

刚刚,网易有道开源了「子曰3」数学模型(Confucius3-Math),以14B参数的轻量级模型在多项数学推理任务上超越了满血参数的DeepSeek-R1。

其号称国内首个专注于数学教育的开源推理模型,最大的亮点是能在单块消费级GPU上高效运行。在GAOKAO-Bench(Math)这个基于高考数学题的评测框架中,子曰3数学模型拿下了98.46分的成绩,比DeepSeek-R1的93.27分高出5分多。
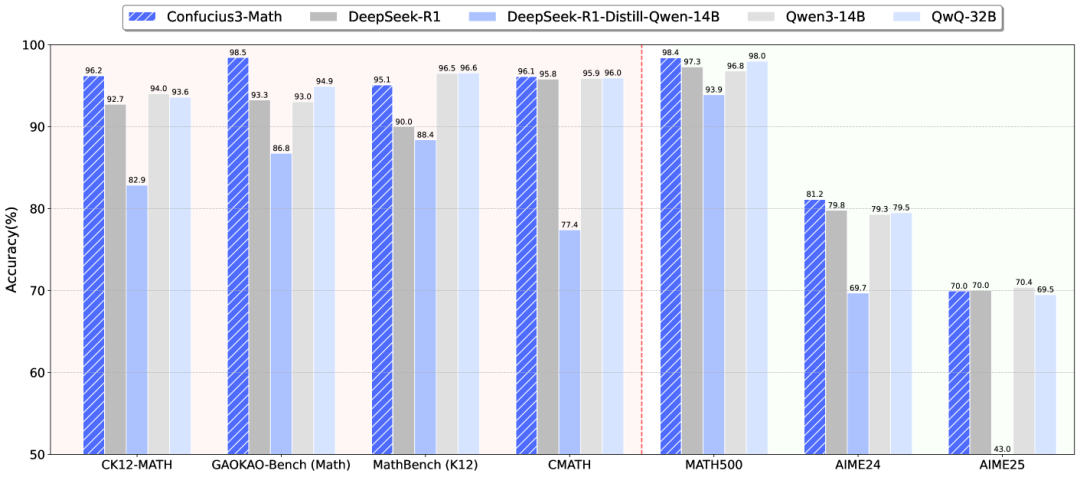
更关键的是,它的推理性能约为DeepSeek R1的15倍,服务成本每百万token仅需0.15美元。
这个价格,比目前大多数通用大模型都要便宜得多。
地板价了属实是。
参数小,但能打
既然是数学模型,我们当然要先来测试一下它的数学实力。
