
在数字化时代,海量的文档资料(PDF、图片、扫描件等)如何高效处理与利用,是企业和开发者面临的共同挑战。
作为一名专注分享全球开源项目与实用工具的开发者,我一直在寻找那些能够真正解决开发者痛点的OCR文档解析利器。
最近也是发现了一款国产的强大文档解析产品:Doc2X。它以高精度、高性价比和强大的API功能,迅速进入到大家的视野。
Doc2X 是一款基于先进AI技术的高精度文档解析工具,专为开发者打造,旨在解决PDF、图片等非结构化文档的解析、转换和翻译难题。
它支持将复杂文档精准转换为Markdown、LaTeX、HTML、Word等多种结构化或半结构化格式,同时提供强大的公式识别、表格解析、图片内容提取和多语言翻译功能。
通过开放的API接口,Doc2X能够无缝集成到各种知识库系统、在线教育平台和企业工作流中,目前已成功接入FastGPT、CherryStudio、字节扣子等知名知识库和AI应用构建平台。
可以助力开发者快速构建高效、智能的应用。
核心亮点一览
1、高精度解析
Doc2X在复杂文档(如学术论文、财报、教辅资料)中表现出色,尤其擅长处理包含数学公式、跨页表格和多栏排版的文档,识别准确率远超传统OCR工具和部分开源方案。

2、公式识别能力领先
针对理工科文档、学术论文及教育试题等富含数学公式的场景,Doc2X进行了深度的优化。
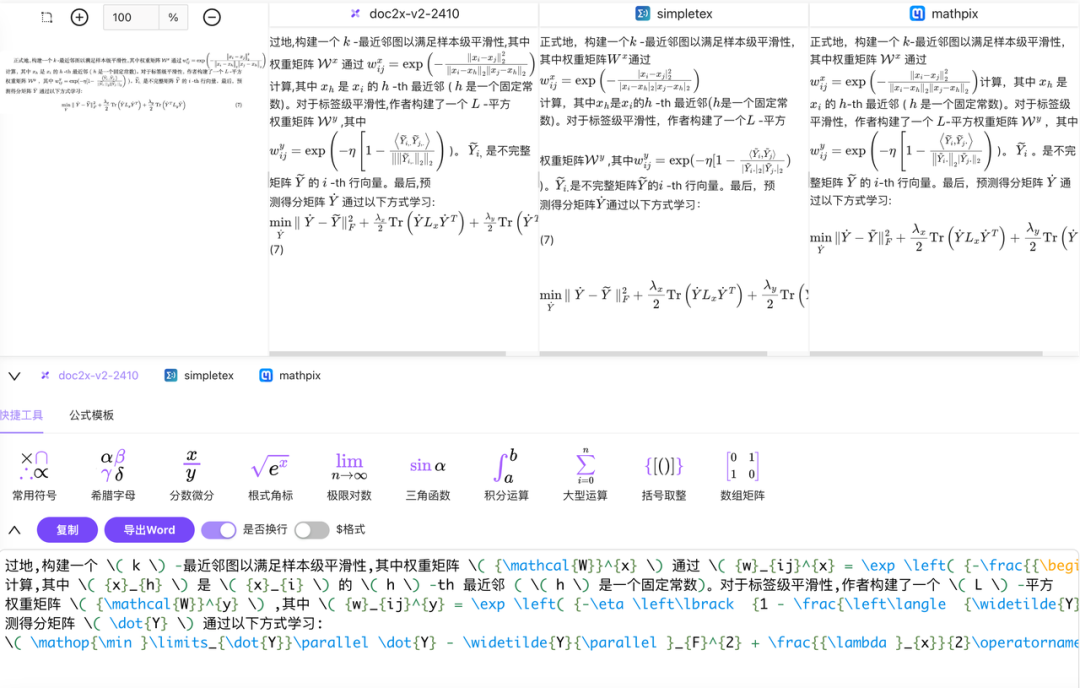
支持印刷体和部分手写体公式的高精度识别,并且提供结构化转换,(比如LaTeX格式),完美适配MathJax渲染和Word公式编辑。
超越了部分开源方案,不论是基于文档还是图片,都不会出现一些OCR工具中的乱码现象,维持用户阅读观感。
3、超全的格式转换
可以轻松将PDF转换为Word、HTML、LaTeX、Markdown等主流文档格式。
还能够确保转换前后的一致性,与原PDF进行对照跳转编辑。
4、多大模型翻译引擎整合,支持双语对照及保留排版
多种AI引擎加持:支持GPT、Deepseek、GLM、Qwen、Yi-Lightning等模型,提供精确翻译。
