



给机器人断了网它也能很好学习并执行任务的日子终于来了。
今天,谷歌DeepMind团队推出一种更加高效的机器人设备端模型:Gemini Robotics On-Device,谷歌方面称:“这是我们最强大的VLA模型,经过优化,它可在机器人设备上本地运行,并且具备强大的通用灵活性和任务泛化能力。”

由于该模型能独立于数据网络运行,因此它对延迟敏感的机器人应用很有帮助,在网络间歇性或零连接环境中实现更好的稳健性。
DeepMind和谷歌研究院首席科学家Jeff Dean发帖称,Gemini Robotics On-Device凝聚了谷歌团队十多年的机器人研究和工程经验。


目前,谷歌提供了Gemini Robotics SDK开发套件,能够帮助开发者轻松评估Gemini Robotics在设备上的性能,在MuJoCo物理模拟器测试中,该模型能让机器人快速适配到新领域或新任务中,只需50~100次示范即可适应新任务,表现十分出色。

这次新发布其实已是Gemini Robotics系列的第三款模型。
谷歌Gemini系列大模型在跨文本、图像、音频和视频等多模态推理、解决复杂问题方面业内领先,然而,这些能力主要局限于数字领域,尚未在现实世界中发挥巨大作用,因为它们必须具备“具身”推理——即像人类一样理解和应对周围世界并采取稳妥行动完成任务的能力。
早在今年3月,谷歌就推出了Gemini Robotics系列VLA(视觉–语言–动作)模型框架,旨在将Gemini 2.0的多模态推理和理解能力带入物理世界。
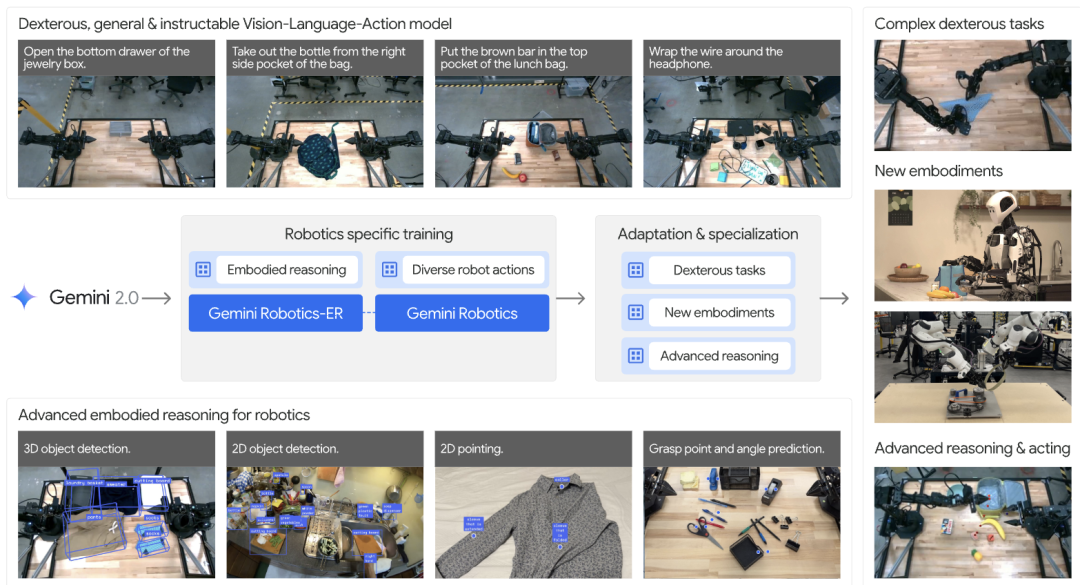
第一个推出是Gemini Robotics,它基于Gemini 2.0构建,添加了物理动作作为新的输出模式,用于直接控制机器人;第二个是Gemini Robotics-ER,这是一个具有先进空间理解能力的Gemini模型,使机器人专家能够将Gemini的具身推理能力运用到自己的程序中。
第三个Gemini Robotics On-Device模型如其字面意思,主要聚焦于设备端上。

