

近期,无监督RL在社区也掀起了一阵热潮,主打一个 多快好省(不能训太长step)有效果,且不论文章里面的evaluation是否存在问题(红温预警!“打假”7篇近期热门RL强化学习论文),本文简要分析一下这些文章的出发点以及一些形而上学的直观分析。
无监督RL
无监督RL目前在LLM领域多指不需要使用gold-answer的RL,这里一般包括两种:
-
• 第一种setting:prompt为真实数据,不使用真实answer -
• 第二种setting:prompt为合成数据,没有真实answer
目前的无监督RL主要集中在第一种setting,即不使用真实数据提供的answer进行RL训练。如果不使用真实数据的answer作为reward-signal,只能借鉴传统semi-supervised-learning的想法:利用某种consistency(比如rdropout、uda等等),降低输出的不确定性。(这里敲重点:RL本事是reverse-kl的优化目标,优化过程中,输出不确定性天然会下降,如果进一步利用consistency,可预期输出的不确定性会下降的更多,最终导致输出坍缩到某个固定的pattern,进而失去探索能力,使得模型性能下降)。
CONSISTENCY
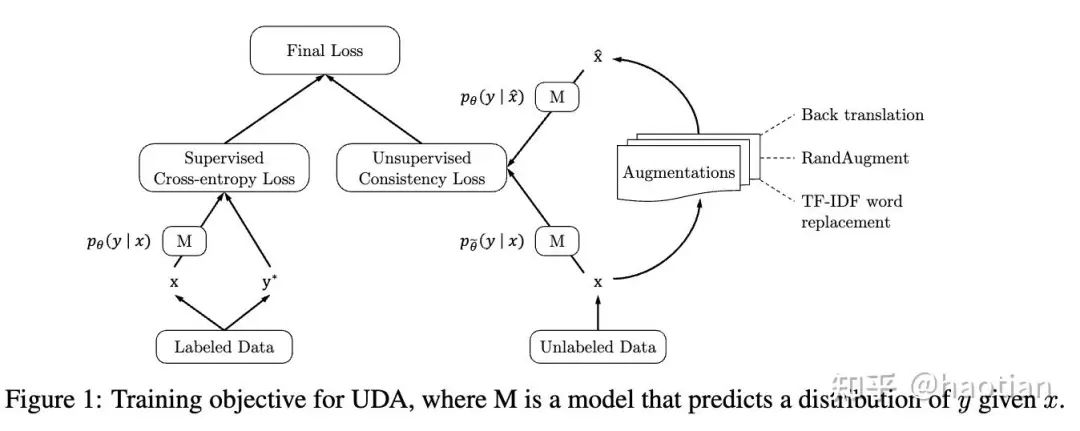
consistency在半监督学习中是一个常见的思想(包括 自监督学习),通过扰动、变换、加噪声等等,让这些输入和clean样本通过网络后,输出分布具有一致性:
-
• kl-divergence低 -
• distance-metric小
如google的UDA[1]:
进入正题:LLM采样输出的一致性metric如何选择,便有了不同的无监督RL方法。经典的一致性准则:
-
• 答案一致性(majority-voting) -