并且提供双语对照的沉浸式翻译体验,支持双向跳转,快速理解。
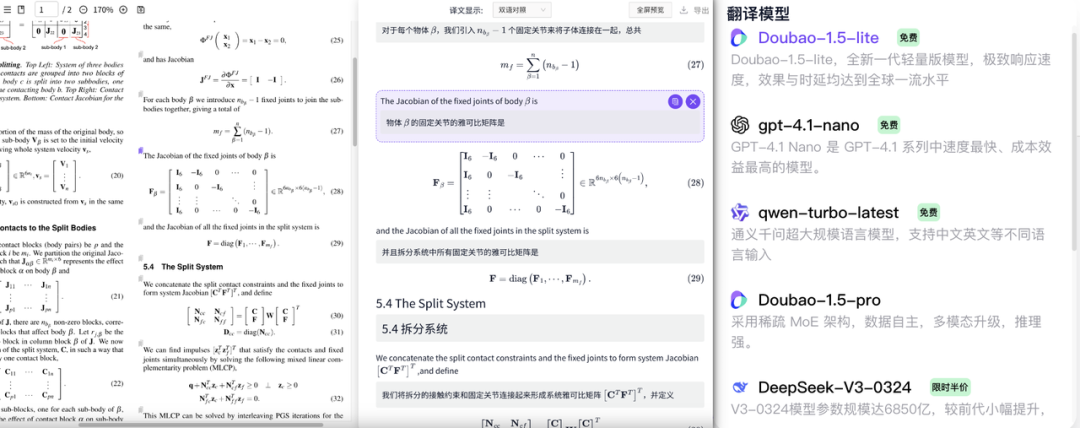
当然,除此之外还支持一个非常实用且友好的功能:完美保留原文的版式和布局,包括公式、表格、图示等。 保证翻译文本与原文相对位置是一致的,让你的翻译文档更易阅读和再编辑。

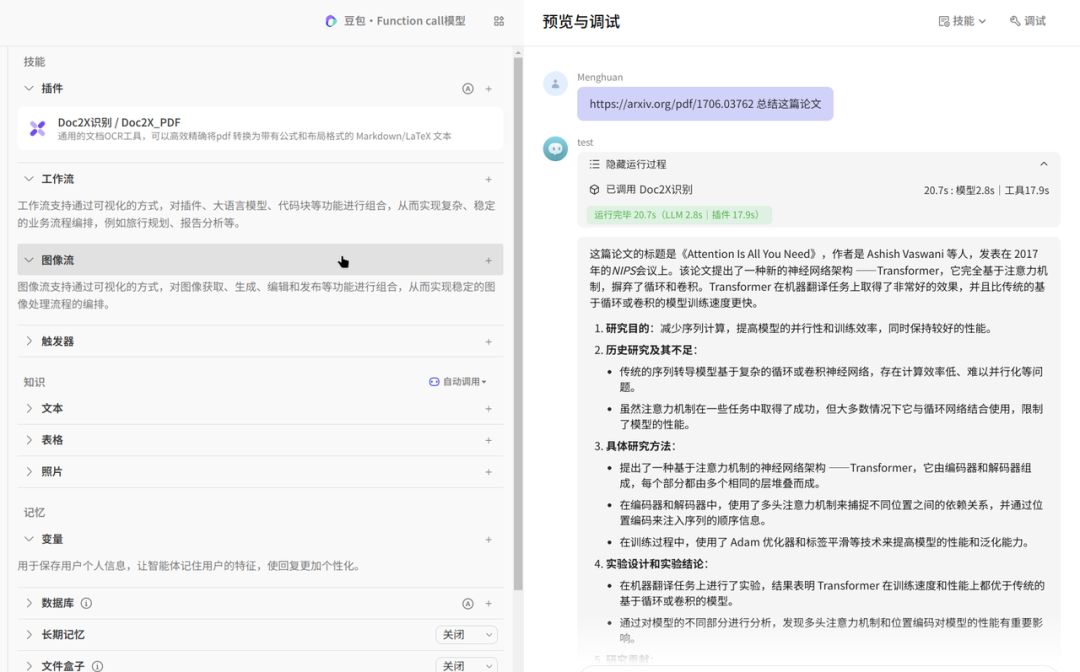
5、支持文档AI对话
基于文档上下文进行AI对话,可快速定位并理解全文关键信息, 支持多轮深度问答、智能总结。
多种大模型可选:DeepSeek v3、GLM4 Plus等,提供原文跳转,免去繁琐翻阅,让你的工作效率倍增。

6、高性价比与灵活API
提供清晰易用的API接口,支持批量处理,性价比极高,以更低的成本提供高质量解析服务,适合个人开发者到大型企业的各种规模及预算需求。
Doc2X线上已累计处理数亿页+文档,日吞吐量千万页+。
同时可以轻松对接到 FastGPT、CherryStudio、扣子(国内版) 等知名知识库和AI应用构建平台。
快速使用(含实测及API教程)
在线体验实测
若要快速体验Doc2X强大的文档解析能力,建议直接打开Doc2X官网,可以直接体验到PDF翻译、图片识别、文档格式转换、文档AI对话等功能。
Doc2X地址:https://doc2x.noedgeai.com
现在注册即赠40页PDF解析额度,40张图片识别额度。每天还可以签到,每月可领总计200页PDF与100张图片额度,对于日常使用也很是不错了。
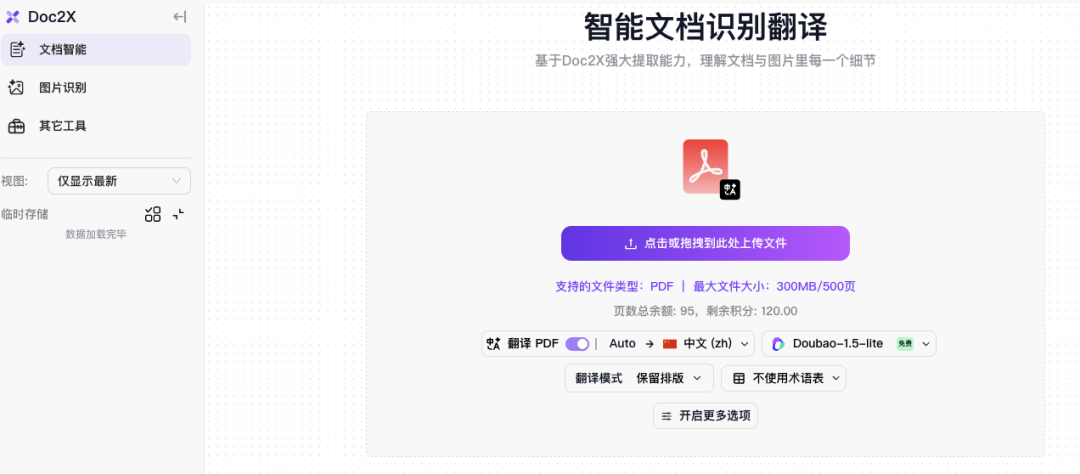
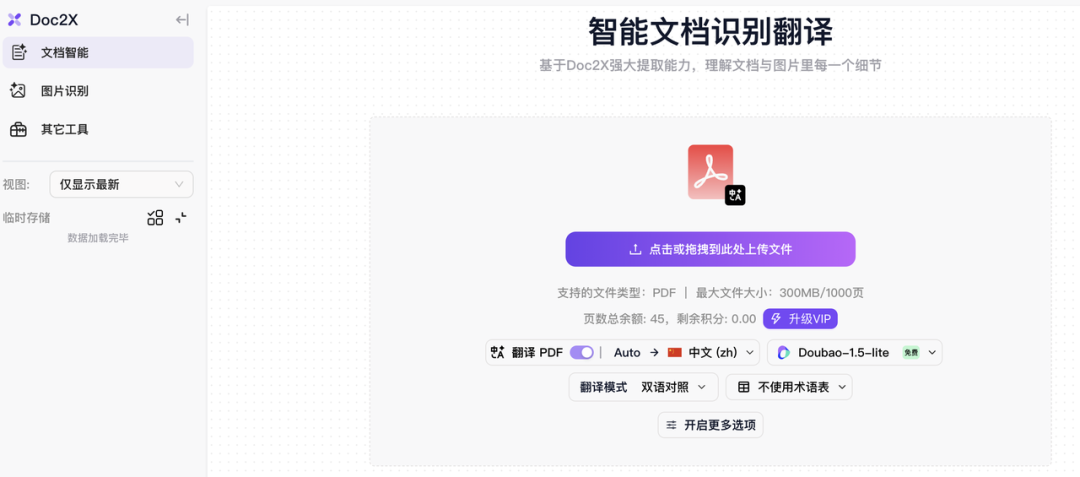
如果想要进行PDF翻译的话,可通过本地文件上传、拖拽的方式导入PDF文档。
在上传文件前,设置好目标语言、翻译大模型(豆包、DeepSeek等),大模型会自动对文本、表格、公式进行识别和翻译。
上传的时候也支持可选参数的调节,如果你的文档页数过多也可以设置页码范围,还有翻译模式(保留排版或对照翻译),也相当的人性化。