实测地址:
https://confucius.youdao.com/

第一题:函数定义域问题

这属于是热身题了。
作为推理模型,子曰3上来确实就是先一通思考:

以及那个神来之笔的“等等”:
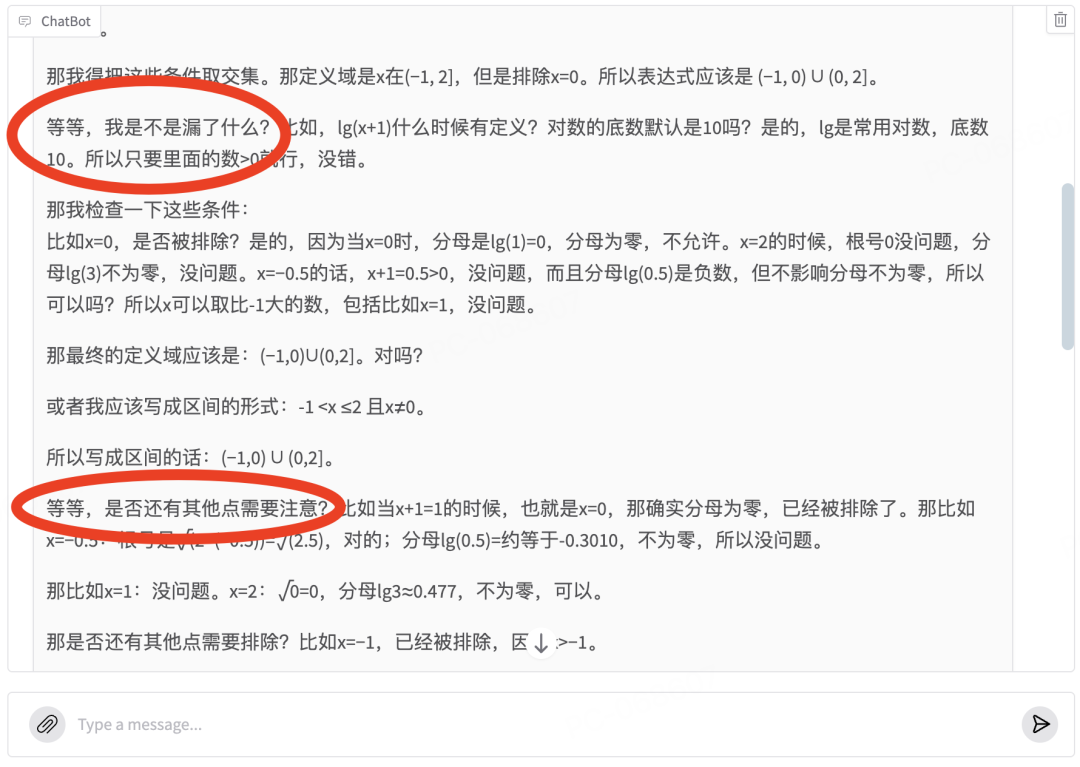
而且还不一个“等等”——或许这也代表模型在面对数学时严谨:需要仔细再仔细,小心再小心,毕竟数学题坑比较多,一个符号,一个开闭搞错,就是0分了。
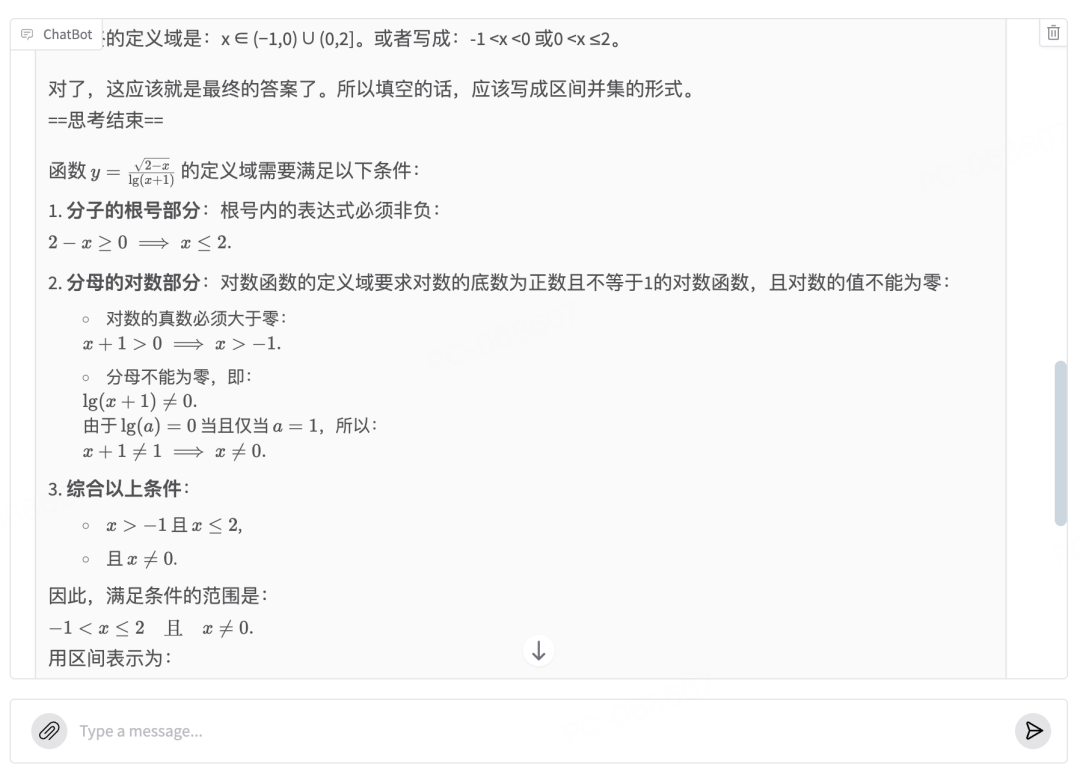
子曰3 明明早就已经拿到了正确答案,但还进行了多次推理数次检查:
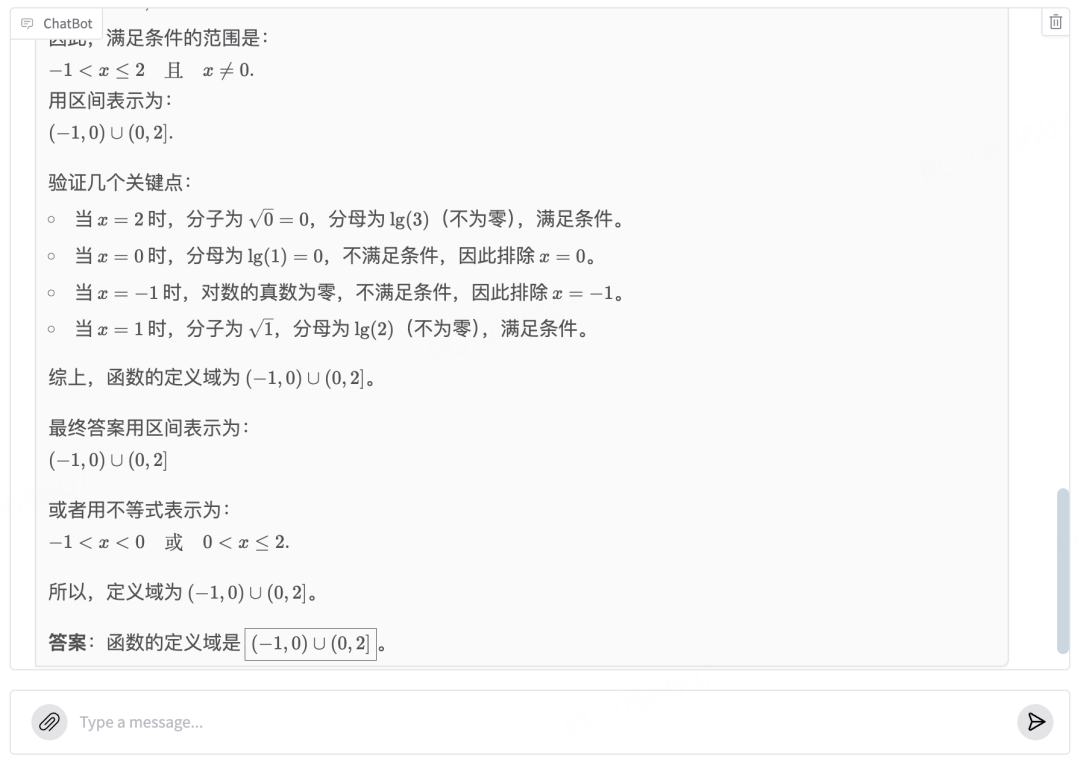
