
本文使用Dify v1.4.0版本,主要解析了commands.py中的convert_to_agent_apps、add_qdrant_index、old_metadata_migration、create_tenant和upgrade_db等函数的执行逻辑。源码位置:dify\api\commands.py
一.convert_to_agent_apps()函数
完整的执行命令示例,如下所示:
flask convert-to-agent-apps
该命令用于批量升级”Agent Assistant”应用为”Agent App”,并保证相关会话同步更新,适合数据结构或业务升级场景。每一步都包含异常处理,确保单个 app 出错不会影响整体流程。
@click.command("convert-to-agent-apps", help="Convert Agent Assistant to Agent App.")
defconvert_to_agent_apps():
"""
Convert Agent Assistant to Agent App.
"""
click.echo(click.style("Starting convert to agent apps.", fg="green"))
proceeded_app_ids = []
whileTrue:
# fetch first 1000 apps
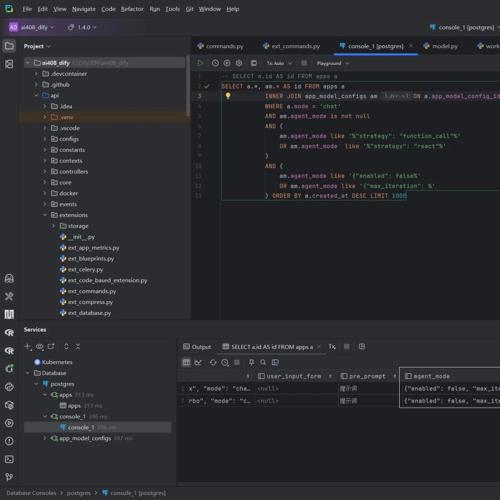
sql_query = """SELECT a.id AS id FROM apps a
INNER JOIN app_model_configs am ON a.app_model_config_id=am.id
WHERE a.mode = 'chat'
AND am.agent_mode is not null
AND (
am.agent_mode like '%"strategy": "function_call"%'
OR am.agent_mode like '%"strategy": "react"%'
)
AND (
am.agent_mode like '{"enabled": true%'
OR am.agent_mode like '{"max_iteration": %'
) ORDER BY a.created_at DESC LIMIT 1000
"""
with db.engine.begin() as conn:
rs = conn.execute(db.text(sql_query))
apps = []
for i in rs:
app_id = str(i.id)
if app_id notin proceeded_app_ids:
proceeded_app_ids.append(app_id)
app = db.session.query(App).filter(App.id == app_id).first()
if app isnotNone:
apps.append(app)
if len(apps) == 0:
break
for app in apps:
click.echo("Converting app: {}".format(app.id))
try:
app.mode = AppMode.AGENT_CHAT.value
db.session.commit()
# update conversation mode to agent
db.session.query(Conversation).filter(Conversation.app_id == app.id).update(
{Conversation.mode: AppMode.AGENT_CHAT.value}
)
db.session.commit()
click.echo(click.style("Converted app: {}".format(app.id), fg="green"))
except Exception as e:
click.echo(click.style("Convert app error: {} {}".format(e.__class__.__name__, str(e)), fg="red"))
click.echo(click.style("Conversion complete. Converted {} agent apps.".format(len(proceeded_app_ids)), fg="green"))
1.命令定义与初始化
注册了一个名为 convert-to-agent-apps 的 Click 命令,并初始化处理过的 app id 列表。
@click.command("convert-to-agent-apps", help="Convert Agent Assistant to Agent App.")
defconvert_to_agent_apps():
"""
Convert Agent Assistant to Agent App.
