
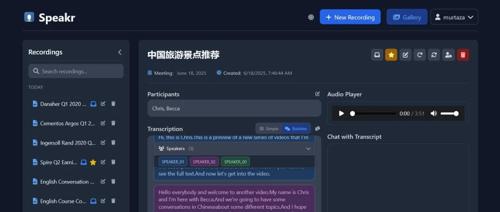
项目简介
Speakr 是一款个人自托管的网络应用程序,专为转录音频记录(如会议)、生成简洁的摘要和标题,并通过聊天界面与内容互动而设计。您可以将所有会议记录和见解安全地保存在自己的服务器上。
功能
-
音频上传: 通过拖放或文件选择上传音频文件(MP3、WAV、M4A等,具体取决于您的转录端点)。 -
浏览器录音: 在“新录音”屏幕上直接从浏览器录制音频(需要HTTPS或HTTP的浏览器配置 – 参见部署指南)。 -
转录: 在标准OpenAI兼容API或更高级的ASR网络服务之间选择。 -
说话人分离: (仅限ASR/WhisperX)自动检测并分离转录中的不同说话人。 -
直观的说话人标记: 新的、更直观的界面用于识别和标记说话人。 -
AI摘要与标题生成: 使用可配置的LLM生成简洁的标题和摘要。 -
互动聊天: 使用AI模型提问并与转录内容互动。 -
元数据编辑: 编辑标题、参与者、会议日期、摘要和笔记。 -
用户管理: 安全的用户注册和登录系统,带有管理用户的管理面板。 -
自定义: 用户可以设置自己的语言偏好、自定义摘要提示和专业上下文,以改进AI结果。
安装说明
详细部署说明,请参阅部署指南
推荐的方法是使用预构建的Docker镜像,这种方法快速且简单。
简单设置(预构建Docker镜像)
此方法无需克隆此仓库。您只需安装Docker。
-
创建
docker-compose.yml文件:创建一个名为docker-compose.yml的新文件,并将以下内容粘贴到其中:services:app:image: learnedmachine/speakr:latestcontainer_name: speakrrestart: unless-stoppedports:- "8899:8899"env_file:- .envvolumes:- ./uploads:/data/uploads- ./instance:/data/instance -
-
创建配置(
.env)文件:您的选择取决于您希望使用的转录方法。有关每个服务必须实现的端点的详细信息,请参阅上面的API端点要求部分。创建一个名为.env的新文件,并将以下模板之一粘贴到其中。 -
选项A:标准Whisper API方法使用
/audio/transcriptions端点。这是最简单的方法,适用于OpenAI、OpenRouter、本地API和其他实现OpenAI Whisper API格式的提供商。# --- 文本生成模型(使用/chat/completions端点) ---TEXT_MODEL_BASE_URL=https://openrouter.ai/api/v1TEXT_MODEL_API_KEY=your_openrouter_api_keyTEXT_MODEL_NAME=openai/gpt-4o-mini# --- 转录服务(使用/audio/transcriptions端点) ---TRANSCRIPTION_BASE_URL=https://api.openai.com/v1TRANSCRIPTION_API_KEY=your_openai_api_keyWHISPER_MODEL=whisper-1# --- 应用程序设置 ---ALLOW_REGISTRATION=falseSUMMARY_MAX_TOKENS=8000CHAT_MAX_TOKENS=5000# --- 管理员用户(首次运行时创建) ---ADMIN_USERNAME=adminADMIN_EMAIL=admin@example.comADMIN_PASSWORD=changeme# --- Docker设置(很少需要更改) ---SQLALCHEMY_DATABASE_URI=sqlite:////data/instance/transcriptions.dbUPLOAD_FOLDER=/data/uploads现在,编辑