不过,虽然过程似乎显得不够自信,但当思考完成,检验通过后,则立刻展示出为满满的信心:

第一道热身题,轻松拿下。
第二题:几何问题
一个圆的半径是5cm,求这个圆内接正六边形的面积。
作为对比,我们可以先看o3 的输出:
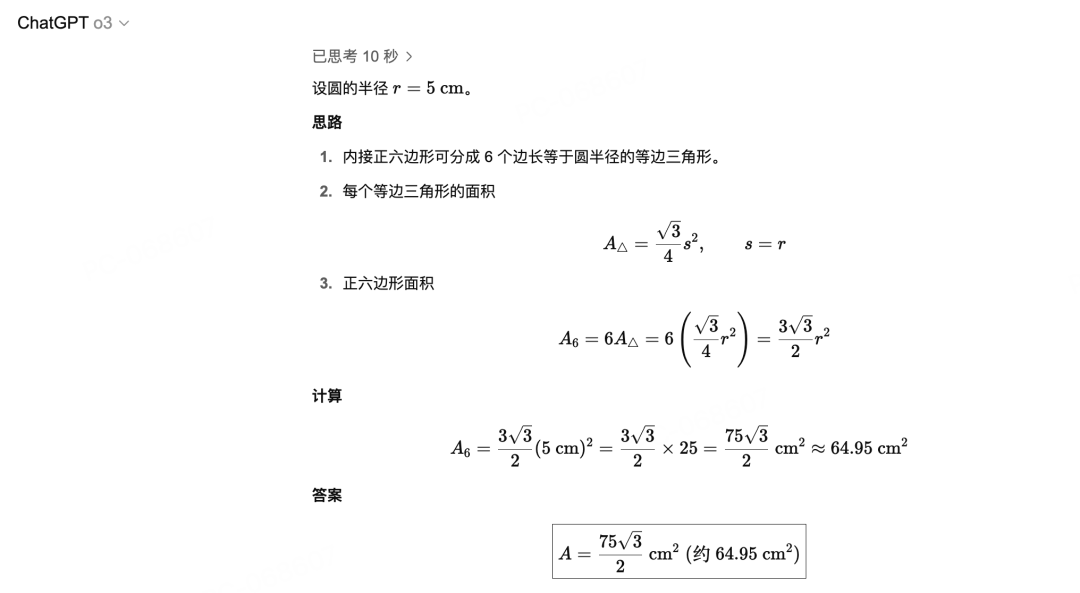
再来看子曰3——
它给出了完整的解题步骤:将正六边形分成6个等边三角形,每个三角形的边长等于圆的半径5cm,计算得出面积为75√3/2 平方厘米。
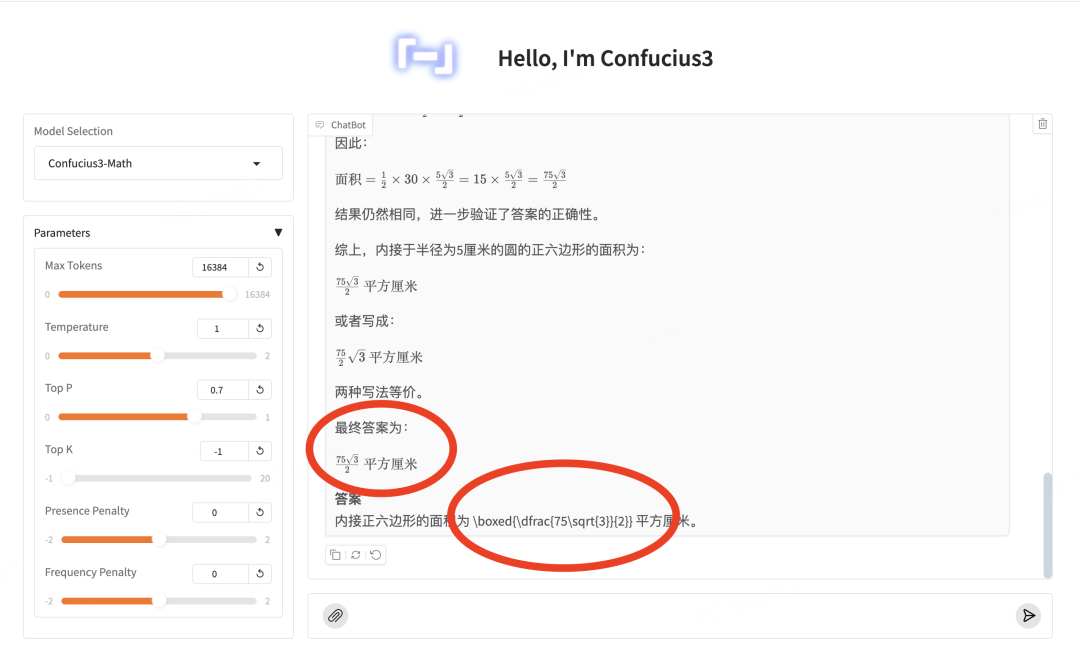
虽然答案对是对了,但还是被吹毛求疵的我挑到了点小小问题——
答案里的LaTex 没有正确渲染出来:需要用$xxx$ 的行内模式来写啊!
不对,我怎么只能挑点无关紧要的问题了?
那就上点难度,来几道新鲜的高考题吧!
