


极市导读
文章以YOLOv11模型为例,详细介绍了在Windows 10环境下进行高性能推理加速的实战步骤,从环境搭建、模型转换到推理执行,为开发者提供了清晰的指导,助力实现低延迟、高吞吐量的模型部署。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
ensorrtx 是由开发者 wang-xinyu 维护的一个针对 NVIDIA TensorRT 的示例项目集合。它提供了多种常用深度学习模型(主要涵盖 目标检测、图像分割、分类 等)的 TensorRT 推理实现示例。这些示例可以帮助开发者把在 PyTorch、TensorFlow 等深度学习框架下训练好的模型,快速转换并部署到 TensorRT 中,从而获得 低延迟、高吞吐量 的推理性能。
核心价值
简洁、直观的示例工程:
每个模型都对应一个独立的文件夹和项目配置,涵盖 模型转换(通常是 .pth / .onnx → TensorRT engine)、推理代码、后处理 等完整流程。
高效部署参考:
tensorrtx 提供了最佳实践示例,许多优化技巧(如 INT8/FP16、Plugins、Cuda Stream 等)在示例中都有体现,能帮助你在实际项目中快速验证和应用。
可持续更新:
该项目随 TensorRT 和 各大主流网络版本 的迭代而不断更新,紧跟前沿模型(如 YOLOv11)的部署需求。
适配多种平台:
tensorrtx 一般在 Linux + NVIDIA GPU 环境下使用。也有部分开发者把它迁移到 Windows 或 Jetson 设备上,通过 CMake 配置可灵活切换。
windows10下yolov11 tensorrtx推理加速
一. yolov11 python环境安装
1.基础环境
CUDA:cuda_11.8.0_522.06_windows
cudnn:cudnn-windows-x86_64-8.6.0.163_cuda11-archive
##创建python环境
conda create --name yolov11 python=3.10 -y
##安装pytorch
pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu118
##安装yolov11
pip install ultralytics -i https://pypi.mirrors.ustc.edu.cn/simple/
##安装必要的库
pip install -r requirements.txt -i https://pypi.mirrors.ustc.edu.cn/simple/
二. windows10下yolov11 tensorrtx推理加速
##官网下载tensorrtx
git clone https://github.com/wang-xinyu/tensorrtx.git
##进入yolov11文件夹,转换模型.pt转.wts
python gen_wts.py -w D:codeultralytics-mainyolo11n.pt -o yolo11n.wts -t detect

注意:pytorch2.6需要修改代码中的torch.load,在里面添加weigths_only=False

修改cmakeList.txt文件
根据自己的opencv,tensort,dirent所在目录路径,修改以下文件路径
cmake_minimum_required(VERSION 3.10)
project(yolov11)
add_definitions(-std=c++11)
add_definitions(-DAPI_EXPORTS)
add_compile_definitions(NOMINMAX)
set(CMAKE_CXX_STANDARD 11)
set(CMAKE_BUILD_TYPE Debug)
set(CMAKE_CUDA_ARCHITECTURES 70 75 80 86)
set(CMAKE_CUDA_COMPILER "C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v11.8/bin/nvcc.exe")
enable_language(CUDA)
include_directories(${PROJECT_SOURCE_DIR}/include)
include_directories(${PROJECT_SOURCE_DIR}/plugin)
# include and link dirs of cuda and tensorrt, you need adapt them if yours are different
if(CMAKE_SYSTEM_PROCESSOR MATCHES "aarch64")
message("embed_platform on")
include_directories(/usr/local/cuda/targets/aarch64-linux/include)
link_directories(/usr/local/cuda/targets/aarch64-linux/lib)
else()
message("embed_platform off")
# cuda
find_package(CUDA REQUIRED)
include_directories(${CUDA_INCLUDE_DIRS})
# tensorrt
set(TRT_DIR "C:\\Program Files\\NVIDIA GPU Computing Toolkit\\CUDA\\TensorRT-8.6.0.12")