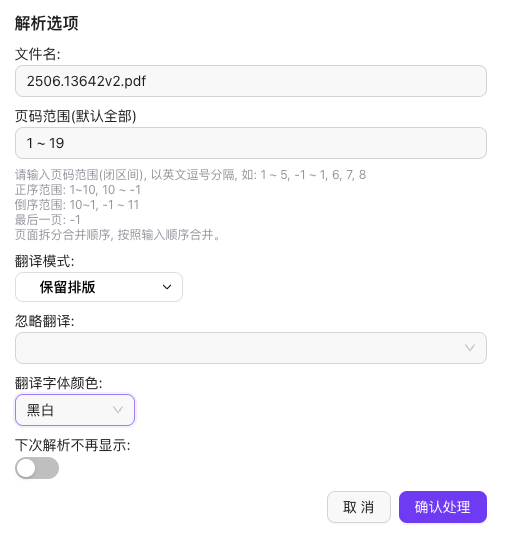
等待一会,经过文档上传-解析-翻译等流程,输出最终效果。

通过点击右上角「AI」气泡图标,可以直接与文档进行AI对话,了解你不清楚的地方,特别适合大文档场景下的关键信息获取及定位。
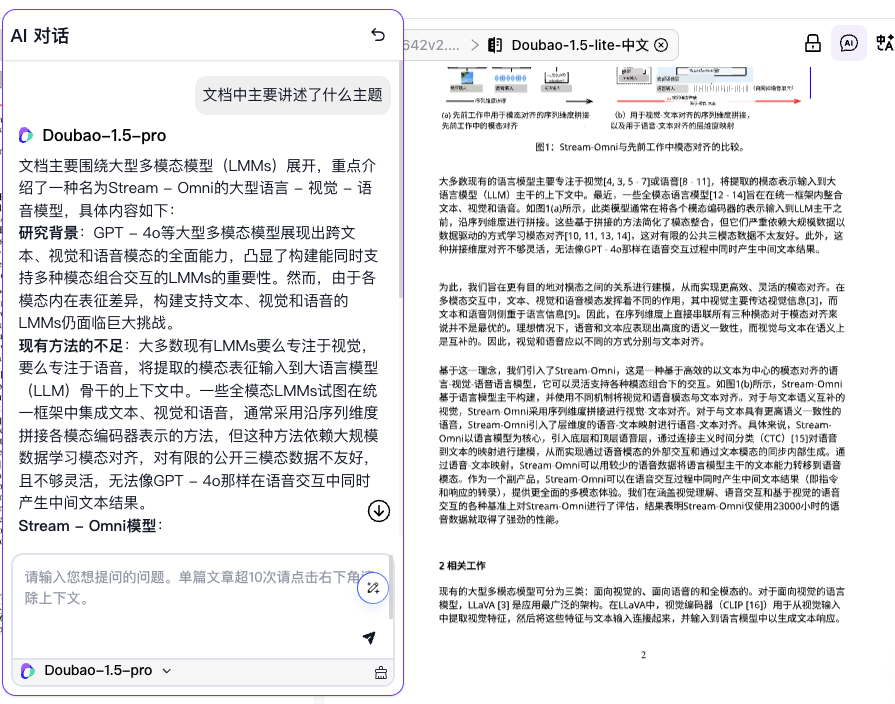
其他效果DEMO演示如下:

(来源于官网示例)

(来源于官网PDF保留排版示例)

(手写公式转化)

(公式智能补全)
API使用(仅支持解析功能)
对于企业或高频翻译场景,可使用API集成功能。将PDF翻译流程嵌入你的应用中,进行批量处理,轻松实现大规模自动化翻译,提高工作效率与协作便利度。
1、获取API Key
要想使用Doc2X的API服务,需要先在Doc2X的开放平台中,创建一个API-KEY,供接口调用鉴权。(小编这里先充值了10元500页的额度,以供测试使用。)
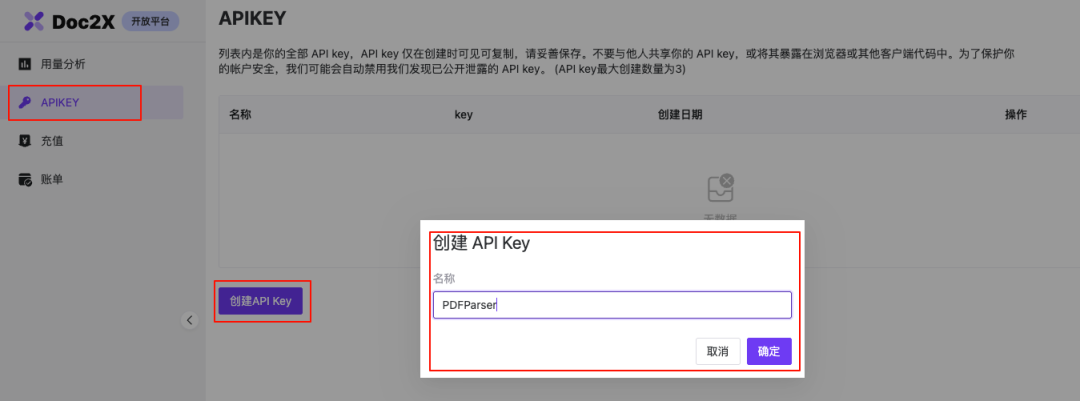
Doc2X开放平台地址:https://open.noedgeai.com
创建完成后,保存好自己生成的API-Key。
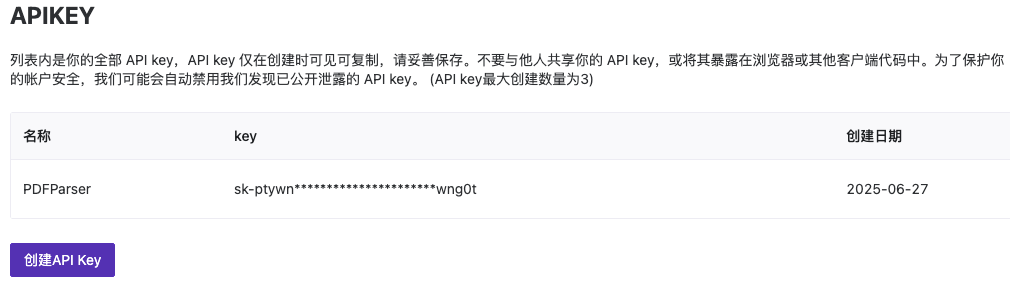
使用方式就是在HTTP请求头里加入以下格式即可。
Authorization: Bearer sk-xxxDoc2x API v2 PDF 接口文档:https://noedgeai.feishu.cn/wiki/Q8QIw3PT7i4QghkhPoecsmSCnG1
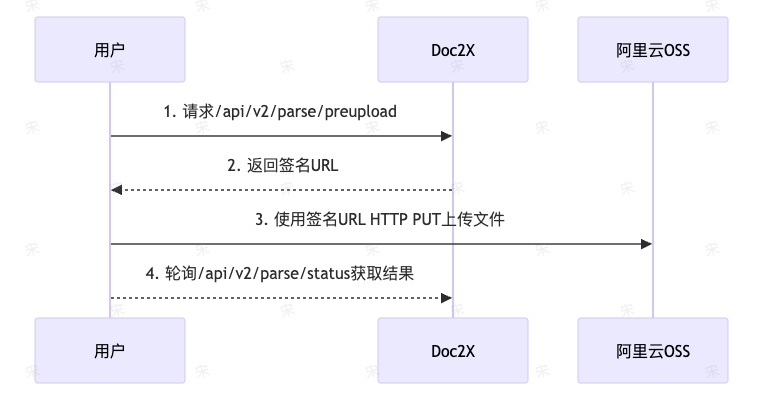
2、文件上传/解析
在文件上传接口的使用上,我们采用最新 preupload 文件预上传,具备更快的上传速度,而且支持最大1GB的文档。
接口(POST):https://v2.doc2x.noedgeai.com/api/v2/parse/preupload
响应示例:
{
"code": "success",
"data": {
"uid": "0192d745-5776-7261-abbd-814df3af3449",