我先用o3 搜索到了题目:

第三题:函数与导数中的“切线判定”问题
注意:输入的时候需要用LaTeX 语法:

小技巧是,如果你懒,可以像我把图直接扔给ChatGPT,让给出LaTex 的表达式,再扔给子曰3。
我试过图片直接给子曰3,目前还不能识别,算是个需要优化的点——不过这不是个大问题,不难处理。
来看下子曰3的结果:
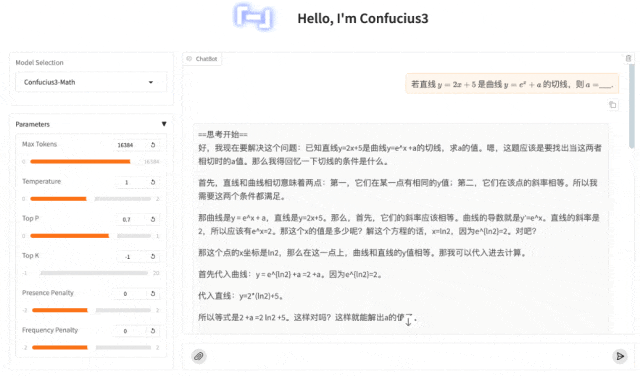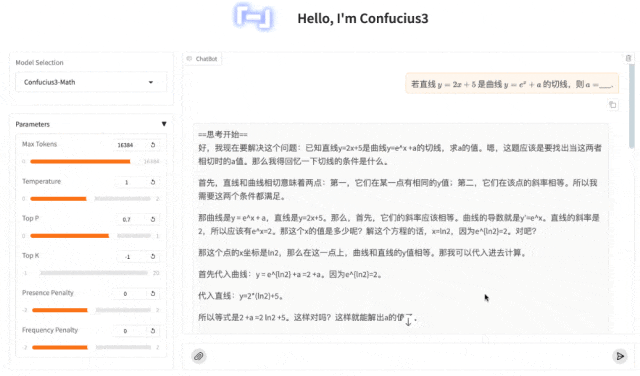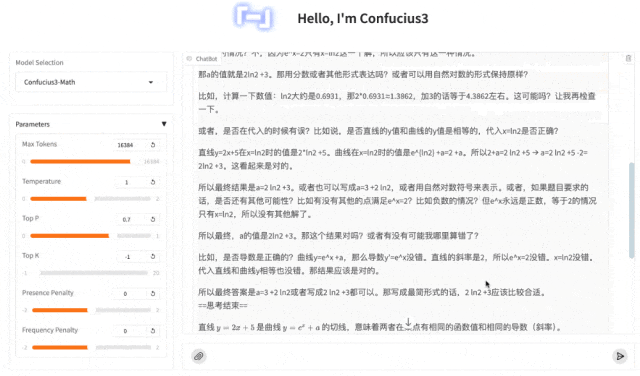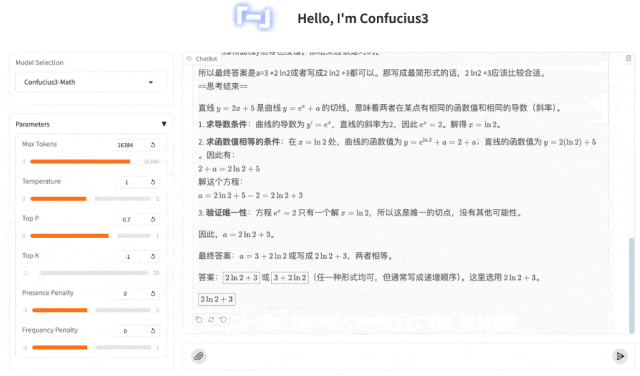
同样,还是不在话下,也是轻松拿下。
作为对比,o3 也给出了同样的结果:

值得一提的是,这里倒是有个细节倒是让我给学到了:
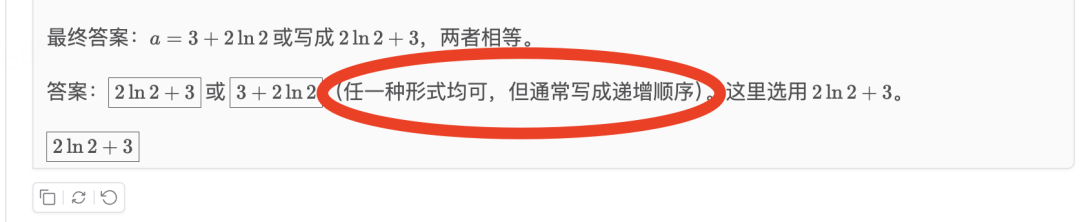
作为曾经高考147分的选手(当年提前交卷的鲁莽少年,只恨不像模型这么多轮检查啊……),我还真是没注意过这样的“通常写成递增顺序”知识点……
第四题:等比数据公比求解
若某正项等比数列前 4 项和为 4,前 8 项和为 68,则该数列的公比为___.