set(TRT_INCLUDE_DIRS ${TRT_DIR}\include)
set(TRT_LIB_DIRS ${TRT_DIR}\\lib)
include_directories(${TRT_INCLUDE_DIRS})
link_directories(${TRT_LIB_DIRS})
# opencv
set(OpenCV_DIR "D:\\Program Files\\opencv\\build")
set(OpenCV_INCLUDE_DIRS ${OpenCV_DIR}\include)
set(OpenCV_LIB_DIRS ${OpenCV_DIR}\\x64\\vc16\\lib)
set(OpenCV_Debug_LIBS "opencv_world4110d.lib")
set(OpenCV_Release_LIBS "opencv_world4110.lib")
include_directories(${OpenCV_INCLUDE_DIRS})
link_directories(${OpenCV_LIB_DIRS})
# dirent
set(Dirent_INCLUDE_DIRS "D:\\Program Files\\dirent\\include")
include_directories(${Dirent_INCLUDE_DIRS})
endif()
add_library(myplugins SHARED ${PROJECT_SOURCE_DIR}/plugin/yololayer.cu)
target_link_libraries(myplugins nvinfer cudart)
file(GLOB_RECURSE SRCS ${PROJECT_SOURCE_DIR}/src/*.cpp ${PROJECT_SOURCE_DIR}/src/*.cu)
add_executable(yolo11_det ${PROJECT_SOURCE_DIR}/yolo11_det.cpp ${SRCS})
target_link_libraries(yolo11_det nvinfer)
target_link_libraries(yolo11_det cudart)
target_link_libraries(yolo11_det myplugins)
target_link_libraries(yolo11_det ${OpenCV_Debug_LIBS})
target_link_libraries(yolo11_det ${OpenCV_Release_LIBS})
add_executable(yolo11_cls ${PROJECT_SOURCE_DIR}/yolo11_cls.cpp ${SRCS})
target_link_libraries(yolo11_cls nvinfer)
target_link_libraries(yolo11_cls cudart)
target_link_libraries(yolo11_cls myplugins)
target_link_libraries(yolo11_cls ${OpenCV_Debug_LIBS})
target_link_libraries(yolo11_cls ${OpenCV_Release_LIBS})
add_executable(yolo11_seg ${PROJECT_SOURCE_DIR}/yolo11_seg.cpp ${SRCS})
target_link_libraries(yolo11_seg nvinfer)
target_link_libraries(yolo11_seg cudart)
target_link_libraries(yolo11_seg myplugins)
target_link_libraries(yolo11_seg ${OpenCV_Debug_LIBS})
target_link_libraries(yolo11_seg ${OpenCV_Release_LIBS})
add_executable(yolo11_pose ${PROJECT_SOURCE_DIR}/yolo11_pose.cpp ${SRCS})
target_link_libraries(yolo11_pose nvinfer)
target_link_libraries(yolo11_pose cudart)
target_link_libraries(yolo11_pose myplugins)
target_link_libraries(yolo11_pose ${OpenCV_Debug_LIBS})
target_link_libraries(yolo11_pose ${OpenCV_Release_LIBS})
add_executable(yolo11_obb ${PROJECT_SOURCE_DIR}/yolo11_obb.cpp ${SRCS})
target_link_libraries(yolo11_obb nvinfer)
target_link_libraries(yolo11_obb cudart)
target_link_libraries(yolo11_obb myplugins)
target_link_libraries(yolo11_obb ${OpenCV_Debug_LIBS})
target_link_libraries(yolo11_obb ${OpenCV_Release_LIBS})
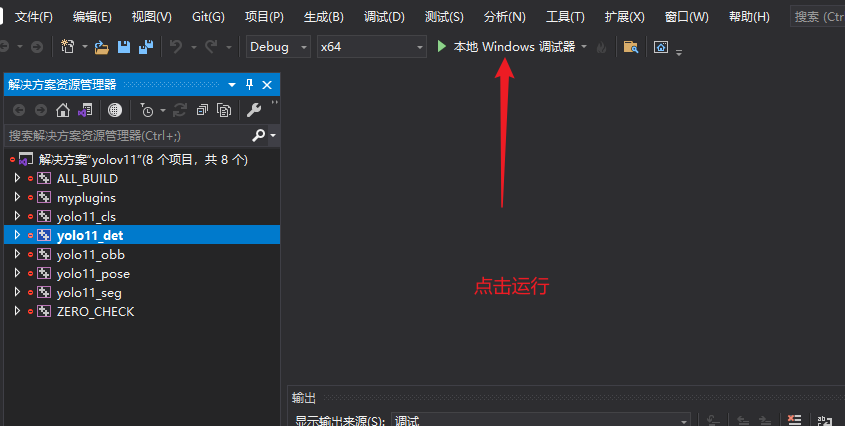
构建项目
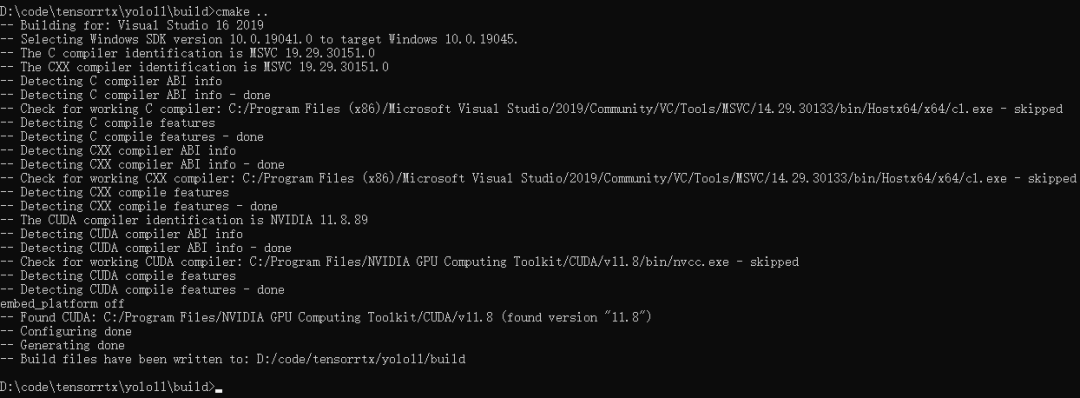
mkdir build
cd build
cmake ..