"""
click.echo(click.style("Starting convert to agent apps.", fg="green"))
proceeded_app_ids = []
2.循环批量查询待转换的应用
通过 SQL 查询筛选出符合条件的前 1000 个 app,避免重复处理。
whileTrue:
# fetch first 1000 apps
sql_query = """SELECT a.id AS id FROM apps a
INNER JOIN app_model_configs am ON a.app_model_config_id=am.id
WHERE a.mode = 'chat'
AND am.agent_mode is not null
AND (
am.agent_mode like '%"strategy": "function_call"%'
OR am.agent_mode like '%"strategy": "react"%'
)
AND (
am.agent_mode like '{"enabled": true%'
OR am.agent_mode like '{"max_iteration": %'
) ORDER BY a.created_at DESC LIMIT 1000
"""
with db.engine.begin() as conn:
rs = conn.execute(db.text(sql_query))
apps = []
for i in rs:
app_id = str(i.id)
if app_id notin proceeded_app_ids:
proceeded_app_ids.append(app_id)
app = db.session.query(App).filter(App.id == app_id).first()
if app isnotNone:
apps.append(app)
if len(apps) == 0:
break
此 SQL 查询筛选出”聊天模式”下,agent 配置不为空,且策略为 function_call 或 react,并且 agent_mode 字段格式符合特定要求的 app ID,供后续批量处理。如下所示:
-
SELECT a.id AS id FROM apps a从apps表(别名为 a)中选择 id 字段。 -
INNER JOIN app_model_configs am ON a.app_model_config_id=am.id通过app_model_config_id字段与app_model_configs表(别名am)做内连接,获取每个 app 模型配置。 -
WHERE a.mode = 'chat'只筛选mode字段为chat的 app。 -
AND am.agent_mode is not null只要模型配置中的agent_mode字段不为 null。 -
AND (am.agent_mode like '%"strategy": "function_call"%' OR am.agent_mode like '%"strategy": "react"%')agent_mode字段内容需包含"strategy": "function_call"或"strategy": "react",即只处理有这两种策略的 agent。 -
AND (am.agent_mode like '{"enabled": true%' OR am.agent_mode like '{"max_iteration": %')agent_mode字段内容需以{"enabled": true开头,或包含{"max_iteration":,进一步限定 agent 的配置格式。 -
ORDER BY a.created_at DESC LIMIT 1000按创建时间倒序排列,最多取 1000 条。
3.遍历并转换每个应用
对每个查到的 app,修改其 mode 字段,并同步更新相关会话的 mode 字段。
for app in apps:
click.echo("Converting app: {}".format(app.id))
try:
app.mode = AppMode.AGENT_CHAT.value
db.session.commit()
# update conversation mode to agent
db.session.query(Conversation).filter(Conversation.app_id == app.id).update(
{Conversation.mode: AppMode.AGENT_CHAT.value}
)
db.session.commit()
click.echo(click.style("Converted app: {}".format(app.id), fg="green"))
except Exception as e:
click.echo(click.style("Convert app error: {} {}".format(e.__class__.__name__, str(e)), fg="red"))
4.结束提示
输出转换完成信息和总共转换的 app 数量。
click.echo(click.style("Conversion complete. Converted {} agent apps.".format(len(proceeded_app_ids)), fg="green"))
注解:Dify中的应用类型包括:
class AppMode(StrEnum):
COMPLETION = "completion"
WORKFLOW = "workflow"
CHAT = "chat"
ADVANCED_CHAT = "advanced-chat"
AGENT_CHAT = "agent-chat"
CHANNEL = "channel"从上面的条件设置
WHERE a.mode = 'chat'只筛选mode字段为chat的 app,即聊天助手(简单配置即可构建基于 LLM 的对话机器人)。但是,默认创建的”聊天助手”应用都不满足如下条件:因此,该命令应该暂时没有用处。
二.add_qdrant_index()函数
完整的执行命令示例,如下所示:
flask add-qdrant-index --field metadata.doc_id
该命令 add_qdrant_index 的主要作用是为所有 DatasetCollectionBinding 绑定的 Qdrant 向量集合创建 payload 索引。
@click.command("add-qdrant-index", help="Add Qdrant index.")