"url": "https://doc2x-pdf.oss-cn-beijing.aliyuncs.com/tmp/0192d745-5776-7261-abbd-814df3af3449.pdf?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=LTAI5tS7hV6uXXVzcpk3EGfX%2F20241029%2Fcn-beijing%2Fs3%2Faws4_request&X-Amz-Date=20241029T075458Z&X-Amz-Expires=600&X-Amz-SignedHeaders=host&X-Amz-Signature=f731ea8fe4efdd7c727c210034bdcf1a63436c74b295db68f9648efdce576a91"
}
}获取到url之后,使用HTTP PUT方法上传文件到返回结果中的url字段,然后使用/api/v2/parse/status 接口轮询结果。
详细封装一体化代码:
import json
import time
import requests as rq
classDoc2xParser:
def__init__(self, secret, base_url="https://v2.doc2x.noedgeai.com"):
"""
初始化解析器
:param secret: API密钥 (格式: "sk-xxx")
:param base_url: API基础URL (默认官方地址)
"""
self.base_url = base_url
self.secret = secret
self.headers = {"Authorization": f"Bearer {secret}"}
def_preupload(self):
"""获取预上传URL和文档UID"""
url = f"{self.base_url}/api/v2/parse/preupload"
res = rq.post(url, headers=self.headers)