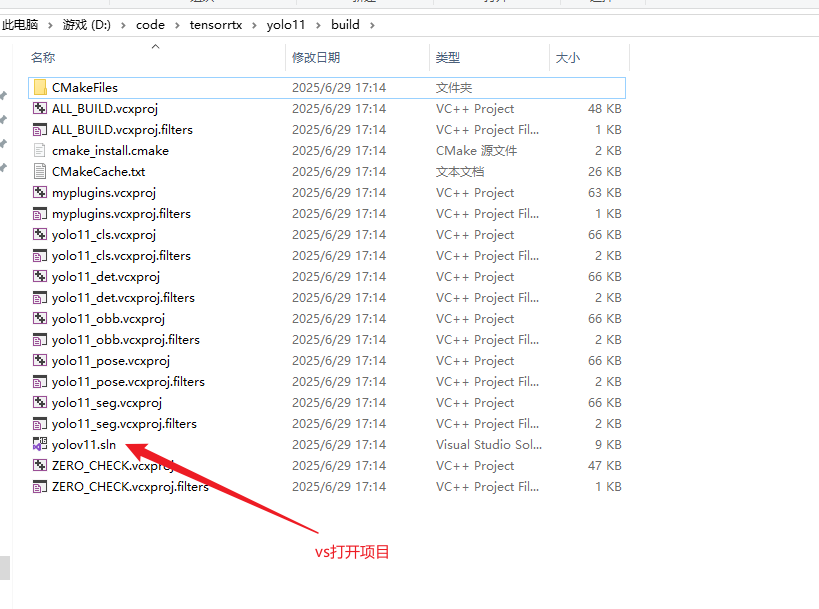
vs打开项目,生成解决方案
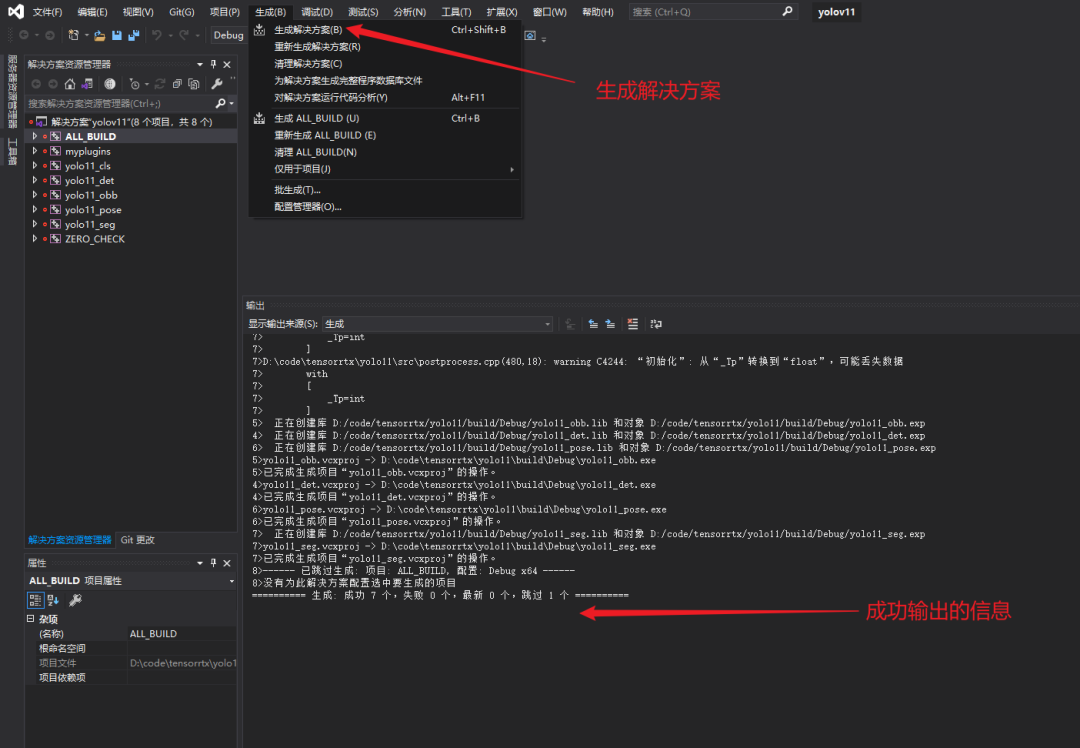
装换.wts为.engine
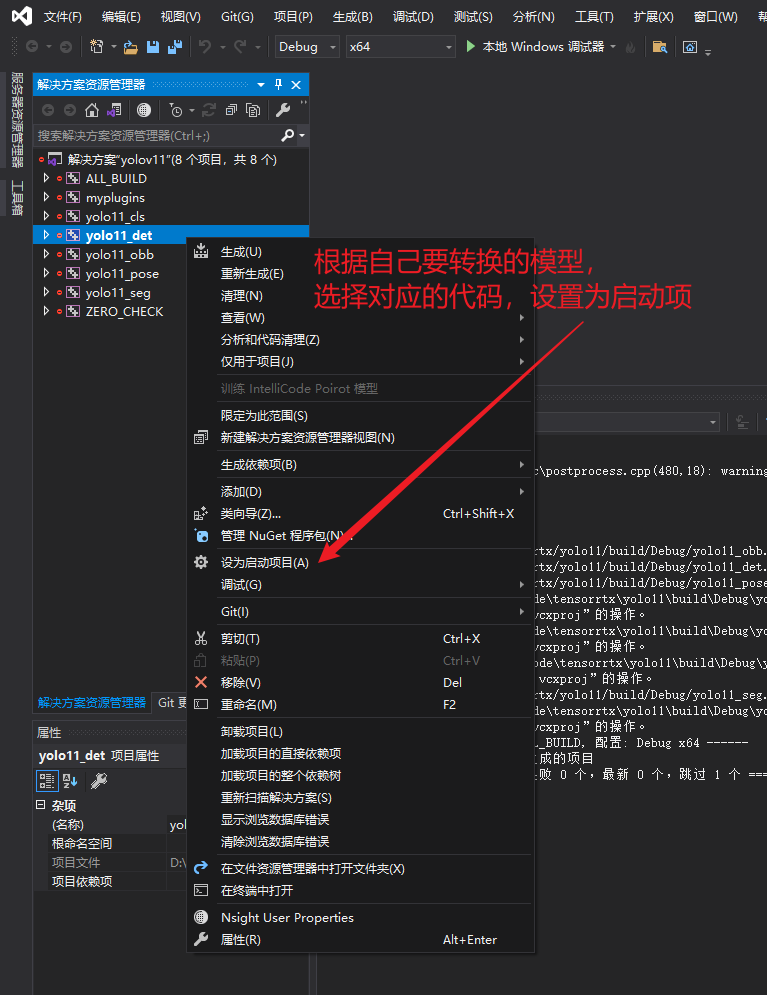
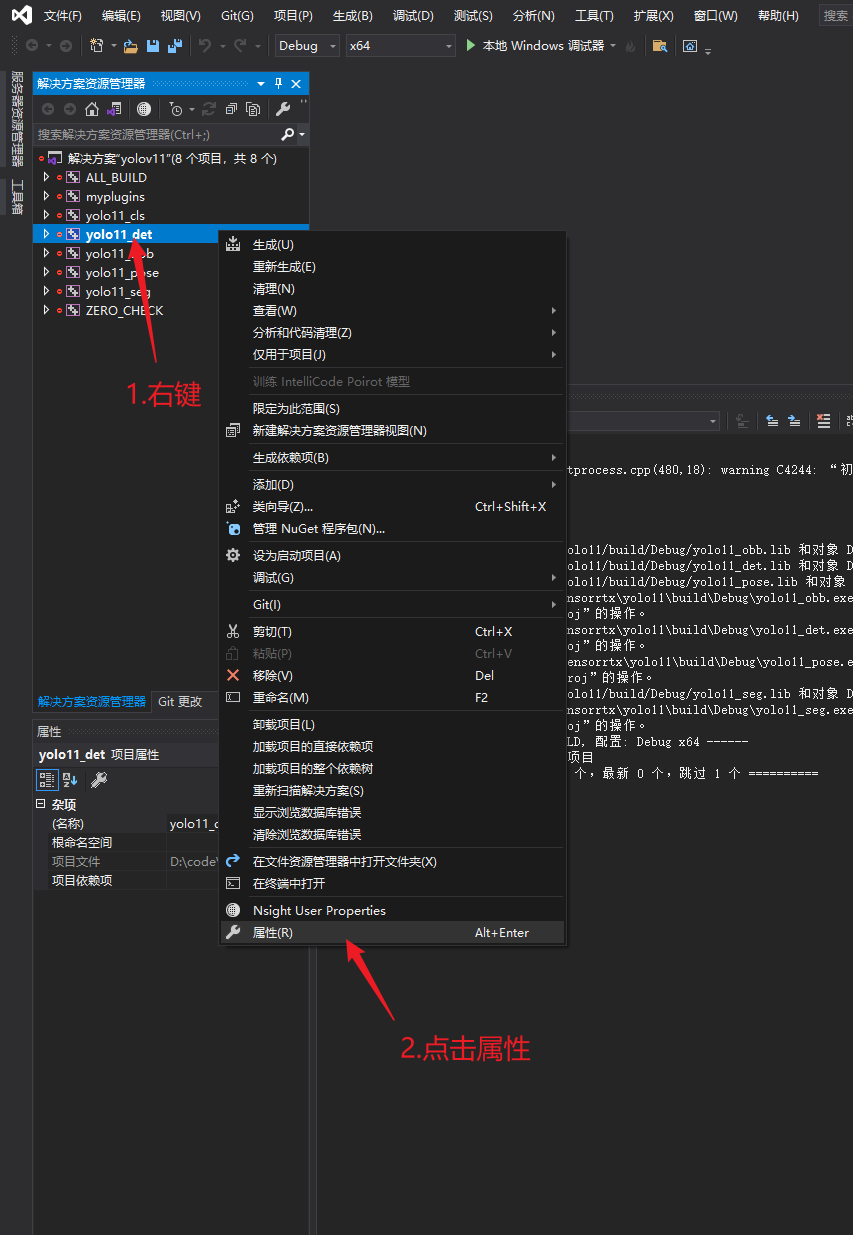
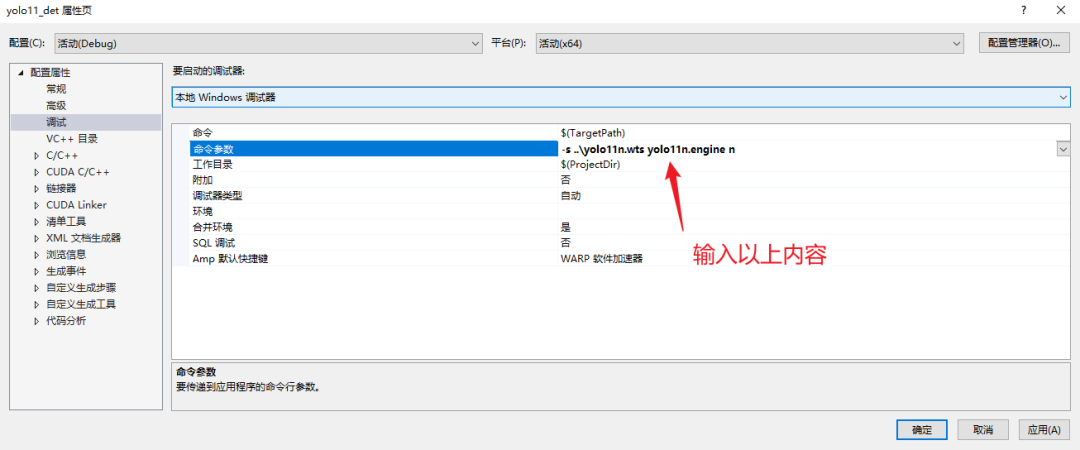
转换前,这里需要根据自己的模型,修改对应的配置,配置文件在以下位置
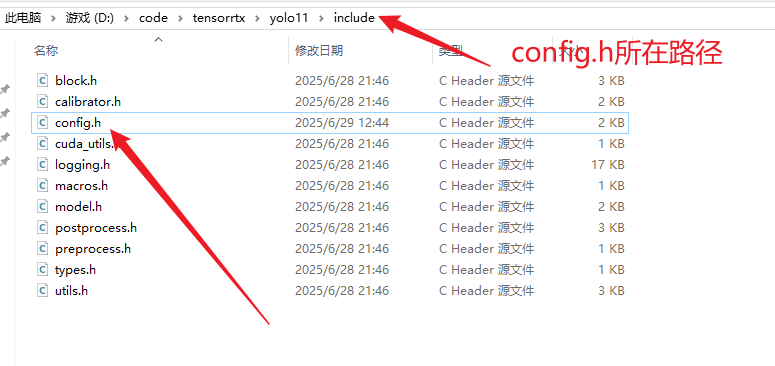
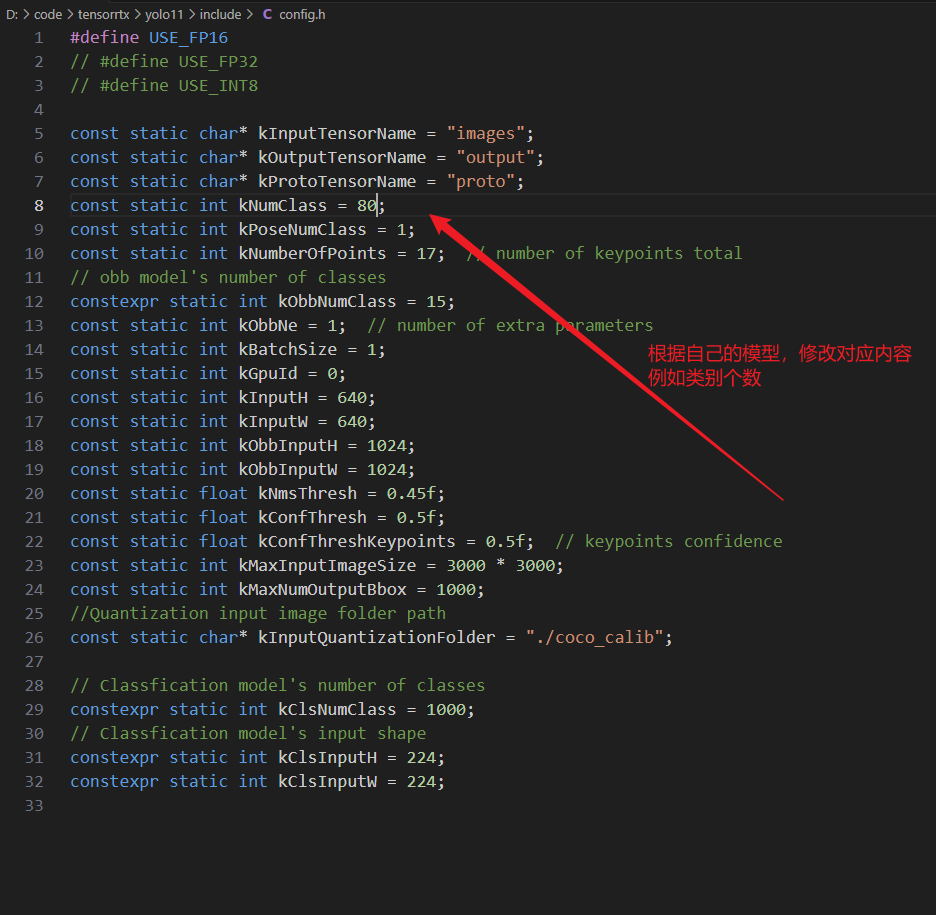
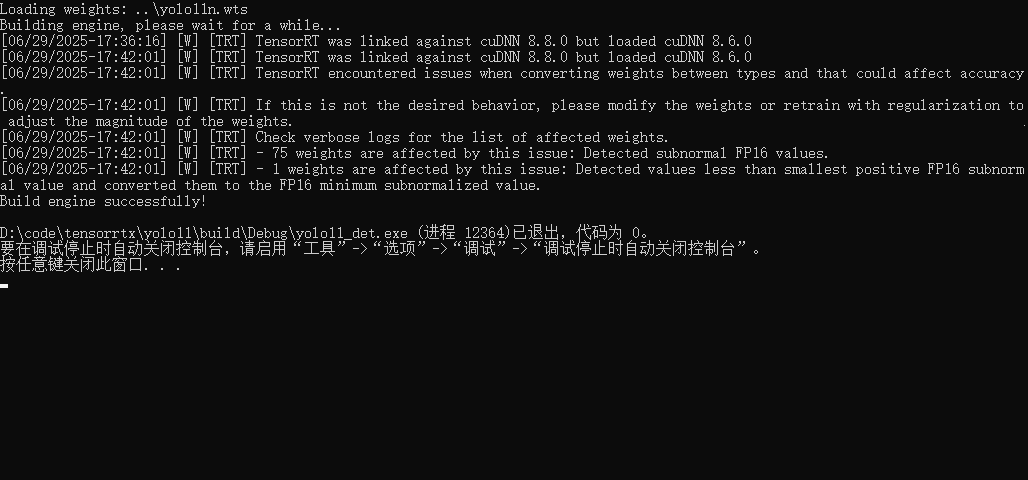
-s ..\yolo11n.wts yolo11n.engine n
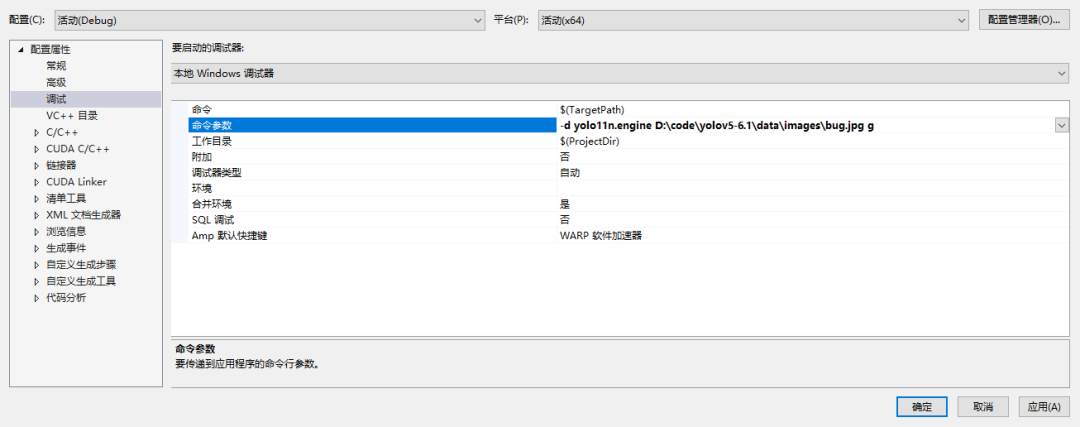
利用转换好的.engine进行推理
-d yolo11n.engine D:\code\yolov5-6.1\data\images g

windows10下qt调用tensorrtx加速的yolov11进行检测
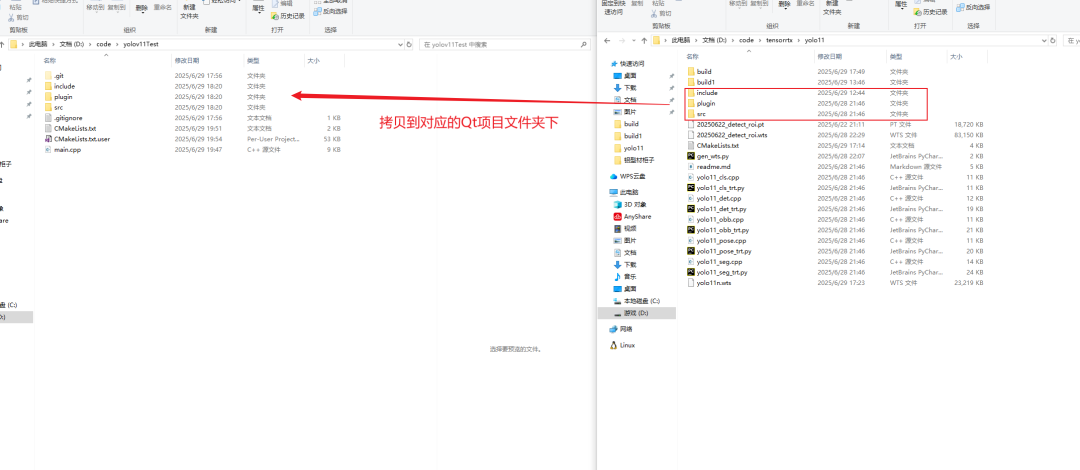
修改Qt项目中的cmakeList.txt文件如下:
cmake_minimum_required(VERSION 3.5)
project(yolov11Test LANGUAGES CXX)
add_definitions(-std=c++11)
add_definitions(-DAPI_EXPORTS)
add_compile_definitions(NOMINMAX)
set(CMAKE_CXX_STANDARD 17)
set(CMAKE_CXX_STANDARD_REQUIRED ON)
set(CMAKE_CUDA_ARCHITECTURES 70 75 80 86)
set(CMAKE_CUDA_COMPILER "C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v11.8/bin/nvcc.exe")
enable_language(CUDA)
include_directories(${PROJECT_SOURCE_DIR}/include)
include_directories(${PROJECT_SOURCE_DIR}/plugin)
# cuda
find_package(CUDA REQUIRED)
include_directories(${CUDA_INCLUDE_DIRS})
# tensorrt
set(TRT_DIR "C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\TensorRT-8.6.0.12")
set(TRT_INCLUDE_DIRS ${TRT_DIR}\\include)
set(TRT_LIB_DIRS ${TRT_DIR}\lib)
include_directories(${TRT_INCLUDE_DIRS})
link_directories(${TRT_LIB_DIRS})
# opencv
set(OpenCV_DIR "D:\Program Files\opencv\build")
set(OpenCV_INCLUDE_DIRS ${OpenCV_DIR}\\include)
set(OpenCV_LIB_DIRS ${OpenCV_DIR}\x64\vc16\lib)