.env文件,填入您的API密钥和设置。 -
选项B:ASR网络服务方法(用于说话人分离)使用
/asr端点。此方法需要单独的ASR网络服务容器,但支持说话人识别。已测试与onerahmet/openai-whisper-asr-webservice镜像兼容。有关如何运行ASR服务的说明,请参阅部署指南。# --- 文本生成模型(使用/chat/completions端点) ---TEXT_MODEL_BASE_URL=https://openrouter.ai/api/v1TEXT_MODEL_API_KEY=your_openrouter_api_keyTEXT_MODEL_NAME=openai/gpt-4o-mini# --- 转录服务(使用/asr端点) ---USE_ASR_ENDPOINT=trueASR_BASE_URL=http://your_asr_host:9000 # 您运行的ASR网络服务的URLASR_DIARIZE=trueASR_MIN_SPEAKERS=1ASR_MAX_SPEAKERS=5# --- 应用程序设置 ---ALLOW_REGISTRATION=falseSUMMARY_MAX_TOKENS=8000CHAT_MAX_TOKENS=5000# --- 管理员用户(首次运行时创建) ---ADMIN_USERNAME=adminADMIN_EMAIL=admin@example.comADMIN_PASSWORD=changeme# --- Docker设置(很少需要更改) ---SQLALCHEMY_DATABASE_URI=sqlite:////data/instance/transcriptions.dbUPLOAD_FOLDER=/data/uploads现在,编辑
.env文件,填入您的ASR服务URL和其他设置。 -
-
启动应用程序:在您的终端中,进入包含
docker-compose.yml和.env文件的目录,运行:docker compose up -d -
高级设置(从源代码构建)
如果您想修改代码或自行构建Docker镜像,请先克隆仓库。
-
克隆仓库: git clone https://github.com/murtaza-nasir/speakr.gitcd speakr -
-
创建 docker-compose.yml和.env文件:从仓库中复制示例文件。cp docker-compose.example.yml docker-compose.yml# 标准APIcp env.whisper.example .env# 或ASR网络服务cp env.asr.example .env编辑
.env文件,填入您的设置。 -
-
构建并启动: docker compose up -d --build -
推荐的ASR网络服务设置
说话人分离仅适用于ASR方法,并需要whisperx引擎。 以下是运行ASR服务本身的docker-compose.yml示例。您需要额外运行此容器与Speakr应用容器。
