


引言
想象一下,我们对一个家务机器人说:“嘿,帮我把客厅打扫一下,然后把那杯喝了一半的水倒掉。” 对于人类,这是一个非常简单的指令,但对机器人而言,这背后却隐藏着巨大的挑战。它需要理解什么是“客厅”,如何识别“喝了一半的水”,并规划出“先去客厅”、“找到杯子”、“拿起杯子”、“走到厨房水槽”、“倒水”、“放回杯子”等一系列连贯、合理的动作。
这个过程,正是具身人工智能(Embodied AI)研究的核心——构建能够在物理世界中感知、交互并完成任务的智能体。其中,具身规划(Embodied Planning)扮演着智能体“大脑”的关键角色。
那么,究竟什么是具身规划?
我们可以把它理解为:一个将高层次、多步骤的用户指令(例如“打扫房间并将所有物品归位”)有效地分解为机器人能够理解并顺序执行的一系列底层原子动作(如“移动到桌子前”、“抓取杯子”)的过程。这要求模型不仅具备高级推理和理解能力,还需要将抽象的语言概念与物理世界的感知和行动紧密“具身”结合。同时,它还要能应对执行过程中可能出现的异常和不确定性,以确保规划的鲁棒性和可落地性。
传统的AI规划方法虽然为此奠定了理论基石,但在处理模糊的自然语言、运用常识以及融合多模态信息方面,始终存在一些难以逾越的局限。近年来,大型语言模型(LLM)和多模态大模型(MLLM)的出现,为解决这些长期存在的难题开辟了新的路径。
这篇笔记将系统梳理具身规划的发展脉络。我们会先回顾奠定基础的经典规划方法,然后重点探讨由大模型驱动的现代研究,剖析其核心策略与挑战,并对领域的未来趋势进行讨论。

图1 具身规划技术框架图
1. 早期经典规划方法
在大型语言模型普及之前,具身规划与机器人任务规划领域已经独立发展了数十年。这些经典的工作在算法、理论和评估体系上,为我们当前的研究打下了坚实的基础。它们的核心思路是利用符号逻辑的严谨性,或早期深度学习的模式识别能力,让智能体在一个明确定义的环境模型中进行有效的决策。理解这些经典方法,有助于我们更全面地认识具身规划的核心挑战,以及大型语言模型带来的真正价值。
1.1 基于符号逻辑的规划
当我们在进行一项规则明确的活动,比如下象棋时,我们的大脑就在进行一种类似符号规划的思考。我们会根据棋盘上每个棋子的明确位置(状态),以及“马走日、象走田”这样严格的规则(动作),在脑中推演一系列合规的移动,以期达到“将死”对方(目标)的最终局面。
经典符号规划(Classical Symbolic Planning)正是借鉴了这种思想。它在一个高度形式化、符号化的世界模型中,通过逻辑推理来搜索一条从初始状态通往目标状态的动作路径。这种方法非常依赖一个精确的“规则手册”,这个手册需要人工定义好世界的所有可能状态、每个动作的前提条件以及它会带来的确定性结果。
在这一领域,有几项工作具有里程碑式的意义。STRIPS [1]框架为了解决早期通用求解器效率过低的问题,将世界模型空间搜索与内部逻辑推导分离。它采用启发式方法搜索状态空间,并仅在需要时调用定理证明器验证状态。其算子定义为前提条件、增加列表和删除列表的组合,并默认未提及事实不变,简化了对状态变化的描述。
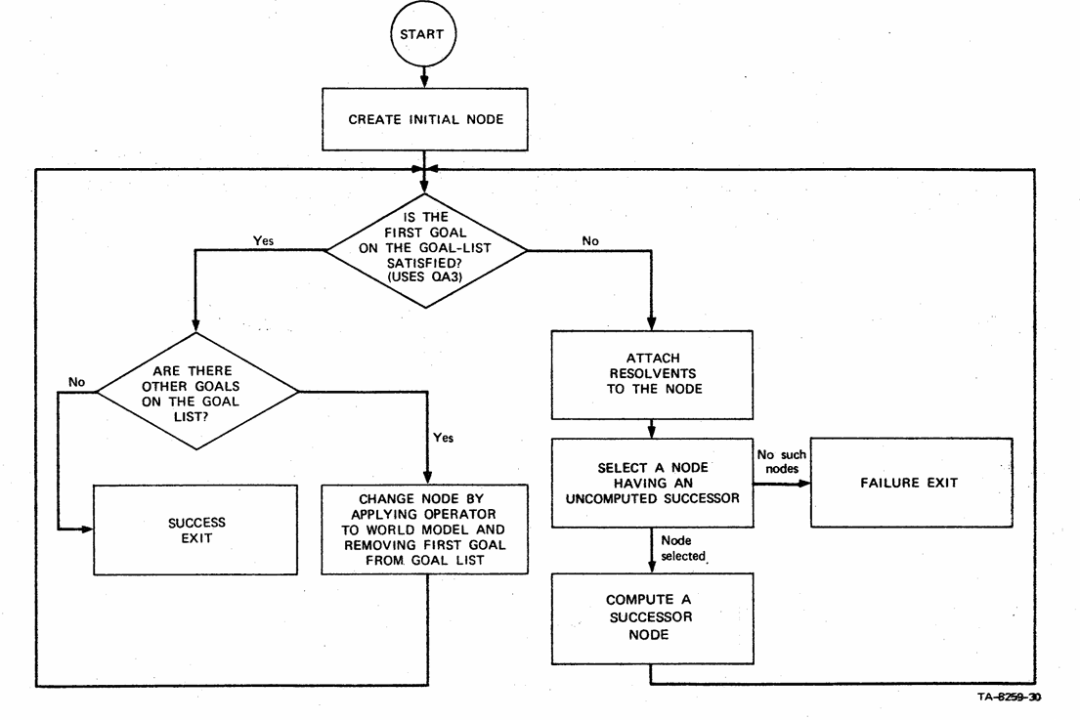
图2 STRIPS框架[1]流程图
规划领域定义语言(PDDL)[2]为自动化规划领域提供了通用描述标准,从而让不同的规划器能在同一个舞台上公平地比较和测试。PDDL3[3]作为其重要升级,引入了强大的“状态轨迹约束”和“软约束”概念,允许通过包含违规惩罚的规划度量来评估和优化不同规划的质量。
答案集编程(ASP)[4]是一种独特的声明式编程方法,尤其擅长解决复杂的搜索问题。它将问题转化为计算逻辑程序“稳定模型”的任务,并通过“生成、定义和测试”模式高效求解。一项对PDDL和ASP任务规划器的实证比较研究发现,PDDL规划器在需要长序列规划步骤计划的问题上表现更优,而ASP规划器则在对象数量庞大或需要复杂推理的问题上更快、扩展性更好。[5]
2011年举办的第七届国际规划竞赛(IPC-7)[6]全面展现了当时自动化规划领域的技术全景和发展方向。当年的竞赛主要分为确定性、学习和不确定性三个赛道,竞赛结果显示,前向搜索、规划器组合和蒙特卡洛树搜索等方法在各个赛道中表现突出,代表了当时最先进的技术水平。
这种方法的严谨性使其生成的计划逻辑清晰,易于人类理解和验证。然而,它也面临着一些固有的局限。随着问题变得复杂,可能的动作组合会急剧增多,导致巨大的计算开销,这就是常说的“状态空间爆炸”问题。同时,它高度依赖一个由专家手工构建的、完美无缺的领域知识库,这在多变的现实世界中难以实现。最后,它很难处理真实世界中普遍存在的传感器噪声和动作执行失败等不确定性。
1.2 基于深度学习的规划
想象一位经验丰富的厨师,他不需要严格的菜谱也能烹饪佳肴。他通过观察食材的形态、闻到香气,并结合过往无数次的烹饪经验,就能下意识地知道下一步该做什么。这个过程并非基于严谨的逻辑推演,而是基于大量经验形成的一种直觉。
在LLM时代来临前,深度学习领域的规划研究便试图借鉴这种基于经验的“直觉”。研究者们探索利用神经网络强大的表示学习能力,直接从海量的高维数据(如图像、视频)中自动学习任务规划所需的知识,比如如何从一张图片中识别出关键物体,或者预测一个动作可能产生的结果。
这一时期的探索也产生了一些代表性的工作。通用规划网络(UPN)[7]提出了一种学习适用于复杂机器人控制的视觉表征的思路。它的核心是一个可微分的规划器,该规划器被直接嵌入到神经网络策略中。UPN在一个学习到的隐空间中,通过梯度下降来优化一个动作序列。整个网络通过模仿学习进行端到端的训练,学习到的表示非常通用,不仅能完成模仿学习任务,还能为强化学习在新任务上提供奖励函数。
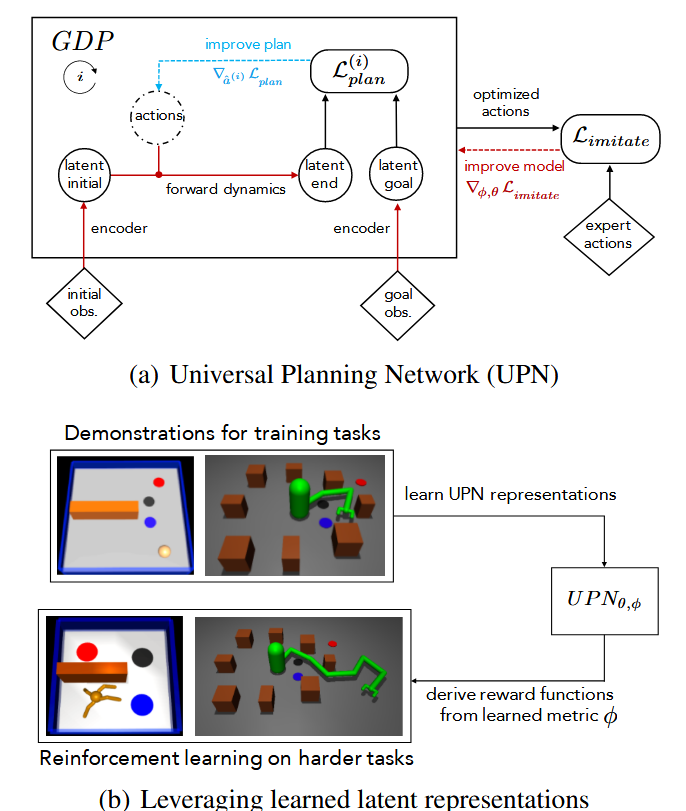
图3 UPN[7]概览图
为了解决长序列机器人操作任务中的组合爆炸难题,一种基于视觉的分层规划算法被提了出来。该方法的核心是一种双层场景图表示:底层的几何场景图描述物体的三维姿态和空间关系,而高层的符号场景图则抽象出逻辑关系。规划时,高层级的神经符号规划器利用GNN在符号图上预测子目标,再由底层的运动生成模块将其“落地”为具体的运动指令。[8]
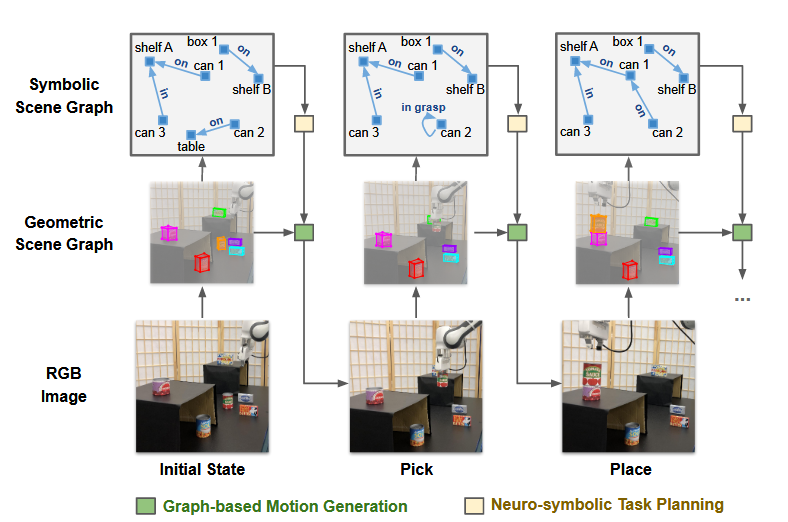
图4 分层规划模型[8]示意图
LatPlan [9]框架探索了完全自动化地打通从像素信息到符号化规划的桥梁。它的核心是一个状态自动编码器(SAE),该编码器以无监督的方式将高维的原始图像编码成离散的、命题化的向量表示。接着,一个动作模型获取模块分析状态向量之间的转换关系,自动学习出动作模型。最终,LatPlan 能将给定的初始和目标图像转化为一个符号规划问题,并调用现成的经典规划器求解。
PlaNet [10]是一个纯粹基于模型的智能体,它能够直接从像素学习环境的动态模型,并在一个紧凑的隐空间中进行快速在线规划。它采用一种名为“循环状态空间模型”(RSSM)的结构,巧妙地结合了确定性部分和随机性部分。在训练时,它通过一种名为“隐式超调”的目标函数来优化多步预测的准确性,以较高的数据效率解决了复杂的图像连续控制任务。
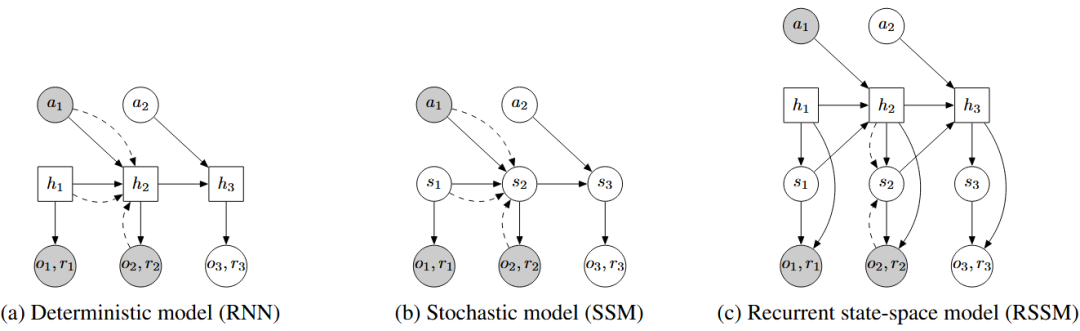
图5 PlaNet[10]模型设计对比图
传统的任务与运动规划(TAMP)方法通常因巨大的离散动作序列搜索空间而效率低下。为了克服这一问题,深度视觉推理(Deep Visual Reasoning[11])框架提出了一种解决方案:使用一个深度卷积循环神经网络,直接从初始场景图像和任务目标中,一次性预测出最有希望成功的整个高层动作序列。该方法的一个核心技巧是将场景中的物体和目标都编码在图像空间中,这使得网络能够很好地泛化到包含更多物体的复杂场景中。
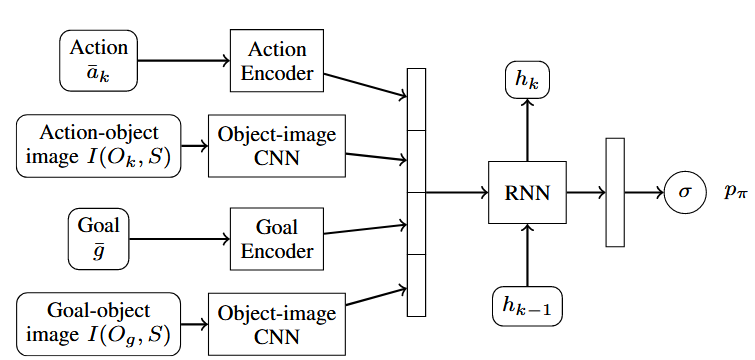
图6 Deep Visual Reasoning[11]神经网络架构图