set(OpenCV_Debug_LIBS "opencv_world4110d.lib")
set(OpenCV_Release_LIBS "opencv_world4110.lib")
include_directories(${OpenCV_INCLUDE_DIRS})
link_directories(${OpenCV_LIB_DIRS})
# dirent
set(Dirent_INCLUDE_DIRS "D:\Program Files\dirent\include")
include_directories(${Dirent_INCLUDE_DIRS})
add_library(myplugins SHARED ${PROJECT_SOURCE_DIR}/plugin/yololayer.cu)
target_link_libraries(myplugins nvinfer cudart)
file(GLOB_RECURSE SRCS ${PROJECT_SOURCE_DIR}/src/*.cpp ${PROJECT_SOURCE_DIR}/src/*.cu)
add_executable(yolov11Test main.cpp ${SRCS})
target_link_libraries(yolov11Test nvinfer)
target_link_libraries(yolov11Test cudart)
target_link_libraries(yolov11Test myplugins)
target_link_libraries(yolov11Test ${OpenCV_Debug_LIBS})
target_link_libraries(yolov11Test ${OpenCV_Release_LIBS})
install(TARGETS yolov11Test
LIBRARY DESTINATION ${CMAKE_INSTALL_LIBDIR}
RUNTIME DESTINATION ${CMAKE_INSTALL_BINDIR}
)
main函数代码如下:
#include <fstream>
#include <iostream>
#include <opencv2/opencv.hpp>
#include "cuda_utils.h"
#include "logging.h"
#include "model.h"
#include "postprocess.h"
#include "preprocess.h"
#include "utils.h"
Logger gLogger;
usingnamespace nvinfer1;
constint kOutputSize = kMaxNumOutputBbox * sizeof(Detection) / sizeof(float) + 1;
void deserialize_engine(std::string& engine_name, IRuntime** runtime, ICudaEngine** engine, IExecutionContext** context)
{
std::ifstream file(engine_name, std::ios::binary);
if (!file.good())
{
std::cerr << "read " << engine_name << " error!" << std::endl;
assert(false);
}
size_t size = 0;
file.seekg(0, file.end);
size = file.tellg();
file.seekg(0, file.beg);
char* serialized_engine = newchar[size];