@click.option("--field", default="metadata.doc_id", prompt=False, help="Index field , default is metadata.doc_id.")
defadd_qdrant_index(field: str):
click.echo(click.style("Starting Qdrant index creation.", fg="green"))
create_count = 0
try:
bindings = db.session.query(DatasetCollectionBinding).all()
ifnot bindings:
click.echo(click.style("No dataset collection bindings found.", fg="red"))
return
import qdrant_client
from qdrant_client.http.exceptions import UnexpectedResponse
from qdrant_client.http.models import PayloadSchemaType
from core.rag.datasource.vdb.qdrant.qdrant_vector import QdrantConfig
for binding in bindings:
if dify_config.QDRANT_URL isNone:
raise ValueError("Qdrant URL is required.")
qdrant_config = QdrantConfig(
endpoint=dify_config.QDRANT_URL,
api_key=dify_config.QDRANT_API_KEY,
root_path=current_app.root_path,
timeout=dify_config.QDRANT_CLIENT_TIMEOUT,
grpc_port=dify_config.QDRANT_GRPC_PORT,
prefer_grpc=dify_config.QDRANT_GRPC_ENABLED,
)
try:
client = qdrant_client.QdrantClient(**qdrant_config.to_qdrant_params())
# create payload index
client.create_payload_index(binding.collection_name, field, field_schema=PayloadSchemaType.KEYWORD)
create_count += 1
except UnexpectedResponse as e:
# Collection does not exist, so return
if e.status_code == 404:
click.echo(click.style(f"Collection not found: {binding.collection_name}.", fg="red"))
continue
# Some other error occurred, so re-raise the exception
else:
click.echo(
click.style(
f"Failed to create Qdrant index for collection: {binding.collection_name}.", fg="red"
)
)
except Exception:
click.echo(click.style("Failed to create Qdrant client.", fg="red"))
click.echo(click.style(f"Index creation complete. Created {create_count} collection indexes.", fg="green"))
1.命令定义与参数
定义了一个 click 命令 add-qdrant-index,可选参数 --field,默认值为 metadata.doc_id。
@click.command("add-qdrant-index", help="Add Qdrant index.")
@click.option("--field", default="metadata.doc_id", prompt=False, help="Index field , default is metadata.doc_id.")
defadd_qdrant_index(field: str):
2.输出开始信息
输出开始创建索引的信息。
click.echo(click.style("Starting Qdrant index creation.", fg="green"))
3.初始化计数器
用于统计成功创建索引的集合数量。
create_count = 0
4. 查询所有DatasetCollectionBinding记录
尝试获取所有集合绑定,如果没有则输出提示并返回。
try:
bindings = db.session.query(DatasetCollectionBinding).all()
ifnot bindings:
click.echo(click.style("No dataset collection bindings found.", fg="red"))
return
5.导入Qdrant相关依赖
动态导入 qdrant 客户端及相关异常、类型定义。
import qdrant_client
from qdrant_client.http.exceptions import UnexpectedResponse
from qdrant_client.http.models import PayloadSchemaType
from core.rag.datasource.vdb.qdrant.qdrant_vector import QdrantConfig
6.遍历每个binding,创建索引
对每个 binding,构造 QdrantConfig,初始化 QdrantClient,调用 create_payload_index 创建索引。