这种数据驱动的思路,使其能够直接处理原始的视觉信息,减少了对人工设计模型的依赖。但这种方法在当时也遇到了瓶颈。它通常需要大量的标注数据才能取得理想效果,获取成本高昂。并且,神经网络的决策过程不透明,如同一个“黑箱”,令人难以完全信任和调试。尤其是在长序列规划和奖励稀疏的任务中,从零开始学习一个有效策略的效率和稳定性都面临很大挑战。
2. 大模型驱动的具身规划
大型语言模型(LLMs)与多模态大模型(MLLMs)的出现,为具身智能体与物理世界的互动方式带来了新的可能性。它们在自然语言理解、逻辑推理、知识整合等方面的能力,为解决传统规划方法中存在的诸多瓶颈,如长序列任务的逻辑一致性、物理世界常识的运用、多模态信息的融合等,提供了有力的解决方案。
研究者们正积极地将大模型的通用能力与具身场景的特定需求相结合,不仅利用其在高层次语义理解和推理上的优势,也努力弥补其在物理世界接地、保障逻辑一致性以及响应实时环境等方面的不足。
2.1 长序列规划的推理生成
当我们需要为一次周末的野餐做准备时,脑中会浮现一个包含数十个步骤的复杂计划:检查天气、列购物清单、去超市采购、准备食物、打包野餐篮等等。在这个过程中,我们必须确保所有步骤逻辑连贯(不能先打包再购物),并且始终围绕“成功举办野餐”这个最终目标。
同样,长序列规划要求智能体为达成一个远期目标,生成并执行一长串环环相扣的复杂动作。这是具身规划中的一个核心难题,因为随着规划链条的增长,模型很容易出现逻辑断裂、忘记初衷或生成与物理现实相悖的动作。为了解决这一问题,研究者们发展出了多种策略。
2.1.1 基于提示工程的推理优化
与人沟通时,我们换一种提问方式,往往能得到更满意的回答。例如,直接问“这个项目怎么做”,不如引导性地问“我们来分三步走,第一步该做什么?”。这种通过优化提问来引导答案的方式,就是提示工程(Prompt Engineering)的核心思想。在具身规划中,它指的是通过设计精心构造的输入提示,来引导和约束模型的思考过程,让它像人类一样“三思而后行”,从而生成更具逻辑性和可执行性的规划。
这一方向的典型工作利用了不同的引导策略。Inner Monologue [12]框架的核心思想是让作为规划器的LLM能够通过“内心独白”来进行具身推理,从而实现闭环的机器人控制。它将来自环境的各种实时反馈——例如,动作成功与否的检测、对场景中物体的描述——持续地以自然语言形式注入到LLM的提示中。这种持续的语言反馈流,使得LLM能够在其规划过程中动态地感知执行结果、发现并修正错误。
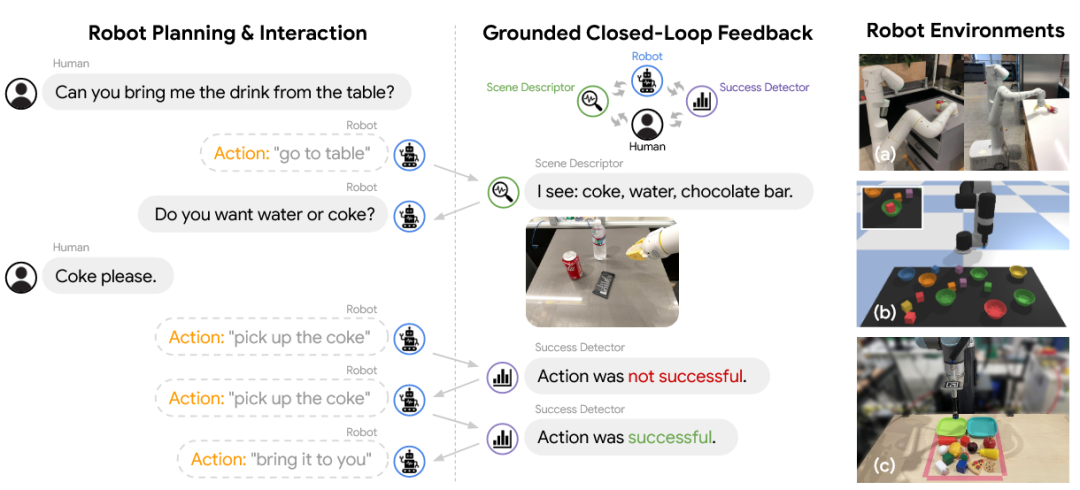
图7 Inner Monologue框架[12]示意图
为了提升视觉语言模型(VLM)在具身任务中进行精确空间推理和生成坐标级动作的能力,研究人员提出了SpatialCoT [13]框架。该方法包含两个核心阶段:首先是“空间坐标双向对齐”,通过专门的数据对模型进行训练,使其能理解语言与坐标之间的相互转换;其次是“思维链空间落地”,在这一阶段,模型被引导先生成一段语言形式的推理过程,然后再基于这段推理产出最终的坐标动作。这种“先思考,后行动”的模式,利用了VLM内在的语言推理能力。
Reflexion 框架[14]提出了一种新颖的“言语强化学习”方法,让语言智能体能够通过试错和自我反思来学习,而无需更新模型权重。其核心机制是,智能体在每次尝试任务后,由一个“自我反思”模型分析这次尝试的轨迹和结果,并生成一段文字性的反思摘要。这段反思文字会被储存在一个记忆模块中,并在下一次尝试时作为额外的上下文信息提供给智能体,帮助其从过去的错误中吸取教训。
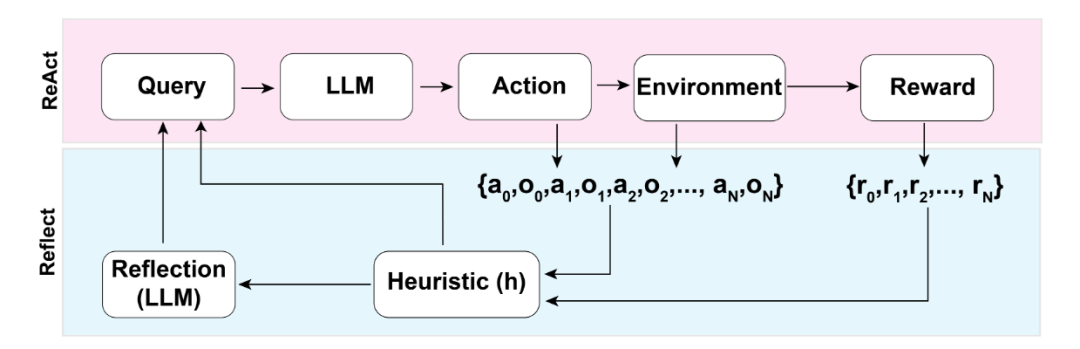
图8 Reflexion框架[14]架构图
为解决传统LLM迭代式规划器高昂的token消耗和低效的错误纠正问题,TREE-PLANNER[15] 提出了一种创新的三阶段框架。首先,它通过一次LLM调用,预先采样出多种可能的任务规划方案,并整合成一棵“动作树”。执行时,LLM仅需根据实时环境观察,在这棵树上选择下一步分支。当遇到失败时,智能体可在树上回溯,而非从头重新规划,提升了纠错的效率和灵活性。
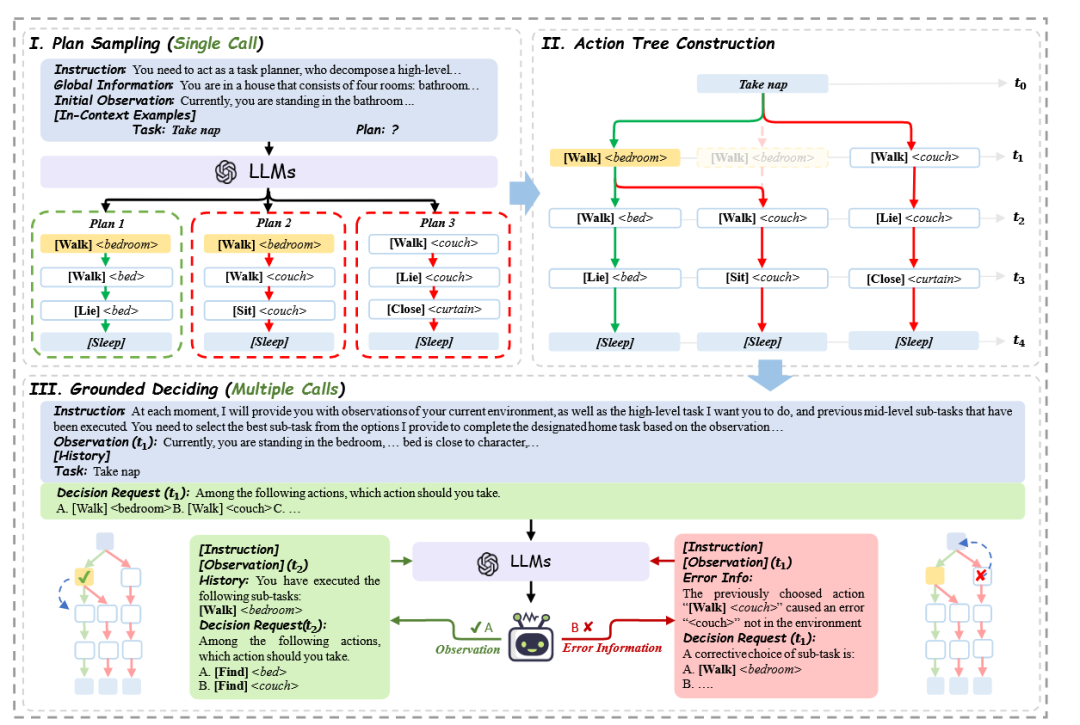
图9 TREE-PLANNER框架[15]架构图
SWIFTSAGE [16]是一个受人类认知双过程理论启发的智能体框架,它结合了“快思考”与“慢思考”来高效地解决复杂交互任务。该框架由代表快速、直觉思维的SWIFT模块(一个经过行为克隆训练的小型语言模型)和代表审慎、分析思维的SAGE模块(在必要时调用强大的LLM)组成。这种快慢结合的策略,使得智能体在实现良好性能的同时,也提升了决策效率和成本效益。
这种方法的灵活性很高,因为它不需要重新训练模型,就能在一定程度上改善规划质量。不过,设计一个高效的提示往往需要针对具体任务进行反复试验,并且复杂的提示也会带来更多的计算开销和推理延迟。
2.1.2 基于监督微调的逻辑强化
除了在对话时巧妙引导,我们还可以采用一种更直接的“教学”方式。这就像教一个学生解应用题,我们不只告诉他技巧,还会给他大量的例题和标准答案,让他通过模仿和归纳,掌握解题的“套路”。在具身规划中,这种方法被称为监督微调(Supervised Fine-tuning, SFT)。它的核心,就是通过准备大量高质量的“任务描述-正确规划序列”配对数据,对预训练的大模型进行“再教育”,使其内在的规划逻辑更贴合特定任务的要求。
一些研究工作在这方面进行了有益的探索。一个名为“赛博力克基础骨架框架”(TBBF)[17]的新方法,借鉴工业工程中的“赛博力克”(therblig)基本动作单元概念,将任何复杂的机器人操作任务都分解为一系列可解释的基础动作序列,形成任务的“骨架”。系统仅需通过一次新任务的演示,就能快速提取出其赛博力克骨架,并将其灵活地适配到新的场景和对象上。这种方法提升了数据效率,也因为其结构化的分解而增强了任务理解和执行过程的可解释性。
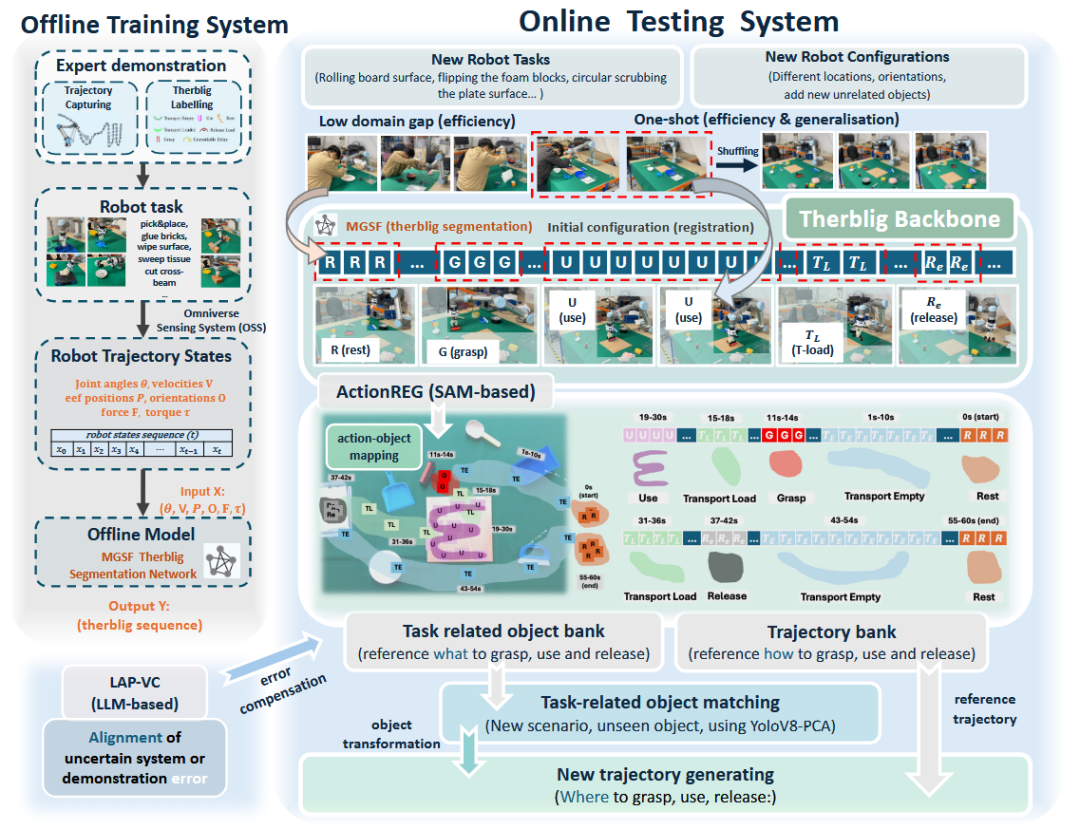
图10 TBBF框架[17]架构图
MLDT 框架[18]提出了一种多层次分解规划方法。该方法模仿人类解决复杂问题的思路,将一个宏大任务在“目标层”、“任务层”和“动作层”三个不同粒度上进行拆解。通过这种层层递进的分解,每个阶段LLM需要处理的上下文和生成的内容长度都大大减少,从而有效规避了小模型在长序列推理上的短板。
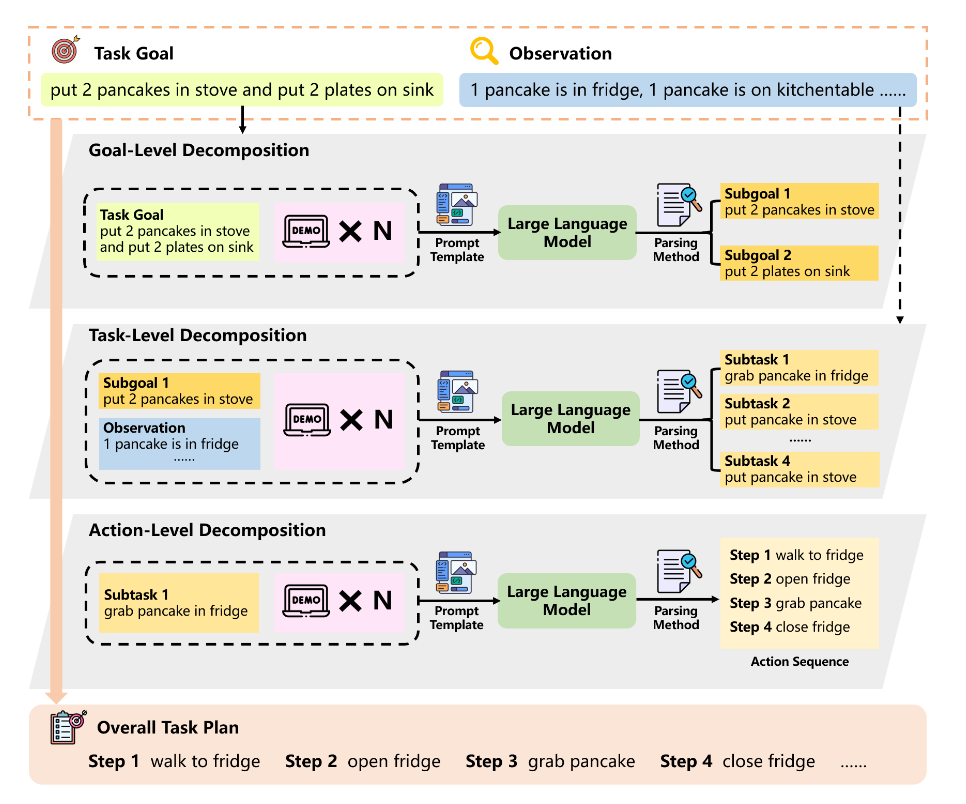
图11 MLDT框架[18]示意图
为了应对机器人高级操作任务中连接人类指令和机器人具体动作的可用数据稀少这一挑战,研究人员提出了CogLoop 框架[19]。该方法首先通过多轮提示,利用LLM自动生成一个包含多步文本规划和成对观察序列的认知机器人数据集(AlphaBlock)。随后,一个闭环的多模态具身规划模型在此数据集上进行微调,该模型以自回归方式,将图像观察作为输入来生成规划。
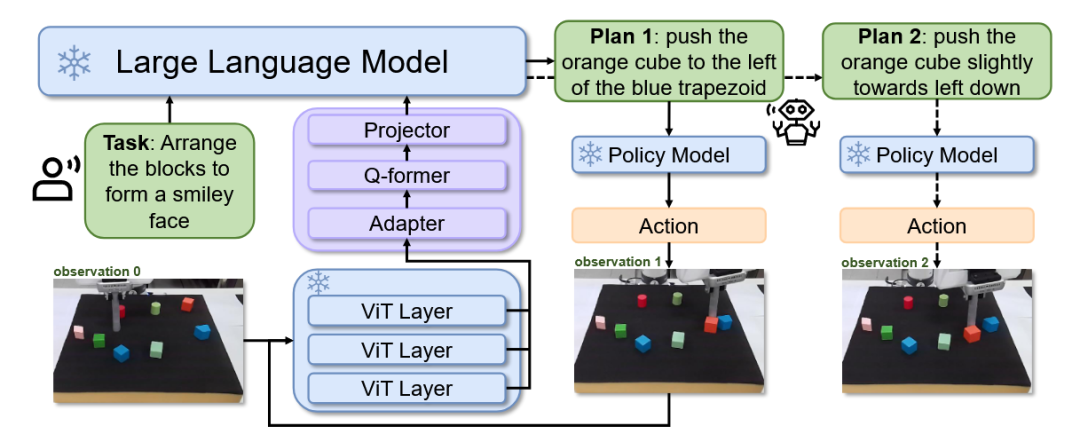
图12 CogLoop框架[19]架构图
MimicPlay 框架[20]为解决长序列机器人模仿学习中演示数据收集成本高昂的问题,提出了一种分层学习策略。它的核心方法是利用廉价易采集的“人类玩耍数据”(用手交互的视频)来训练一个高层级的隐式规划器,该规划器学习预测未来手部运动的3D轨迹。同时,用少量宝贵的机器人遥操作数据训练一个低层级控制器来执行该规划。这种方式提升了学习长序列任务的样本效率和泛化能力。
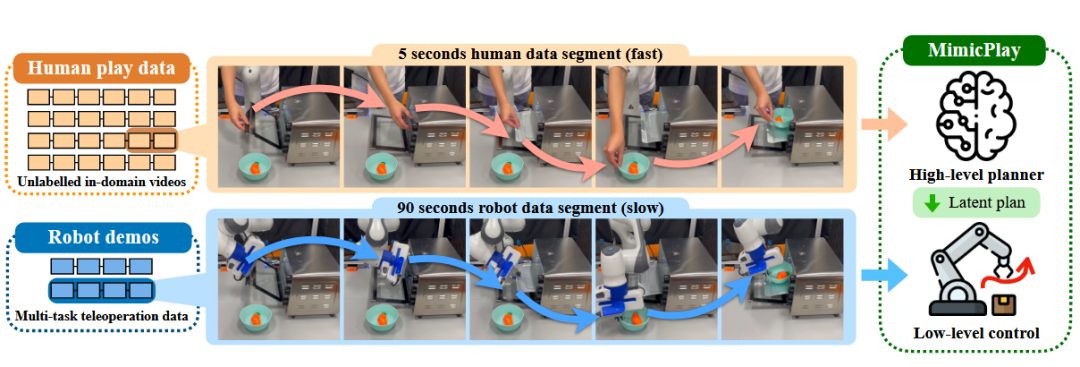
图13 MimicPlay框架[20]示意图
经过微调的模型,其生成的规划往往更能遵循特定领域的物理约束和逻辑范式,显得更加“专业”。但这种方法的门槛也相对较高,它的效果很大程度上依赖于大规模、高质量的标注数据,而这类数据的获取成本可能非常高昂。此外,也需要注意模型“过拟合”训练数据的风险,这可能导致其在未见过的新场景中泛化能力有所下降。
2.1.3 基于程序符号的规划生成
