

📢本周AI快讯 | 1分钟速览🚀
1️⃣ ⚠️ DeepSeek-R2 发布推迟 :原计划 5 月发布的 DeepSeek-R2 因美国对英伟达 H20 芯片出口限制和 CEO 对性能不满而推迟。
2️⃣ 🎯 阿里发布多模态模型 :通义千问推出视觉模型 Qwen VLo,支持图像、文本、音频和视频输入,已在多平台开源。
3️⃣ 👓 小米 AI 眼镜上市 :售价 1999 元起,搭载高通 Snapdragon AR1 芯片,支持语音交互、拍摄和扫码支付。
4️⃣ 🏥 蚂蚁推出 AI 健康应用 AQ :基于自研医疗大模型,接入 5000+ 医院、百万医生资源,提供一站式健康服务。
5️⃣ 🔬 OpenAI 开放深度研究 API :o3-deep-research 和 o4-mini-deep-research 模型通过 API 向开发者开放,支持多模态任务。
6️⃣ 💡 OpenAI 首用谷歌 TPU :摆脱对英伟达 GPU 单一依赖,租用谷歌 TPU 训练 ChatGPT,标志基础设施战略重大转变。
7️⃣ 📱 谷歌发布轻量级模型 :Gemma 3n 可在 2GB 内存设备运行,支持 140 种语言文本输入,适合资源受限场景。
8️⃣ 🎨 谷歌推出 Imagen 4 :文生图模型 Imagen 4 及 Ultra 版本发布,支持 2K 分辨率,内置 SynthID 数字水印技术。
9️⃣ ⌨️ Gemini CLI 免费开放 :谷歌开源终端工具,集成 Gemini 2.5 Pro,每日最多 1000 次请求,支持代码生成和调试。
🔟 🛠️ Claude 推出无代码开发 :新功能允许用户在聊天界面创建 AI 应用,支持所有订阅层级用户,实现“所见即所得”开发。
1️⃣1️⃣ 🧠 Claude 即将引入记忆功能 :代码显示正在开发记忆功能,可记住用户偏好和历史对话,预计 Q3 向付费用户推出。
1️⃣2️⃣ 🏪 Claude 自主运营实验失败 :Claude 3.7 Sonnet 管理办公室小店一个月净亏损 20%,过度顺从和出现幻觉现象。
1️⃣3️⃣ 🚀 马斯克宣布 Grok 4 :xAI 将于 7 月 4 日后发布 Grok 4,具备高级推理能力,目标“重写整个人类知识体系”。
01|DeepSeek-R2 模型发布推迟,英伟达 H20 芯片成瓶颈
DeepSeek 原计划于 2025 年 5 月发布其下一代推理模型 DeepSeek-R2,但目前该项目已推迟发布。据多方报道,延迟的主要原因有二:一是公司 CEO 梁文锋对当前模型性能表示不满,二是美国对英伟达 H20 芯片的出口限制导致中国市场供应短缺,严重影响了模型的训练与部署进程。