assert(serialized_engine);
file.read(serialized_engine, size);
file.close();
*runtime = createInferRuntime(gLogger);
assert(*runtime);
*engine = (*runtime)->deserializeCudaEngine(serialized_engine, size);
assert(*engine);
*context = (*engine)->createExecutionContext();
assert(*context);
delete[] serialized_engine;
}
void prepare_buffer(ICudaEngine* engine, float** input_buffer_device, float** output_buffer_device, float** output_buffer_host, float** decode_ptr_host, float** decode_ptr_device, std::string cuda_post_process)
{
assert(engine->getNbBindings() == 2);
// In order to bind the buffers, we need to know the names of the input and output tensors.
// Note that indices are guaranteed to be less than IEngine::getNbBindings()
constint inputIndex = engine->getBindingIndex(kInputTensorName);
constint outputIndex = engine->getBindingIndex(kOutputTensorName);
assert(inputIndex == 0);
assert(outputIndex == 1);
// Create GPU buffers on device
CUDA_CHECK(cudaMalloc((void**)input_buffer_device, kBatchSize * 3 * kInputH * kInputW * sizeof(float)));
CUDA_CHECK(cudaMalloc((void**)output_buffer_device, kBatchSize * kOutputSize * sizeof(float)));
if (cuda_post_process == "c") {
*output_buffer_host = newfloat[kBatchSize * kOutputSize];
} elseif (cuda_post_process == "g") {
if (kBatchSize > 1) {
std::cerr << "Do not yet support GPU post processing for multiple batches" << std::endl;
exit(0);
}
// Allocate memory for decode_ptr_host and copy to device
*decode_ptr_host = newfloat[1 + kMaxNumOutputBbox * bbox_element];
CUDA_CHECK(cudaMalloc((void**)decode_ptr_device, sizeof(float) * (1 + kMaxNumOutputBbox * bbox_element)));
