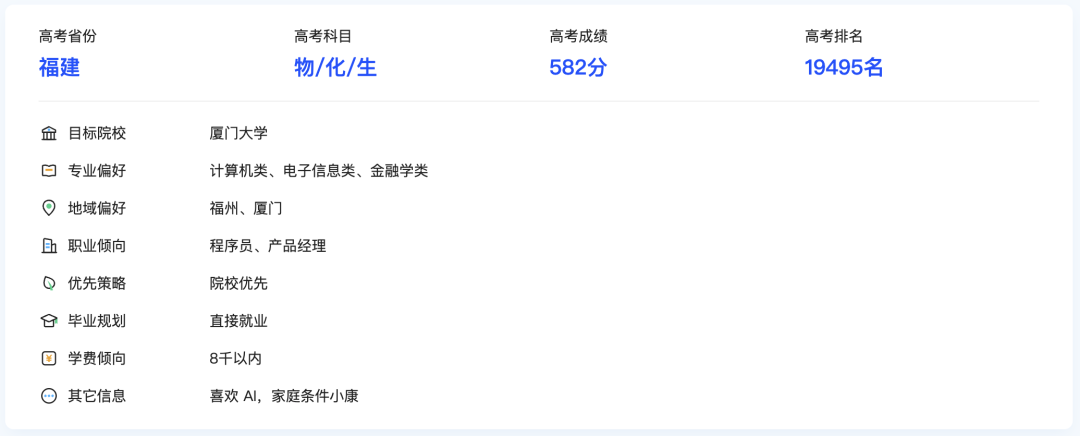
让我们来看看夸克“志愿报告” Agent 是怎么样来处理的:
一句话概括就是“规划-执行-检查-反思”,这也是我们常见的 PDCA Agent 模式设计。
1. 考生数据分析与任务规划
夸克先是基于考生的分数、目标院校、地域偏好等信息,规划出自己搜集信息与制定志愿报告的步骤。从其规划的步骤可以看出,夸克对院校专业的筛选是全面且高度定制的,不仅是基于分数,更基于考生的目标院校、意向专业、地域、就业前景甚至学费。

2. 院校信息筛选
确认完考生的需求,并完成信息检索规划后,夸克便从分数线到地域、学费等将可填报的院校、专业逐步缩小到可供用户决策的范围,最终再根据考生未来的职业规划对结果进行重排序。

在这一阶段,我们能从夸克的执行步骤中看到两个出现频率很高的词:「夸克高考志愿工具」、「夸克高考知识库」,对与前者我们可以理解为夸克高考志愿 MCP,后者则是 RAG 知识库。
夸克高考志愿 MCP 负责志愿表的操作,高考知识库则结合夸克自研的高考志愿大模型提供决策支持。
3. 结果检查与反思
如果说,前面 2 步只是用 AI 的方式替代了其他市面上的志愿填报工具,夸克 AI 对初版结果的检查与反思则是传统工具无法做到的,这是独属于大模型、Agent 的能力。举 2 个例子:
在面对考生希望在省内大学就读时,夸克会优先筛选省内主要城市的院校、专业信息。但当省内主要城市的院校、专业信息不满足考生的需求时,夸克 Agent 还会自行反思再规划,将地域要求拓展至周边省份的院校、专业以寻找更符合考生需求的结果。