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineservices:whisper-asr-webservice:image: onerahmet/openai-whisper-asr-webservice:latest-gpucontainer_name: whisper-asr-webserviceports:- "9000:9000"environment:- ASR_MODEL=distil-large-v3 # 或large-v3, medium- ASR_COMPUTE_TYPE=float16 # 或int8, float32- ASR_ENGINE=whisperx # 说话人分离必需- HF_TOKEN=your_hugging_face_token # 可选deploy:resources:reservations:devices:- driver: nvidiacapabilities: [gpu]device_ids: ["0"]restart: unless-stopped
关于说话人分离准确性的说明: 为了获得最佳结果,通常将说话人数量设置为比实际数量略高(例如多1-2个)。您可以在说话人识别模态中稍后合并说话人。
Speakr已测试与推荐的onerahmet/openai-whisper-asr-webservice镜像兼容。其他ASR网络服务可能可用但未经测试。
ASR设置的重要提示: 说话人分离需要Hugging Face令牌并接受受保护模型(pyannote)的条款。如果遇到问题,请使用docker logs whisper-asr-webservice检查ASR容器日志以进行故障排除。
完整的ASR设置说明、模型配置、故障排除和日志分析,请参阅部署指南
使用指南
-
注册/登录: 访问 http://localhost:8899。管理员用户首次启动时从.env文件中的ADMIN_*变量创建。 -
设置偏好(推荐): 转到您的账户页面。在这里您可以: -
设置您偏好的转录和输出语言。 -
定义自定义摘要提示以根据您的需求定制摘要。 -
添加您的姓名、职位和公司,为AI聊天互动提供更多上下文。 -
查看和管理保存的说话人。 -
上传或录制: -
上传: 转到新录音或将音频文件拖放到页面上。 -
录制: 在“新录音”屏幕上使用浏览器录音功能直接从麦克风录制(需要HTTPS或浏览器配置 – 参见浏览器录音设置)。 -
上传和处理状态将显示在弹出窗口中。 -
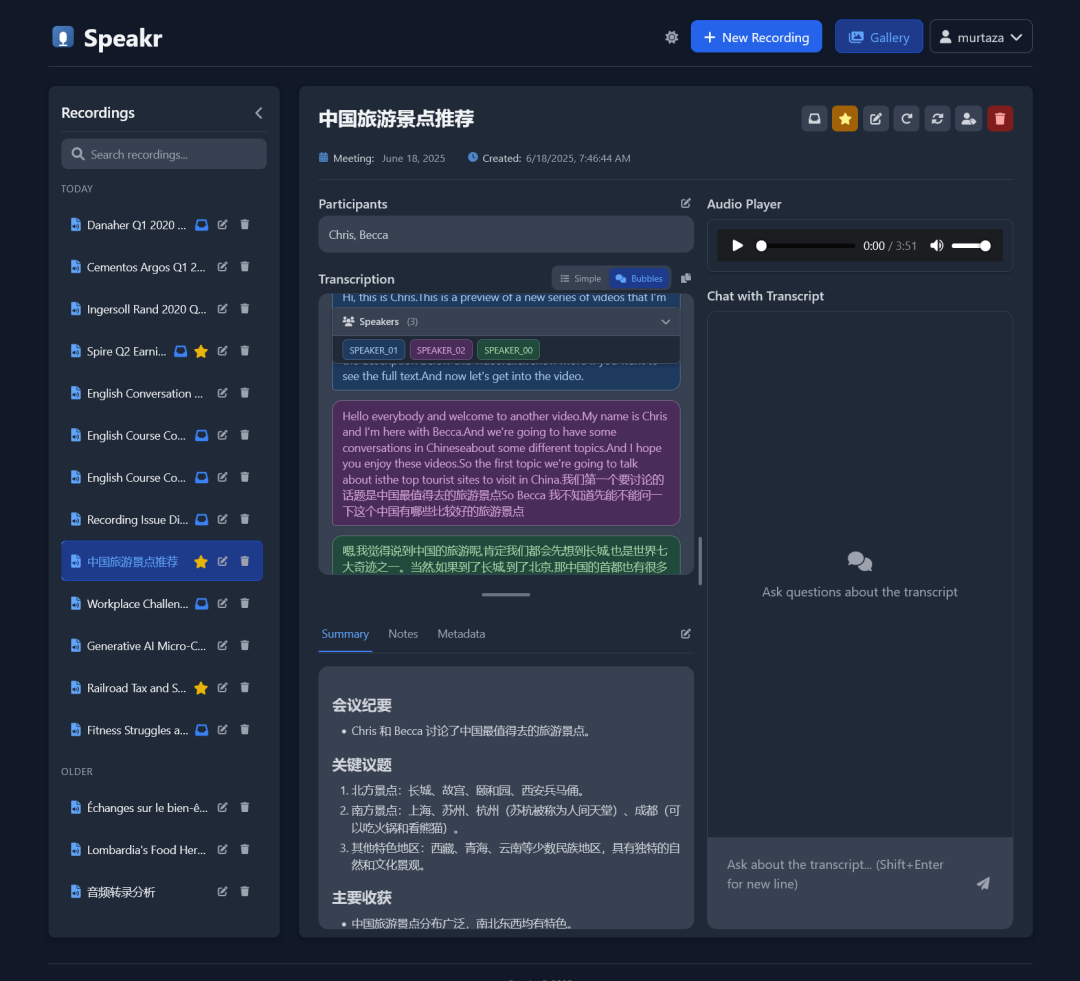
查看与互动: -
主图库列出您的录音。点击一个以查看其详细信息。 -
收听内置播放器的音频。 -
阅读转录和AI生成的摘要。 -
编辑标题、参与者和其他元数据。 -
与转录聊天: 使用聊天面板提问关于录音的问题。 -
说话人分离工作流程: -
要启用说话人分离,您必须使用ASR端点方法并在 .env文件中设置ASR_DIARIZE=true。 -
当使用此选项处理录音时,说话人将自动检测并分配通用标签(例如 SPEAKER 00、SPEAKER 01)。 -
处理后,点击转录页面上的识别说话人按钮。 -
在说话人识别模态中,您可以手动为每个说话人分配名称。 -
或者,使用自动识别按钮让AI模型尝试根据对话上下文识别和命名说话人。 -
保存的说话人将在未来会话中建议自动完成。 -
如果需要,您还可以使用重新处理按钮以不同的说话人分离设置重新转录音频。
项目地址
https://github.com/murtaza-nasir/speakr/blob/master/README.md
扫码加入技术交流群,备注「开发语言-城市-昵称」
(文:GitHubStore)