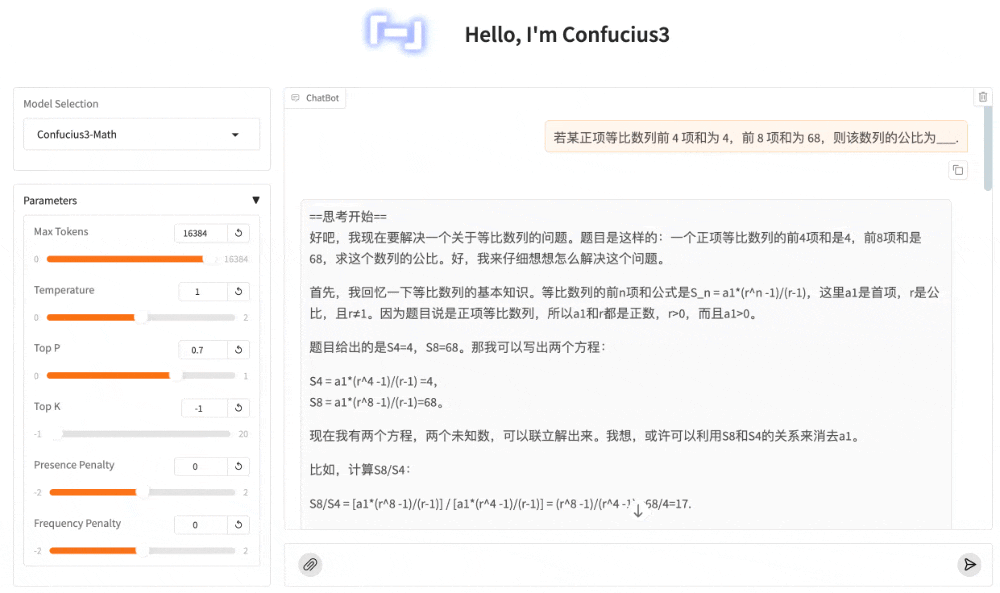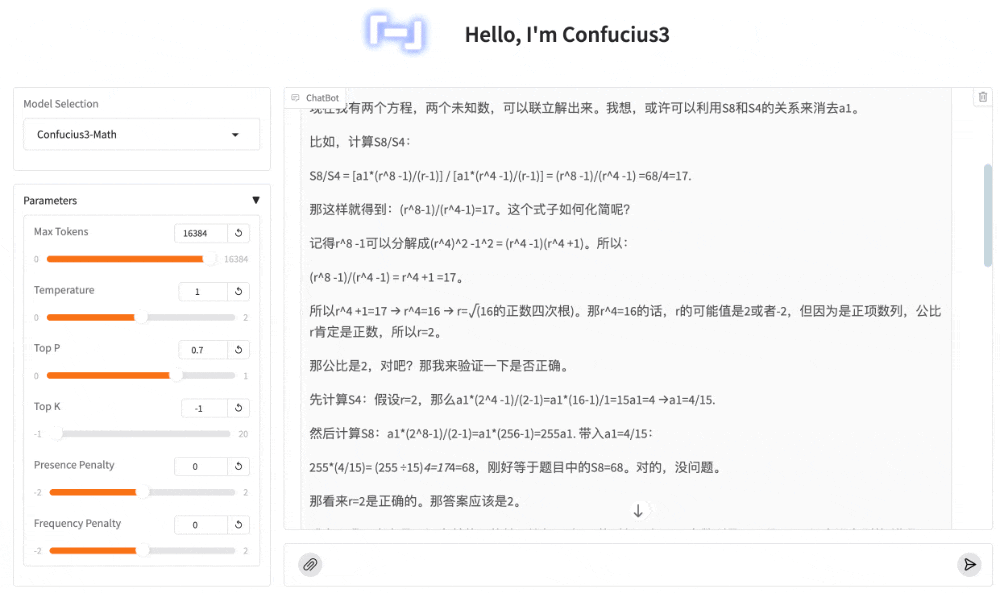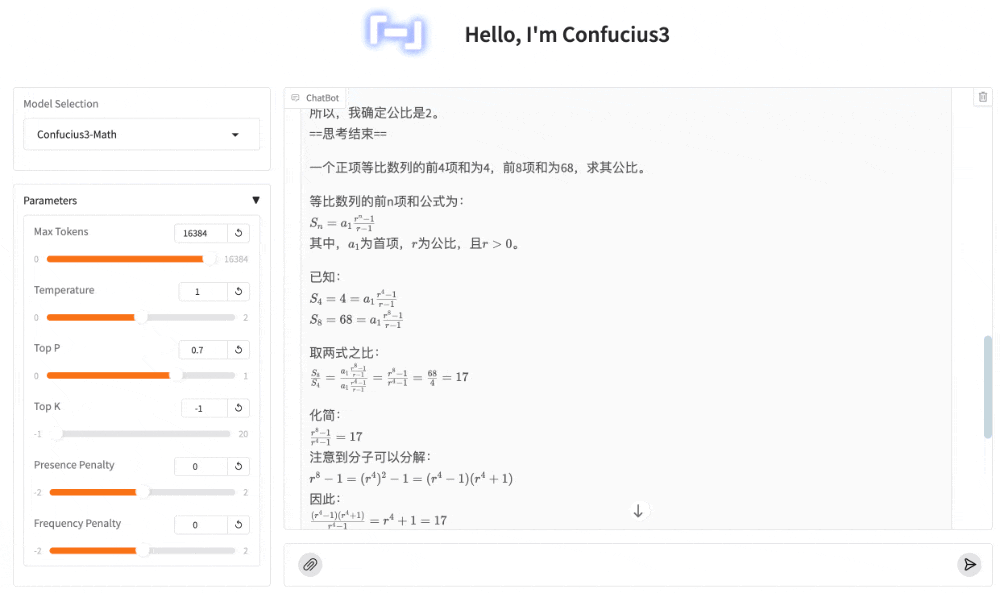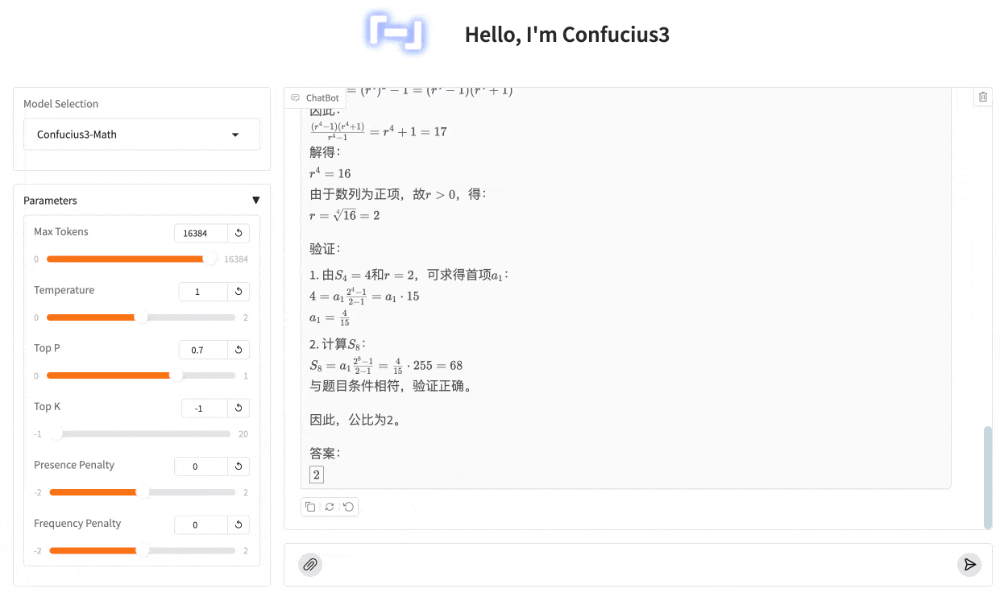
又一次,子曰3准确的理解了题意,并正确的列出了公式,然后同样进行了推导、检验、熟悉的“等等”之后,给出了正确答案:2。
好吧,我放弃了,不找你麻烦了。
总之,以我的出题能力,暂时还没能难倒它……
快速上手部署
而如果你想要自行部署体验子曰3数学模型,则很简单。
首先,你只需要定义系统提示词和用户提示词模板:
SYSTEM_PROMPT_TEMPLATE = """A conversation between User and Assistant. The user asks a question, and the Assistant solves it. The assistant first thinks about the reasoning process in the mind and then provides the user with the answer. The reasoning process and answer are enclosed within <think> </think> and <answer> </answer> tags, respectively, i.e., <think> reasoning process here </think> <answer> answer here </answer>."""