}
}
void infer(IExecutionContext& context, cudaStream_t& stream, void** buffers, float* output, int batchsize,
float* decode_ptr_host, float* decode_ptr_device, int model_bboxes, std::string cuda_post_process) {
// infer on the batch asynchronously, and DMA output back to host
auto start = std::chrono::system_clock::now();
context.enqueueV2(buffers, stream, nullptr);
if (cuda_post_process == "c") {
CUDA_CHECK(cudaMemcpyAsync(output, buffers[1], batchsize * kOutputSize * sizeof(float), cudaMemcpyDeviceToHost,
stream));
auto end = std::chrono::system_clock::now();
std::cout << "inference time: " << std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count()
<< "ms" << std::endl;
} elseif (cuda_post_process == "g") {
CUDA_CHECK(
cudaMemsetAsync(decode_ptr_device, 0, sizeof(float) * (1 + kMaxNumOutputBbox * bbox_element), stream));
cuda_decode((float*)buffers[1], model_bboxes, kConfThresh, decode_ptr_device, kMaxNumOutputBbox, stream);
cuda_nms(decode_ptr_device, kNmsThresh, kMaxNumOutputBbox, stream); //cuda nms
CUDA_CHECK(cudaMemcpyAsync(decode_ptr_host, decode_ptr_device,
sizeof(float) * (1 + kMaxNumOutputBbox * bbox_element), cudaMemcpyDeviceToHost,
stream));
auto end = std::chrono::system_clock::now();
std::cout << "inference and gpu postprocess time: "
<< std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count() << "ms" << std::endl;
}
CUDA_CHECK(cudaStreamSynchronize(stream));
}
int main(int argc, char** argv) {
// yolo11_det -s ../models/yolo11n.wts ../models/yolo11n.fp32.trt n
// yolo11_det -d ../models/yolo11n.fp32.trt ../images c
cudaSetDevice(kGpuId);