如果说自然语言像散文,自由但有时模糊,那么程序代码就像法律条文,严谨且无歧义。为了兼顾大模型的理解能力和传统方法的严谨性,一个很有前景的思路是引导LLM不直接输出自然语言规划,而是生成具有严格语法结构和可执行性的代码(如Python脚本)或符号化表示(如PDDL文件)。
LLM+P 框架[21]结合了大语言模型(LLM)的自然语言理解能力与经典规划器的精确求解能力。其工作方法并非让LLM直接生成规划,而是将其作为一个“翻译器”:首先,LLM负责将用户用自然语言描述的复杂问题,自动转换成经典规划器可以理解的、形式化的PDDL问题文件。然后,系统调用高效的经典规划器找到最优的符号化解决方案,最后再由LLM将这个方案翻译回通俗易懂的自然语言描述。
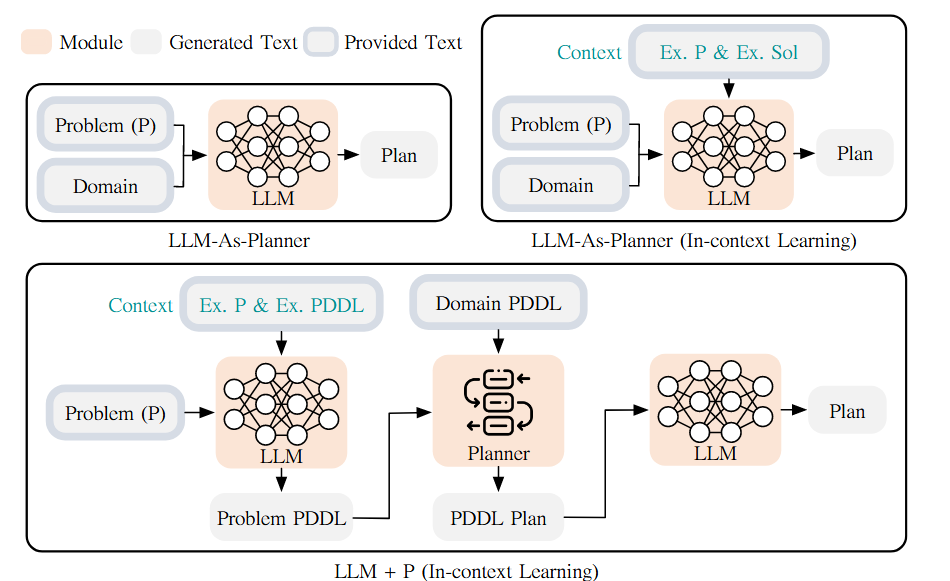
图14 LLM+P框架[21]示意图
为解决大语言模型在长序列规划中时常忽略给定规则和约束的问题,研究人员提出了FLTRNN 框架[22]。该方法受人类智能启发,采用了一种基于语言的循环神经网络(RNN)结构,将任务分解和记忆管理机制融入LLM的规划推理过程,确保LLM在规划时能聚焦于当前最相关的规则与约束。
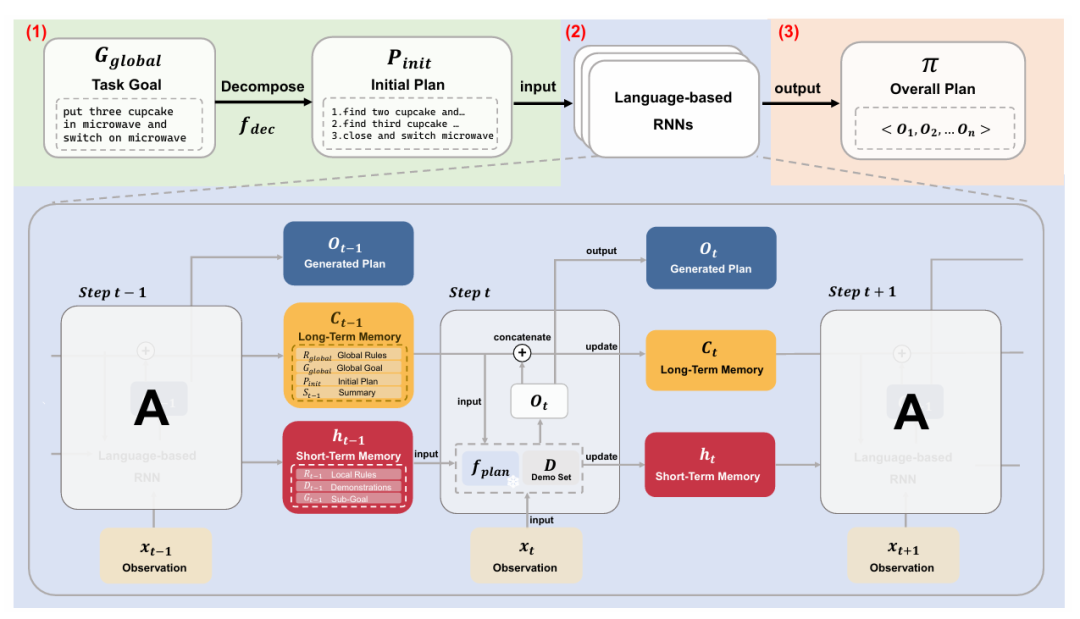
图15 FLTRNN框架[22]架构图
BTGenBot [23]尝试解决在机器人上直接部署任务规划模型的难题,其核心是证明了轻量级大语言模型(参数量≤7B)同样能够胜任为机器人生成行为树(BT)的复杂任务。该方法通过收集并利用开源机器人项目的行为树,自动生成一个高质量的指令微调数据集,并采用参数高效微调技术训练紧凑型LLM,使其掌握从自然语言到行为树XML代码的生成能力。
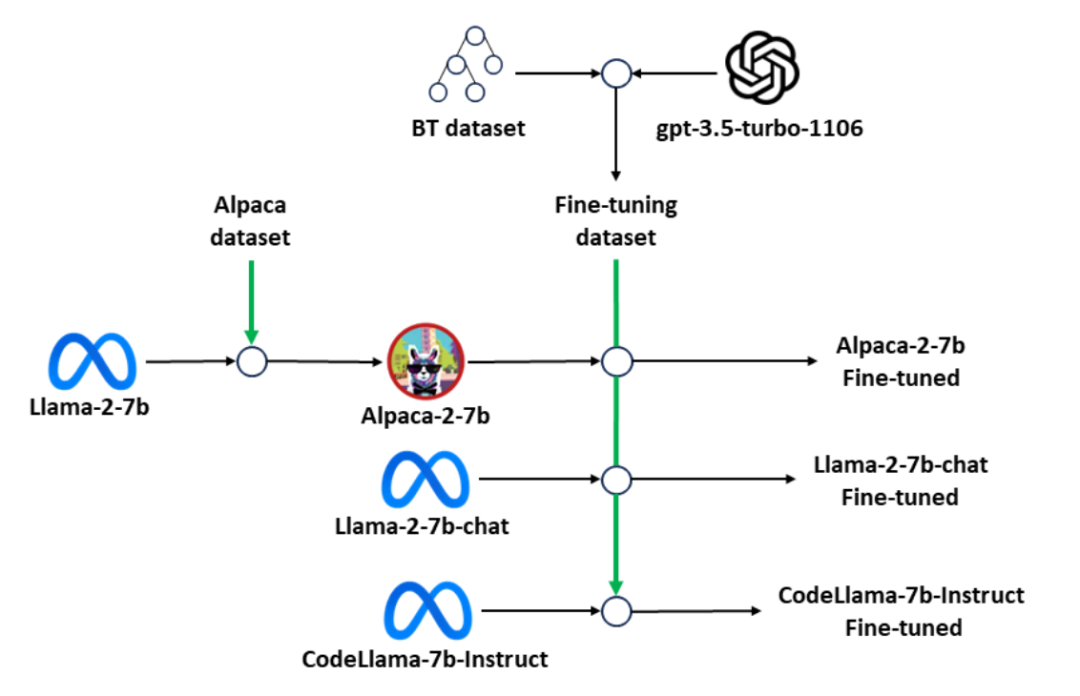
图16 BTGenBot[23]微调流程图
“代码即策略”(Code as Policies)框架[24]提出,可以直接将为代码补全而训练的大语言模型(LLM)用于编写机器人策略代码。其核心方法是,通过少量示例提示,让LLM将自然语言指令转化为包含感知API调用和控制API参数化的Python代码,从而表达出反应式或基于路点的复杂策略。
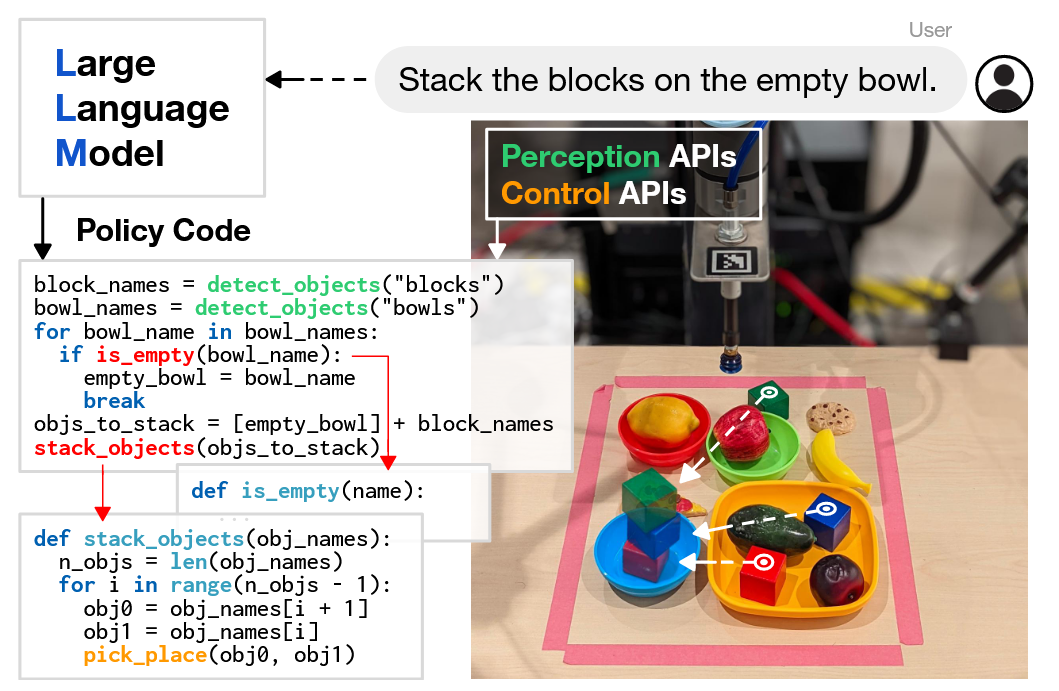
图17 Code as Policies框架[24]示意图
为了让机器人能够理解并执行复杂的菜谱指令,Cook2LTL 框架[25]应运而生。该方法的核心是将自然语言菜谱指令,通过大型语言模型(LLM)的辅助,自动翻译成精确且无歧义的线性时序逻辑(LTL)公式。系统能将未知的烹饪动作分解为一系列基本动作,并将分解后的策略缓存到动态更新的动作库中。
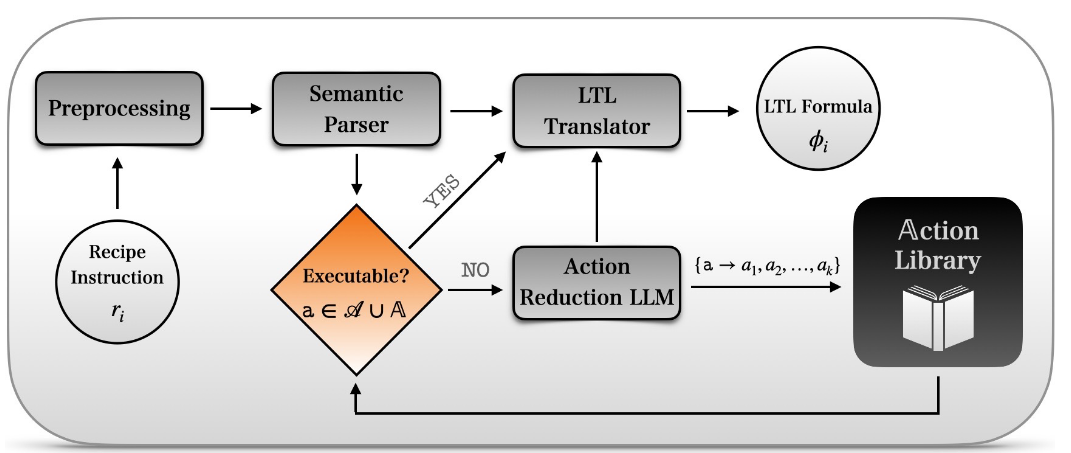
图18 Cook2LTL框架[25]架构图
通过这种方式生成的规划,逻辑严谨、可验证、可解释性强。不过,这种方法通常需要为代码或符号的解析和执行开发额外的工具,增加了系统的整体复杂性。
2.2 面向物理世界的知识运用
当你被告知“去给我热杯牛奶”时,你的大脑会自动调用大量常识:牛奶通常在冰箱里,需要用微波炉或炉灶加热,得用一个适用于微波炉的杯子,加热时间不能太长等等。这些知识对于成功完成任务至关重要。
尽管LLM在训练中见过了海量文本,但它们生成的规划步骤常常因为缺乏对物理世界深刻、隐性的理解而变得不可行。这种“知识壁垒”源于大模型对物体可供性(affordance,如杯子是用来装水的)、基本物理规律、操作约束等常识的缺失。如何弥补这些知识缺失,是提升其具身规划能力的关键。
2.2.1 基于场景图的知识融合
正如我们看地图比听人描述路线更容易找到方向一样,为大模型提供一张关于物理环境的“地图”,能让它的规划更加“接地气”。这种地图就是场景图(Scene Graph)。它是一种结构化的数据,能将视觉等感知信息转化为包含“物体节点”和“关系边”(如“杯子在桌子上”)的图结构,让模型在规划时能“看懂”环境的实际情况,而不是在真空中想象。
这方面的工作通常聚焦于如何构建和利用这种“地图”。研究者提出了一种场景驱动的多模态知识图谱(Scene-MMKG)构建方法[26]。该方法利用LLM对自然场景描述进行分析,通过提示工程自动生成一个与场景高度相关的知识图谱模式。随后,以此模式为指导,从现有通用知识库中获取基础知识,并结合小规模的多模态数据进行补充,从而高效地完成知识填充。
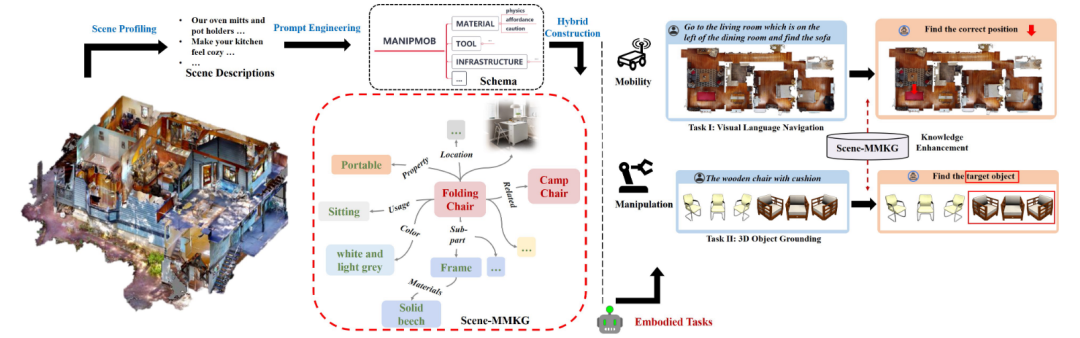
图19 Scene-MMKG[26]构建与使用示意图
ConceptGraphs 方法[27]构建一种开放词汇的三维场景图,为机器人提供一个既语义丰富又紧凑的世界表征。它的构建流程是:首先通过多视角关联,将二维物体分割结果融合成三维实体作为图的节点。然后,系统利用大型视觉语言模型(LVLM)为每个三维物体生成生动的文字描述,并借助大型语言模型(LLM)推断物体间的空间关系,形成图的边。
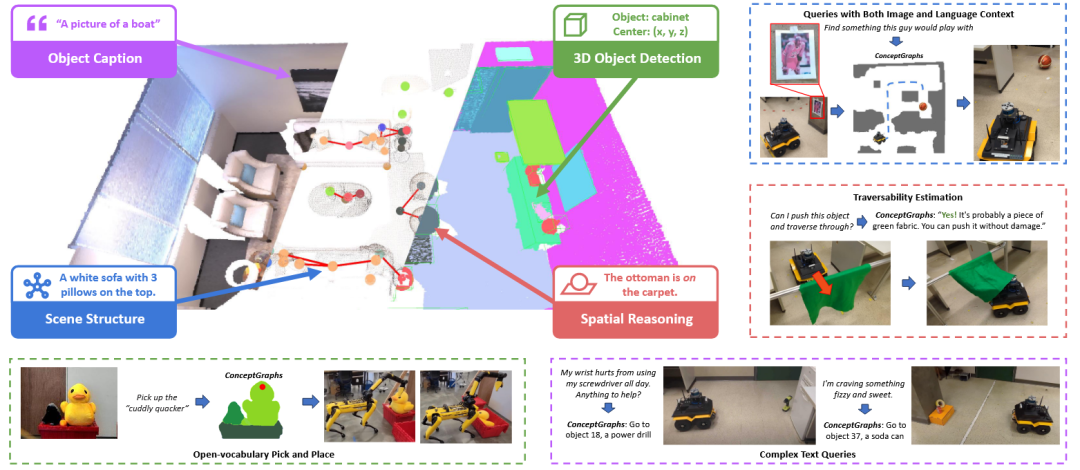
图20 ConceptGraphs[27]构建与使用示意图
为了让具身智能体能够更好地理解并执行复杂的自然语言指令,LookPlanGraph 框架[28]提出了一种分层的规划方法。该方法首先通过一个Look模块,从视觉输入中构建一个明确的、包含物体及其空间关系的场景图。紧接着,一个高层级的规划模块 (Plan) 在这个结构化的场景图上进行推理,生成一系列子目标。最后,一个低层级的模块负责将这些符号化的子目标解释并“落地”为智能体可以执行的具体动作 (Graph)。
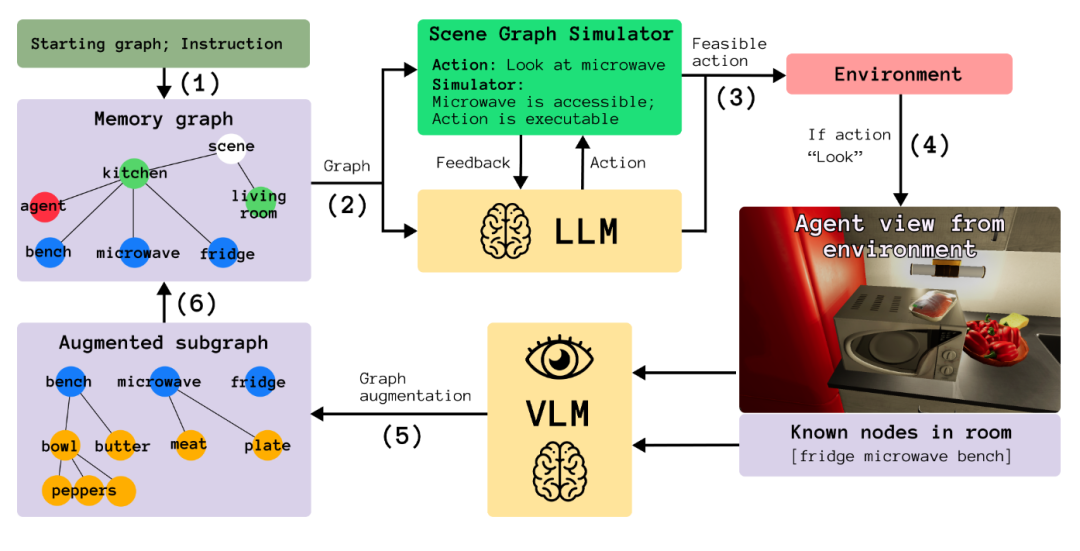
图21 LookPlanGraph框架[28]架构示意图
GRID 框架[29]利用场景图(Scene Graph)来代替传统的图像输入,以应对机器人任务规划中对全局环境理解的挑战。该方法的核心是一个轻量级网络,它将人类指令、包含物体及其关系的场景图、以及机器人自身状态图作为输入。GRID 通过一个共享的LLM编码器来理解语义,并利用图注意力网络(GAT)来处理图的结构化信息,从而精确地规划出子任务。
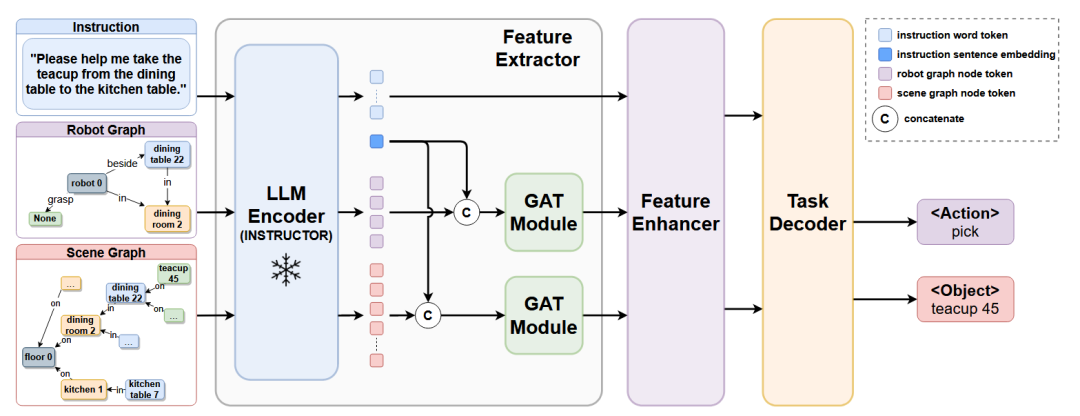
图22 GRID框架[29]架构示意图
为了让机器人在现实世界中能更好地理解模糊、抽象的人类指令,EventNav 框架[30]被提了出来,专门处理视觉语言导航(VLN)中的粗粒度任务。该方法首先从多个主流VLN数据集中构建了一个名为 VLN-EventKG 的事件知识图谱,用于封装任务步骤之间的时序关系和常识。在规划时,EventNav 借助这个知识图谱来增强大型语言模型(LLM)的能力,使其能将抽象指令有效分解为一系列具体的子任务。
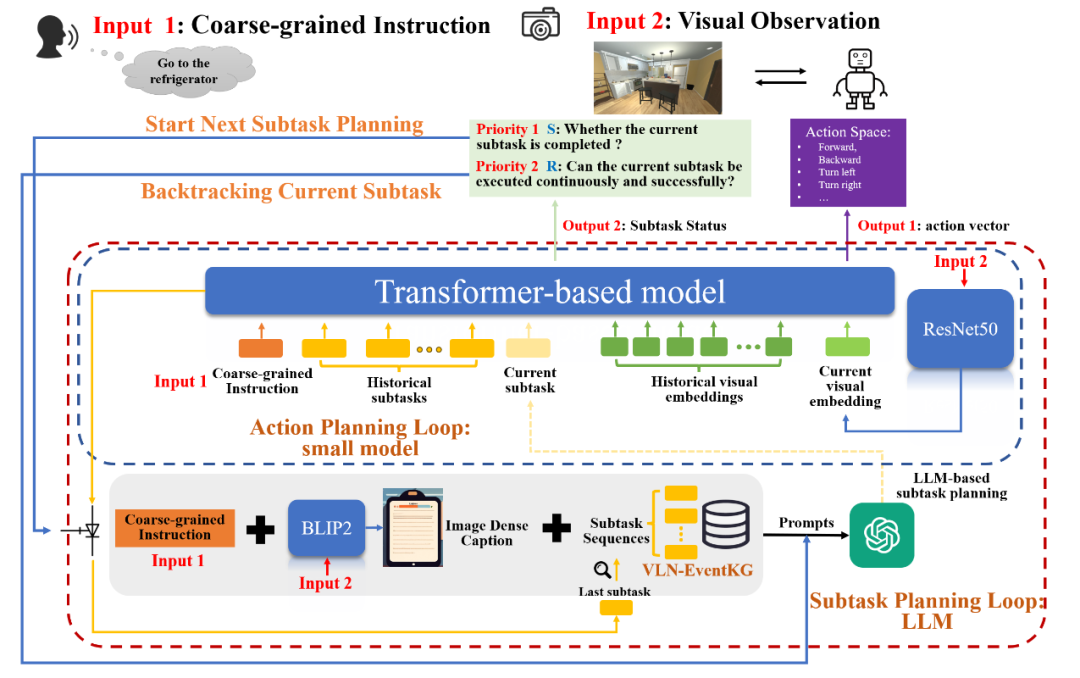
图23 EventNav框架[30]架构示意图
为了将大型语言模型(LLM)的语义理解能力与机器人任务规划相结合,研究者设计了一种名为 Think_Net_Prompt [31]的提示模板。该方法的核心是利用有向图来表示结构化的专业知识,通过逐层分解复杂任务来生成任务树,有效降低了单次规划的逻辑难度。同时,通过解耦任务规划与机器人分配,整个流程变得更加灵活和高效。
这种方法为大模型提供了精确的空间信息,使其规划更具针对性。但它的难点在于,准确、实时地从原始感知数据中构建高质量的场景图本身,就是一个复杂且充满挑战的技术问题。
2.2.2 基于领域知识的规划辅助
通用常识可以帮助机器人完成日常任务,但对于专业任务,比如在化学实验室里进行操作,则需要严格遵守特定的安全规程。注入领域特定知识的核心思路,就是通过直接编码、信息检索或微调等方式,将这些专家知识明确地提供给大模型,确保其生成的规划严格遵循该领域的安全要求和隐性约束。
SayCan 框架[32]提出了一种将大型语言模型(LLM)的丰富语义知识与机器人的物理能力相结合的方法。其核心思想是:首先,一个LLM(代表“说”,Say)负责评估一系列预先训练好的机器人技能对于完成一个高阶自然语言指令的有用程度。与此同时,与每个技能相关联的价值函数(代表“能”,Can)会评估该技能在当前物理环境下成功执行的可能性。最终,系统通过将这两个概率相乘来选择一个既有用又可行的技能来执行。