USER_PROMPT_TEMPLATE = """{question}"""
然后使用Transformers加载模型:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "netease-youdao/Confucius3-Math"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
messages = [
{'role': 'system', 'content': SYSTEM_PROMPT_TEMPLATE},
{'role': 'user', 'content': USER_PROMPT_TEMPLATE.format(question=question)},
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
这里建议使用Temperature=1.0, TopP=0.7的采样参数。
要是想要更高的性能,也可以使用vLLM部署。
同时,有道还提供了基于Gradio的Web界面,支持Docker一键部署:
# 构建镜像
docker build -t confucius3 .
# 启动容器服务
docker run -e ARK_API_KEY=xxx -p 8827:8827 confucius3
技术创新值得借鉴
看了下模型的训练论文,我发现子曰3数学模型这么能扛能打,原因倒也并非偶然。
它选择了DeepSeek-R1-Distill-Qwen-14B作为基座模型(从思考的过程就能猜到了),然后通过纯强化学习进行后训练。
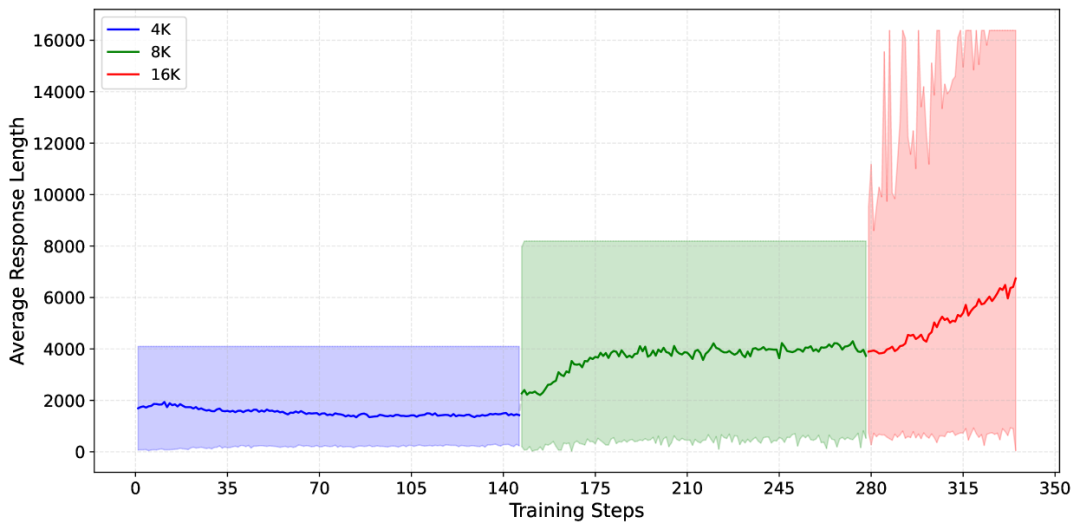
子曰3的训练过程分为三个阶段,上下文窗口从4K逐步扩展到16K。随着训练的进行,模型的思维链越来越长,推理能力也越来越强。
在数据准备上,它使用了约54万条训练数据,其中21万来自开源数据集(包括MATH、NuminaMath等),33万来自他们自己积累的K-12数学题库。
而这里有个巧妙的点是,数学题天然就是最好的奖励模型。
这不像猜女朋友到底在想什么一样不可捉摸——这太难了,且不可scale.