考虑到考生未来的职业规划时,夸克 Agent 会使用搜索引擎多次调研适合的专业方向来交叉验证,支持自己的决策思考。

这是在传统工具上找不到的,AI 独有的、超脱于冰冷机械的温暖‘人性’,或者说‘模性’。
4. 志愿报告交付
最终夸克交付的志愿报告也不是简单的院校列表罗列,而是给出了填报策略、志愿成功率、志愿表解读甚至风险提示。不输一般的“张老师”,至少不输当初为我辅导志愿的“张老师”。
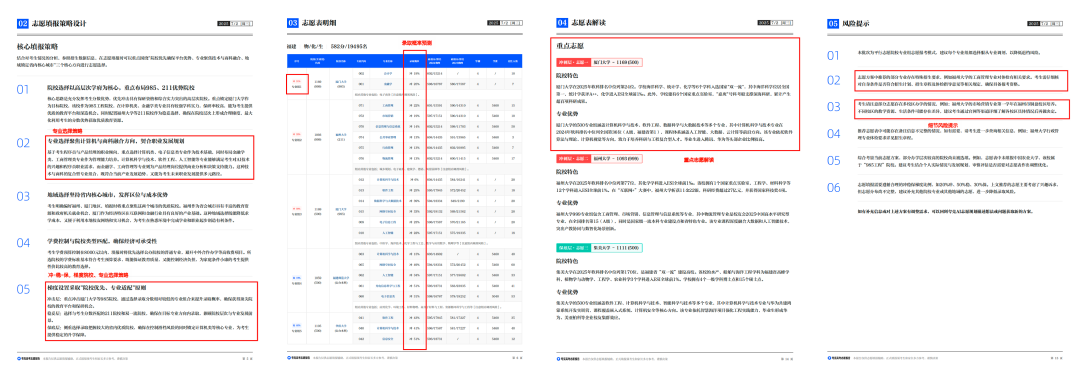

那么夸克志愿报告数据的准确性能信任吗?
大家可能觉得夸克只是在高考这一点上做了个很好的 Agent 帮考生快速地去出一份志愿填报指南,但是听完 6 月 30 日的夸克高考 AI 技术沟通会后,特工们觉得夸克团队是花了很多的功夫在构建志愿报告可信度上的。
其构建“报告可信度”的工作主要体现在两点,就是我们在上文中提到的「夸克高考数据库」以及夸克自研的「高考志愿大模型」。