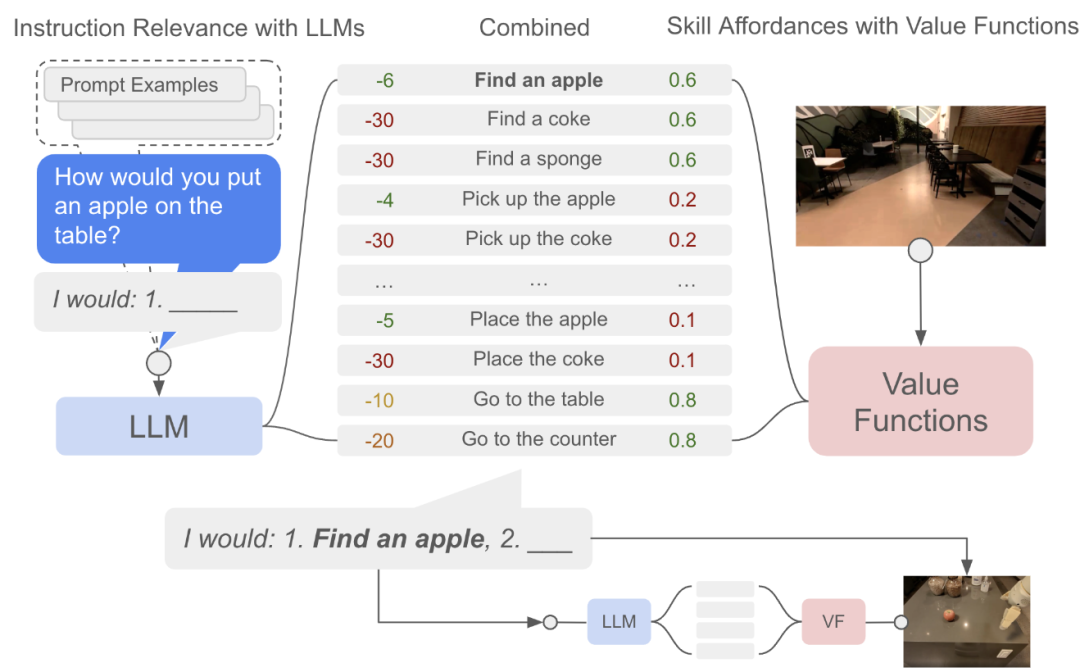
图24 SayCan框架[32]示意图
SayCanPay 框架[33]在 SayCan 的基础上进行了扩展,引入了一个名为 Pay 的新模块,该模块通过学习领域知识来评估每个候选动作的长远回报或“收益”。因此,在规划的每一步,系统会综合考量动作可能性(Say)、可行性(Can)和预估的长期收益(Pay),利用这个组合分数作为启发式信息,通过搜索算法选择最优的动作序列。
DKPROMPT 框架[34]结合经典规划器的鲁棒性与视觉语言模型(VLM)的环境理解能力。其核心思想是利用经典规划器中已有的领域知识(以PDDL等语言形式化定义)来自动生成对VLM的提示。具体来说,在执行计划的每一步前后,DKPROMPT 会将动作的“前提条件”和“预期效果”转化为自然语言问题,并结合机器人当前的视觉观测,向VLM进行提问,从而有效地检测动作的失败或环境中的意外情况。
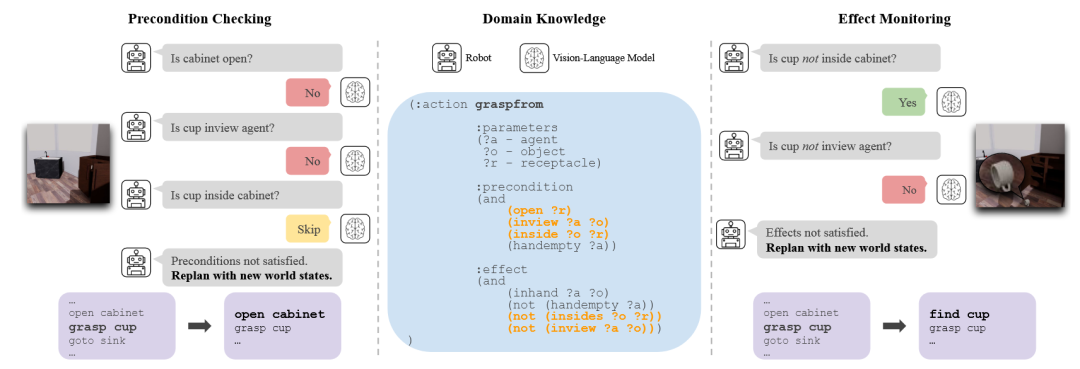
图25 DKPROMPT框架[34]示意图
为了让机器人能够像人一样、在没有明确指令的情况下整理房间,研究者提出了 Housekeep 任务基准[35]。该任务的核心是让智能体利用常识推理来判断哪些物体被放错了位置,并将其重新摆放到符合人类偏好的合适地点。为了支持这一任务,研究者首先收集了一个大规模的人类偏好数据集,并提出了一个模块化的基准模型,其规划核心是利用一个在偏好数据上微调过的LLM。
为加速机器人的长序列任务规划,一项研究提出了一种利用“抽象策略”(Abstract Strategies)[36]的方法,即对过往的成功规划经验进行编码和泛化。其核心是将规划问题重新定义为一个“策略增强域”,在这个域中,抽象策略可以像普通动作一样被规划器直接调用和组合。该方法提出了策略“可供性”(Affordance)的概念,通过一个评分函数来预测策略在当前任务中的潜在价值和适用性。
面对经典任务规划器在开放世界中显得脆弱的问题,研究人员提出了COWP 框架[37]。该方法的核心是动态地利用LLM的常识知识来增强经典规划器的行动知识库。当计划监视器检测到意外情况(如“杯子是脏的”)时,会向LLM查询并补充新的前提条件。当规划器因此无法找到解决方案时,知识获取器会向LLM寻求常识性的解决方案(如“碗也可以用来装水”),并作为新动作效果添加到规划器中。
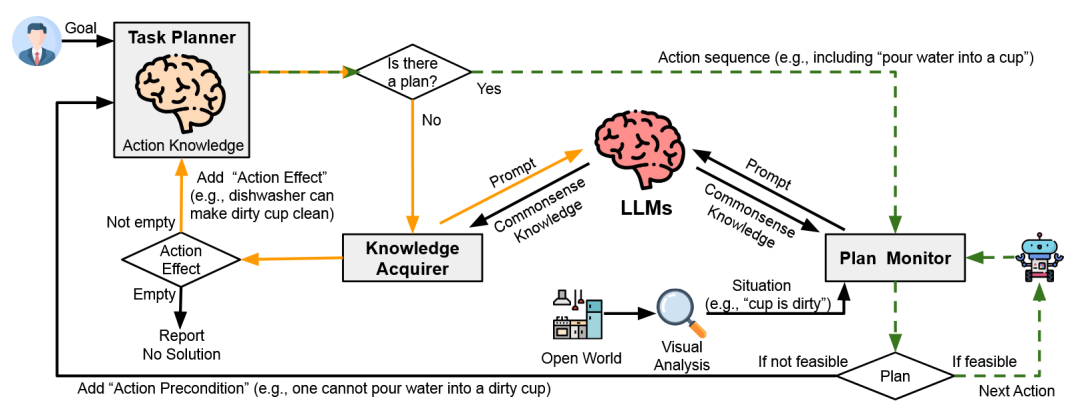
图26 COWP框架[37]示意图
这种方法能有效提高规划在特定领域中的安全性和可执行性。但挑战在于,设计、构建并维护一个全面、准确的领域知识库,需要大量的专家投入和持续的工程努力。
2.2.3 基于技能库的规划约束
为了从根本上确保大模型生成的规划是机器人“能做到的”,一个直接的方法就是用一个经过验证的机器人技能库(Skill Library)来约束大模型的输出空间。这就像给一个刚学做饭的人一本只包含“切菜”、“炒”、“煮”等几个基本操作的菜谱,他虽然不能自由发挥,但做出的菜至少是合规的。这里的“技能”通常指机器人已经掌握的、具有明确语义和可靠执行能力的基本动作单元(如grasp(object)、move_to(location))。规划时,LLM的任务不再是自由生成文本,而是从这个技能集合中进行选择、参数化并组合。
为结合大型语言模型(LLM)的高阶规划能力与端到端模仿学习的灵活性,研究者提出了计划条件化行为克隆(PCBC)方法[38]。该方法首先利用LLM为特定任务生成一个由一系列“如果(条件),则(技能)”规则组成的“条件化计划”。在执行时,一个可微分的神经网络架构会实时评估计划中的所有条件,并根据评估结果对所有技能的嵌入向量进行加权组合,生成一个融合了当前意图的“技能隐向量”,最终生成控制指令。
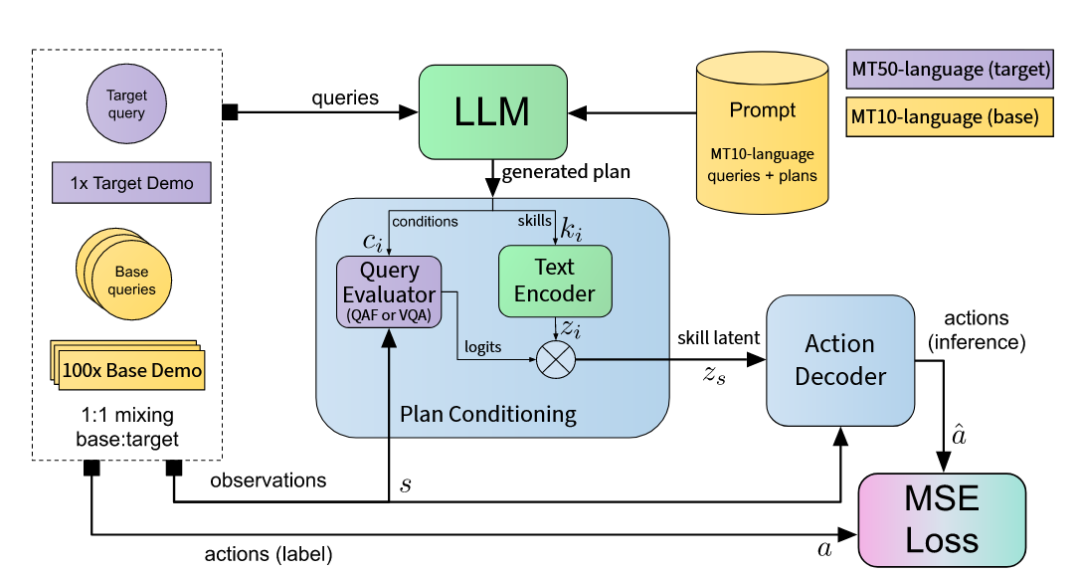
图27 PCBC框架[38]架构图
为提升机器人在多样化多任务场景中的学习效率和泛化能力,RT-H 框架[39]提出了一种利用语言构建动作层次结构的方法。其核心思想是在高阶任务指令和底层机器人动作之间,增加一个中间预测层,即“语言动作”(如“手臂前移”)。在执行时,模型首先预测出当前的语言动作,然后再结合任务、观察和预测的语言动作来生成最终的精确控制指令。
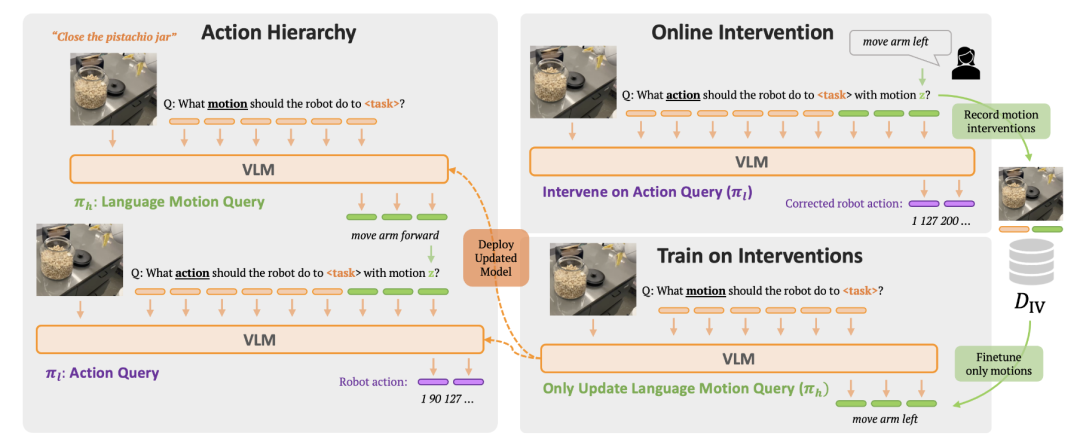
图28 RT-H框架[39]架构图
VOYAGER [40]是一个由大型语言模型(LLM)驱动的具身智能体,用于在像《我的世界》这样的开放世界中进行无人工干预的终身学习。该智能体的核心由三部分构成:一个自动提出新任务的自动课程模块,一个不断增长的、用于存储成功代码的技能库,以及一个通过整合环境反馈、代码执行错误和自我验证来反复修正和完善代码的迭代式提示机制。
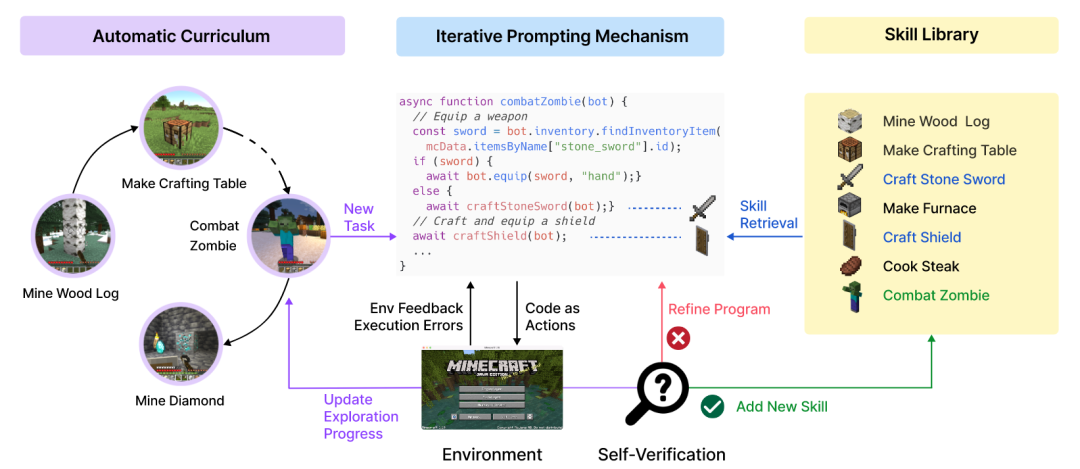
图29 VOYAGER框架[40]架构图
RoboMatrix [41]提出了一个“以技能为中心”的层次化框架。该方法的核心思想是从各种复杂任务中提炼出可复用的“元技能”(如“移动到物体”),并以此构建一个技能库。当面对新任务时,框架的高层调度模块会利用大型语言模型(LLM)将任务分解为一系列元技能的组合,随后由中层的技能模块调用一个统一的视觉-语言-动作模型来执行这些技能。
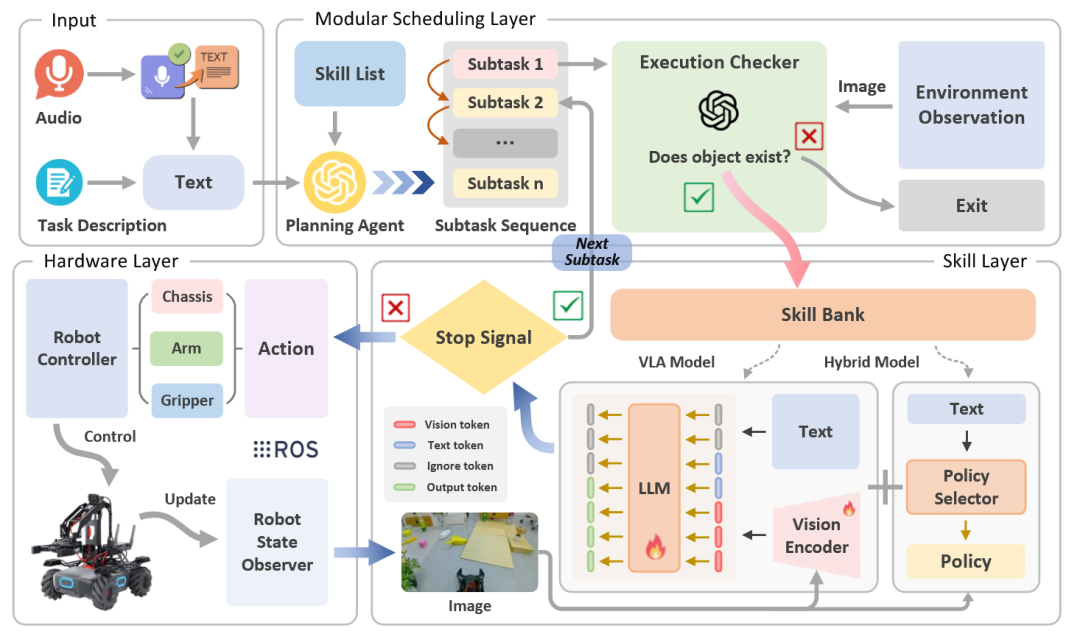
图30 RoboMatrix框架[41]架构图
AutoGPT+P 框架[42]首先构建一个基于“可供性”的场景表示,来明确场景中每个物体所能支持的动作。在此基础上,一个大型语言模型(LLM)充当决策中心,根据任务需求和当前信息,从一系列工具中进行选择:当条件完备时,调用LLM+P工具进行规划;当发现物体缺失时,则调用“探索”或“建议替代品”等工具寻找替代方案或搜索环境。
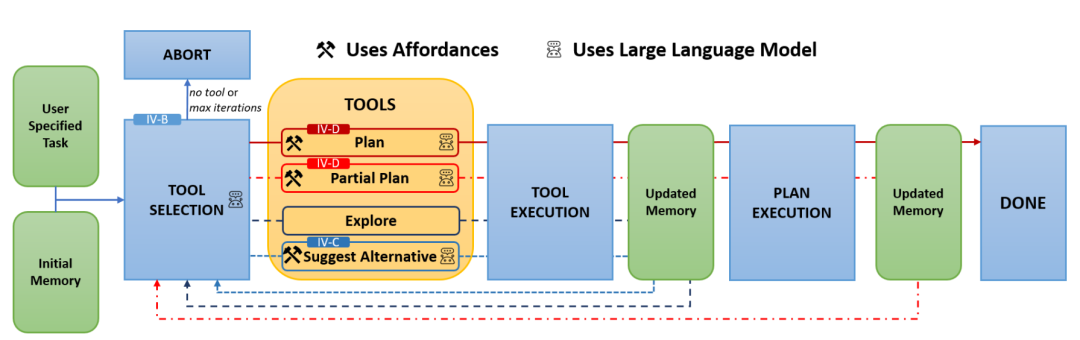
图31 AutoGPT+P框架[42]架构图
这种方法保证了规划的可执行性,简化了LLM的任务。但其局限性也很明显:如果技能库不够全面或粒度太粗,会限制LLM规划的灵活性和创造性,使其无法应对技能库之外的新情况。
2.2.4 基于外部工具的能力扩展
就像人类会使用计算器来解决复杂的数学题一样,让大模型学会使用外部“工具”,可以极大地扩展其能力边界。工具学习(Tool Learning)允许大模型在规划过程中意识到自身信息不足时,能够主动生成指令,去调用外部的、能解决特定问题的资源(如搜索引擎、计算器、专业API等),并将工具返回的结果整合到后续的推理中。
ReAct 框架[43]为大型语言模型(LLM)引入了一种协同推理与行动以解决复杂任务的方法。其核心方法是提示 LLM 生成交错的推理轨迹(思考)和特定于任务的动作序列。这种方法创建了一种动态关系:推理帮助模型追踪和调整行动计划,而行动则允许它与外部来源(如维基百科 API)交互,以收集信息来为推理过程提供依据。通过将外部反馈整合到其推理步骤中,ReAct 克服了仅推理方法中常见的事实幻觉和错误传播等问题。
AUTOACT 框架[44]实现了问答任务的自动化智能体学习,它不依赖大规模标注数据。该过程始于一个META-AGENT(元智能体),它通过自我指导过程扩充一小组种子示例。其关键是“劳动分工”策略,即META-AGENT首先合成自己的规划轨迹,然后“分化”成三个专门的子智能体:PLAN-AGENT(规划)、TOOL-AGENT(工具)和REFLECT-AGENT(反思),从而能够在新任务上有效协作。
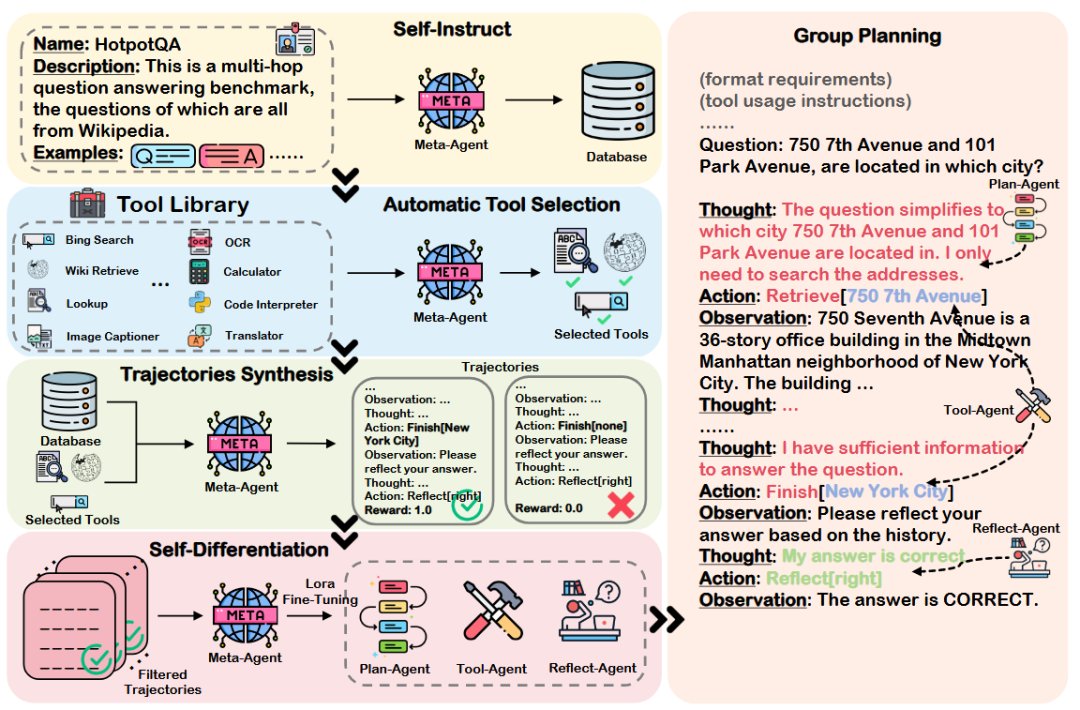
图32 AUTOACT框架[44]架构图
工具学习让大模型摆脱了自身静态知识的束缚,使其能解决更复杂、更需要实时信息的任务。但它也可能增加推理的延迟,并且系统的性能开始依赖于外部工具的可用性和可靠性。
