

招商局狮子山人工智能实验室 投稿
量子位 | 公众号 QbitAI
大模型可以不再依赖人类调教,真正“自学成才”啦?
新研究仅通过RLVR(可验证奖励的强化学习),成功让模型自主进化出通用的探索、验证与记忆能力,让模型学会“自学”!

当前主流的LLM Agent依然高度依赖于提示词工程、复杂的系统编排、甚至静态规则表,这使得它们在面对复杂任务时难以实现真正的智能行为演化。
而来自招商局狮子山人工智能实验室的研究团队认为,RLVR范式是智能体(Agent)通往更高通用性和自主性的重要突破口。
于是,他们从两个关键层面出发构建了端到端Agent训练pipeline——L0系统:
- 智能体架构层面
提出了结构化智能体框架——NB-Agent,在经典”代码即行动”(Code-as-Action)架构基础上进行扩展,使智能体能够操作记忆/上下文,从而获得类人类的记忆存储、信息总结与自我反思能力。 - 学习范式层面
探索了一个核心问题:是否可以仅通过RLVR范式,引导智能体从零开始,学会如何规划、搜索、验证与记忆,最终解决复杂的多轮推理任务?
L0系统的框架、模型及训练集已全部开源,详细可见文末链接。
结构化智能体框架:Notebook Agent(NB-Agent)
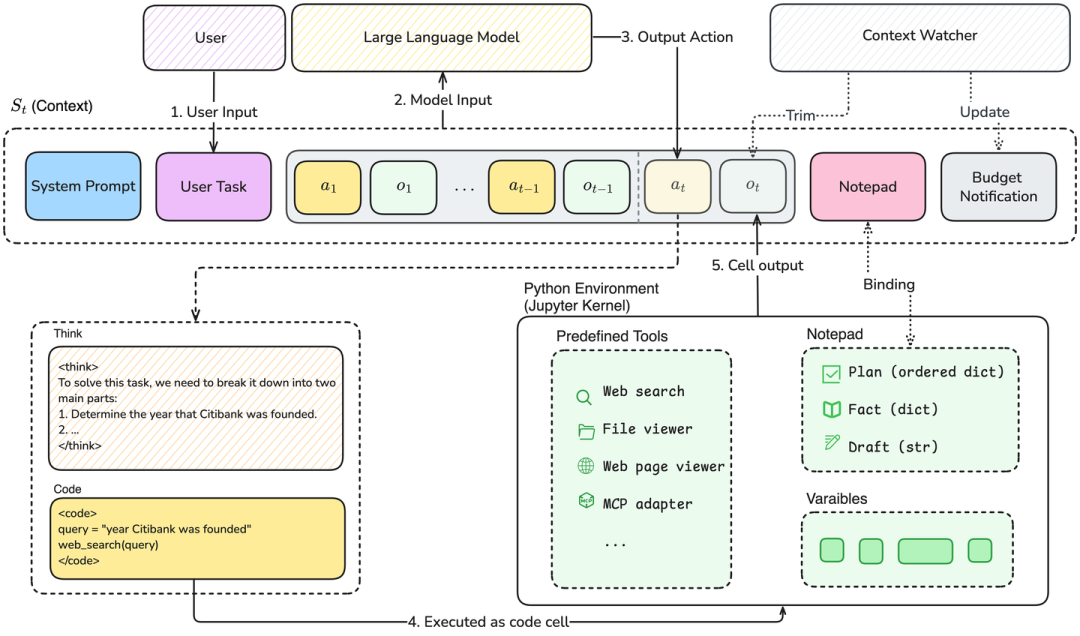
△NB-Agent的“Think-Code-Observe”循环
受到“代码即行动”的启发,NB-Agent选择使用代码作为通用的动作空间,并且遵循“读取-求值-输出”循环(Read-Eval-Print-Loop,REPL)的方式来和Jupyter Kernel交互。
每一步都是“Think-Code-Observe”:
-
Think:模型生成推理逻辑; -
Code:将推理转化为Python代码; -
Observe:执行代码并观察输出结果,反馈进入下一轮思考。