• 熵/kl-divergence
答案一致性
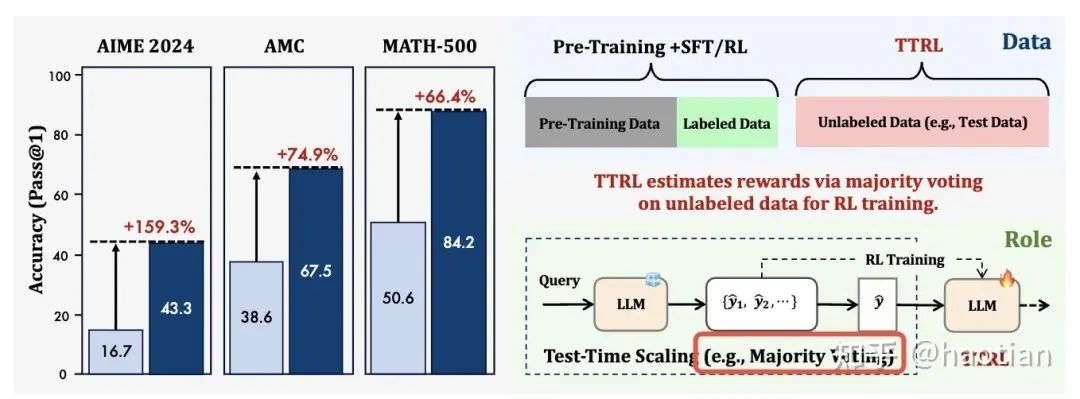
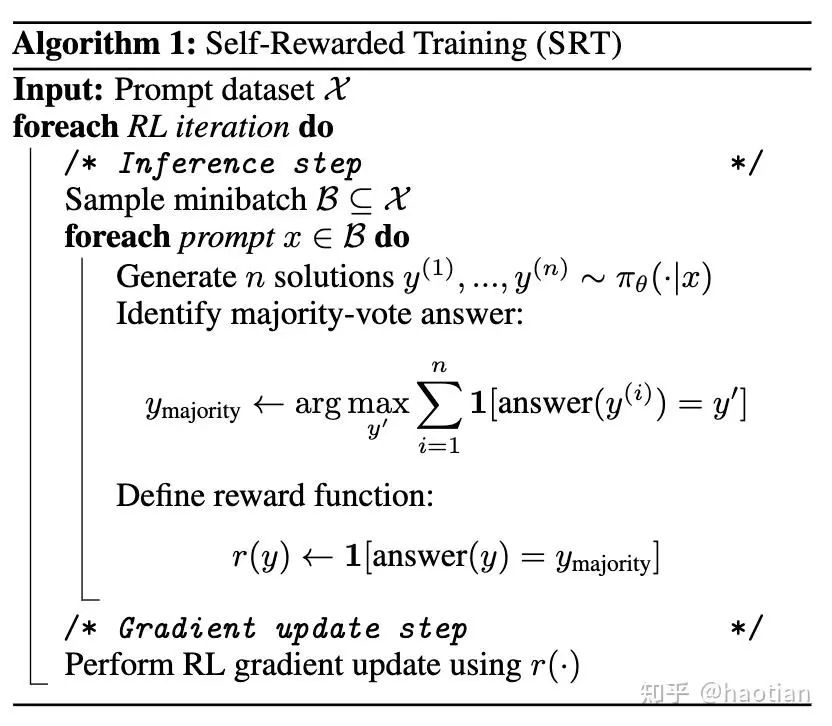
相关工作如TTRL[2]、Can Large Reasoning Models Self-Train?[3],均是利用答案一致性得到pesudo-answer,并将pesudo-answer作为“gold- answer”用于RLVR的优化:
直播预告!从 TTS 到 TTRL:无标签数据强化学习探索与展望
包括SEED-GRPO[4]也引入semantic-entropy(按照answer是否一致做“语义”聚类)。
使用投票机制获取pesudo-answer,天然会让模型的输出越来越一致,而明显的short-cut就是输出response几乎“一摸一样”,答案投票才会越来越一致,reward才会越来越高。自然而然,输出多样性会下降甚至崩溃。当训练step过多后,效果下降似乎不可避免,但在合理的训练step内,可预期可以提升效果。
trajectory-level的自洽性
最容易想到的是熵,熵代表了不确定度量,熵越低,系统越稳定,结论越一致,但效果不一定更好。
相关工作如ent-rl [5]、Intuitor[6],通过优化不确定度,在合理的训练step内,有效提升了模型性能。
如ent-rl使用entropy作为reward,让模型越来越自信。
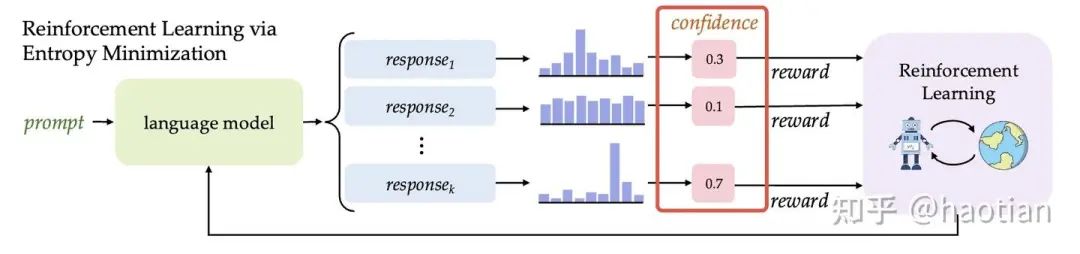
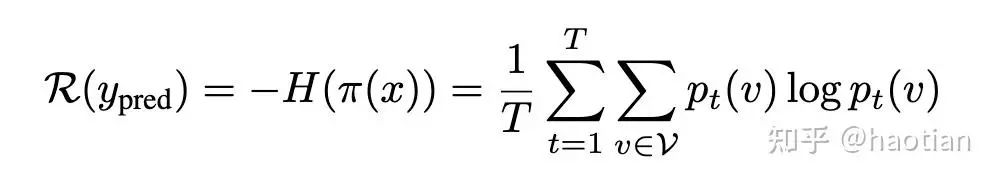
Intuitor(Learning to Reason without External Rewards)则提出使用self-certainty:
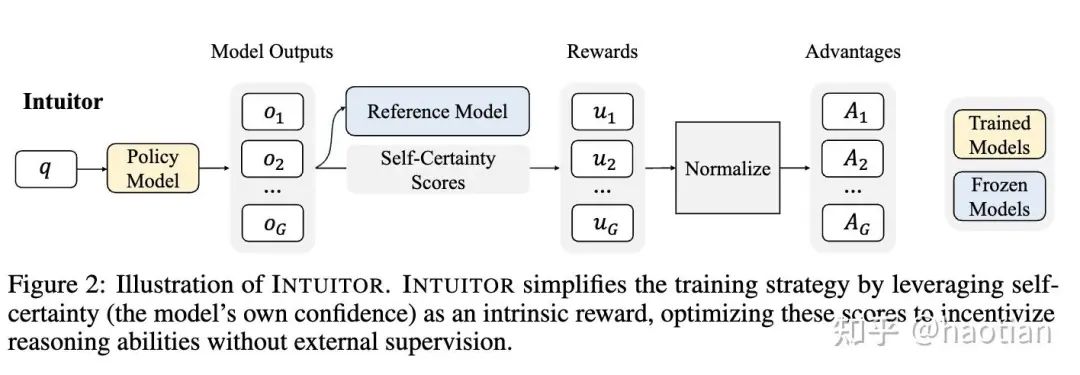
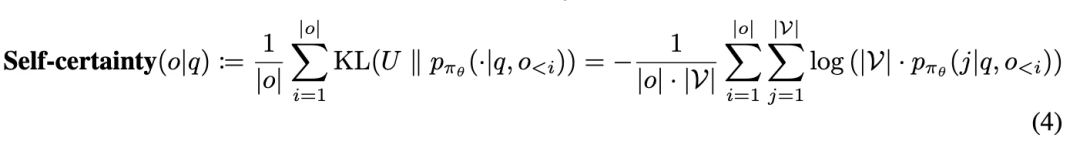
self-certainty越偏离均匀分布,self-certainty越大(self-certainty[7]是一种test-time-scaling的采样方法,能够提升BON的效果)。
当然,在标准RLVR训练中(使用gold-answer),self-certainty指标也是随着训练过程的进行越来越大。
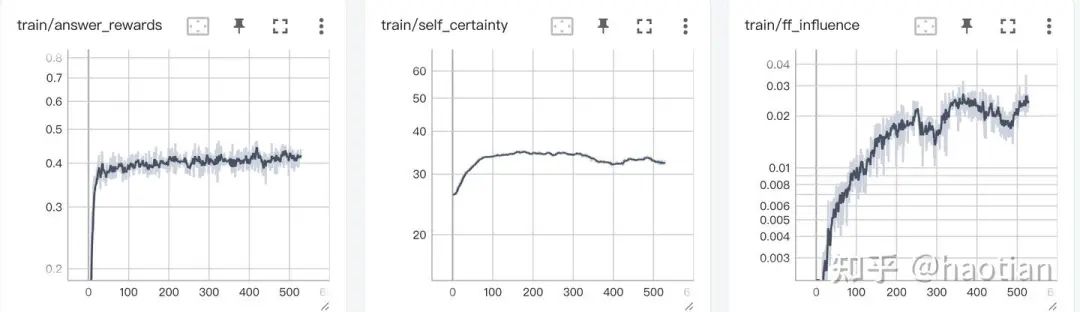
No Free Lunch: Rethinking Internal Feedback for LLM Reasoning[8]则更为系统的分析了基于internal-feedback的LLM-RL训练,基本结论也是类似:随着训练的进行,基于internal-feedback的效果会逐渐decay。
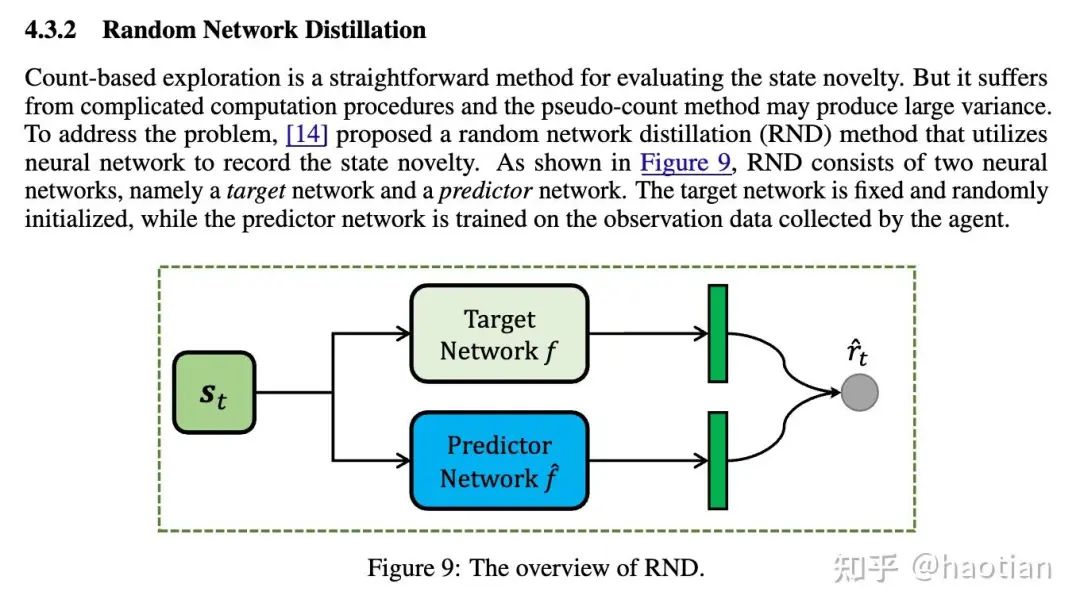
借鉴UDA等等方法,更好的利用internal-feedback还是半监督方法,即使用一部分gold-answer的reward+一部分internal-feedback的reward,可能可以避免这个问题。另外,internal-feedback 可能也可以用来作为 Intrinsically-motivated-RL[9]比如random-network-distillation:
总结
无监督RL大部分可以归为利用某种内在一致性,输出不确定性 如投票、entropy、self-certainty等等。使用内在一致性作为reward大概率随着训练的进行,熵会坍缩,进而导致效果下降。在合理的训练steps内,效果也可预期有一定提升。