夸克高考算法负责人唐亮在沟通会上表示:
专业知识库其实我们总共搜集了 8000 多站点,大概覆盖 20 多亿数据,高考相关的权威站点 99% 以上。虽然有 8000 多个站点,但是我们内部也会有些分层。
比如有些像考试院、教育部、招生办这部分肯定是政策相关最权威的。第二个是在学校官网,招生网,教育研究院等高考权威机构,也是比较权威的。另外是一些垂直站,比如阳光高考、全国教育在线,权威站点覆盖非常全。
政策库,比如说每年填报政策都会不间断的出些新的政策,我们也会人工实时更新,通过人工与组织监控方式,补足到政策库里,让整体的数据可以有详细的更新。
这部分数据一是应用到了 RAG 材料作供给,二是作为训练语料应用到「高考志愿大模型」的训练打磨之中。
而如此海量的数据如果一股脑训练进模型,模型的幻觉率是难以避免要高的。故夸克 AI 团队在数据清洗时也花了上百人的人工成本去做大量的比对、校验以及对齐工作:
-
对于核心志愿信息,夸克团队通过算法去做资料内容正确性比对,同时对不置信结果人工校验,保障 99.99%+ 的对齐准确率;
-
对于一些实时性数据,同样通过人工比对和校验的方式,做高数据准确率,并及时地更新高校招生数据,保证数据实时性;
其次便是在模型训练上,夸克团队在预训练之后,也持续地在后链路做大量对齐,以降低模型幻觉:
-
SFT:训练冷启动时会根据线下老师一对一数据,如专家和家长老师对话过程,专家面对考生时的分析思路,以及专家怎么给不同考生的个性化推荐内容等,形成训练数据集,进行监督训练,模拟专家推理思路;
-
RLVR:对于一些客观事实的数据,如招生计划、报考政策等,让大模型自行进行输出比对,自我修正;
-
RLHF:上线之后再收集线上用户的真实反馈数据,同时也会让线下的志愿填报专家进行打分,构建 RLHF 强化学习数据,优化偏好推荐策略。
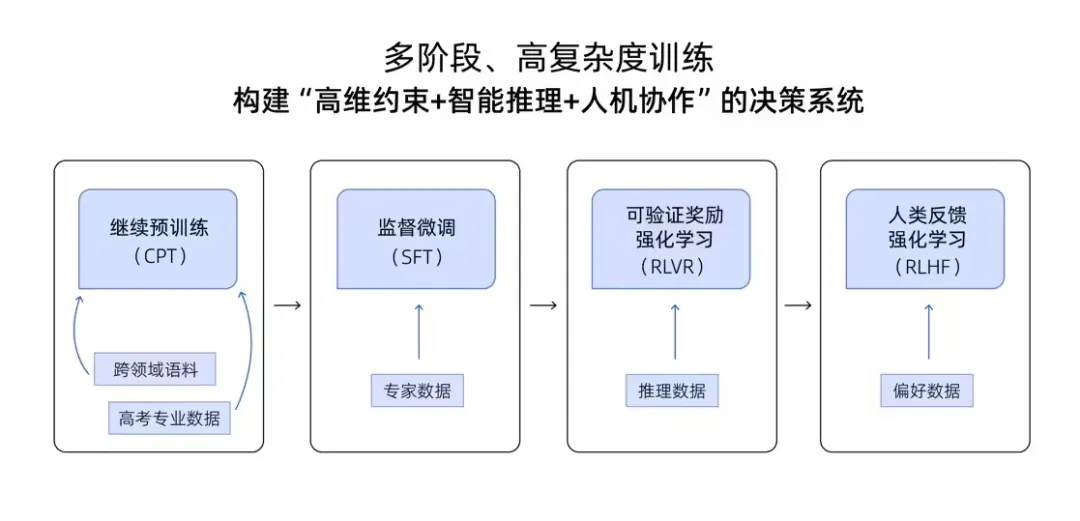
夸克高考志愿大模型训练策略
基于海量高考志愿数据的收集、分层整理,以及大量严谨的人工数据清洗,再加上多阶段、高复杂度的模型训练,目前对比通用模型,「高考志愿大模型」的幻觉率大幅降低。
一直以来有个观点:当大模型尚未内化行业 Know-how 时,细分领域专家设计的 Structure 仍是刚需,业内专业数据训练的专家模型仍不可或缺。那么人工收集整理、清洗数据便是做垂直领域专家 Agent 逃不过的、至关重要的一步。
这次夸克「深度研究」能力在高考志愿垂类场景的应用实践也证明了这一点。
不得不再次感叹,朱啸虎老师的‘脏活累活最后才是护城河’这句话说的挺对。


纵观现在市面上的各家通用 Agent 产品的「深度研究」功能,既受限于底层通用大模型的能力,又受限于信息检索的专业能力,在教育、金融等一些垂类场景与业内专家相比依然有着较大的差距。
在沟通会上,夸克算法负责人蒋冠军同样也谦虚地表示:AI 在当前这个阶段,肯定是替代不了考生的决策的。
但夸克 AI 团队或许已经走出了一条独属于自己的‘通向 AGI 之路’,以高考志愿为例——针对垂类场景 Know-How 与数据持续地进行深入的打磨,再将结果通过持续训练反哺到底层大模型之上,最终炼成集各大成为一体的超级 AI 助手。
不止高考志愿这一场景,蒋冠军在沟通会上透露了夸克 AI 团队在医疗、教育等垂直场景的「深度研究」应用也有着较深的积累,打造其他垂直场景用的方法和本次的高考志愿 Agent 类似——以专业数据为基石,以切实场景需求为标准。
用户需要的其实不是在 benchmark 各种飙高分,而是像夸克志愿填报 Agent 这样脚踏实地地、能切实解决用户问题的 AI 助手。
期待夸克 AI 团队带来更多「深度研究」垂类应用。




(文:特工宇宙)