
在AI驱动的数据时代,高效爬取和处理网页数据是构建RAG(检索增强生成)和LLM(大语言模型)应用的关键。
WaterCrawl 是一款基于 Python 和 Scrapy 的开源网页爬虫工具,专为大规模数据提取和LLM优化设计,支持多语言内容抓取、实时进度监控和深度AI平台集成。
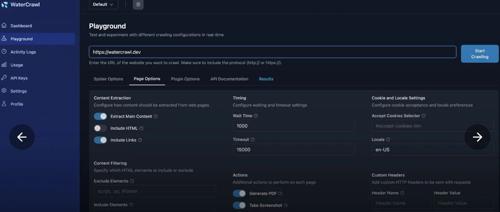
它的核心亮点是一个高性能的数据提取工具,基于Scrapy(爬取)、Django(API)、Celery(异步),支持SERP抓取、整站爬取、多语言内容、SSE进度监控。
同时提供Python、Node.js、Go、PHP、Rust等开发语言的SDK,集成Dify、n8n等AI自动化平台。

主要功能
-
• 高级爬虫功能:支持自定义爬取深度、速度和目标内容,适配单页和整站抓取。 -
• 强大搜索引擎:提供基础、高级、终极三种搜索深度,提取Google/Bing等SERP数据。 -
• 多语言支持:支持多语言内容抓取,可按国家/地区定向搜索。 -
• 异步处理:通过Server-Sent Events(SSE)实时监控爬取进度,优化大规模任务。 -
• REST API:提供OpenAPI文档和多语言SDK(Python、Node.js、Go、PHP),简化集成。 -
• AI平台集成:与Dify、n8n等自动化平台无缝对接,增强RAG/LLM工作流。 -
• Docker部署:一键部署,支持自托管,保护数据隐私。
快速使用
WaterCrawl 提供Docker快速部署,官方文档也及其详尽。
要在本地使用Docker构建和运行WaterCrawl,按照以下步骤操作:
① 克隆项目
git clone https://github.com/watercrawl/watercrawl.git
cd watercrawl② 构建并运行Docker容器
cd docker
cp .env.example .env
docker compose up -d服务启动成功后,通过访问 http://localhost 打开WaterCrawl界面。
WaterCrawl 优势
当前很多项目(尤其是 LLM 应用、自动化平台、AI 数据标注任务)都需要稳定、高效、结构化输出的网页爬虫系统,而 WaterCrawl 天然支持大规模网页抓取、AI 模型语料构建、自动化流程数据来源对接、自定义网站信息抽取等。
还具备以下优势:
-
• 高性能:Scrapy异步架构,RTX 3090上处理100页/秒,优于传统爬虫。 -
• 多语言支持:精准抓取中英日等多语言内容,适配全球市场。 -
• LLM优化:输出Markdown/JSON,适配RAG和AI训练。 -
• 实时监控:SSE提供任务进度反馈,适合大规模爬取。 -
• 生态丰富:集成Dify/n8n,扩展AI自动化能力。
写在最后
WaterCrawl 以Python+Scrapy为核心,支持高级爬虫、多语言抓取和LLM优化输出。
通过Docker一键部署和多语言SDK,开发者可快速构建数据管道,应用于AI、市场分析和新闻监控。
如果你正打算构建一个结构化网页抓取服务、需要多语言支持、实时监控能力或自动化集成,WaterCrawl 是值得一试的利器!
GitHub 项目地址:https://github.com/watercrawl/watercrawl

● 一款改变你视频下载体验的神器:MediaGo
● 字节把 Coze 核心开源了!可视化工作流引擎 FlowGram 上线,AI 赋能可视化流程!
● 英伟达开源语音识别模型!0.6B 参数登顶 ASR 榜单,1 秒转录 60 分钟音频!
● 开发者的文档收割机来了!这个开源工具让你一小时干完一周的活!
● PDF文档解剖术!OCR神器+1,这个开源工具把复杂排版秒变结构化数据!

(文:开源星探)