std::string engine_name= "D:\code\tensorrtx\yolo11\build\yolo11n.engine"; //转换好的模型文件路径
std::string img_dir= "D:\code\yolov5-6.1\data\images\"; //要预测的图像文件夹所在路径
std::string cuda_post_process = "g";
int model_bboxes;
float gd = 0, gw = 0;
int max_channels = 0;
// 反序列化模型文件 Deserialize the engine from file
IRuntime* runtime = nullptr;
ICudaEngine* engine = nullptr;
IExecutionContext* context = nullptr;
deserialize_engine(engine_name, &runtime, &engine, &context);
cudaStream_t stream;
CUDA_CHECK(cudaStreamCreate(&stream));
cuda_preprocess_init(kMaxInputImageSize);
auto out_dims = engine->getBindingDimensions(1);
model_bboxes = out_dims.d[0];
// 准备cpu和gpu缓存 Prepare cpu and gpu buffers
float* device_buffers[2];
float* output_buffer_host = nullptr;
float* decode_ptr_host = nullptr;
float* decode_ptr_device = nullptr;
// 从文件夹中读取图像 Read images from directory
std::vector<std::string> file_names;
if (read_files_in_dir(img_dir.c_str(), file_names) < 0) {
std::cerr << "read_files_in_dir failed." << std::endl;
return -1;
}
prepare_buffer(engine, &device_buffers[0], &device_buffers[1], &output_buffer_host, &decode_ptr_host,
&decode_ptr_device, cuda_post_process);
// 批预测batch predict
for (size_t i = 0; i < file_names.size(); i += kBatchSize)
{
// 通过opencv读取一批图像Get a batch of images
std::vector<cv::Mat> img_batch;
std::vector<std::string> img_name_batch;
for (size_t j = i; j < i + kBatchSize && j < file_names.size(); j++)
{
cv::Mat img = cv::imread(img_dir + "/" + file_names[j]);
img_batch.push_back(img);
img_name_batch.push_back(file_names[j]);
}
// Preprocess
cuda_batch_preprocess(img_batch, device_buffers[0], kInputW, kInputH, stream);