if res.status_code != 200:
raise Exception(f"Preupload failed: HTTP {res.status_code}, {res.text}")
data = res.json()
if data.get("code") != "success":
raise Exception(f"Preupload failed: {data}")
return data["data"]
def_upload_file(self, file_path, upload_url):
"""上传文件到预签名URL"""
withopen(file_path, "rb") as f:
res = rq.put(upload_url, data=f)
if res.status_code != 200:
raise Exception(f"Upload failed: HTTP {res.status_code}, {res.text}")
def_get_status(self, uid):
"""获取文档解析状态"""
url = f"{self.base_url}/api/v2/parse/status?uid={uid}"
res = rq.get(url, headers=self.headers)
if res.status_code != 200:
raise Exception(f"Status check failed: HTTP {res.status_code}, {res.text}")
data = res.json()
if data.get("code") != "success":
raise Exception(f"Status check failed: {data}")
return data["data"]
defparse_document(self, file_path, poll_interval=3, max_retries=100):
"""
解析PDF文档并返回结果
:param file_path: PDF文件路径
:param poll_interval: 轮询间隔(秒)
:param max_retries: 最大轮询次数
:return: 解析结果字典
"""
# 获取上传凭证
upload_data = self._preupload()
upload_url = upload_data["url"]
uid = upload_data["uid"]
# 上传文件
self._upload_file(file_path, upload_url)
print(f"File uploaded successfully. Document UID: {uid}")
# 轮询解析结果
retries = 0
while retries < max_retries:
status_data = self._get_status(uid)
status = status_data["status"]
if status == "success":
return status_data["result"]
elif status == "failed":
detail = status_data.get("detail", "Unknown error")
raise Exception(f"Parsing failed: {detail}")
elif status == "processing":
progress = status_data.get("progress", 0)
print(f"Processing... Progress: {progress}%")
time.sleep(poll_interval)
retries += 1
raise TimeoutError(f"Parsing timed out after {max_retries * poll_interval} seconds")
# 使用示例
if __name__ == "__main__":
# 初始化解析器
parser = Doc2xParser(secret="sk-xxx")
try:
# 解析PDF文档
result = parser.parse_document("test.pdf")
# 保存解析结果
withopen("result.json", "w") as f:
json.dump(result, f, indent=2)
print("Result saved to result.json")
# 直接使用结果数据
print(f"Document title: {result.get('title', 'N/A')}")
print(f"Total pages: {len(result.get('pages', []))}")
except Exception as e:
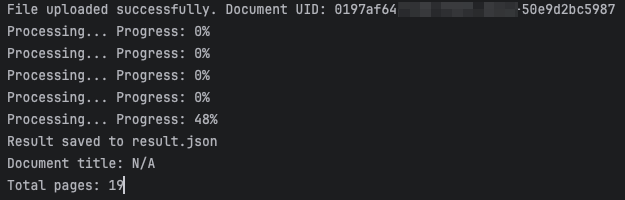
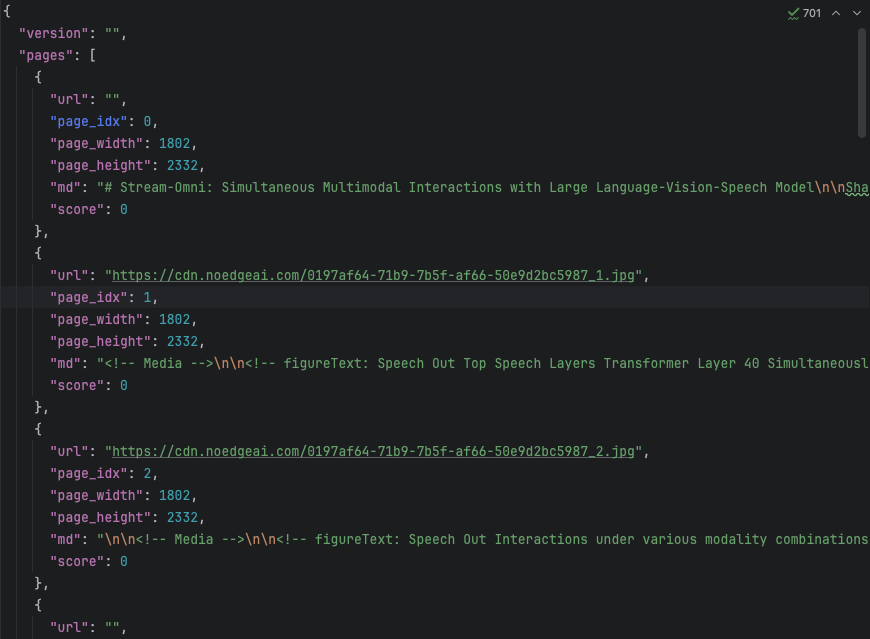
print(f"Error occurred: {str(e)}")通过上传了一个19页PDF文档进行了测试。
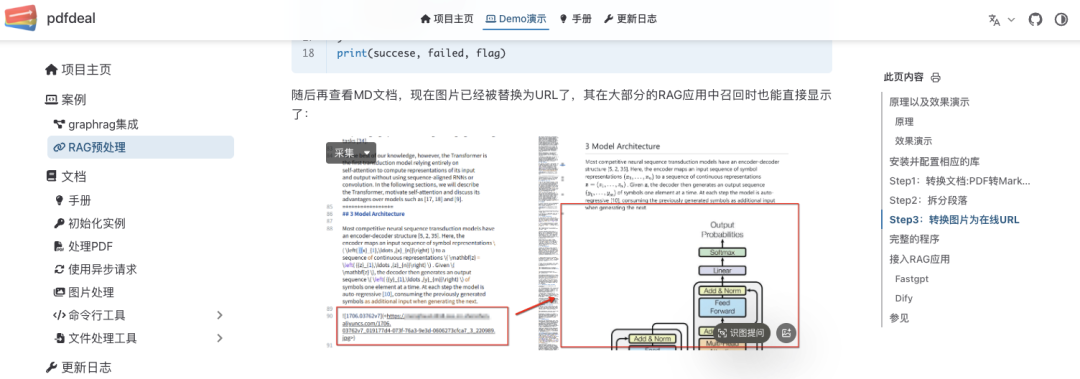
如果想更加便捷的使用Doc2X接口,也有现成封装好的Python包,比如:pdfdeal、doc2x-doc,pdfdeal可直接通过pip命令安装到本地。
相关源码地址:
PdfDeal:https://github.com/NoEdgeAI/pdfdeal-docs
doc2x-doc:https://github.com/NoEdgeAI/doc2x-doc
接入扣子(Coze国内版)工作流
目前Doc2X也上架了扣子平台,可做成插件或工作流发布为实用工具,快速使用其功能。
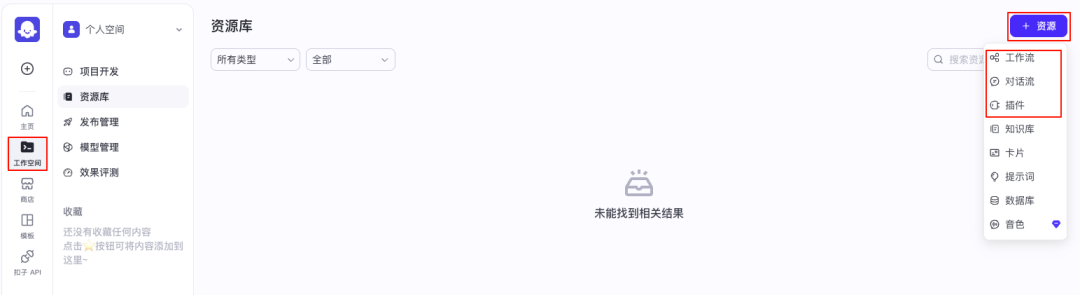
打开扣子空间(coze.cn),点击“资源”,创建工作流或插件。
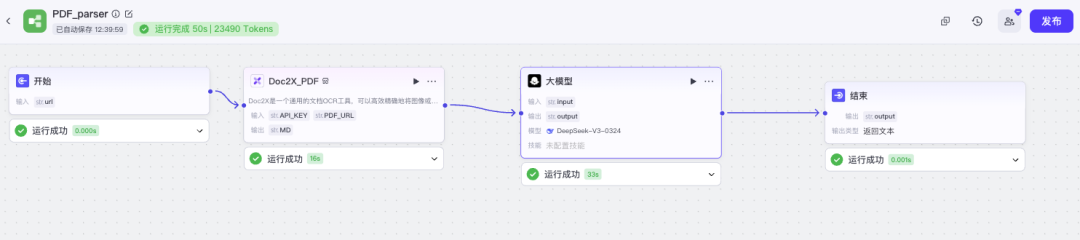
然后命名一个工作流名称(仅支持英文下划线),填写描述,添加【Doc2x识别】节点、【大模型】节点,将其连线。输入输出变量都对应好,API-Key可以直接固定。