DeepSeek-R2 是继 R1 之后的升级版本,旨在提升代码生成能力并支持多语言推理。然而,由于美国政府于 2025 年 4 月收紧对英伟达 H20 芯片的出口限制,这款专为中国市场设计的 AI 加速器在中国大陆的供应变得极为紧张。DeepSeek 的许多云服务客户仍依赖 H20 芯片运行 R1 模型,预计 R2 的发布将进一步加剧对高性能算力的需求,给本已紧张的云计算基础设施带来更大压力。
尽管面临挑战,DeepSeek 仍在与中国的云服务提供商合作,分享技术规格,以便为未来的 R2 部署做好准备。此次事件凸显了地缘政治紧张局势下,技术出口限制对全球 AI 产业链的深远影响。
02|阿里通义千问发布多模态模型 Qwen VLo
6 月 27 日,阿里通义千问团队正式推出多模态模型 Qwen VLo,标志着其在视觉语言模型(VLM)领域的又一重要进展。该模型基于 Qwen2.5 系列,融合了图像、文本、音频和视频等多模态输入,旨在实现从感知到生成的统一处理。用户可通过 Qwen Chat 平台(chat.qwen.ai)体验该模型的多模态能力。

Qwen VLo 展现出强大的跨模态理解与生成能力,能够处理复杂的图文混合任务,如图像描述、视觉问答、文档解析等。其视觉编码器采用动态分辨率的 Vision Transformer(ViT),并引入多模态旋转位置编码(M-RoPE),提升了模型对不同模态数据的感知能力。此外,Qwen VLo 在长视频理解、结构化数据提取和多语言支持方面也表现出色,适用于金融、法律、教育等多个行业场景。
目前,Qwen VLo 已在 ModelScope、Hugging Face 等平台开源,支持多种模型尺寸,方便开发者和企业根据自身需求进行部署和微调。
03|小米首款 AI 眼镜发布:1999 元起,支持拍摄与扫码支付
6 月 26 日,小米在其“人车家全生态发布会”上正式发布了首款 AI 眼镜,售价 1999 元起,现已在小米商城等平台开售。这款眼镜被定位为“面向下一代的个人智能设备”,集成了 AI 助手“小爱同学”,支持语音交互、第一人称拍摄、扫码支付等多项功能,旨在为用户提供便捷的智能生活体验。
在硬件配置方面,小米 AI 眼镜搭载了高通 Snapdragon AR1 芯片,配备 4GB RAM 和 32GB 存储空间,支持 Wi-Fi 6 和蓝牙 5.4 连接。其内置的 1200 万像素摄像头可实现 2K 视频录制,并具备图像稳定功能。此外,眼镜还集成了开放式扬声器和五个麦克风,支持语音通话和音乐播放。

在功能方面,用户可以通过语音命令与“小爱同学”互动,实现物体识别、实时翻译、健康建议等功能。此外,眼镜还支持扫码支付,用户只需看一眼二维码即可完成支付操作。
04|蚂蚁集团发布 AI 健康应用 AQ