// 进行推理Run inference
infer(*context, stream, (void**)device_buffers, output_buffer_host, kBatchSize, decode_ptr_host,
decode_ptr_device, model_bboxes, cuda_post_process);
// 保存output_buffer_host的前100个值,一行一个
// std::ofstream out("../models/output.txt");
// for (int j = 0; j < 100; j++) {
// out << output_buffer_host[j] << std::endl;
// }
// out.close();
std::vector<std::vector<Detection>> res_batch;
if (cuda_post_process == "c")
{
// NMS非极大值抑制
batch_nms(res_batch, output_buffer_host, img_batch.size(), kOutputSize, kConfThresh, kNmsThresh);
} else if (cuda_post_process == "g")
{
//GPU非极大值抑制Process gpu decode and nms results
batch_process(res_batch, decode_ptr_host, img_batch.size(), bbox_element, img_batch);
}
// 绘制结果Draw bounding boxes
draw_bbox(img_batch, res_batch);
//显示图像
for (size_t j = 0; j < img_batch.size(); j++)
{
cv::imshow("results", img_batch[j]);
cv::waitKey(0);
}
// 保存图像Save images
for (size_t j = 0; j < img_batch.size(); j++)
{
cv::imwrite("_" + img_name_batch[j], img_batch[j]);
}
}
// Release stream and buffers
cudaStreamDestroy(stream);
CUDA_CHECK(cudaFree(device_buffers[0]));
CUDA_CHECK(cudaFree(device_buffers[1]));
CUDA_CHECK(cudaFree(decode_ptr_device));
delete[] decode_ptr_host;
delete[] output_buffer_host;
cuda_preprocess_destroy();
// Destroy the engine
delete context;
delete engine;
delete runtime;
// Print histogram of the output distribution
//std::cout << "nOutput:nn";
//for (unsigned int i = 0; i < kOutputSize; i++)
//{
// std::cout << prob[i] << ", ";
// if (i % 10 == 0) std::cout << std::endl;
//}
//std::cout << std::endl;
return 0;
}
本文仅做学术分享,如有侵权,请联系删文。
(文:极市干货)