for binding in bindings:
if dify_config.QDRANT_URL isNone:
raise ValueError("Qdrant URL is required.")
qdrant_config = QdrantConfig(
endpoint=dify_config.QDRANT_URL,
api_key=dify_config.QDRANT_API_KEY,
root_path=current_app.root_path,
timeout=dify_config.QDRANT_CLIENT_TIMEOUT,
grpc_port=dify_config.QDRANT_GRPC_PORT,
prefer_grpc=dify_config.QDRANT_GRPC_ENABLED,
)
try:
client = qdrant_client.QdrantClient(**qdrant_config.to_qdrant_params())
# create payload index
client.create_payload_index(binding.collection_name, field, field_schema=PayloadSchemaType.KEYWORD)
create_count += 1
client.create_payload_index(...)代码会在 Qdrant 的某个集合上为指定字段创建一个关键词类型的索引,以便后续可以高效地通过该字段进行过滤和检索。如下所示:
-
client是 Qdrant 的 Python 客户端实例,用于与 Qdrant 向量数据库进行交互。 -
create_payload_index是 Qdrant 客户端的方法,用于在指定的集合(collection)上为某个字段(payload field)创建索引,以提升检索效率。 -
binding.collection_name指定了要在哪个 Qdrant 集合上创建索引,通常对应一个数据集的向量集合名称。 -
field是要被索引的字段名,默认为metadata.doc_id,也可以通过命令行参数指定。 -
field_schema=PayloadSchemaType.KEYWORD指定该字段的类型为 KEYWORD,表示该字段是离散的、可枚举的字符串类型,适合做精确匹配索引。
7.异常处理
如果集合不存在(404),输出提示并跳过;其他异常输出错误信息。
except UnexpectedResponse as e:
# Collection does not exist, so return
if e.status_code == 404:
click.echo(click.style(f"Collection not found: {binding.collection_name}.", fg="red"))
continue
# Some other error occurred, so re-raise the exception
else:
click.echo(
click.style(
f"Failed to create Qdrant index for collection: {binding.collection_name}.", fg="red"
)
)
8.总体异常处理
如果整体流程出错,输出失败信息。
except Exception:
click.echo(click.style("Failed to create Qdrant client.", fg="red"))
9.输出完成信息
输出创建索引的总数。
click.echo(click.style(f"Index creation complete. Created {create_count} collection indexes.", fg="green"))
注解:
1.Dify支持的支持向量数据库:包括weaviate、qdrant、milvus、myscale、relyt、pgvecto_rs、pgvector、pgvector、chroma、opensearch、tidb_vector、couchbase、vikingdb、upstash、lindorm、oceanbase、opengauss、tablestore。默认为weaviate,而qdrant只是其中的一种向量数据库。
2.collection_name相当于Qdrant中的表名:在 Qdrant(一个向量数据库)中,
collection_name表示集合的名称。集合(Collection)是 Qdrant 中用于存储一组向量及其元数据的逻辑分区。每个集合可以有不同的配置、索引和数据隔离。
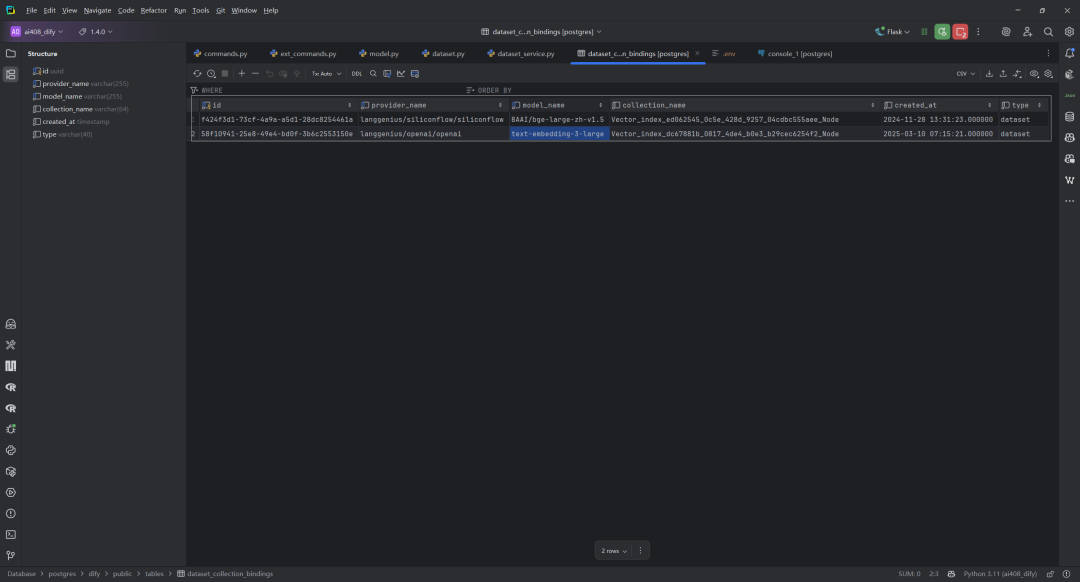
3.DatasetCollectionBinding数据表:用于管理知识库(数据集)与向量集合(collection)的绑定关系。它的主要作用是记录每个数据集在不同向量检索服务(如不同的 provider 和 model)下所对应的集合名称。这样可以支持多模型、多服务商的向量存储和检索,便于灵活切换和扩展。表结构说明:
provider_name:向量服务提供商名称(如 OpenAI、自建等)。
model_name:使用的向量模型名称。
type:绑定类型,通常为 dataset。
collection_name:实际在向量数据库中的集合名。
created_at:创建时间。通过该表,可以实现同一个知识库(数据集)在不同向量服务/模型下的多集合管理,支持多租户和多模型检索场景。
三.old_metadata_migration()函数
完整的执行命令示例,如下所示:
flask old-metadata-migration
该函数 old_metadata_migration 主要用于将 DatasetDocument 表中 doc_metadata 字段的旧元数据迁移到新的 DatasetMetadata 和 DatasetMetadataBinding 表中。
@click.command("old-metadata-migration", help="Old metadata migration.")