在这个过程中,长文本处理是智能体驱动模型(Agentic model)面临的核心挑战。
为此,研究团队提出一个创新方案:将模型的上下文窗口(context)与一个Python运行时的变量进行双向绑定。
这赋予了智能体主动管理自身记忆的能力,不再被动受限于上下文长度。
具体来说,研究团队提供了一个Notepad Python类作为结构化的外部记忆模块。智能体可以通过代码指令,将关键信息、推理步骤或中间结果写入Notepad。
这些信息会持久存在,并映射到上下文中一个稳定区域,确保在长程任务中不被遗忘。
同时,REPL的交互模式,使智能体能像程序员一样,将复杂信息存入变量、随时取用,从而彻底突破上下文的枷锁。
训练流程:端到端强化学习
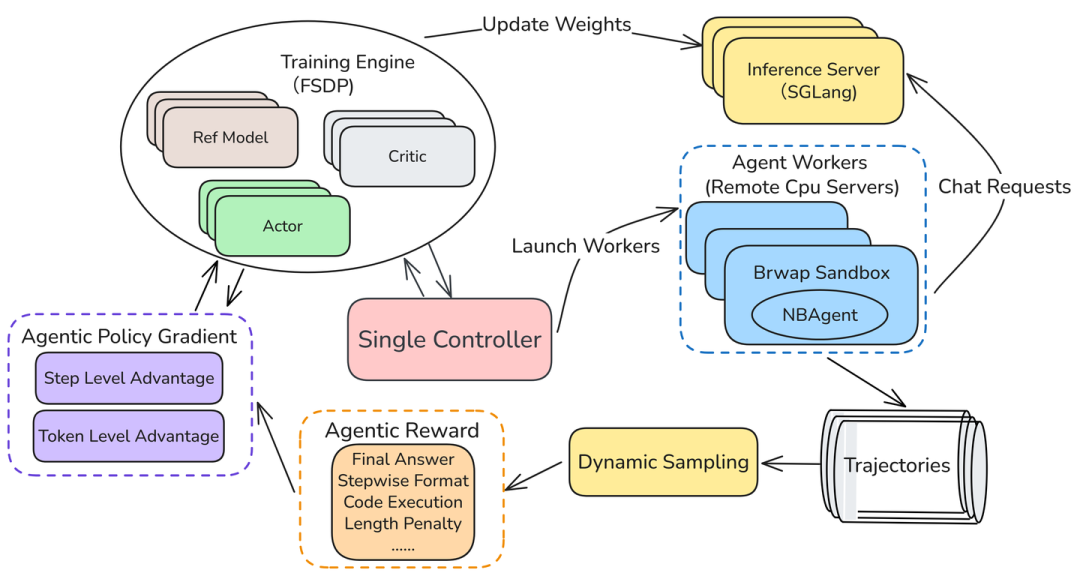
△L0的multi-turn训练过程
L0采用端到端强化学习进行智能体训练:
- 重新定义动作粒度
一个动作不再是一个token,而是一个完整的“思考+代码段”; - 提出Agentic Policy Gradient算法
适应序列级动作定义,将策略梯度从单token级扩展到完整动作序列级; - 构建多维度自动奖励函数
包括最终答案正确性、代码执行情况、输出结构规范性等; - 分布式训练架构
采用轻量级沙箱隔离(Bubblewrap),支持高并发、低部署门槛的大规模RL训练。
测试:L0显著提升了模型在多个基准测试上的性能
在多个经典的开放领域问答数据集对L0系统进行测试,见证了智能体的惊人进化。
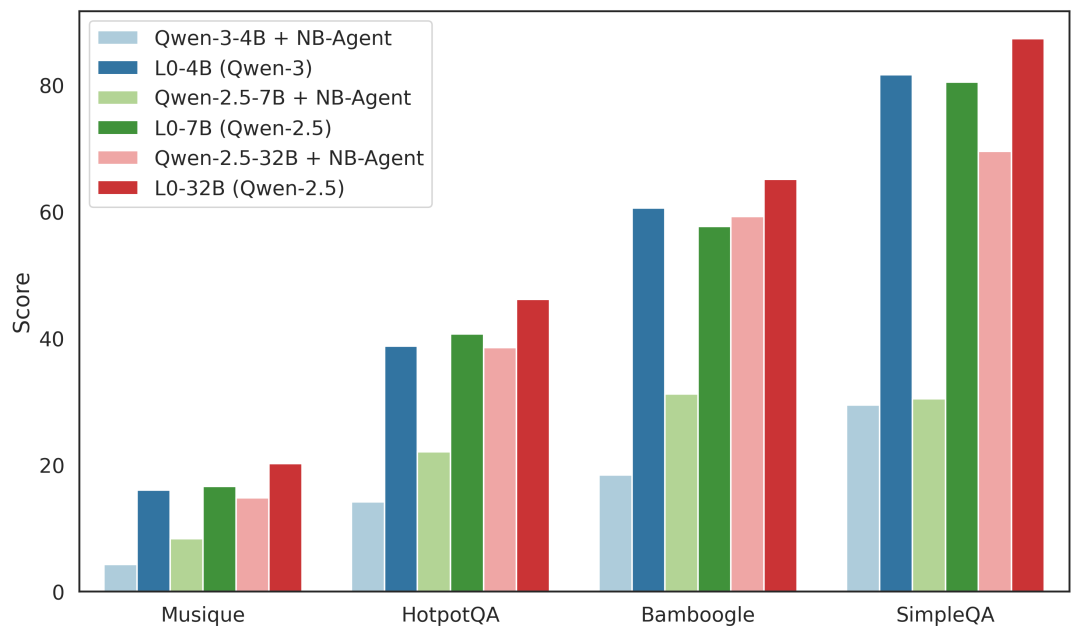
以Qwen2.5-7B这个基础模型为例:
在L0-Scaffold(仅有架构,未经过RL训练)下,它就像一个刚拿到Notebook的新手,在HotpotQA上得分22%。