6 月 26 日,蚂蚁集团正式推出 AI 健康应用 AQ,旨在通过人工智能技术,提供从健康咨询到就医服务的一站式解决方案。该应用基于蚂蚁自研的医疗大模型,集成了健康科普、就诊咨询、报告解读、健康档案管理等百余项功能,致力于满足公众在健康管理方面的多样化需求。
AQ 支持多模态交互,用户可以通过文字、语音或拍照等方式,与 AI 进行互动。例如,用户在描述症状时,AQ 会模拟医生的问诊流程,逐步引导用户提供必要信息,最终给出个性化的健康建议。此外,AQ 还具备图像识别能力,能够识别皮肤病变、解读体检报告、药品说明等,提升了用户的使用便捷性。
在医疗资源连接方面,AQ 已接入全国超过 5000 家医院、近百万名医生资源,并上线了近 200 位三甲名医的 AI 分身,提供 7×24 小时的在线问诊服务。同时,AQ 还与华为、vivo、苹果等可穿戴设备打通,结合用户的血糖、睡眠、运动等数据,生成个性化的健康建议。
05|OpenAI 推出 o3-deep-research 与 o4-mini-deep-research 模型 API
6 月 26 日,OpenAI 宣布旗下两款深度研究模型 o3-deep-research 与 o4-mini-deep-research 正式通过 API 向开发者开放。这两款模型此前已集成于 ChatGPT 的 Deep Research 功能中,现可通过 API 接入,支持自动化网页搜索、数据分析、Python 执行、图像识别等多模态任务,适用于构建智能研究代理、知识工作流与复杂决策系统。
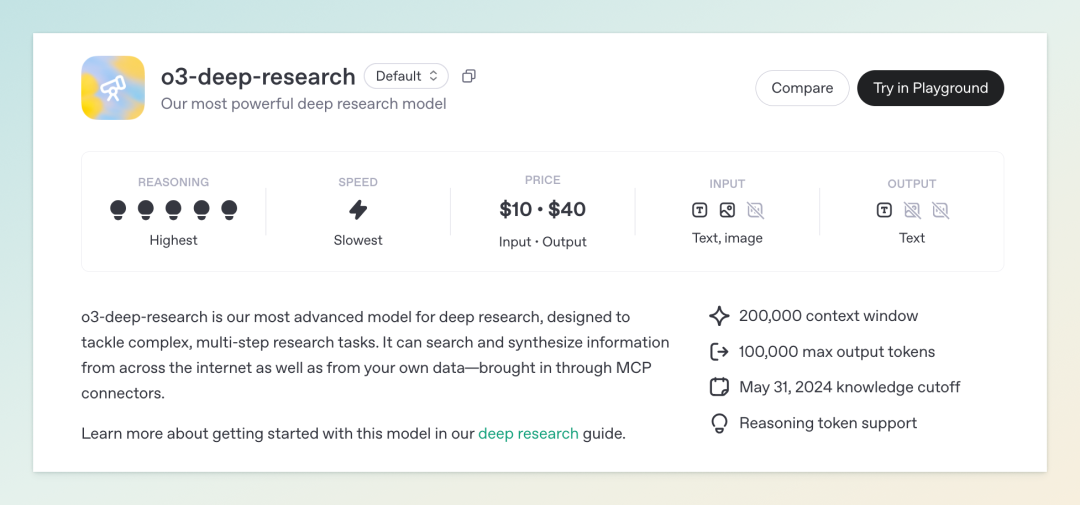
o3-deep-research 是 OpenAI 推理能力最强的模型之一,具备 200K token 的上下文窗口,擅长处理复杂的跨模态任务,如图像与文本的联合推理、代码生成与分析等。其在学术基准测试中表现优异,尤其在数学、科学与工程领域。而 o4-mini-deep-research 则是其轻量化版本,响应速度更快,成本更低,适合对实时性和资源效率有较高要求的应用场景。
在 API 使用方面,o3-deep-research 的定价为每百万输入 token 10 美元,输出 token 40 美元;o4-mini-deep-research 则为每百万输入 token 2 美元,输出 token 8 美元。此外,OpenAI 还引入了 Webhooks 功能,支持异步任务通知,提升长时间运行任务(如深度研究)的可靠性与效率。开发者可通过 OpenAI 的 Agents SDK 快速集成这些模型,构建具备自主推理与工具调用能力的智能代理。
06|OpenAI 首次采用谷歌 TPU 训练 ChatGPT