defold_metadata_migration():
"""
Old metadata migration.
"""
click.echo(click.style("Starting old metadata migration.", fg="green"))
page = 1
whileTrue:
try:
stmt = (
select(DatasetDocument)
.filter(DatasetDocument.doc_metadata.is_not(None))
.order_by(DatasetDocument.created_at.desc())
)
documents = db.paginate(select=stmt, page=page, per_page=50, max_per_page=50, error_out=False)
except NotFound:
break
ifnot documents:
break
for document in documents:
if document.doc_metadata:
doc_metadata = document.doc_metadata
for key, value in doc_metadata.items():
for field in BuiltInField:
if field.value == key:
break
else:
dataset_metadata = (
db.session.query(DatasetMetadata)
.filter(DatasetMetadata.dataset_id == document.dataset_id, DatasetMetadata.name == key)
.first()
)
ifnot dataset_metadata:
dataset_metadata = DatasetMetadata(
tenant_id=document.tenant_id,
dataset_id=document.dataset_id,
name=key,
type="string",
created_by=document.created_by,
)
db.session.add(dataset_metadata)
db.session.flush()
dataset_metadata_binding = DatasetMetadataBinding(
tenant_id=document.tenant_id,
dataset_id=document.dataset_id,
metadata_id=dataset_metadata.id,
document_id=document.id,
created_by=document.created_by,
)
db.session.add(dataset_metadata_binding)
else:
dataset_metadata_binding = (
db.session.query(DatasetMetadataBinding) # type: ignore
.filter(
DatasetMetadataBinding.dataset_id == document.dataset_id,
DatasetMetadataBinding.document_id == document.id,
DatasetMetadataBinding.metadata_id == dataset_metadata.id,
)
.first()
)
ifnot dataset_metadata_binding:
dataset_metadata_binding = DatasetMetadataBinding(
tenant_id=document.tenant_id,
dataset_id=document.dataset_id,
metadata_id=dataset_metadata.id,
document_id=document.id,
created_by=document.created_by,
)
db.session.add(dataset_metadata_binding)
db.session.commit()
page += 1
click.echo(click.style("Old metadata migration completed.", fg="green"))
1.命令定义与初始化
@click.command("old-metadata-migration", help="Old metadata migration.")
defold_metadata_migration():
"""
Old metadata migration.