而数学题的答案对错一目了然,这种特性让强化学习在数学领域格外有效——具备RLVR(RL with Verification)的特点。
而在子曰3的训练过程中,有道的研究团队也提出了三个关键创新:
目标熵正则化(Targeted Entropy Regularization)
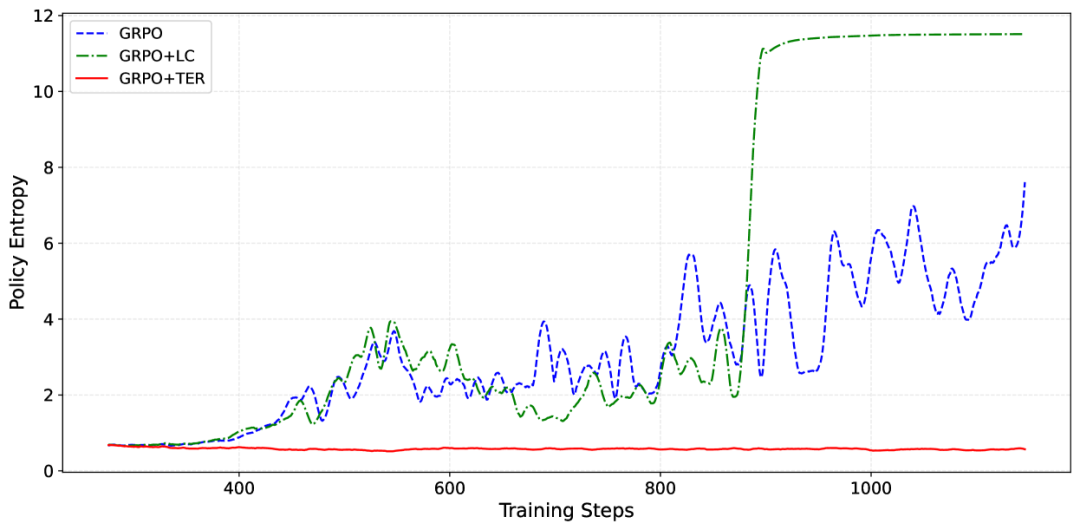
通过将熵值控制在0.55左右,既保证了探索的多样性,又避免了DeepSeek R1中出现的「混合语言现象」。
策略特定难度加权(Policy-Specific Hardness Weighting)
这是对传统课程学习的改进。
不同于按难度排序训练数据,这个方法根据当前模型对每道题的解答能力动态调整权重,让模型更专注于「刚好能学会」的问题。
这其实很好理解,如果让一个人上来先学高数,再学高中数据,再学乘法口诀……
不但学不好,估计会走火入魔——凡事得有个过程,需循序渐进。
好比我们得先学走,然后才能跑。
近期样本恢复(Recent Sample Recovery)
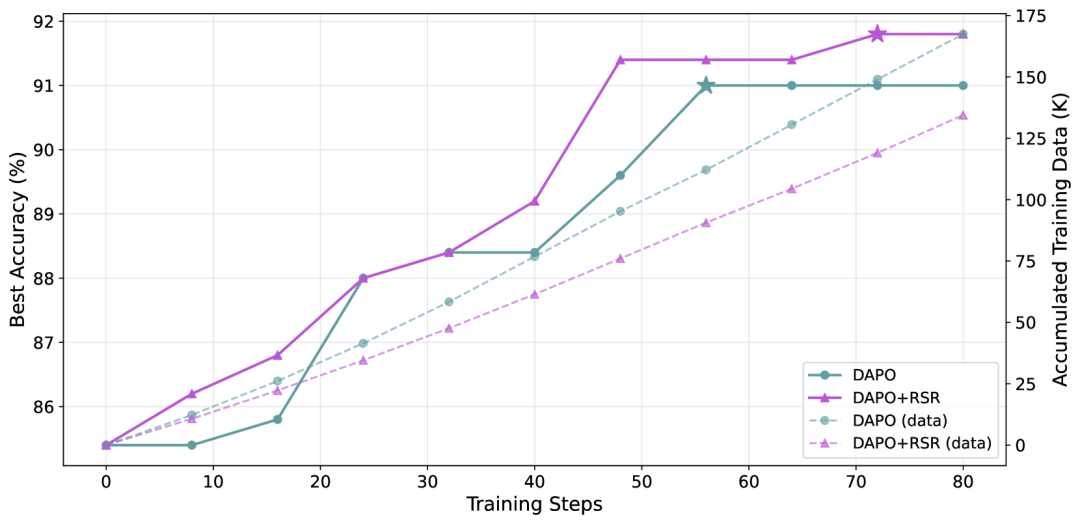
在动态采样过程中,那些被过滤掉但仍然有价值的样本会被保存起来,在下一批次中重新利用。
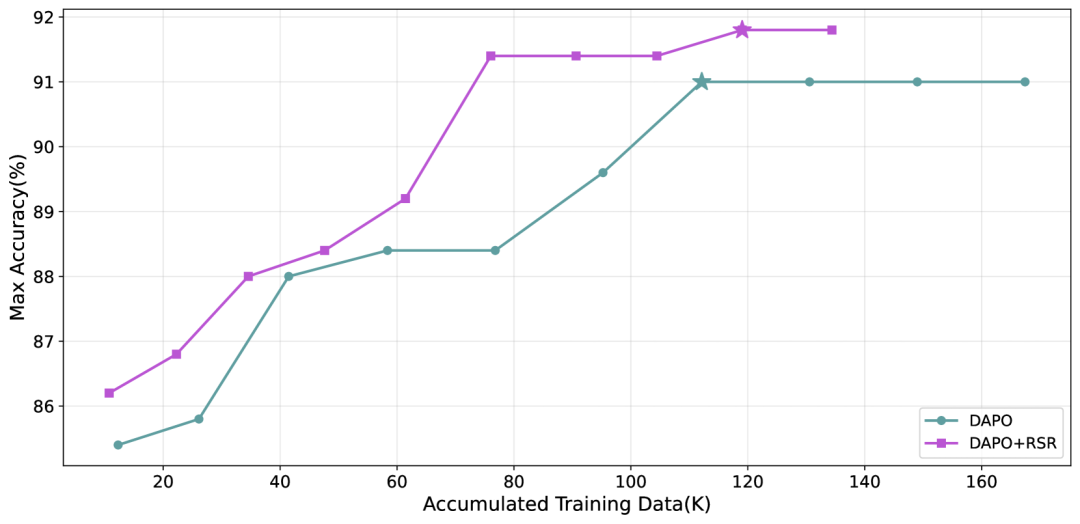
这个看似简单的改进,让数据利用率提升了3倍,同时还提升了训练质量。
成本仅为R1 的 1/15
再来看一下模型的训练成本。
按有道提供的信息,整个训练过程只需要13,109 GPU小时,按照H800每GPU小时2美元的租赁价格计算,总成本仅为26,000美元。
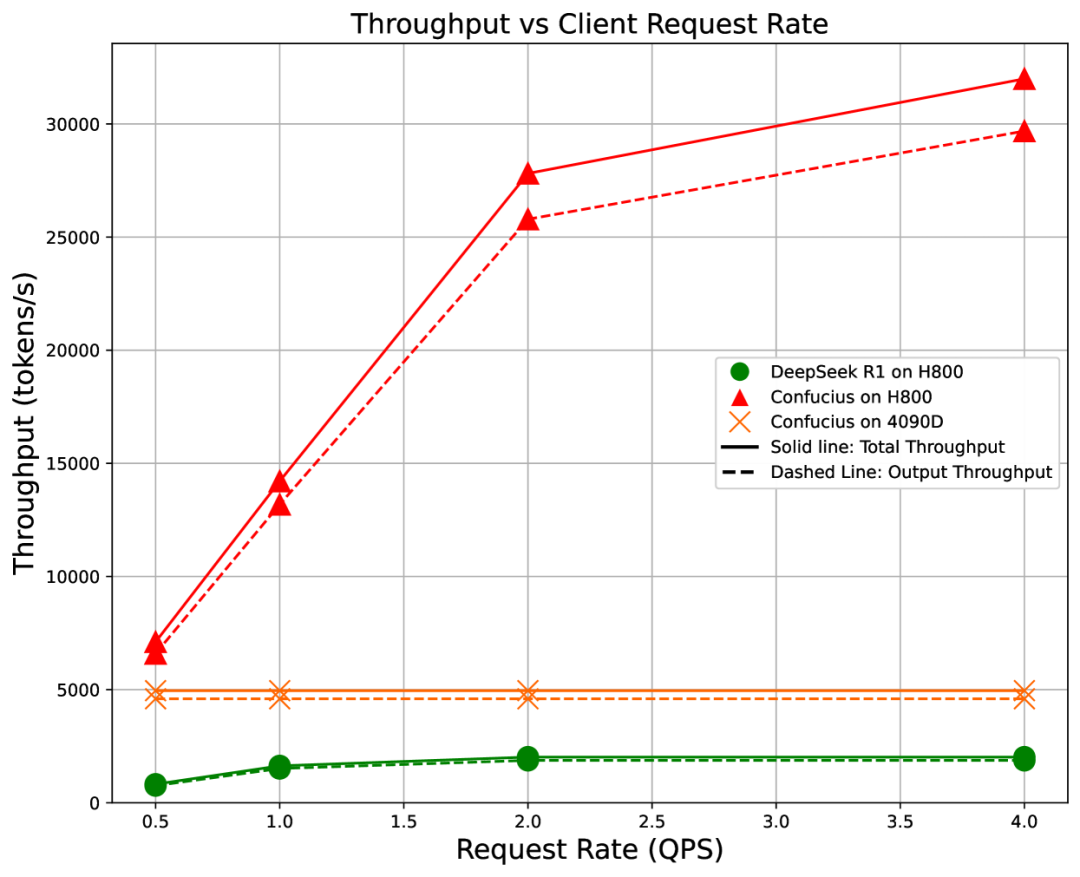
在推理性能上,子曰3在H800上的吞吐量可达31,994 tokens/秒,是DeepSeek R1的15.8倍。
即使在消费级的RTX 4090D上运行,也能达到4,956 tokens/秒的吞吐量。
推理成本也是无比便宜,如前所述——约为DeepSeek R1的15倍,服务成本每百万token仅需0.15美元。