2.3 基于多模态感知的规划
当我们走进一个陌生的厨房想找个苹果时,需要处理各种信息:我们看到台面上的水果篮(视觉),听到冰箱的嗡嗡声(听觉),并结合我们的常识(苹果通常在水果篮或冰箱里),最终规划出“先检查水果篮,如果没有,再去打开冰箱”的行动。
LLM本质上是基于文本训练的,这使得它们在直接处理和理解来自物理世界的、复杂的、实时的多模态感知数据(如视觉、深度、音频等)时面临固有困难。如何有效地桥接多模态感知与LLM的规划能力,实现从“看到”到“做到”的流畅转换,是当前具身规划领域需要解决的关键问题。
2.3.1 分阶段的视觉-语言规划
一种直接的思路是分工协作。即先将原始的多模态感知数据交由一个专门的视觉模型(如物体检测器)或视觉语言模型(VLM)进行处理,提取出高层次、结构化的场景表征(如“一个红色杯子在桌上”的文本描述),再将这些“净化”后的信息输入给LLM进行更高层次的任务规划。
Socratic Models (SMs) 框架[45]通过多模态提示让多个预训练模型(如VLM和LM)在无需额外微调的情况下进行信息交换,组合出新的多模态能力。一个关键应用是将视频理解问题重新构建为阅读理解问题,即先将视频内容转化为语言形式的“世界状态历史”,再由LM进行问答。
DaDu-E 框架[46]重新思考了大型语言模型(LLM)在机器人计算流程中的角色。该框架采用一个轻量级LLM,并为其配备一套封装好的机器人技能指令集、一个反馈系统和记忆增强模块。这种设计使得机器人能够主动感知和适应动态变化的环境,在保持良好性能的同时优化计算成本。
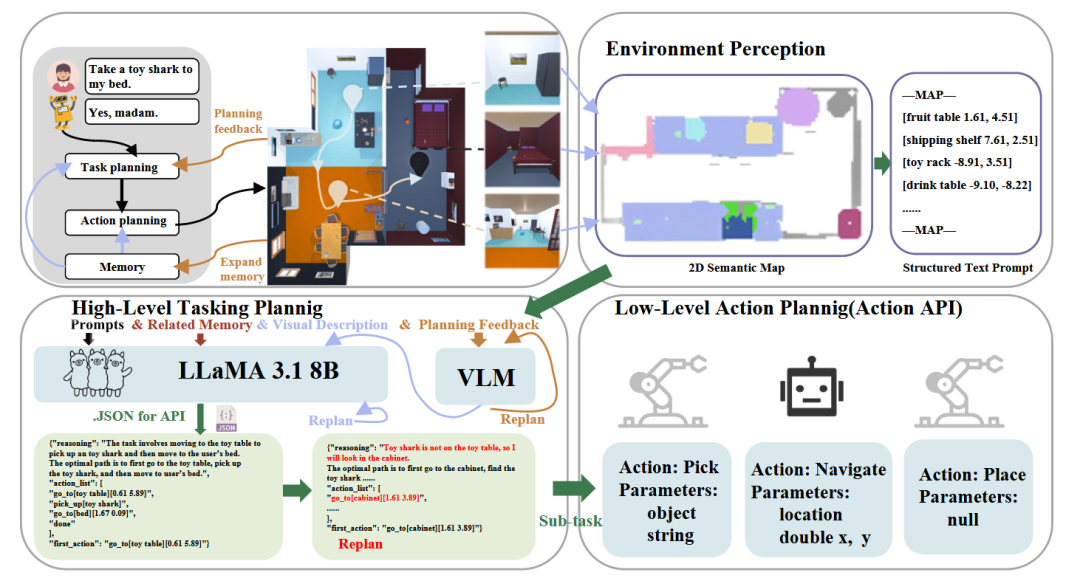
图33 DaDu-E框架[46]架构图
这种策略解耦了复杂的感知和高级的规划,使得系统搭建更灵活,能利用各自领域最强大的模型。但缺点是在信息从视觉到文本的压缩过程中,可能会丢失关键的细节(如物体的精确空间关系),导致“认知”与“现实”脱节。
2.3.2 端到端的多模态规划模型
与分工协作不同,另一种思路是采用端到端的一体化多模态大模型(M-LLM),如GPT-4V、PaLM-E等。这类模型在架构层面就实现了视觉与语言信息的深度融合,能够直接将图像、视频等多模态数据作为输入,在模型内部一体化地完成从感知理解到规划生成的整个流程。
PaLM-E [47]是一个具身多模态语言模型,它将现实世界的连续传感器模态(如图像、状态估计)直接编码成与文本符号相同维度的“多模态语句”,然后让大型语言模型进行处理,从而能够端到端地处理多种具身推理任务。
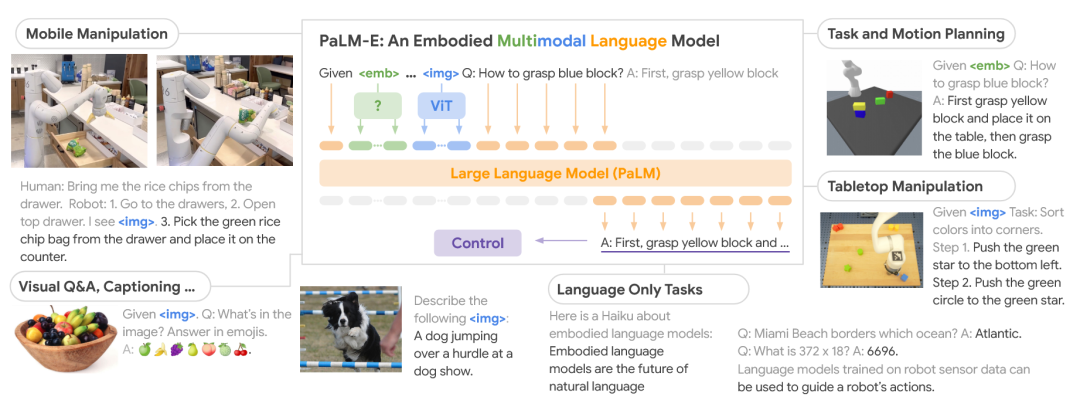
图34 PaLM-E框架[47]示意图
EmbodiedGPT [48]是一个端到端的多模态基础模型。研究者首先构建了EgoCOT大规模具身规划数据集,然后通过前缀微调的方式,将一个7B参数的LLM适配到该数据集上。框架引入的embodied-former模块能够从LLM生成的规划查询中提取任务相关特征,形成从高层规划到低层控制的闭环。
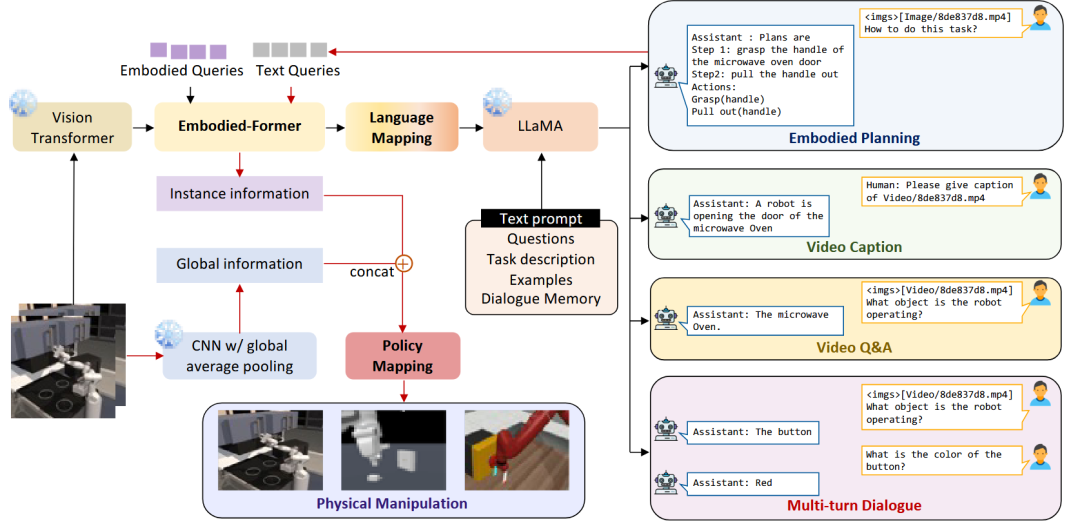
图35 EmbodiedGPT框架[48]架构图
CogVLM [49]是一种开源的视觉语言基础模型,它通过一个可训练的视觉专家模块来连接固定的预训练语言模型和图像编码器,从而实现了视觉和语言特征的深度融合。与传统的“浅层对齐”方法不同,CogVLM在语言模型的每一层都增加了一个视觉专家模块,在多个经典的跨模态基准测试中都取得了不错的性能。
WorldGPT[50]是一个基于多模态大型语言模型(MLLM)构建的通用世界模型,它通过分析数百万个跨领域的视频来理解世界动态。为处理专业场景和长序列任务,WorldGPT集成了新颖的认知架构,融合了记忆卸载、知识检索和上下文反思等功能。
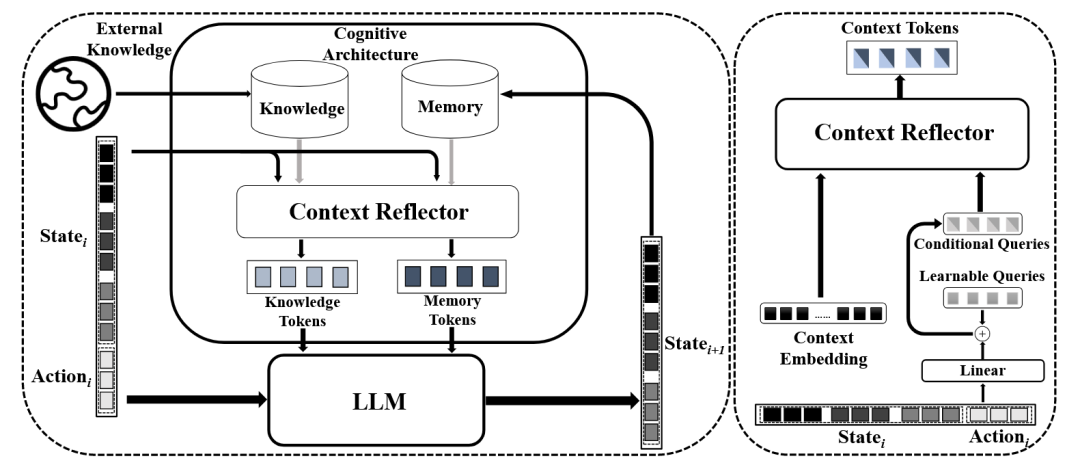
图36 WorldGPT框架[50]架构图
Octopus [51]是一个具身的视觉语言编程器,它通过生成可执行代码来连接高级规划与底层操作。为训练Octopus,研究者首先构建了OctoVerse环境套件,其中包含了为视觉代码生成器量身定制的各种任务。此外,该研究还引入了“基于环境反馈的强化学习”(RLEF)的训练方案,利用智能体在模拟器中获得的反馈来优化模型。
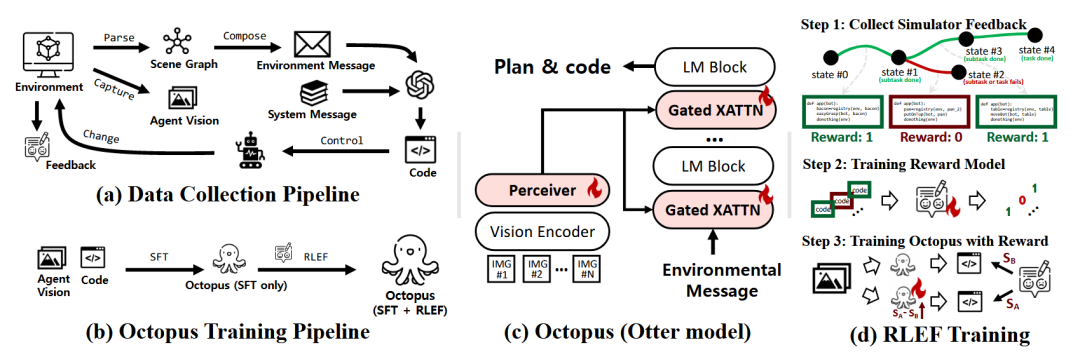
图37 Octopus框架[51]数据收集与模型训练流程图
端到端的方式理论上可以最大程度地保留原始信息,减少信息在模块间传递时的损失。但挑战在于,这类一体化模型通常参数量巨大,对训练数据和计算资源的要求很高,且其内部的决策过程更加“黑箱”,给调试和可解释性带来了更大的困难。
2.4 动态环境中的规划适应
我们在用一个新买的烤箱烤蛋糕时,会按照说明书设置时间和温度。但中途透过玻璃门发现蛋糕表面上色太快,可能会烤糊,于是我们会立即做出调整:降低温度或提前结束烘烤。这种根据实时反馈动态调整计划的能力,是智能行为的关键。
在多轮交互或长序列任务中,真实世界是动态且充满不确定性的。一个动作可能无法达到预期效果,或者环境自身发生了变化。如何让基于LLM的智能体具备持续学习和动态适应的能力,及时地将新情况纳入考量并调整规划,是避免“一条道走到黑”导致任务最终失败的核心挑战。
2.4.1 基于即时反馈的动态重规划
最直接的适应方式,就是错了就改。通过实施基于即时反馈的动态重规划机制,系统可以持续地监测智能体的行动效果和环境状态。一旦检测到实际结果与预期出现偏离(例如,机器人想抓取杯子却失败了),系统会立即捕获这一反馈信息,并更新给大模型,触发其基于新的上下文重新生成后续计划。
DOREMI 框架[52]包含一个负责检测的Detector(VLM)和一个负责恢复的Recoverer(LLM)。Detector通过比对计划与真实视觉观察,判断是否存在不一致。一旦检测到,Recoverer便会启动,生成一个子计划来纠正当前状态,之后再继续执行原计划。
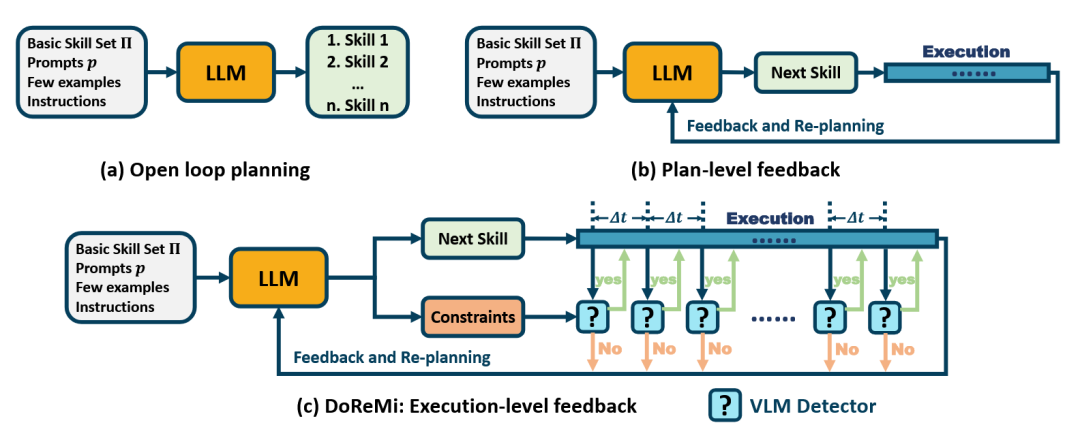
图38 DOREMI框架[52]架构及其与其他规划方法对比图
REPLAN 框架[53]利用VLM进行两阶段推理:在动作失败后,VLM首先通过对比执行前后的图像来生成关于失败原因的自然语言“解释”。随后,这个解释被反馈给一个基于LLM的规划器,规划器会根据这个新的情境信息来生成一个修正动作或全新的计划。
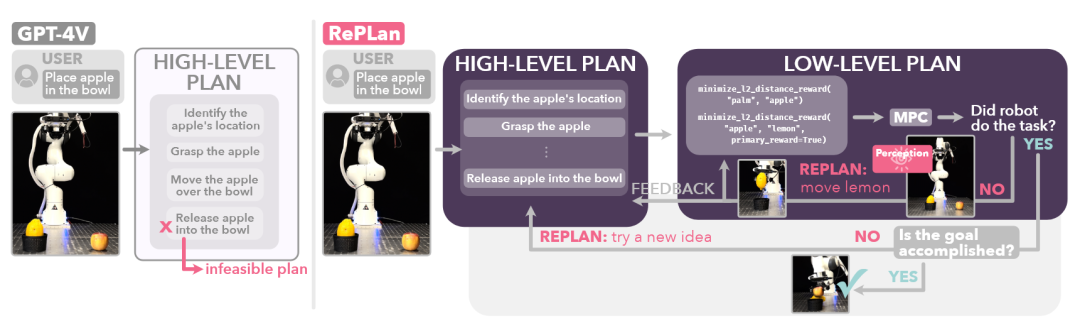
图39 REPLAN框架[53]示意图
ReplanVLM 框架[54]通过引入一个双重错误校正机制,提升VLM在机器人任务规划中的可靠性和适应性。该框架包含一个“内部错误校正机制”(在任务执行前审查计划和代码)和一个“外部错误校正机制”(在任务执行后通过对比图像来判断任务是否成功)。一旦任一机制检测到错误,系统就会触发重新规划流程。
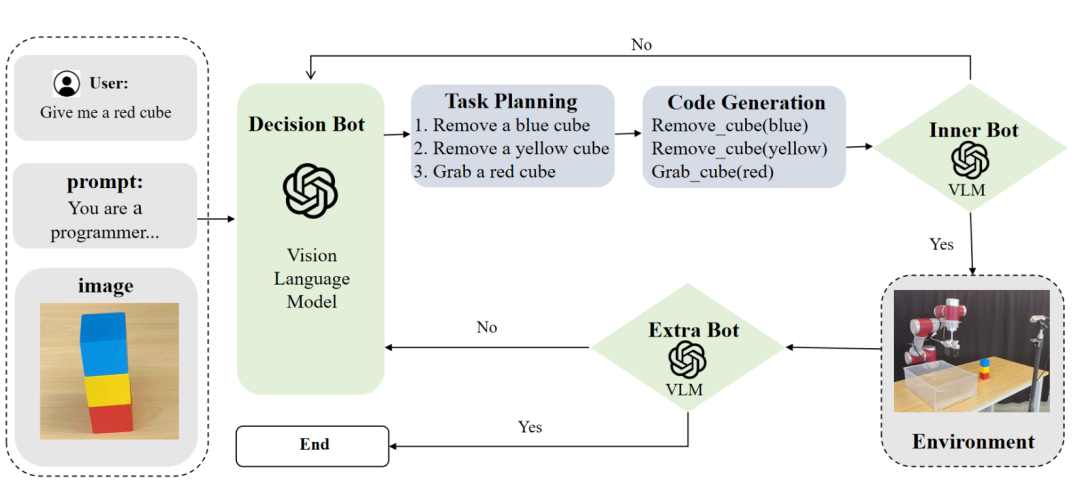
图40 ReplanVLM 框架[54]示意图
LLM³ 框架[55]将一个LLM定位为任务与运动规划(TAMP)流程的核心。LLM首先一次性生成一个完整的计划,该计划同时包含高层级的符号动作和底层的连续参数。随后,计划被送入运动规划器进行验证;如果某个动作失败,系统会生成一个分类后的失败反馈。在下一次迭代时,LLM会接收包含失败历史的新提示,通过推理失败原因来生成一个经过修正的计划。
这种实时重规划策略能使系统对偏差做出迅速响应,避免错误累积。但挑战在于,对于长序列任务,反复的反馈和重规划会导致LLM的上下文窗口变得极长,且错误的反馈信息也可能误导模型,使其陷入反复试错的循环。
2.4.2 基于自我反思的规划修正
除了依赖外部的即时反馈,还可以引导模型进行自我反思(Self-Reflection)。通过精心设计一系列结构化的提示,不仅可以向LLM传递任务指令,更能够引导其在规划或执行的特定阶段,主动审视其先前的输出、评估行为的后果,并基于这些反思来调整后续步骤。