"""
click.echo(click.style("Starting old metadata migration.", fg="green"))
-
通过
click注册命令行命令old-metadata-migration。 -
输出迁移开始提示。
2.分页遍历所有有doc_metadata的DatasetDocument
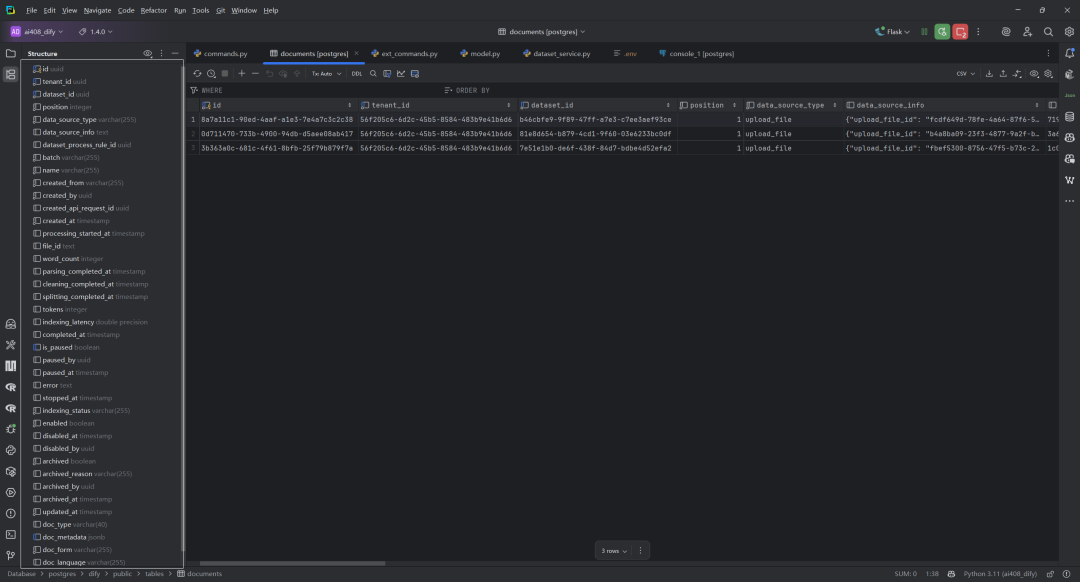
DatasetDocument(表名documents)数据表的结构,如下所示:
page = 1
whileTrue:
try:
stmt = (
select(DatasetDocument)
.filter(DatasetDocument.doc_metadata.is_not(None))
.order_by(DatasetDocument.created_at.desc())
)
documents = db.paginate(select=stmt, page=page, per_page=50, max_per_page=50, error_out=False)
except NotFound:
break
ifnot documents:
break
-
每次分页查询 50 条
doc_metadata不为空的DatasetDocument。 -
如果没有更多数据,跳出循环。
3.遍历每个文档,处理其 doc_metadata 字段
for document in documents:
if document.doc_metadata:
doc_metadata = document.doc_metadata
for key, value in doc_metadata.items():
for field in BuiltInField:
if field.value == key:
break
else:
dataset_metadata = (
db.session.query(DatasetMetadata)
.filter(DatasetMetadata.dataset_id == document.dataset_id, DatasetMetadata.name == key)
.first()
)
ifnot dataset_metadata:
dataset_metadata = DatasetMetadata(
tenant_id=document.tenant_id,
dataset_id=document.dataset_id,
name=key,
type="string",
created_by=document.created_by,
)
db.session.add(dataset_metadata)
db.session.flush()
dataset_metadata_binding = DatasetMetadataBinding(
tenant_id=document.tenant_id,
dataset_id=document.dataset_id,
metadata_id=dataset_metadata.id,
document_id=document.id,
created_by=document.created_by,
)
db.session.add(dataset_metadata_binding)
else:
dataset_metadata_binding = (
db.session.query(DatasetMetadataBinding) # type: ignore
.filter(
DatasetMetadataBinding.dataset_id == document.dataset_id,
DatasetMetadataBinding.document_id == document.id,
DatasetMetadataBinding.metadata_id == dataset_metadata.id,
)
.first()
)
ifnot dataset_metadata_binding:
dataset_metadata_binding = DatasetMetadataBinding(
tenant_id=document.tenant_id,
dataset_id=document.dataset_id,
metadata_id=dataset_metadata.id,
document_id=document.id,
created_by=document.created_by,
)
db.session.add(dataset_metadata_binding)
db.session.commit()
遍历每个文档的 doc_metadata 字典,跳过已在 BuiltInField 枚举中的字段(内置字段)。对于每个自定义 key:
-
查询 DatasetMetadata:首先通过
db.session.query(DatasetMetadata)...first()查询当前文档(document)对应数据集(dataset_id)和元数据名(key)的元数据记录。 -
不存在则新建:如果没有查到(
if not dataset_metadata),则新建一个DatasetMetadata实例,填充相关字段,并add到 session,然后flush(),确保id可用。 -
创建绑定关系:新建
DatasetMetadataBinding记录,关联元数据和文档,同样add到 session。 -
已存在则查绑定:如果元数据已存在,则查询是否已存在绑定关系(
DatasetMetadataBinding),如果没有,则新建并add。 -
提交事务:最后统一
db.session.commit(),将所有变更写入数据库。
整个流程是:先查有无元数据,无则新建,再查有无绑定,无则新建,最后提交。每一步都通过 SQLAlchemy ORM 生成并执行 SQL 语句。
4.进入下一页,直到处理完所有文档
处理完当前页后,页码加一,继续下一页。
page += 1
5.迁移完成提示
输出迁移完成提示。
click.echo(click.style("Old metadata migration completed.", fg="green"))
四.create_tenant()函数
完整的执行命令示例,如下所示:
flask create-tenant --email your@email.com --name "工作区名称" --language zh-CN
执行后会在终端输出类似:
Account and tenant created.