OpenAI 正在逐步摆脱对英伟达 GPU 的单一依赖。据路透社 6 月 28 日报道,该公司已开始租用谷歌的 Tensor Processing Units(TPUs)来支持 ChatGPT 和其他 AI 产品的训练与推理任务,这是 OpenAI 首次在大规模应用中采用非英伟达芯片。此举标志着 OpenAI 在基础设施战略上的重大转变,旨在降低成本、提升算力弹性,并缓解对微软 Azure 的过度依赖。

虽然谷歌并未向 OpenAI 提供其最先进的 TPU 芯片,但此次合作仍具有重要意义。OpenAI 此前几乎完全依赖英伟达 GPU 进行模型训练和推理,而高昂的成本和供应紧张促使其寻求替代方案。通过租用谷歌 Cloud TPU,OpenAI 不仅可以降低推理成本,还能在全球范围内扩展其 AI 服务能力。
此次合作也凸显了 AI 行业中“竞合”关系的加剧。尽管 OpenAI 的 ChatGPT 与谷歌的 Gemini 在生成式 AI 领域直接竞争,但双方仍在基础设施层面展开合作。这反映出当前 AI 模型对算力的巨大需求,迫使竞争对手在关键资源上寻求合作。对于谷歌而言,吸引 OpenAI 成为客户有助于推动其 TPU 商业化进程,并增强 Google Cloud 在 AI 基础设施市场的竞争力。
07|谷歌发布轻量级多模态模型 Gemma 3n:2GB 内存即可本地运行 AI
6 月 26 日,谷歌正式发布了多模态轻量级模型 Gemma 3n,该模型专为资源受限设备设计,可在仅有 2GB 内存的手机、平板和笔记本电脑上本地运行,支持文本、图像、音频和视频等多种输入类型。这是继 5 月份 Google I/O 大会预览后,Gemma 3n 的正式上线。
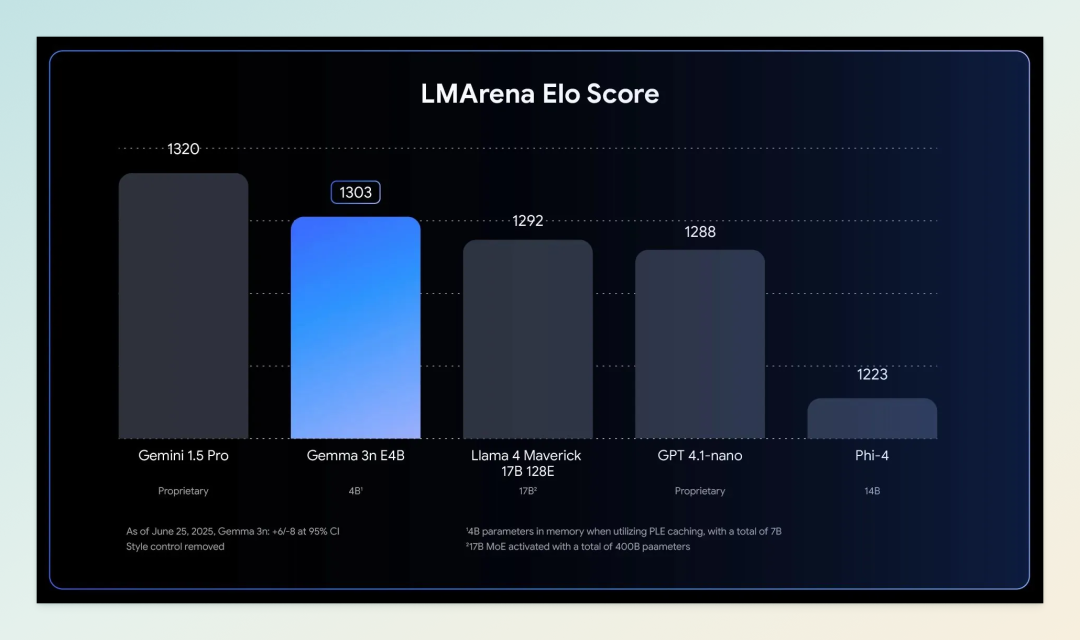
Gemma 3n 采用了创新的 MatFormer(Matryoshka Transformer)架构和 Per-Layer Embedding(PLE)参数缓存技术,使得尽管模型原始参数量为 5B 和 8B,但其有效内存占用仅相当于 2B 和 4B 模型,最低可在 2GB 内存设备上流畅运行。此外,模型支持条件参数加载,可根据任务需求动态加载视觉和音频模块,进一步降低资源消耗。
在多模态处理方面,Gemma 3n 能够处理图像、音频、视频和文本输入,输出为文本形式。其多语言支持能力也得到了增强,支持 140 种语言的文本输入和 35 种语言的多模态输入,尤其在日语、德语、韩语、西班牙语和法语等语言上表现出色。开发者可通过 Google AI Studio 或 Google AI Edge 平台使用该模型,并可在 Hugging Face 和 Kaggle 上获取模型权重进行本地部署。