为解决LLM生成的机器人计划在物理世界中常常因不满足前提条件而失败的问题,一项研究提出了一种“纠正性重提示”[56]的闭环规划策略。其核心方法是,当机器人执行某个动作失败时,系统会从环境中捕获到一个描述失败原因的“前提条件错误”信息。接着,这个错误信息会被嵌入到一个新的提示中,再次请求LLM生成一个具有针对性的纠正动作。
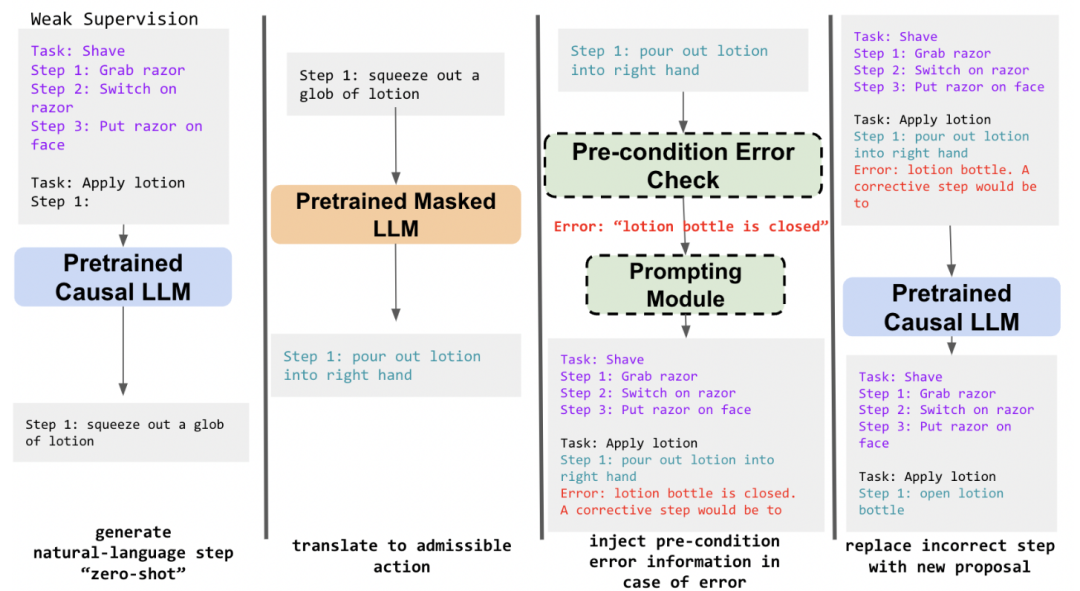
图41 “纠正性重提示”框架[56]架构图
REFINER 框架[57]通过一个“生成器”与一个“批评家”之间的互动循环,提升语言模型的推理能力。首先由生成器模型产出解决任务的中间推理步骤,随后一个经过专门训练的批评家模型会对其进行评估,并提供结构化的文本反馈。最后,生成器模型会将这个具体的错误反馈连同原始问题一起作为新的输入,来迭代地修正自己的推理过程。
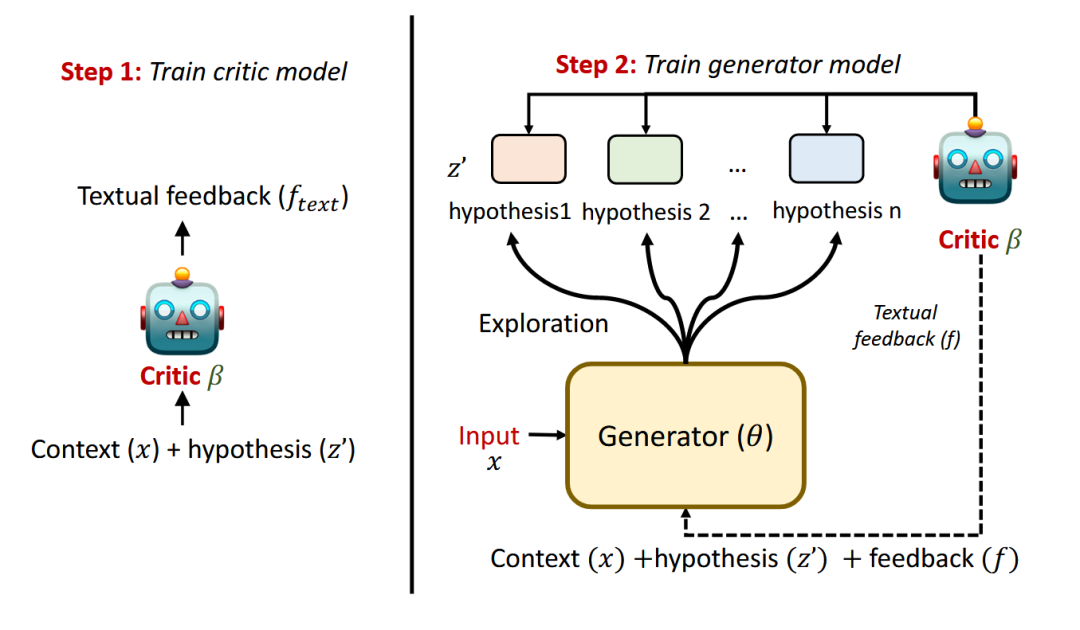
图42 REFINER框架[57]架构图
SelfCheck [58]提出了一种让大型语言模型在零样本场景下,对自身分步推理进行检查的框架。该方法并非直接让模型判断对错,而是将检查过程分解为“目标提取”、“信息收集”、“步骤重新生成”和“结果比较”四个阶段。通过这种“生成再比较”的策略,该框架能有效识别推理错误。
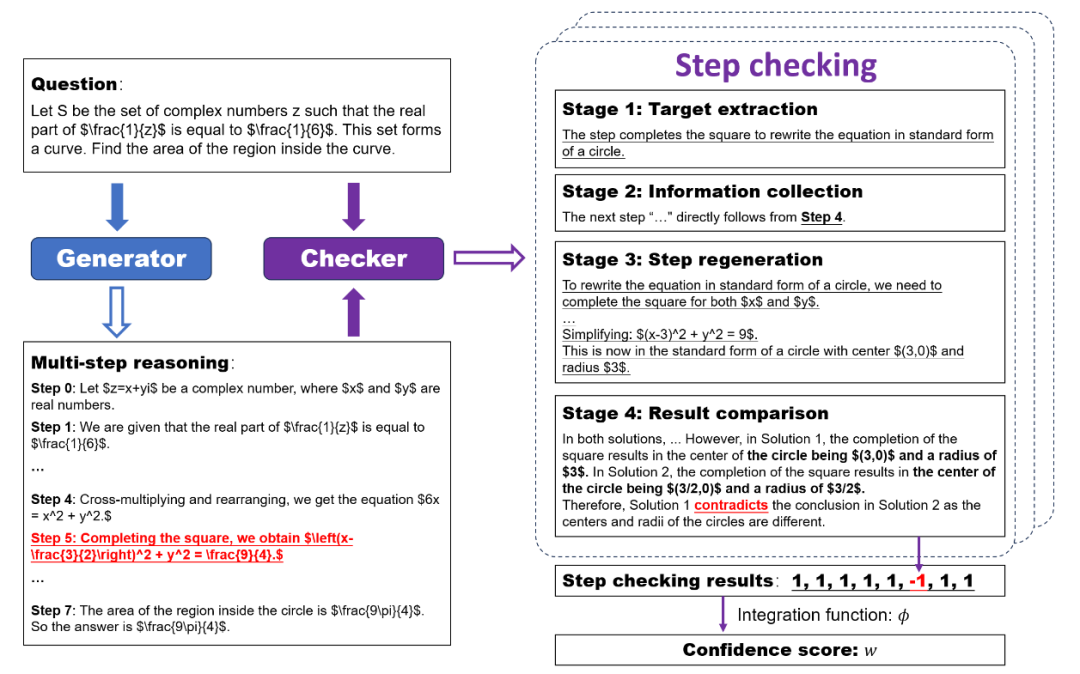
图43 SelfCheck框架[58]架构图
这种方法的优势在于不依赖于对大模型本身进行重新训练,具有很高的灵活性。但高效且通用的反思式提示设计本身具有相当大的挑战性。
2.4.3 基于强化学习的策略优化
更进一步,我们可以让模型从与环境的持续交互和历史经验中自主学习。这就是将强化学习(RL)的原理与大型语言模型相结合的思路。在这种框架下,LLM被视为一个决策代理,其生成的规划或动作会得到一个奖励或惩罚信号(如任务成功加分,失败扣分),模型通过不断试错来最大化长期累积奖励,从而迭代地优化其行为策略。Octopus [51]框架在训练视觉语言编程器时,就引入了“基于环境反馈的强化学习”(RLEF)方案,它利用智能体在模拟器中执行生成的代码后获得的反馈来直接优化模型。
强化学习使得模型能直接从与物理世界的交互中学习和演进,是实现真正自主智能的理想路径。但其主要挑战在于,通常需要大量的交互数据才能取得良好效果,且奖励函数的设计(如何定义“好”与“坏”)以及训练过程的稳定性都是公认的难题。
2.5 多智能体协同规划
想象一个团队在厨房里准备一顿大餐。有人负责洗菜切菜,有人负责烹饪,还有人负责摆盘。他们需要不断沟通(“洋葱切好了吗?”),合理分配任务,并解决冲突(比如只有一口锅,需要协调使用顺序),才能高效地完成这顿复杂的晚餐。
当任务的复杂度超出了单个智能体的能力范围时,就需要多个智能体协同工作。多智能体协同规划需要解决如何让基于LLM的智能体群体进行有效沟通、合理分工、协调行动并解决冲突,以共同完成一个宏大目标。
一些工作已经开始探索这个方向。为实现对异构多机器人团队的自主任务规划,SMART-LLM 框架[59]利用LLM分阶段将高级指令转化为具体执行计划。它首先进行“任务分解”,然后是“联盟形成”以决定由单个机器人还是团队来执行,最后在“任务分配”阶段为每个子任务精确指派机器人并生成可执行代码。
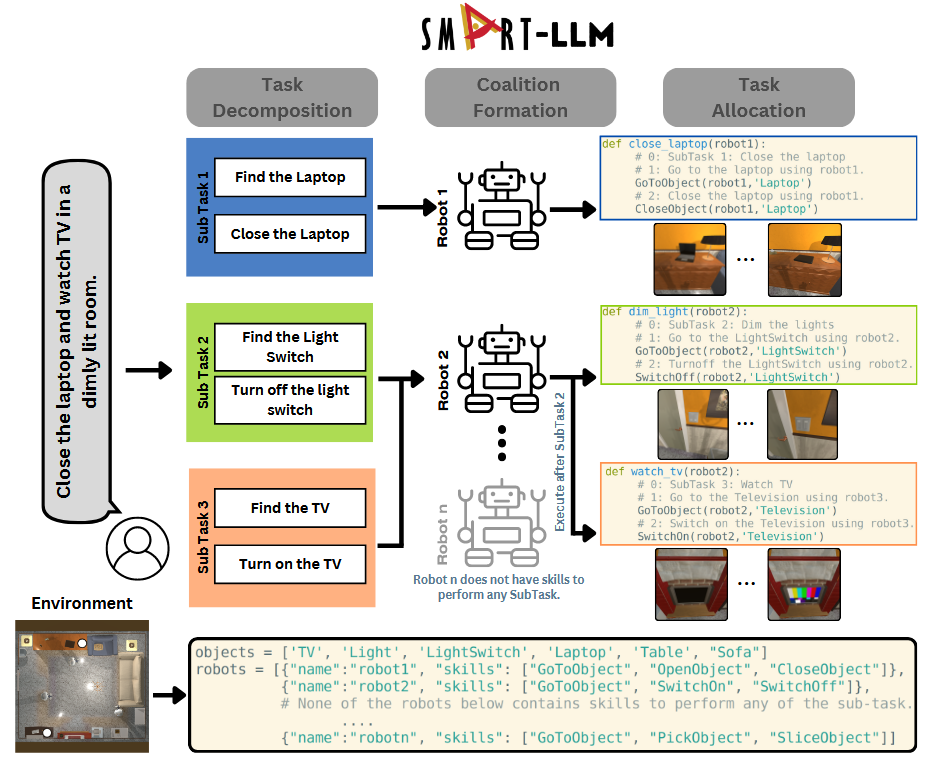
图44 SMART-LLM框架[59]架构图
LLM-MARS [60]提出了一种多机器人控制与交互架构,其核心是利用单个LLM并为其配备多个可切换的、经过轻量化微调的LoRa适配器。在行为生成方面,系统使用第一个经过行为树样本微调的适配器,将操作员的自然语言指令直接转换成一个结构化的行为树。在人机交互方面,当人类提问时,系统会切换到第二个为问答任务微调的适配器,生成关于其行为和状态的自然语言回答。
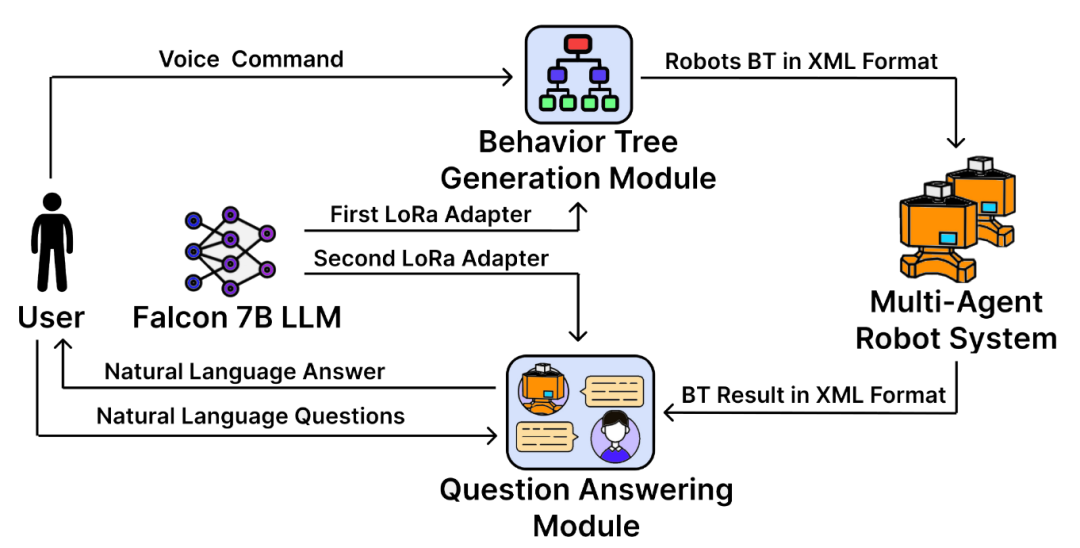
图45 LLM-MARS框架[60]架构图
为应对去中心化、通信受限的多智能体协作挑战,CoELA 框架[61]构建了一个受认知科学启发的模块化智能体架构。该架构包含感知、记忆、通信、规划和执行五大模块,其规划与沟通能力由LLM驱动,以实现高效的协同作业。
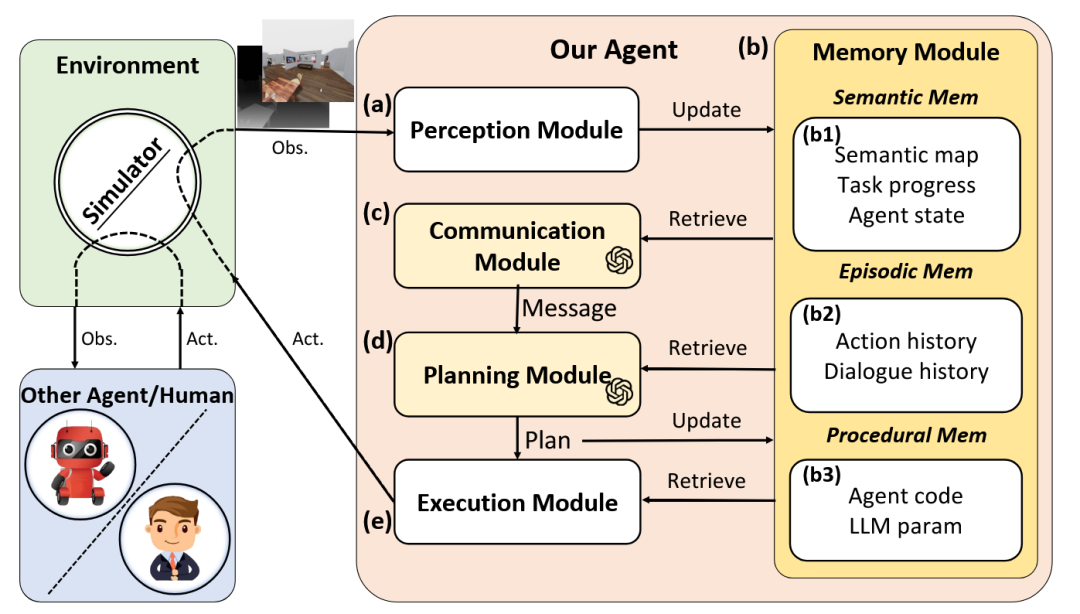
图46 CoELA框架[61]架构图
为解决多机器人任务中复杂的依赖关系,DART-LLM 框架[62]提出了一种依赖感知的任务分解与执行方法。其核心是利用LLM将自然语言指令分解为子任务,并显式地使用有向无环图(DAG)来对这些子任务间的依赖关系进行建模。在执行流程中,系统严格按照DAG定义的顺序来执行任务,确保需要前置任务完成的步骤能被正确协调。
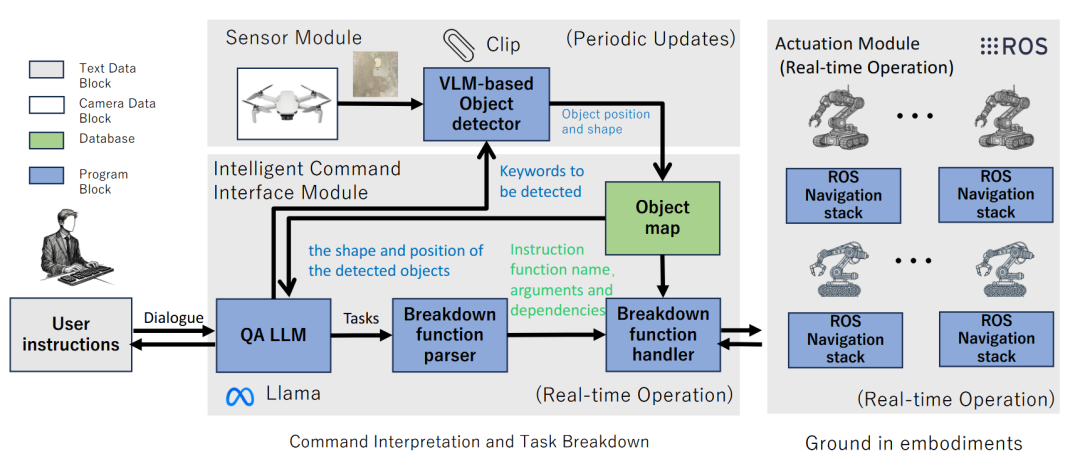
图47 DART-LLM框架[62]架构图
利用LLM强大的自然语言能力,智能体之间可以使用更接近人类的、更灵活的方式进行通信和协商。但挑战也十分巨大,包括如何设计高效的通信协议以避免显著的系统延迟,如何建立公平的任务分配和冲突解决机制,以及如何确保去中心化决策的一致性等。
3 支撑规划的数据与评测
如果说模型和算法是“引擎”,那么数据和评测就是驱动引擎运转的“燃料”和检验其性能的“跑道”。LLM在具身规划领域的进展,很大程度上依赖于高质量、多样化的训练数据以及全面、标准化的评测基准。因此,系统性地构建能够支撑LLM训练、微调及评估的数据资源和测试平台,是推动该领域发展的基石。
3.1 基于数据采集的基准构建
要教一个孩子认识世界,我们需要给他看各种各样的图画书(仿真数据),也要带他去公园、动物园亲身体验(真实世界数据),还要通过对话问答来检验他的理解能力(交互数据)。同样,构建具身规划的基准数据集,也需要通过多种方式收集能够全面反映其能力需求的数据。
3.1.1 仿真环境中的数据采集
在已有的成熟仿真平台(如AI2-THOR, Habitat等)或专门自建的虚拟环境中,通过程序化自动生成或结合人类演示的方式,可以系统性地收集智能体与环境的交互数据、规划轨迹以及对应的多模态观测数据。
为了对具身智能体在日常家务任务中的能力进行基准测试,研究人员提出了一个包含100种活动的BEHAVIOR基准[63]。其核心创新在于BEHAVIOR领域定义语言(BDDL),这是一种基于谓词逻辑的语言,它通过定义任务的初始和目标条件,使得可以程序化地生成大量多样的任务实例。为了提供人类表现的参照,该基准还包含了500个在虚拟现实(VR)中收集的人类演示。
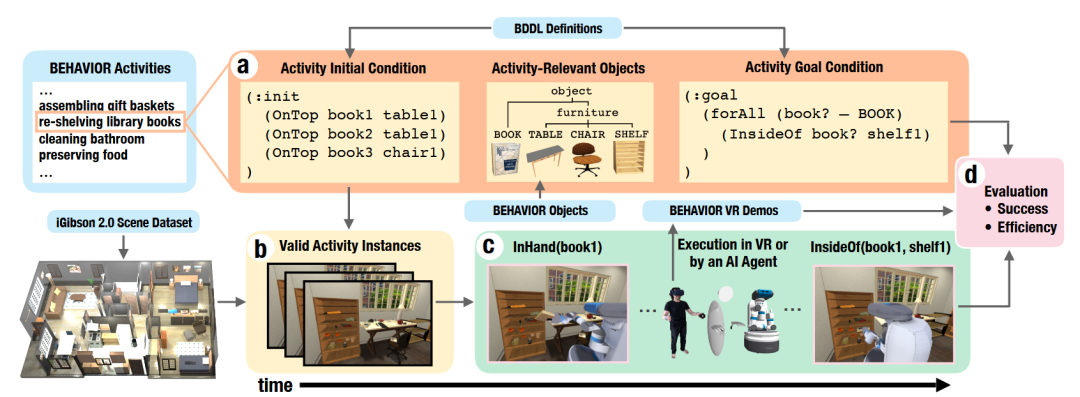
图48 BEHAVIOR基准数据集[63]示意图
BEHAVIOR-1K [64]提出了一个以人类真实需求为核心的大规模具身智能基准。它通过广泛调查确定了1000项日常活动,并用BDDL语言进行形式化定义。为支持这些活动,该工作开发了OMNIGIBSON全新高保真模拟器,能模拟流体、可变形物体和热效应等复杂物理现象。

图49 BEHAVIOR-1k基准数据集[64]示意图
EMBODIEDBENCH [65]提出了一套全面的基准,用于评估由MLLM驱动的具身智能体。该基准的特点在于其分层和细粒度的评测设计,它包含了横跨四个不同环境的1,128个测试任务,并精心构建了六个能力导向的子集,用以分别考察智能体在常识推理、复杂指令理解、空间感知等方面的表现。
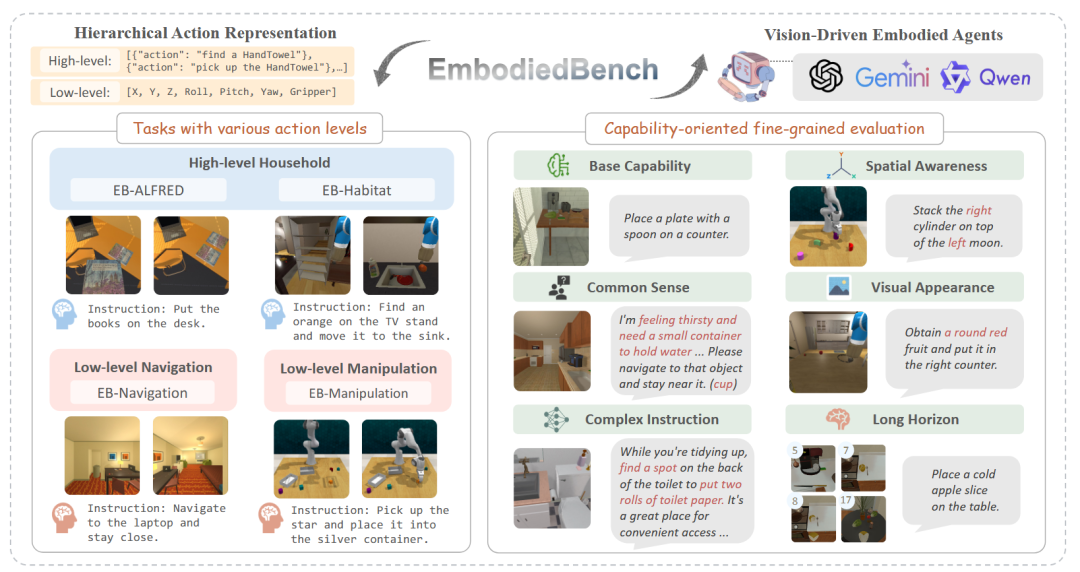
图50 EMBODIEDBENCH基准数据集[65]示意图
LIBERO [66]为机器人终身学习领域提供一个全新的基准,其核心方法是系统性地研究不同类型知识的迁移过程。为此,该工作设计了一个程序化的任务生成流程,能够从大规模人类活动数据集中提取行为模板,并结合PDDL语言来定义初始和目标状态,从而在Robosuite仿真器中创建出大量机器人操作任务。