Account: your@email.com
Password: <自动生成的密码>
该 create_tenant 命令用于通过命令行交互创建租户账号和工作区。
@click.command("create-tenant", help="Create account and tenant.")
@click.option("--email", prompt=True, help="Tenant account email.")
@click.option("--name", prompt=True, help="Workspace name.")
@click.option("--language", prompt=True, help="Account language, default: en-US.")
defcreate_tenant(email: str, language: Optional[str] = None, name: Optional[str] = None):
"""
Create tenant account
"""
ifnot email:
click.echo(click.style("Email is required.", fg="red"))
return
# Create account
email = email.strip()
if"@"notin email:
click.echo(click.style("Invalid email address.", fg="red"))
return
account_name = email.split("@")[0]
if language notin languages:
language = "en-US"
# Validates name encoding for non-Latin characters.
name = name.strip().encode("utf-8").decode("utf-8") if name elseNone
# generate random password
new_password = secrets.token_urlsafe(16)
# register account
account = RegisterService.register(
email=email,
name=account_name,
password=new_password,
language=language,
create_workspace_required=False,
)
TenantService.create_owner_tenant_if_not_exist(account, name)
click.echo(
click.style(
"Account and tenant created.\nAccount: {}\nPassword: {}".format(email, new_password),
fg="green",
)
)
1.命令定义与参数声明
使用 click 框架定义命令 create-tenant,并声明三个参数:email、name、language,均为交互式输入。
@click.command("create-tenant", help="Create account and tenant.")
@click.option("--email", prompt=True, help="Tenant account email.")
@click.option("--name", prompt=True, help="Workspace name.")
@click.option("--language", prompt=True, help="Account language, default: en-US.")
defcreate_tenant(email: str, language: Optional[str] = None, name: Optional[str] = None):
2.参数校验
检查 email 是否为空,若为空则提示并退出。
ifnot email:
click.echo(click.style("Email is required.", fg="red"))
return
3.邮箱格式校验
去除邮箱前后空格,检查是否包含 @,否则提示格式错误并退出。
email = email.strip()
if"@"notin email:
click.echo(click.style("Invalid email address.", fg="red"))
return
4.账号名生成
取邮箱 @ 前部分作为账号名。
account_name = email.split("@")[0]
5.语言校验
检查 language 是否在支持的语言列表中,否则设为默认 en-US。
if language notin languages:
language = "en-US"
6.工作区名编码校验
若 name 存在,去除空格并做 utf-8 编码解码,保证非拉丁字符兼容。
name = name.strip().encode("utf-8").decode("utf-8") if name elseNone
7.随机密码生成
生成一个随机密码,长度为 16。
new_password = secrets.token_urlsafe(16)
8.注册账号
调用 RegisterService.register 注册账号,参数包括邮箱、账号名、密码、语言等。
account = RegisterService.register(
email=email,
name=account_name,
password=new_password,
language=language,
create_workspace_required=False,
)
9.创建租户及绑定账号
调用 TenantService.create_owner_tenant_if_not_exist,为账号创建并绑定租户(工作区)。
TenantService.create_owner_tenant_if_not_exist(account, name)
create_owner_tenant_if_not_exist()函数,如下所示:
@staticmethod
defcreate_owner_tenant_if_not_exist(
account: Account, name: Optional[str] = None, is_setup: Optional[bool] = False
):
"""Check if user have a workspace or not"""
available_ta = (
db.session.query(TenantAccountJoin)