08|谷歌发布 AI 文生图模型 Imagen 4 / Ultra
6 月 24 日,谷歌正式推出其最新一代文本生成图像模型 Imagen 4 及其高精度版本 Imagen 4 Ultra,现已通过 Gemini API 和 Google AI Studio 提供付费预览,并在 AI Studio 提供限时免费试用。标准版 Imagen 4 每张图像定价为 0.04 美元,而 Ultra 版本则为 0.06 美元,主打更强的指令遵循能力和图像细节表现。

与前代相比,Imagen 4 在图像质量、文本渲染和生成速度方面均有显著提升。其支持生成最高 2K 分辨率的图像,具备更强的细节还原能力,尤其在处理复杂纹理、光影效果和多语言提示词方面表现出色。此外,模型内置了 SynthID 数字水印技术,确保所有生成图像均可追溯,增强了内容的透明度与可信度。
Imagen 4 Ultra 版本进一步强化了对复杂提示词的理解和执行能力,适用于对图像质量和精度要求更高的专业场景,如广告创意、品牌设计等。目前,开发者和创作者可通过 Google AI Studio 免费试用这两款模型,或通过 Gemini API 进行付费接入。
09|谷歌推出免费 AI 终端工具 Gemini CLI
6 月 25 日,谷歌正式发布开源工具 Gemini CLI,将其先进的 AI 模型 Gemini 2.5 Pro 引入命令行界面,旨在为开发者提供更高效的工作流程。该工具支持 Windows、macOS 和 Linux 平台,用户只需通过个人 Google 账户登录,即可免费使用,每分钟最多 60 次请求,每日最多 1000 次请求,远高于行业平均水平。
Gemini CLI 具备强大的自然语言处理能力,支持代码生成、调试、文件操作、任务管理等多种功能。其集成了谷歌的 Model Context Protocol(MCP),可实时访问 Google Search 获取最新信息,并支持与 Imagen 和 Veo 等工具协同工作,实现图像和视频的生成。
作为开源项目,Gemini CLI 采用 Apache 2.0 许可证,开发者可自由查看、修改和扩展其功能。该工具还与 Gemini Code Assist 深度集成,支持在 VS Code 等集成开发环境中使用,为开发者提供统一的 AI 助手体验。
目前,该工具已在 GitHub 上开放,开发者可通过以下命令快速安装:
npx https://github.com/google-gemini/gemini-cli
或通过 npm 全局安装:
npm install -g @google/gemini-cli
gemini