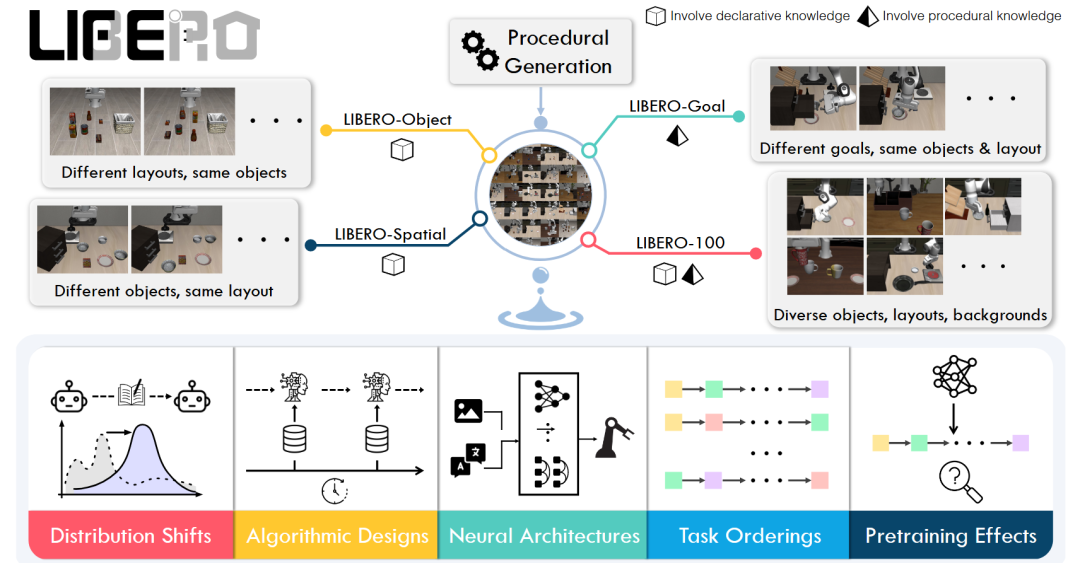
图51 LIBERO基准数据集[66]示意图
为解决现有视觉-语言基准在任务时长、组合性和状态变化方面与现实应用脱节的问题,ALFRED [67]提出了一种新的基准测试。其核心方法是,在AI2-THOR交互式仿真器中,构建一个包含超过2.5万条自然语言指令的数据集。ALFRED要求智能体在执行交互动作时,必须在第一人称的视觉输入上生成一个像素级的“交互掩码”来精确指定操作对象,这提升了任务的真实性和挑战性。
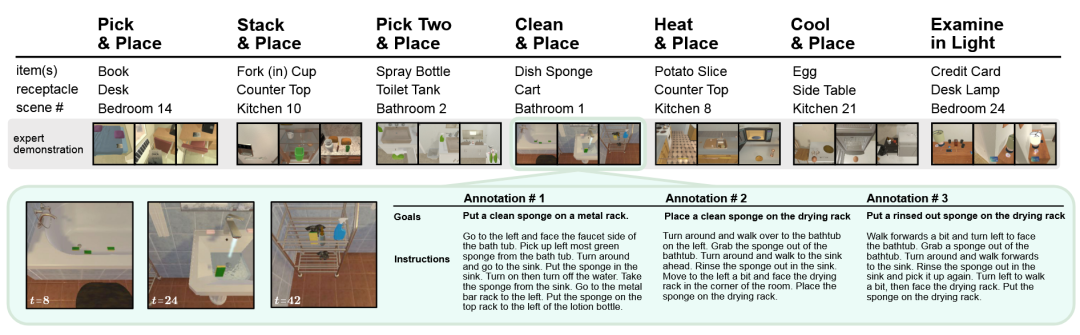
图52 ALFRED基准数据集[67]示意图
VirtualHome 项目[68]创建了一个用于模拟日常家庭活动的大规模知识库和仿真平台。研究者通过众包方式收集描述各种家庭活动的自然语言文本,并让众包人员使用一个图形化编程界面将其“翻译”成由原子动作构成的“程序”。在环境实现阶段,这些程序中最高频的原子动作被在Unity3D游戏引擎中实现,构建出一个名为VirtualHome的仿真器。
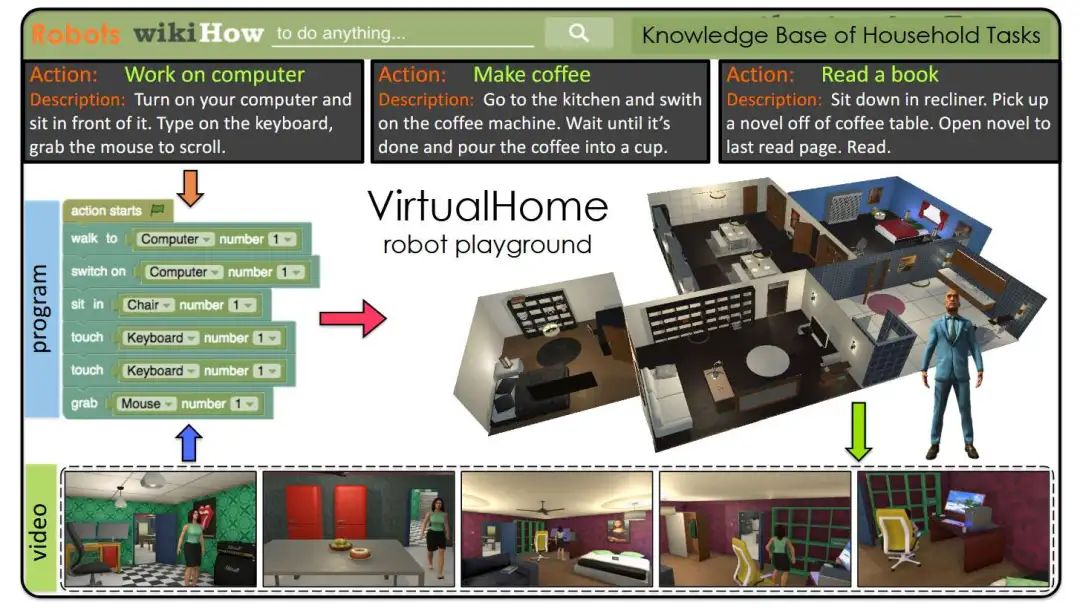
图53 VirtualHome基准数据集[68]示意图
仿真环境能够以较低的成本安全、可控地生成海量、多样化的数据。但它最大的挑战是“仿真到真实”(sim-to-real)的迁移差距,在仿真中表现优异的模型在真实世界中可能会“水土不服”。
3.1.2 真实世界中的数据采集
直接从真实的物理世界中提取和利用数据,对于训练和评估模型的现实落地能力至关重要。这通常涉及利用互联网上存在的大量第一视角视频(如Ego4D数据集),或真实机器人部署时产生的操作日志。
为实现让机器人通过观看人类演示来零样本学习新技能,GPT-4V(ision) for Robotics 框架[69]利用VLM作为“世界模型”。VLM分析人类演示视频和文本描述,生成一个抽象的任务计划,并直接将其“翻译”成调用机器人预设技能库的Python代码,展现了较好的零样本泛化能力。
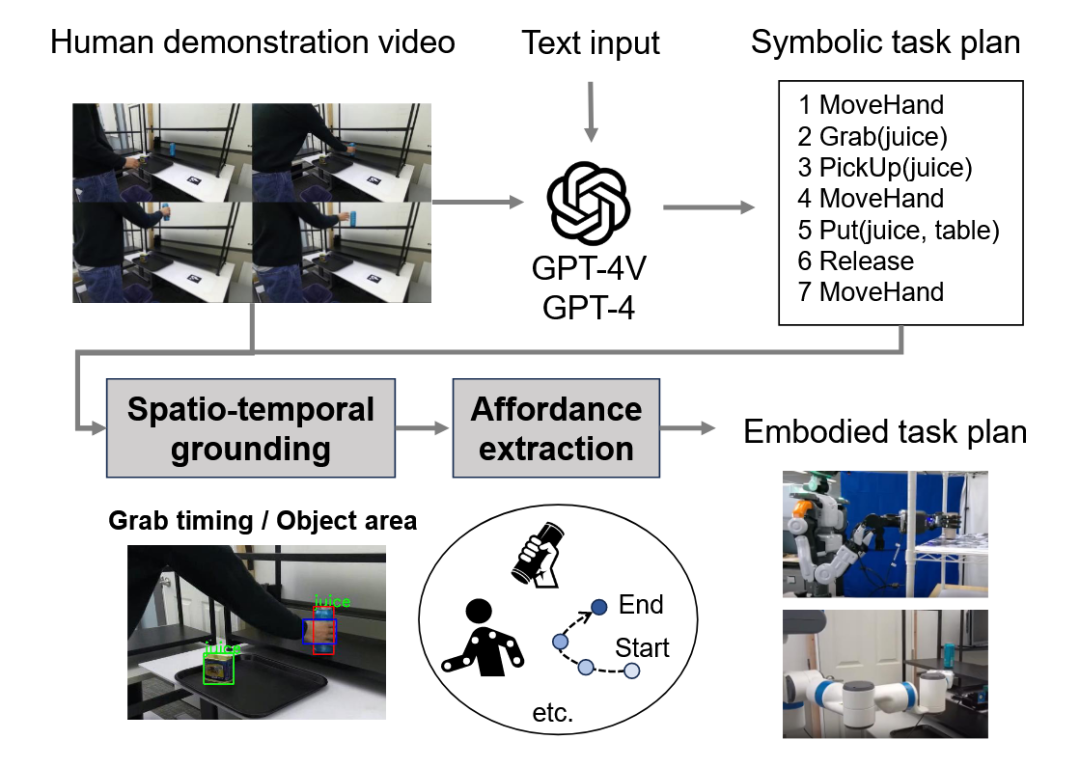
图54 GPT-4V(ision) for Robotics框架[69]示意图
EgoTaskQA [70]是一个面向第一人称视频的问答基准,它超越简单的动作识别,直接评估模型对人类任务的深层次理解,着重考察模型对动作间的因果依赖、物体状态变化等复杂逻辑的掌握程度。

图55 EgoTaskQA基准数据集 [70]示意图
面对现有视觉语言模型(VLM)评估大多集中于第三方视角的问题,EgoThink基准[71]被提出来专门评测模型从第一人称视角进行“思考”的能力。该基准的构建方法是,首先从第一人称视频中选取代表性片段,然后通过人工标注的方式创建与个人视角紧密相关的问答对。这些问答对被系统性地组织成六大核心能力,从而实现对模型能力的全面评估。

图56 EgoThink基准数据集[71]示意图
为了更深入地评估人机交互中的沟通能力,有研究构建了HandMeThat基准[72],专门处理人类指令中存在的模糊性。这项工作的核心方法要求机器人不仅要理解物体的物理状态,还要通过观察人类之前的动作来推断其社交意图和未言明的目标。该基准利用符号化模拟器和理性言语行为模型来自动生成多样化的任务场景和自然的模糊指令。

图57 HandMeThat基准数据集[72]的一条示例数据
这类数据能够最真实地捕捉到现实世界的复杂性和物理约束。但挑战在于,从非结构化的真实世界数据中准确、高效地提取出有用的、结构化的规划信息(如动作标签、因果关系)是一个极其困难的过程。
3.1.3 基于文本交互的数据采集
除了依赖复杂的视觉环境,还有一类基准通过更抽象的、通常是基于文本描述的环境或交互流程来生成数据。这类基准不直接处理高维视觉输入,而是更侧重于评估和训练大模型在任务理解、逻辑推理、规划分解、工具使用等核心认知能力上的表现。
为了系统性地评估大语言模型(LLM)在任务自动化方面的能力,有研究提出了TASKBENCH框架[73]。该框架将复杂的任务自动化过程分解为三个关键阶段:任务分解、工具选择和参数预测。为生成高质量的评测数据,研究者引入“工具图”来显式地建模工具间的复杂依赖关系,并采用一种“反向指令”策略,即先从图中采样出工具组合,再利用LLM逆向生成符合该组合的用户指令和任务步骤。
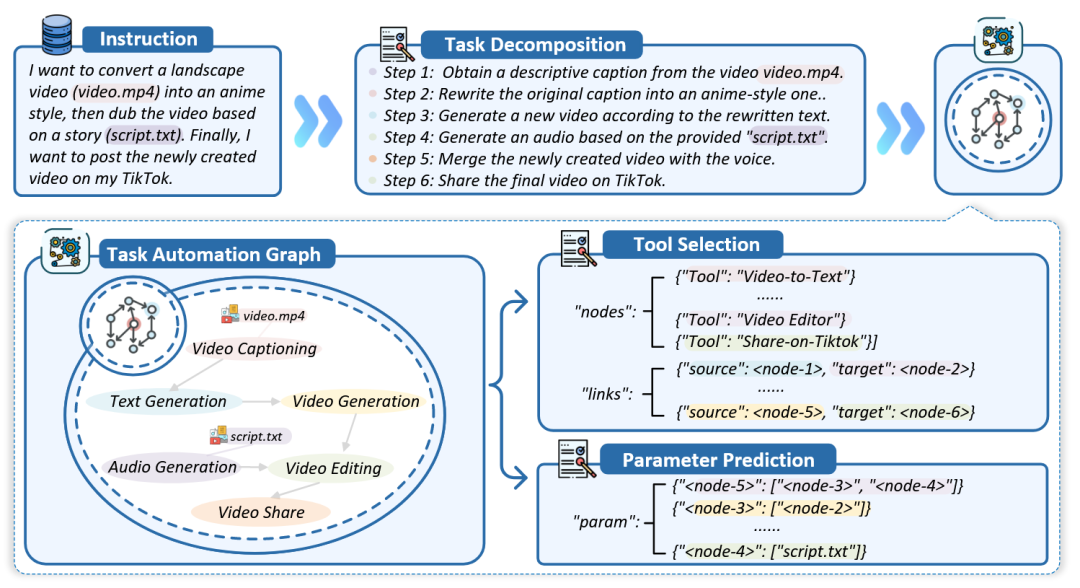
图58 TASKBENCH基准数据集[73]示意图
针对现有基准未能测试语言智能体与真人用户交互及遵守特定领域规则能力的不足,有研究提出了τ-bench[74]。该基准通过模拟一个由语言模型驱动的用户,与一个配备了领域特定API工具和政策指南的智能体进行动态、多轮的对话。其评估方法独到之处在于,它不评估对话路径本身,而是通过对比交互结束后后台数据库的最终状态与预设的唯一正确状态,来实现对任务成功与否的客观判断。

图59 τ-bench基准数据集[74]示意图
这种方法能够专注于评估模型的认知和推理能力,避免了复杂感知模块带来的干扰。但它的缺点是过于抽象,可能无法完全反映在与物理世界实际交互时会遇到的挑战。
3.2 基于数据合成的基准构建
当我们想训练一个模型来识别各种各样罕见的猫,但网上找不到足够的照片时,一个可行的办法是利用生成模型(如Stable Diffusion)来自动“画”出成千上万张不同品种、不同姿态的猫的图片,从而扩充训练集。
同样,除了直接收集“真实”数据外,研究者们也开始探索利用模型来自动地、程序化地生成新的、多样化的规划训练数据。这种“数据合成”方法,可以针对性地创造出大量用于训练特定技能或罕见场景的实例,从而有效补充现有数据集的不足。
为解决大语言模型智能体训练中,人工设计环境和任务成本高昂且多样性不足的问题,AGENTGEN框架[75]利用LLM来全自动地生成多样化的环境和规划任务。在任务生成阶段,它提出一种“双向演化”方法,即让LLM以初始任务为种子,通过增减约束来同时向更简单和更困难两个方向演化,从而构建出一个难度曲线平滑的任务集。
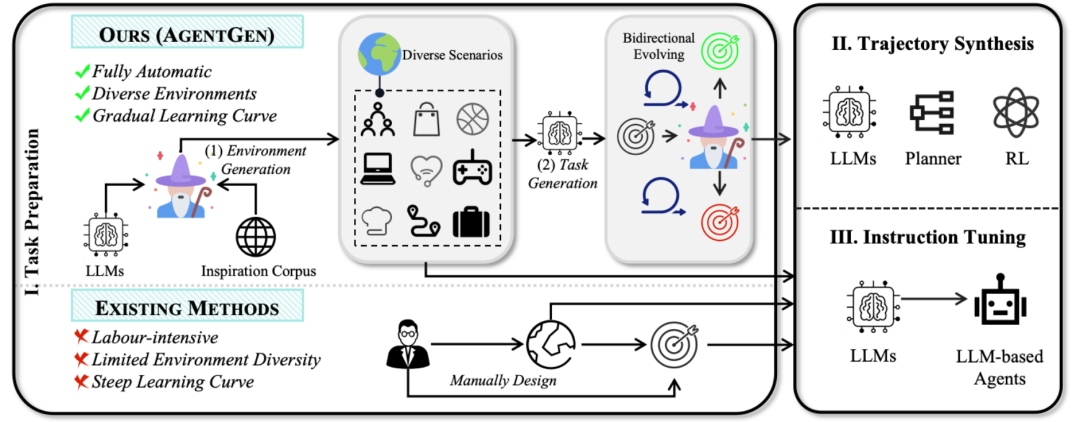
图60 AGENTGEN框架[75]架构图
这种方法能够以较低的成本海量生成数据,特别适用于弥补现有数据集中罕见或长序列场景的不足。但其主要风险在于,自动合成的数据可能与真实世界的内在复杂性和分布存在偏差,过度依赖合成数据可能会降低模型在真实场景中的性能。
结语
这篇笔记系统地梳理了具身规划领域从经典的符号方法,到当前由大模型驱动的技术演进之路。我们回顾了经典方法如何为该领域奠定理论基石,也剖析了LLM与MLLM如何通过其在推理、知识和多模态理解方面的能力,为打破传统方法的瓶颈带来新的机遇。
当前的研究正从多个维度展开:通过提示工程、监督微调和代码生成等手段应对长序列规划的推理难题;通过融合场景图、注入领域知识、运用技能库和外部工具等方法来打破模型与物理世界之间的“知识壁垒”;通过模块化与端到端结合的思路应对多模态感知的挑战;并通过即时反馈和自我反思的机制提升模型在动态环境中的适应能力。
展望未来,具身规划领域依然面临诸多深刻的挑战,其中包括系统的安全性与可解释性、终身学习与持续适应的能力、物理常识的深度接地,以及如何构建真正有效的泛化能力评测体系等,这些都是领域内研究者正在努力探索的方向。
从经典方法的严谨逻辑,到大模型驱动的认知探索,具身规划正处在一个激动人心的快速发展时期。我们有理由相信,随着算法、数据和算力的不断突破,那个能够在物理世界中从容、智能地思考、行动和交互的通用具身智能体,正从一个远大的构想,向着可以触及的未来不断迈进。
参考文献列表
[1] Fikes, R. E., & Nilsson, N. J. (1971). STRIPS: A new approach to the application of theorem proving to problem solving. Artificial intelligence, 2(3-4), 189-208.