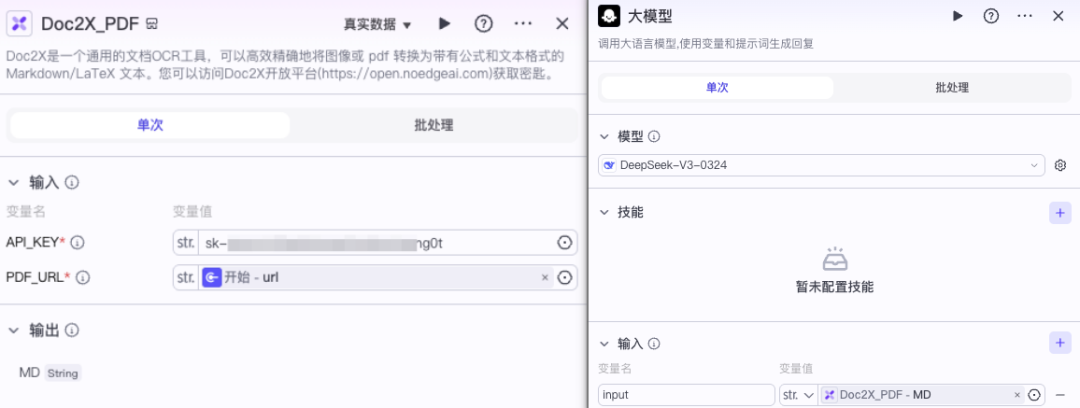
然后通过URL方式输入一个论文PDF,进行解析并通过大模型进行总结输出。
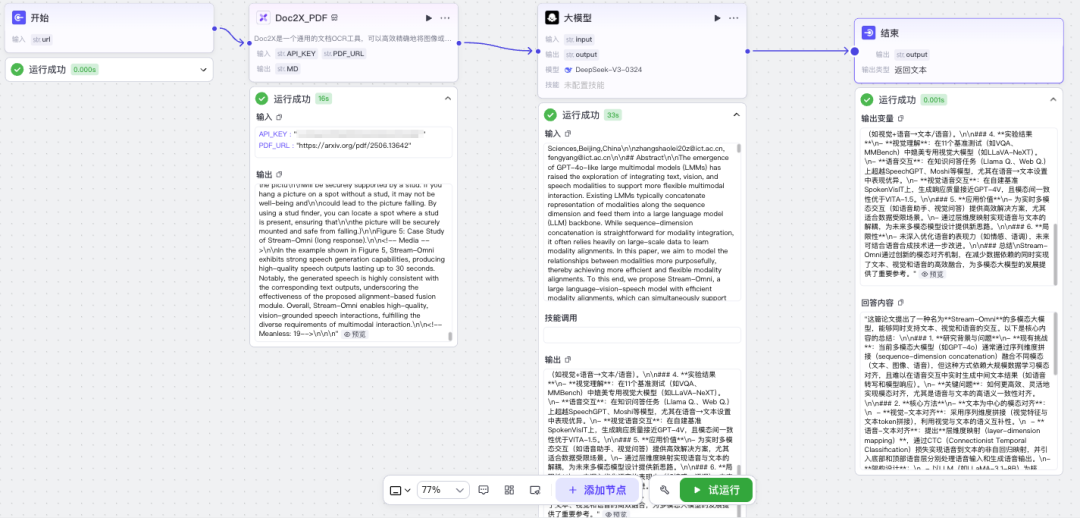
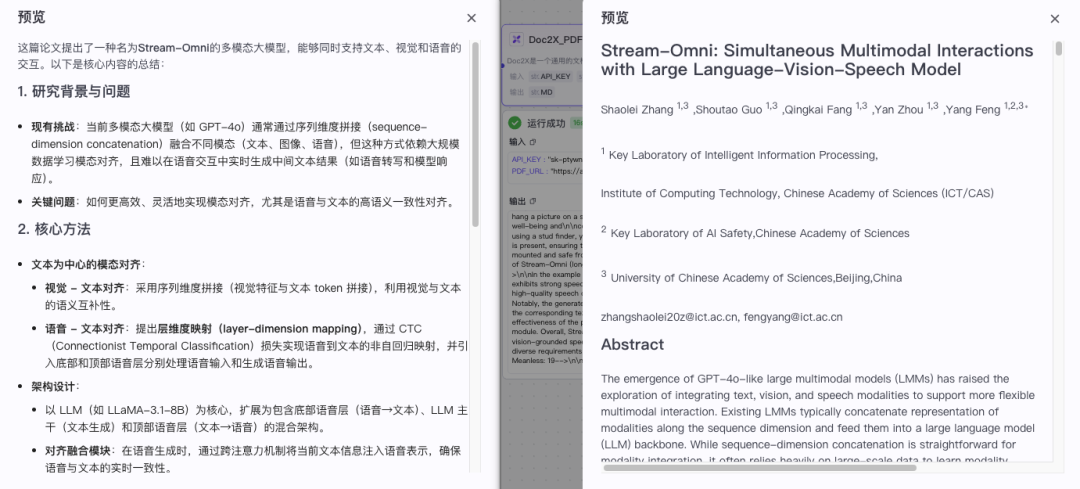
后续也可以将其做成一个扣子智能体进行发布,在对话窗口下实时进行交互处理。
Doc2X的优势
综合实测体验和功能分析,Doc2X在以下方面展现了无可比拟的优势:
-
• 高精度解析:尤其在公式、表格和复杂排版处理上,领先于传统OCR工具和部分开源方案。 -
• 开发者友好:提供清晰的API文档和灵活的集成方式,支持FastGPT、CherryStudio等主流平台。 -
• 高性价比:相比其他商业化工具,Doc2X以更低的价格提供更优质的服务,适合从个人开发者到大型企业的各种需求。 -
• 多场景适配:覆盖知识库建设、教育科技、学术研究、企业数据分析等多个领域。
写在最后
Doc2X 以其高精度、快速度和低成本,成为开发者在知识库搭建和教育科技领域的得力助手。
无论是企业希望打造智能知识管理体系,还是教育机构追求试题数字化的革新,Doc2X都能提供强有力的支持。
推荐人群:
-
• 企业开发者:需要批量处理文档、构建知识库或优化问答系统。 -
• 教育科技从业者:从事题库建设、试卷数字化或在线教育平台开发。 -
• 个人开发者:希望以低成本集成高精度文档解析功能。
总的来说,Doc2X效果还是不错的。不管你是通过在线体验使用它的文档翻译和图片识别,还是通过API调用解析文档都不错,最后为这款国产神器点个赞!

● 一款改变你视频下载体验的神器:MediaGo
● 字节把 Coze 核心开源了!可视化工作流引擎 FlowGram 上线,AI 赋能可视化流程!
● 英伟达开源语音识别模型!0.6B 参数登顶 ASR 榜单,1 秒转录 60 分钟音频!
● 开发者的文档收割机来了!这个开源工具让你一小时干完一周的活!
● PDF文档解剖术!OCR神器+1,这个开源工具把复杂排版秒变结构化数据!

(文:开源星探)