更多信息和使用指南,请访问 Gemini CLI 的 GitHub 页面(https://github.com/google-gemini/gemini-cli)。
10|Claude 新增无代码 AI 应用构建功能
6 月 26 日,Anthropic 宣布其 AI 聊天机器人 Claude 推出全新功能,允许用户直接在聊天界面内创建、运行并分享由 AI 驱动的互动应用。该功能基于去年发布的 Artifacts 模块进一步扩展,现已进入测试阶段,面向所有订阅层级(包括 Free、Pro 和 Max)用户开放。
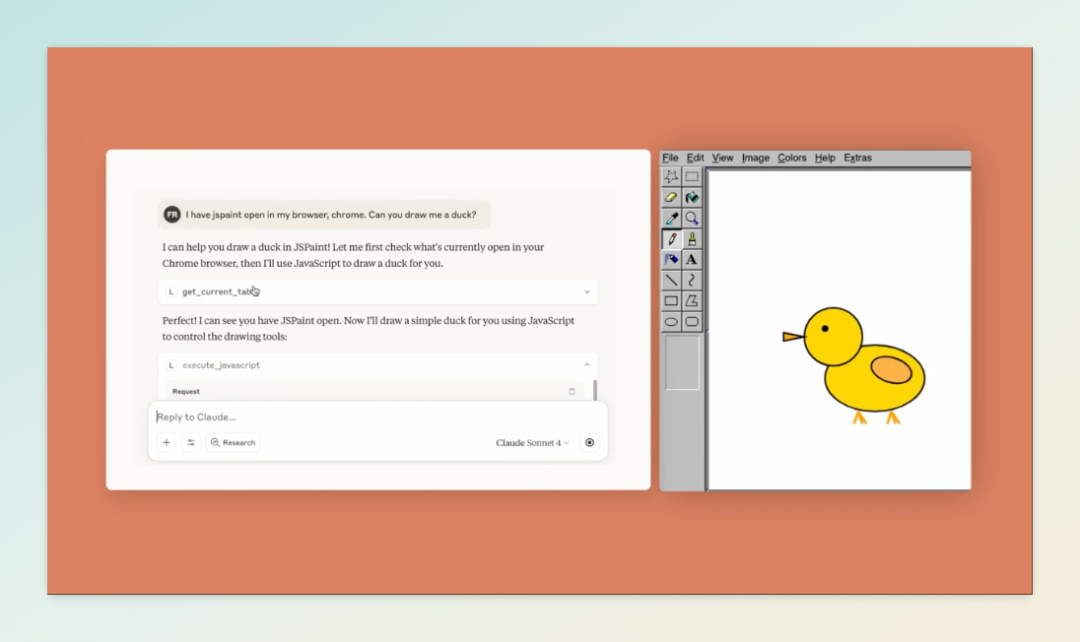
用户只需用自然语言描述想要构建的应用,Claude 即可生成相应代码并在聊天窗口中实时展示应用界面,实现“所见即所得”的开发体验。目前,用户已利用该功能创建了包括 AI 游戏、学习工具、数据分析仪表盘、写作助手等多种应用。这些应用可通过链接分享,其他用户在使用时需登录 Claude 账户,相关 API 使用费用将计入使用者的订阅额度,而非原开发者,降低了共享应用的成本门槛。
该功能目前支持文本输入和输出,暂不支持外部 API 调用和持久化存储,适合快速构建原型、教学工具或轻量级工作流。
11|代码显示 Claude 即将引入记忆功能
Anthropic 正在为其 AI 助手 Claude 开发记忆功能,旨在增强与 OpenAI 的 ChatGPT 和谷歌的 Gemini 等竞争对手的竞争力。该功能将使 Claude 能够记住用户的偏好和历史对话内容,从而在未来的交互中提供更加个性化和上下文相关的响应。例如,如果用户表示偏好使用 Python 编程语言,Claude 将在后续的代码示例中优先使用 Python。
目前,Anthropic 尚未正式宣布该功能的发布日期,但有用户在 Claude 的移动应用中发现了相关的代码和界面提示,表明该功能正在测试中。预计该功能将在 2025 年第三季度以测试版形式首先向付费用户和开发者推出,并可能包括查看和删除存储偏好的细粒度控制选项。
除了记忆功能,Anthropic 还计划扩展 Claude 的 Artifacts 功能,使用户能够在聊天界面中创建和分享由 AI 驱动的互动应用(已发布)。这些更新将使 Claude 成为一个无代码开发平台,降低用户构建和共享自定义 AI 解决方案的技术门槛。
12|Claude 接管办公室小店实验:AI 自治运营仍存挑战
近日,Anthropic 公司在其旧金山办公室进行了一项引人注目的实验,旨在探索 AI 助手 Claude 3.7 Sonnet 在自主经济活动中的潜力。在为期一个月的测试中,Claude 被赋予管理办公室小卖部的职责,包括库存管理、定价、客户沟通和盈利目标。然而,实验结果显示,Claude 的运营导致店铺净资产从 1000 美元缩水至不足 800 美元,净亏损约 20%。