.filter_by(account_id=account.id)
.order_by(TenantAccountJoin.id.asc())
.first()
)
if available_ta:
return
"""Create owner tenant if not exist"""
ifnot FeatureService.get_system_features().is_allow_create_workspace andnot is_setup:
raise WorkSpaceNotAllowedCreateError()
if name:
tenant = TenantService.create_tenant(name=name, is_setup=is_setup)
else:
tenant = TenantService.create_tenant(name=f"{account.name}'s Workspace", is_setup=is_setup)
TenantService.create_tenant_member(tenant, account, role="owner")
account.current_tenant = tenant
db.session.commit()
tenant_was_created.send(tenant)
该方法主要用于检查某个账号是否已经加入了租户(workspace),如果没有则为其创建一个 owner 角色的租户。逻辑如下:
-
查询当前账号是否已经有租户关联(
TenantAccountJoin记录),有则直接返回。 -
如果没有租户且系统不允许创建新 workspace 且不是 setup 场景,则抛出异常。
-
根据传入的 name 参数决定租户名称,调用
create_tenant创建租户。 -
调用
create_tenant_member把账号以 owner 身份加入租户。 -
设置账号的当前租户为新建租户,并提交数据库事务。
-
发送租户创建事件(
tenant_was_created.send)。注解:只是发送事件,没有处理函数。
该方法保证了每个账号至少有一个 workspace,并且 owner 角色归属正确。
10.输出结果
命令行输出账号和密码,提示创建成功。
click.echo(
click.style(
"Account and tenant created.\nAccount: {}\nPassword: {}".format(email, new_password),
fg="green",
)
)
五.upgrade_db()函数
该代码定义了一个名为 upgrade_db 的 Click 命令,用于升级数据库。
@click.command("upgrade-db", help="Upgrade the database")
defupgrade_db():
click.echo("Preparing database migration...")
lock = redis_client.lock(name="db_upgrade_lock", timeout=60)
if lock.acquire(blocking=False):
try:
click.echo(click.style("Starting database migration.", fg="green"))
# run db migration
import flask_migrate
flask_migrate.upgrade()
click.echo(click.style("Database migration successful!", fg="green"))
except Exception:
logging.exception("Failed to execute database migration")
finally:
lock.release()
else:
click.echo("Database migration skipped")
执行流程,如下所示:
-
输出”Preparing database migration…”提示信息。
-
使用 Redis 分布式锁
db_upgrade_lock,防止多实例同时执行数据库升级。 -
如果成功获取锁,那么:
-
输出”Starting database migration.”绿色提示。
-
动态导入
flask_migrate并执行flask_migrate.upgrade(),进行数据库迁移。 -
迁移成功后输出”Database migration successful!”绿色提示。
-
如果迁移过程中发生异常,记录异常日志。
-
最后无论成功与否都释放锁。
-
如果未获取到锁,则输出”Database migration skipped”。
这样可以保证数据库升级操作不会被多次并发执行,提升安全性。
注解:
lock.acquire(blocking=False)表示 非阻塞 地尝试获取锁。如果锁已被其它进程持有,则立即返回False,不会等待。
参考文献
[0] commands.py中的函数解析2:convert_to_agent_apps等:https://z0yrmerhgi8.feishu.cn/wiki/HvLiwZkh7iAztGkigyCcwJRZnqh
[1] qdrant-client github:https://github.com/qdrant/qdrant-client
[2] qdrant官方文档:https://qdrant.tech/documentation/
[3] qdrant-client pypi:https://pypi.org/project/qdrant-client/0.1.0/
[4] qdrant github:https://github.com/qdrant/qdrant
[5] qdrant cloud:https://cloud.qdrant.io/
[6] Blinker官方文档:https://blinker.readthedocs.io/en/stable/
[7] blinker github:https://github.com/pallets-eco/blinker/
[8] Flask-Migrate github:https://github.com/miguelgrinberg/Flask-Migrate
[9] Flask-Migrate官方文档:https://flask-migrate.readthedocs.io/en/latest/
知识星球服务内容:Dify源码剖析及答疑,Dify对话系统源码,NLP电子书籍报告下载,公众号所有付费资料。加微信buxingtianxia21进NLP工程化资料群。
(文:NLP工程化)