经过L0-RL(强化学习训练)后,它学会了如何高效搜索、验证信息、剔除冗余步骤,最终在同一任务上得分飙升至41%(提升84%)。
在SimpleQA数据集上,L0-RL带来的提升更加显著:EM(精确匹配)得分从30%暴涨到80%(提升166%)。
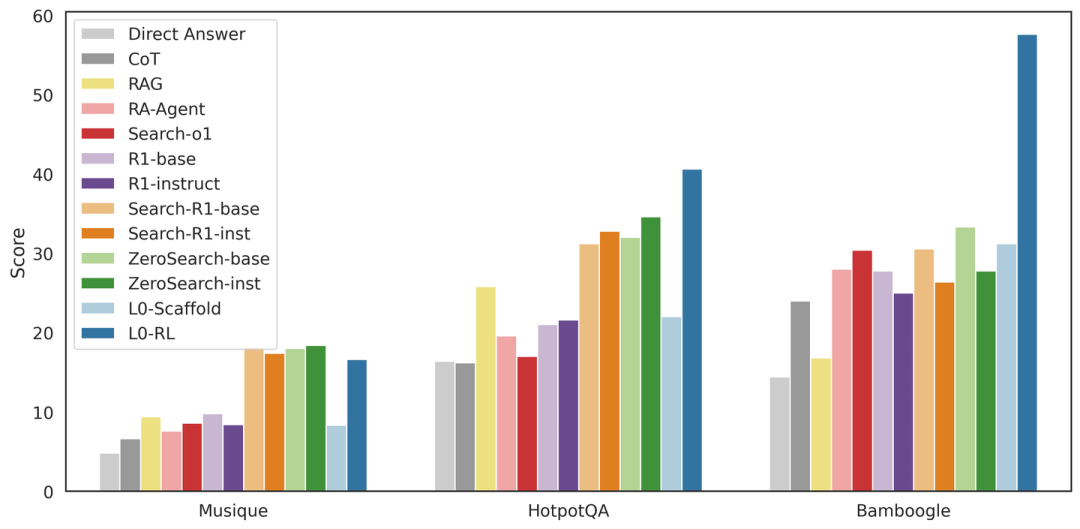
L0在与其他工作的比较中也获得了具有竞争力的性能,在平均表现上明显优于Search-R1和ZeroSearch。
这表明L0框架为强化学习提供了更丰富和更具表现力的环境:其他方法训练智能体学习何时调用单个工具(例如搜索引擎),而L0框架训练智能体成为一个程序化的问题解决者,学习如何在结构化环境中组合动作、管理状态和进行推理。
这意味着什么?
在真实搜索之外,模型自己“学会”的搜索、规划和记忆行为,比直接调用API的规则式Agent更稳定、更泛化、也更强大!
它不再是生硬地调用工具,而是真正理解了怎么利用代码和这个世界交互,展现了通往更高级通用智能的清晰路径。
论文:https://github.com/cmriat/l0/tree/main/papers/l0.pdf
NB-Agent框架、训练pipeline和所有训练recipe:https://github.com/cmriat/l0
模型checkpoint:https://huggingface.co/cmriat/models
20K训练数据集:https://huggingface.co/cmriat/datasets
用checkpoint执行深度搜索任务的示例:https://github.com/cmriat/l0/blob/main/examples/nb_agent/deep_searcher_case.md
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —

🌟 点亮星标 🌟
(文:量子位)