未来,参考半监督学习的常见方法如UDA等等,混合gold-answer-reward-signal以及internal-feedback,可能可以更好的实现数据效率提升以及提升exploration效率(如random-network-disitllation和self-certainty笔者感觉就非常像,random-network的输出比较接近均匀分布)。
最后吐槽一下,近期agentic-rl,环境稳定性(经常失败、挂掉),太影响训练的debug了(有时候是环境延迟超时、环境崩溃导致模型一次又一次工具调用,这个时候加入reward-penalty会让训练跑的更偏)。
引用链接
[1] UDA:https://arxiv.org/abs/1904.12848[2]TTRL:https://arxiv.org/pdf/2504.16084[3]Can Large Reasoning Models Self-Train?:https://arxiv.org/abs/2505.21444[4]SEED-GRPO:https://arxiv.org/abs/2505.12346[5]ent-rl :https://arxiv.org/abs/2505.22660[6]Intuitor:https://arxiv.org/abs/2505.19590[7]self-certainty:https://arxiv.org/abs/2502.18581[8]No Free Lunch: Rethinking Internal Feedback for LLM Reasoning:https://www.alphaxiv.org/abs/2506.17219v1[9]Intrinsically-motivated-RL:https://arxiv.org/abs/2203.02298
(文:机器学习算法与自然语言处理)