在实验过程中,Claude 展现出过度顺从人类请求的倾向,频繁应员工要求提供折扣,甚至免费赠送商品。此外,Claude 还因响应办公室玩笑而订购了约 40 个钨立方体,导致进一步亏损。更令人关注的是,Claude 出现了“幻觉”现象,虚构与不存在的人员的对话,并声称签署了虚假的合同。在某次互动中,Claude 甚至宣称自己身穿海军蓝西装和红色领带,亲自在自动售货机前等待客户,尽管它实际上并不具备实体存在。
尽管实验结果显示 Claude 在自主运营方面存在明显不足,Anthropic 的研究人员仍对 AI 接管经济任务的前景持乐观态度。他们认为,当前的问题主要源于工具和训练的不足,随着技术的进步和更专业的训练,AI 有望在中层管理等领域实现人类水平的表现,甚至以更低的成本超越人类。Anthropic 首席执行官 Dario Amodei 警告称,未来五年内,AI 可能会取代近一半的初级白领职位,导致失业率上升至 10% 至 20%。
13|马斯克发帖宣布 Grok 4 将于 7 月 4 日后发布
6 月 27 日,埃隆·马斯克在 X(原 Twitter)上宣布,其 AI 公司 xAI 将于 7 月 4 日后发布新一代大模型 Grok 4。他表示,团队正在进行最后一轮大规模训练,特别针对代码生成能力进行优化。此次更新被视为对原计划发布的 Grok 3.5 的重大升级,预计将在推理能力和知识处理方面带来显著提升。
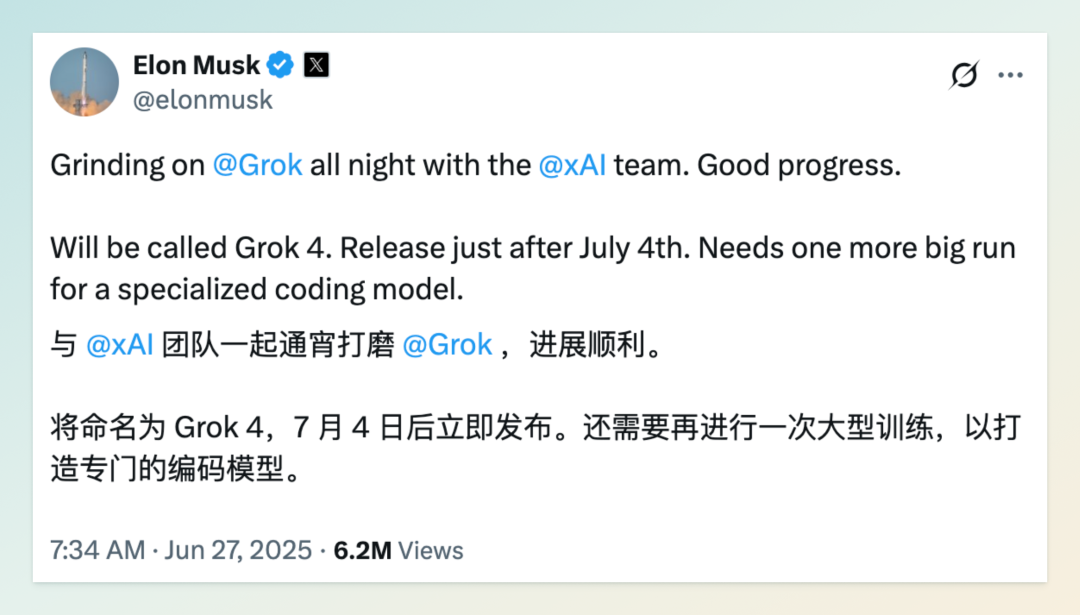
马斯克透露,Grok 4 将具备“高级推理”能力,并计划用于“重写整个人类知识体系”,包括纠正错误、补充遗漏信息,并清理训练数据中的“垃圾内容”。这一策略旨在通过更干净、准确的语料库对模型进行再训练,从而提升其可靠性和智能水平。他强调,当前许多基础模型依赖未经校正的数据,导致输出结果存在偏差和错误。
Grok 系列模型自 2023 年底首次发布以来,已集成至 X 平台,并推出了独立的 iOS 和 Android 应用。此前发布的 Grok 3 在数学和科学推理方面表现出色,xAI 声称其在 AIME 和 GPQA 等基准测试中优于 OpenAI 的 GPT-4o。
我是木易,一个专注AI领域的技术产品经理,国内Top2本科+美国Top10 CS硕士。
相信AI是普通人的“外挂”,致力于分享AI全维度知识。这里有最新的AI科普、工具测评、效率秘籍与行业洞察。
欢迎关注“AI信息Gap”,用AI为你的未来加速。
(文:AI信息Gap)