开源的背后
有道选择开源这个模型,背后或许有更深的考量。

来自社区,回馈社区——
有道在教育领域深耕多年,积累了大量高质量的数学数据。现在把基于开源模型训练出的模型和技术细节完全开源,是对开源社区的回报,respect!
另外这也是希望和社区共建共同进步。
14B的模型已经能在消费级GPU上运行,如果未来能做到更小、再结合量化,再再结合有道的硬件线产品,端云结合会带来全新的教育可能性。
别忘了还有无数的偏远地区,还有许多渴望知识的孩子们,尚未拥有达标的教育资源。

而从技术角度看,数学能力的提升往往会带动模型在编码、逻辑推理等其他任务上的表现。
有道这次在数学垂直领域的探索,为整个社区提供了宝贵的经验——在特定领域做深做透,小模型也能超越大模型。
当教育遇上AI,当开源遇上垂直领域,子曰3数学模型证明了一件事:
真正的竞争力不在于模型有多大,而在于找到了正确的方法,在正确的领域,解决真正的问题。
不落下每一个领域,不放弃每一个渴望学习的孩子。
搞好教育,才是搞好人类的未来。
有道素来低调且务实,而此次发布的14B模型在数学领域击败了671B的DeepSeek-R1,这——
并非终点,而是才刚刚开始。
Demo 体验: https://confucius.youdao.com/
[2]GitHub 仓库: https://github.com/netease-youdao/Confucius3-Math
[3]HuggingFace 模型: https://huggingface.co/netease-youdao/Confucius3-Math
[4]ModelScope 模型: https://modelscope.cn/models/netease-youdao/Confucius3-Math
[5]WiseModel 模型: https://www.wisemodel.cn/models/Netease_Youdao/Confucius3-Math
[6]技术论文 (arXiv): https://arxiv.org/abs/2506.18330
(文:AGI Hunt)