[2] Aeronautiques, C., Howe, A., Knoblock, C., McDermott, I. D., Ram, A., Veloso, M., … & Sun, Y. (1998). Pddl| the planning domain definition language. Technical Report, Tech. Rep.
[3] Gerevini, A., & Long, D. (2005). Plan constraints and preferences in PDDL3. Technical Report 2005-08-07, Department of Electronics for Automation, University of Brescia, Brescia, Italy.
[4] Vladimir, L. (2008). What is answer set programming. In Proc. Natl. Conf. Artif. Intell (Vol. 3, pp. 1594-1597).
[5] Jiang, Y. Q., Zhang, S. Q., Khandelwal, P., & Stone, P. (2019). Task planning in robotics: an empirical comparison of pddl-and asp-based systems. Frontiers of Information Technology & Electronic Engineering, 20, 363-373.
[6] Coles, A., Coles, A., Olaya, A. G., Jiménez, S., López, C. L., Sanner, S., & Yoon, S. (2012). A survey of the seventh international planning competition. Ai Magazine, 33(1), 83-88.
[7] Srinivas, A., Jabri, A., Abbeel, P., Levine, S., & Finn, C. (2018, July). Universal planning networks: Learning generalizable representations for visuomotor control. In International conference on machine learning (pp. 4732-4741). PMLR.
[8] Zhu, Y., Tremblay, J., Birchfield, S., & Zhu, Y. (2021, May). Hierarchical planning for long-horizon manipulation with geometric and symbolic scene graphs. In 2021 IEEE International Conference on Robotics and Automation (ICRA) (pp. 6541-6548). Ieee.
[9] Asai, M., & Fukunaga, A. (2018, April). Classical planning in deep latent space: Bridging the subsymbolic-symbolic boundary. In Proceedings of the aaai conference on artificial intelligence (Vol. 32, No. 1).
[10] Hafner, D., Lillicrap, T., Fischer, I., Villegas, R., Ha, D., Lee, H., & Davidson, J. (2019, May). Learning latent dynamics for planning from pixels. In International conference on machine learning (pp. 2555-2565). PMLR.
[11] Driess, D., Ha, J. S., & Toussaint, M. (2020). Deep visual reasoning: Learning to predict action sequences for task and motion planning from an initial scene image. arXiv preprint arXiv:2006.05398.
[12] Huang, W., Xia, F., Xiao, T., Chan, H., Liang, J., Florence, P., … & Ichter, B. (2022). Inner monologue: Embodied reasoning through planning with language models. arXiv preprint arXiv:2207.05608.
[13] Liu, Y., Chi, D., Wu, S., Zhang, Z., Hu, Y., Zhang, L., … & Zhuang, Y. (2025). SpatialCoT: Advancing Spatial Reasoning through Coordinate Alignment and Chain-of-Thought for Embodied Task Planning. arXiv preprint arXiv:2501.10074.
[14] Shinn, N., Cassano, F., Gopinath, A., Narasimhan, K., & Yao, S. (2023). Reflexion: Language agents with verbal reinforcement learning. Advances in Neural Information Processing Systems, 36, 8634-8652.
[15] Hu, M., Mu, Y., Yu, X., Ding, M., Wu, S., Shao, W., … & Luo, P. (2023). Tree-planner: Efficient close-loop task planning with large language models. arXiv preprint arXiv:2310.08582.
[16] Lin, B. Y., Fu, Y., Yang, K., Brahman, F., Huang, S., Bhagavatula, C., … & Ren, X. (2023). Swiftsage: A generative agent with fast and slow thinking for complex interactive tasks. Advances in Neural Information Processing Systems, 36, 23813-23825.
[17] Chen, X., Chen, W., Lee, D., Ge, Y., Rojas, N., & Kormushev, P. (2025). A Backbone for Long-Horizon Robot Task Understanding. IEEE Robotics and Automation Letters.
[18] Wu, Y., Zhang, J., Hu, N., Tang, L., Qi, G., Shao, J., … & Song, W. (2024, July). Mldt: Multi-level decomposition for complex long-horizon robotic task planning with open-source large language model. In International Conference on Database Systems for Advanced Applications (pp. 251-267). Singapore: Springer Nature Singapore.
[19] Jin, C., Tan, W., Yang, J., Liu, B., Song, R., Wang, L., & Fu, J. (2023). Alphablock: Embodied finetuning for vision-language reasoning in robot manipulation. arXiv preprint arXiv:2305.18898.
[20] Wang, C., Fan, L., Sun, J., Zhang, R., Fei-Fei, L., Xu, D., … & Anandkumar, A. (2023). Mimicplay: Long-horizon imitation learning by watching human play. arXiv preprint arXiv:2302.12422.
[21] Liu, B., Jiang, Y., Zhang, X., Liu, Q., Zhang, S., Biswas, J., & Stone, P. (2023). Llm+ p: Empowering large language models with optimal planning proficiency. arXiv preprint arXiv:2304.11477.
[22] Zhang, J., Tang, L., Song, Y., Meng, Q., Qian, H., Shao, J., … & Gu, J. (2024, May). Fltrnn: Faithful long-horizon task planning for robotics with large language models. In 2024 IEEE International Conference on Robotics and Automation (ICRA) (pp. 6680-6686). IEEE.
[23] Izzo, R. A., Bardaro, G., & Matteucci, M. (2024, October). Btgenbot: Behavior tree generation for robotic tasks with lightweight llms. In 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) (pp. 9684-9690). IEEE.
[24] Liang, J., Huang, W., Xia, F., Xu, P., Hausman, K., Ichter, B., … & Zeng, A. (2023, May). Code as policies: Language model programs for embodied control. In 2023 IEEE International Conference on Robotics and Automation (ICRA) (pp. 9493-9500). IEEE.
[25] Mavrogiannis, A., Mavrogiannis, C., & Aloimonos, Y. (2024, May). Cook2LTL: Translating cooking recipes to LTL formulae using large language models. In 2024 IEEE International Conference on Robotics and Automation (ICRA) (pp. 17679-17686). IEEE.
[26] Song, Y., Sun, P., Liu, H., Li, Z., Song, W., Xiao, Y., & Zhou, X. (2024). Scene-driven multimodal knowledge graph construction for embodied ai. IEEE Transactions on Knowledge and Data Engineering.
[27] Gu, Q., Kuwajerwala, A., Morin, S., Jatavallabhula, K. M., Sen, B., Agarwal, A., … & Paull, L. (2024, May). Conceptgraphs: Open-vocabulary 3d scene graphs for perception and planning. In 2024 IEEE International Conference on Robotics and Automation (ICRA) (pp. 5021-5028). IEEE.
[28] Onishchenko, A., Kovalev, A., & Panov, A. LookPlanGraph: Embodied instruction following method with VLM graph augmentation. In Workshop on Reasoning and Planning for Large Language Models.
[29] Ni, Z., Deng, X., Tai, C., Zhu, X., Xie, Q., Huang, W., … & Zeng, L. (2024, October). Grid: Scene-graph-based instruction-driven robotic task planning. In 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) (pp. 13765-13772). IEEE.
[30] Zhao, K., Song, Y., Zhao, H., Liu, H., Li, T., & Li, Z. (2024, October). Towards Coarse-grained Visual Language Navigation Task Planning Enhanced by Event Knowledge Graph. In Proceedings of the 33rd ACM International Conference on Information and Knowledge Management (pp. 3320-3330).
[31] Zhen, Y., Bi, S., Xing-tong, L., Wei-qin, P., Hai-peng, S., Zi-rui, C., & Yi-shu, F. (2023). Robot task planning based on large language model representing knowledge with directed graph structures. arXiv preprint arXiv:2306.05171.
[32] Ahn, M., Brohan, A., Brown, N., Chebotar, Y., Cortes, O., David, B., … & Zeng, A. (2022). Do as i can, not as i say: Grounding language in robotic affordances. arXiv preprint arXiv:2204.01691.
[33] Hazra, R., Dos Martires, P. Z., & De Raedt, L. (2024, March). Saycanpay: Heuristic planning with large language models using learnable domain knowledge. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 38, No. 18, pp. 20123-20133).
[34] Zhang, X., Altaweel, Z., Hayamizu, Y., Ding, Y., Amiri, S., Yang, H., … & Zhang, S. (2024). Dkprompt: Domain knowledge prompting vision-language models for open-world planning. arXiv preprint arXiv:2406.17659.
[35] Kant, Y., Ramachandran, A., Yenamandra, S., Gilitschenski, I., Batra, D., Szot, A., & Agrawal, H. (2022, October). Housekeep: Tidying virtual households using commonsense reasoning. In European Conference on Computer Vision (pp. 355-373). Cham: Springer Nature Switzerland.
[36] Elimelech, K., Kingston, Z., Thomason, W., Vardi, M. Y., & Kavraki, L. E. (2024, May). Accelerating long-horizon planning with affordance-directed dynamic grounding of abstract strategies. In 2024 IEEE International Conference on Robotics and Automation (ICRA) (pp. 12688-12695). IEEE.
[37] Ding, Y., Zhang, X., Amiri, S., Cao, N., Yang, H., Kaminski, A., … & Zhang, S. (2023). Integrating action knowledge and LLMs for task planning and situation handling in open worlds. Autonomous Robots, 47(8), 981-997.
[38] Zentner, K. R., Julian, R., Ichter, B., & Sukhatme, G. S. (2024, May). Conditionally Combining Robot Skills using Large Language Models. In 2024 IEEE International Conference on Robotics and Automation (ICRA) (pp. 14046-14053). IEEE.
[39] Belkhale, S., Ding, T., Xiao, T., Sermanet, P., Vuong, Q., Tompson, J., … & Sadigh, D. (2024). Rt-h: Action hierarchies using language. arXiv preprint arXiv:2403.01823.
[40] Wang, G., Xie, Y., Jiang, Y., Mandlekar, A., Xiao, C., Zhu, Y., … & Anandkumar, A. (2023). Voyager: An open-ended embodied agent with large language models. arXiv preprint arXiv:2305.16291.
[41] Mao, W., Zhong, W., Jiang, Z., Fang, D., Zhang, Z., Lan, Z., … & Yoshie, O. (2024). Robomatrix: A skill-centric hierarchical framework for scalable robot task planning and execution in open-world. arXiv preprint arXiv:2412.00171.
[42] Birr, T., Pohl, C., Younes, A., & Asfour, T. (2024). Autogpt+ p: Affordance-based task planning with large language models. arXiv preprint arXiv:2402.10778.
[43] Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., & Cao, Y. (2023, January). React: Synergizing reasoning and acting in language models. In International Conference on Learning Representations (ICLR).
[44] Qiao, S., Zhang, N., Fang, R., Luo, Y., Zhou, W., Jiang, Y. E., … & Chen, H. (2024). AutoAct: Automatic agent learning from scratch for QA via self-planning. arXiv preprint arXiv:2401.05268.
[45] Zeng, A., Attarian, M., Ichter, B., Choromanski, K., Wong, A., Welker, S., … & Florence, P. (2022). Socratic models: Composing zero-shot multimodal reasoning with language. arXiv preprint arXiv:2204.00598.
[46] Sun, W., Hou, S., Wang, Z., Yu, B., Liu, S., Yang, X., … & Han, Y. (2024). DaDu-E: Rethinking the Role of Large Language Model in Robotic Computing Pipeline. arXiv preprint arXiv:2412.01663.
[47] Driess, D., Xia, F., Sajjadi, M. S., Lynch, C., Chowdhery, A., Wahid, A., … & Florence, P. (2023). Palm-e: An embodied multimodal language model.
[48] Mu, Y., Zhang, Q., Hu, M., Wang, W., Ding, M., Jin, J., … & Luo, P. (2023). Embodiedgpt: Vision-language pre-training via embodied chain of thought. Advances in Neural Information Processing Systems, 36, 25081-25094.
[49] Wang, W., Lv, Q., Yu, W., Hong, W., Qi, J., Wang, Y., … & Tang, J. (2024). Cogvlm: Visual expert for pretrained language models. Advances in Neural Information Processing Systems, 37, 121475-121499.
[50] Ge, Z., Huang, H., Zhou, M., Li, J., Wang, G., Tang, S., & Zhuang, Y. (2024, October). Worldgpt: Empowering llm as multimodal world model. In Proceedings of the 32nd ACM International Conference on Multimedia (pp. 7346-7355).
[51] Yang, J., Dong, Y., Liu, S., Li, B., Wang, Z., Tan, H., … & Liu, Z. (2024, September). Octopus: Embodied vision-language programmer from environmental feedback. In European Conference on Computer Vision (pp. 20-38). Cham: Springer Nature Switzerland.
[52] Guo, Y., Wang, Y. J., Zha, L., & Chen, J. (2024, October). Doremi: Grounding language model by detecting and recovering from plan-execution misalignment. In 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) (pp. 12124-12131). IEEE.
[53] Skreta, M., Zhou, Z., Yuan, J. L., Darvish, K., Aspuru-Guzik, A., & Garg, A. (2024). Replan: Robotic replanning with perception and language models. arXiv preprint arXiv:2401.04157.
[54] Mei, A., Zhu, G. N., Zhang, H., & Gan, Z. (2024). ReplanVLM: Replanning robotic tasks with visual language models. IEEE Robotics and Automation Letters.
[55] Wang, S., Han, M., Jiao, Z., Zhang, Z., Wu, Y. N., Zhu, S. C., & Liu, H. Llm3: large language model-based task and motion planning with motion failure reasoning, 2024. URL https://arxiv. org/abs/2403.11552.
[56] Raman, S. S., Cohen, V., Rosen, E., Idrees, I., Paulius, D., & Tellex, S. (2022, December). Planning with large language models via corrective re-prompting. In NeurIPS 2022 Foundation Models for Decision Making Workshop.
[57] Paul, D., Ismayilzada, M., Peyrard, M., Borges, B., Bosselut, A., West, R., & Faltings, B. (2023). Refiner: Reasoning feedback on intermediate representations. arXiv preprint arXiv:2304.01904.
[58] Miao, N., Teh, Y. W., & Rainforth, T. (2023). Selfcheck: Using llms to zero-shot check their own step-by-step reasoning. arXiv preprint arXiv:2308.00436.
[59] Kannan, S. S., Venkatesh, V. L., & Min, B. C. (2024, October). Smart-llm: Smart multi-agent robot task planning using large language models. In 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) (pp. 12140-12147). IEEE.
[60] Lykov, A., Dronova, M., Naglov, N., Litvinov, M., Satsevich, S., Bazhenov, A., … & Tsetserukou, D. (2023). Llm-mars: Large language model for behavior tree generation and nlp-enhanced dialogue in multi-agent robot systems. arXiv preprint arXiv:2312.09348.
[61] Zhang, H., Du, W., Shan, J., Zhou, Q., Du, Y., Tenenbaum, J. B., … & Gan, C. (2023). Building cooperative embodied agents modularly with large language models. arXiv preprint arXiv:2307.02485.
[62] Wang, Y., Xiao, R., Kasahara, J. Y. L., Yajima, R., Nagatani, K., Yamashita, A., & Asama, H. (2024). Dart-llm: Dependency-aware multi-robot task decomposition and execution using large language models. arXiv preprint arXiv:2411.09022.
[63] Srivastava, S., Li, C., Lingelbach, M., Martín-Martín, R., Xia, F., Vainio, K. E., … & Fei-Fei, L. (2022, January). Behavior: Benchmark for everyday household activities in virtual, interactive, and ecological environments. In Conference on robot learning (pp. 477-490). PMLR.
[64] Li, C., Zhang, R., Wong, J., Gokmen, C., Srivastava, S., Martín-Martín, R., … & Fei-Fei, L. (2024). Behavior-1k: A human-centered, embodied ai benchmark with 1,000 everyday activities and realistic simulation. arXiv preprint arXiv:2403.09227.
[65] Yang, R., Chen, H., Zhang, J., Zhao, M., Qian, C., Wang, K., … & Zhang, T. (2025). EmbodiedBench: Comprehensive Benchmarking Multi-modal Large Language Models for Vision-Driven Embodied Agents. arXiv preprint arXiv:2502.09560.
[66] Liu, B., Zhu, Y., Gao, C., Feng, Y., Liu, Q., Zhu, Y., & Stone, P. (2023). Libero: Benchmarking knowledge transfer for lifelong robot learning. Advances in Neural Information Processing Systems, 36, 44776-44791.
[67] Shridhar, M., Thomason, J., Gordon, D., Bisk, Y., Han, W., Mottaghi, R., … & Fox, D. (2020). Alfred: A benchmark for interpreting grounded instructions for everyday tasks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 10740-10749).
[68] Puig, X., Ra, K., Boben, M., Li, J., Wang, T., Fidler, S., & Torralba, A. (2018). Virtualhome: Simulating household activities via programs. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 8494-8502).
[69] Wake, N., Kanehira, A., Sasabuchi, K., Takamatsu, J., & Ikeuchi, K. (2024). Gpt-4v (ision) for robotics: Multimodal task planning from human demonstration. IEEE Robotics and Automation Letters.
[70] Jia, B., Lei, T., Zhu, S. C., & Huang, S. (2022). Egotaskqa: Understanding human tasks in egocentric videos. Advances in Neural Information Processing Systems, 35, 3343-3360.
[71] Cheng, S., Guo, Z., Wu, J., Fang, K., Li, P., Liu, H., & Liu, Y. (2024). Egothink: Evaluating first-person perspective thinking capability of vision-language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 14291-14302).
[72] Wan, Y., Mao, J., & Tenenbaum, J. (2022). Handmethat: Human-robot communication in physical and social environments. Advances in Neural Information Processing Systems, 35, 12014-12026.
[73] Shen, Y., Song, K., Tan, X., Zhang, W., Ren, K., Yuan, S., … & Zhuang, Y. (2024). Taskbench: Benchmarking large language models for task automation. Advances in Neural Information Processing Systems, 37, 4540-4574.
[74] Yao, S., Shinn, N., Razavi, P., & Narasimhan, K. (2024). -bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains. arXiv preprint arXiv:2406.12045.
[75]Hu, M., Zhao, P., Xu, C., Sun, Q., Lou, J., Lin, Q., … & Rajmohan, S. (2024). Agentgen: Enhancing planning abilities for large language model based agent via environment and task generation. arXiv preprint arXiv:2408.00764.
(文:机器学习算法与自然语言处理)