官方表示,Gemini Robotics On-Device是基于双臂机器人训练的基础通用模型,旨在最大限度地减少计算资源需求,其具备三大特点:1、专为灵巧操作的快速实验而设计;2、能通过微调来适应新任务进一步提高性能;3、经过优化,可在本地运行并实现超低延迟推理。
值得称赞的是,这个离线模型的部分性能几乎与其旗舰Gemini Robotics模型一样好。
研究人员的评估结果显示,该模型的“设备模式”在完全本地运行时表现出强大的泛化性能。
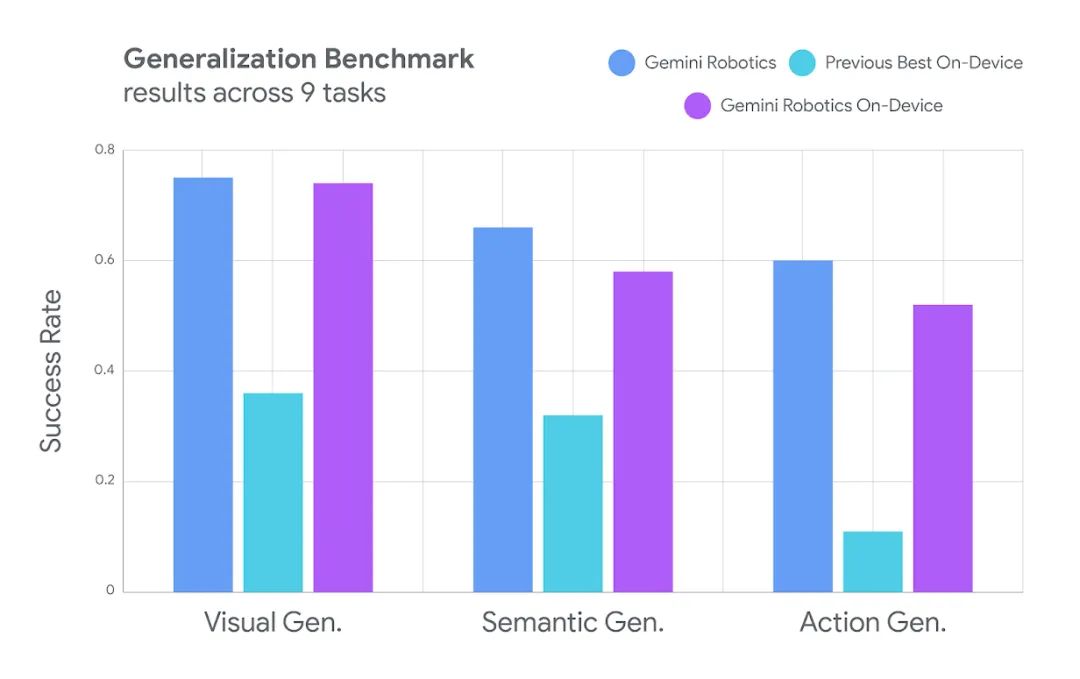
在更具挑战性的分布式任务和复杂的多步骤指令方面,Gemini Robotics On-Device模型的表现优于其他设备端替代方案,对于希望获得最佳结果且不受设备端限制的开发者,谷歌还提供了优化的Gemini Robotics模型。
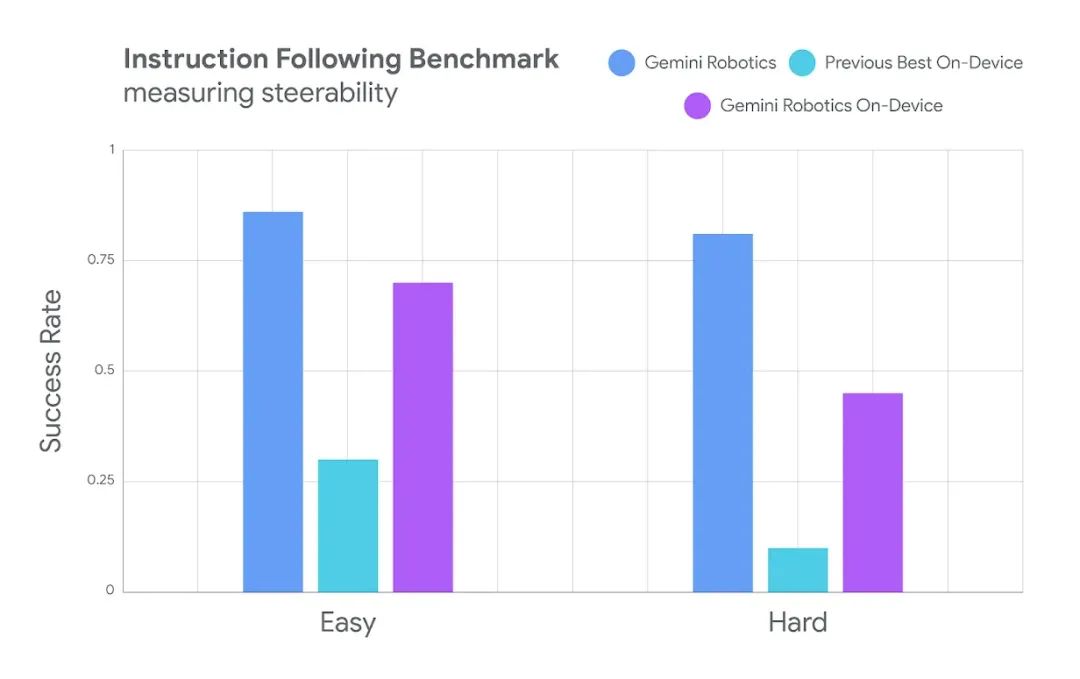
Gemini Robotics On-Device也是谷歌首个可供微调的VLA模型,虽然在许多任务上可以直接运行,但开发者也可以选择调整模型参数,使其更加匹配具体需求和设备,从而获得更佳性能,研究人员表示,该模型能够快速适应新任务,只需50到100次演示即可完成学习,充分表明了该设备端模型将其基础知识推广到新任务的泛化能力。
从官方给出的实际演示案例来看,虽然模型仅针对ALOHA机器人进行了训练,但却能很快将其调整到双臂Franka FR3机器人和Apptronik的Apollo人形机器人上。

而且在Apollo人形机器人上,模型能适应截然不同的多种任务形态,可以遵循自然语言指令,并以通用的方式操控不同的物体,包括它之前从未见过的物体。
从目前来看,Gemini Robotics On-Device是业内唯一支持全链路离线运行、任务泛化性强且开放SDK的通用VLA模型,谷歌DeepMind机器人技术主管Carolina Parada表示,这种方法可以让机器人在具有挑战性的环境下更加可靠。
不过本地运行的模型端侧算力限制仍是挑战,这可能也是Gemini Robotics On-Device是基于Gemini 2.0研发而非最新的2.5版本。
VLA模型是目前具身智能领域十分火热的研究课题,在国内,不少具身智能企业和高校科研机构联手,从不同角度进行着创新探索。
国内VLA模型的核心竞争力体现在三维空间理解、物理规律挖掘、场景泛化、架构创新等方向,背后依赖“国家队科研机构+高校+企业”的协同生态,技术路径和创新各有千秋。

例如,银河通用联合北京智源人工智能研究院、北京大学和香港大学发布的具身抓取基础大模型GraspVLA,特点是预训练完全基于合成大数据,数据量达十亿帧“视觉–语言–动作”对,后训练阶段支持零样本迁移与小样本学习,仅需小样本真实数据微调即可迁移至特定场景(如工业分拣、家庭整理),形成“专家”技能。
智元机器人和上海交通大学合作推出的Hume双系统VLA模型,引入慢思考机制,通过动作价值引导的候选动作采样与级联去噪,解决长时序任务(如折叠短裤、倒咖啡)的规划难题,平均成功率达91%;智元机器人的另一个模型GO-1提出ViLLA(Vision-Language-Latent-Action)架构,整合VLM(通用感知)、隐式规划器(动作理解)、动作专家(精细执行),成功率较基线模型提升32%。
灵初智能推出的DexGraspVLA采用“域不变表征+分层扩散控制”架构,通过统一语义与动作空间,实现数据高效利用与开放场景泛化,据悉,这是全球首个用于灵巧手通用抓取的VLA框架,仅需2小时真实抓取数据(2094 条轨迹)即可泛化至1287种未见过的物体、光照和背景组合,数据利用效率是海外模型的250倍。
自变量机器人研发的WALL-A端到端统一具身大模型,突破传统分层架构(感知→规划→控制)的噪声传递问题,支持从原始传感器信号到机器人动作的纵向统一和横向任务统一,跨任务泛化能力出色,据说是全球唯二掌握“端到端统一架构”的团队。
千寻智能推出的千寻VLA,将“动态感知柔性操作+高效样本利用+任务级泛化”三位一体,实现“一镜到底”的叠衣服全流程(抓取→甩平→折叠→堆叠),连续操作50件衣物成功率超90%。
中科院自动化所谭铁牛团队和字节跳动Seed合作推出的BridgeVLA,斩获CVPR 2025 GRAIL workshop的COLOSSEUM Challenge冠军,该模型通过创新性的“2D空间对齐”架构,解决了传统3D VLA模型数据效率低与泛化能力弱的难题。
VLA模型作为当下具身智能的核心技术之一,正深刻重塑着机器人产业的发展路径,推动机器人从“专用自动化”迈向“通用智能”,重构人机交互范式,实现自然语言驱动的机器人复杂任务执行能力。
做好VLA,或许将见证具身智能机器人产业第一次真正高峰的到来。
-END-

(文:头部科技)