

本文使用Dify v1.4.0版本,主要介绍了app_factory.py中的create_migrations_app()函数的实现原理。
源码位置:dify\api\app_factory.py
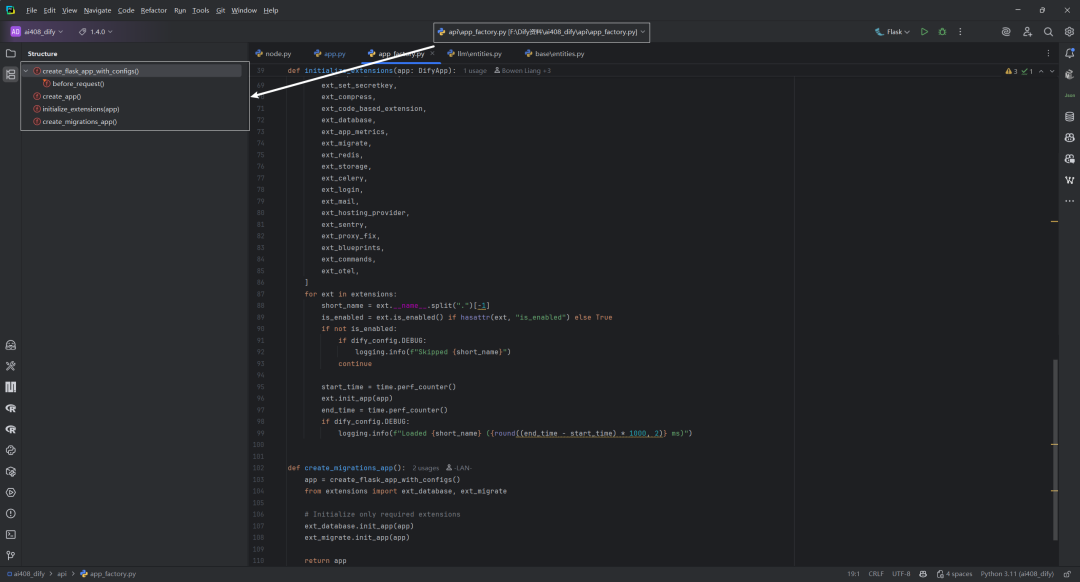
一.create_migrations_app() 函数
这段代码定义了一个名为 create_migrations_app() 的函数,它用于创建一个专门用于数据库迁移的精简版 Flask 应用。这种设计模式常见于 Flask 应用中,当只需要执行数据库迁移操作时,创建一个轻量级的应用实例可以提高效率,避免加载不必要的扩展和功能。
defcreate_migrations_app():
app = create_flask_app_with_configs()
from extensions import ext_database, ext_migrate
# Initialize only required extensions
ext_database.init_app(app)
ext_migrate.init_app(app)
return app
1.主要功能点
-
调用
create_flask_app_with_configs()创建一个基础的 Flask 应用,并加载配置信息 -
仅导入必要的两个扩展:
ext_database和ext_migrate -
只初始化这两个必要的扩展,而不是像
create_app()函数那样初始化所有扩展
2.函数执行顺序
-
创建配置好的 Flask 应用
-
导入数据库和迁移相关扩展
-
初始化这些扩展
-
返回配置好的应用实例
这个函数很可能是被数据库迁移命令(如 Flask-Migrate 的命令)调用的。
二.create_flask_app_with_configs()函数
这段代码实现了一个Flask应用工厂函数,主要功能是创建并配置一个基础的Flask应用实例。这个工厂函数体现了Flask应用程序开发中的最佳实践,通过函数返回应用实例,使得应用创建过程更加模块化和可配置。
# ----------------------------
# Application Factory Function
# ----------------------------
defcreate_flask_app_with_configs() -> DifyApp:
"""
create a raw flask app
with configs loaded from .env file
"""
dify_app = DifyApp(__name__)
dify_app.config.from_mapping(dify_config.model_dump())
# add before request hook
@dify_app.before_request
defbefore_request():
# add an unique identifier to each request
RecyclableContextVar.increment_thread_recycles()
return dify_app
1.函数定义
defcreate_flask_app_with_configs() -> DifyApp:
这个函数不接受参数,返回类型是DifyApp(Flask的一个定制子类)。
2.应用实例创建
dify_app = DifyApp(__name__)
创建了一个DifyApp实例,传入当前模块名作为参数。DifyApp继承自Flask,可简单理解DifyApp就是Flask。
源码位置:dify\api\dify_app.py。
classDifyApp(Flask):
pass
3.配置加载
dify_app.config.from_mapping(dify_config.model_dump())
从dify_config(Pydantic模型)加载配置到应用实例中,本质上还是从dify\api\.env文件加载的配置。
4.请求前钩子
@dify_app.before_request
defbefore_request():
RecyclableContextVar.increment_thread_recycles()
添加了一个在每个请求处理前执行的钩子函数,主要用于为每个请求添加唯一标识符,通过递增RecyclableContextVar中的计数器实现。
三.dify_app.config.from_mapping(dify_config.model_dump())
该行代码负责将配置信息加载到Flask应用实例中,详细执行流程如下:
1.dify_config对象
-
从
configs模块导入的配置对象 -
它是一个Pydantic模型实例,用于管理应用配置
2.model_dump()方法
-
这是Pydantic模型的方法
-
将Pydantic模型的所有属性转换为普通Python字典
-
包含所有配置键值对
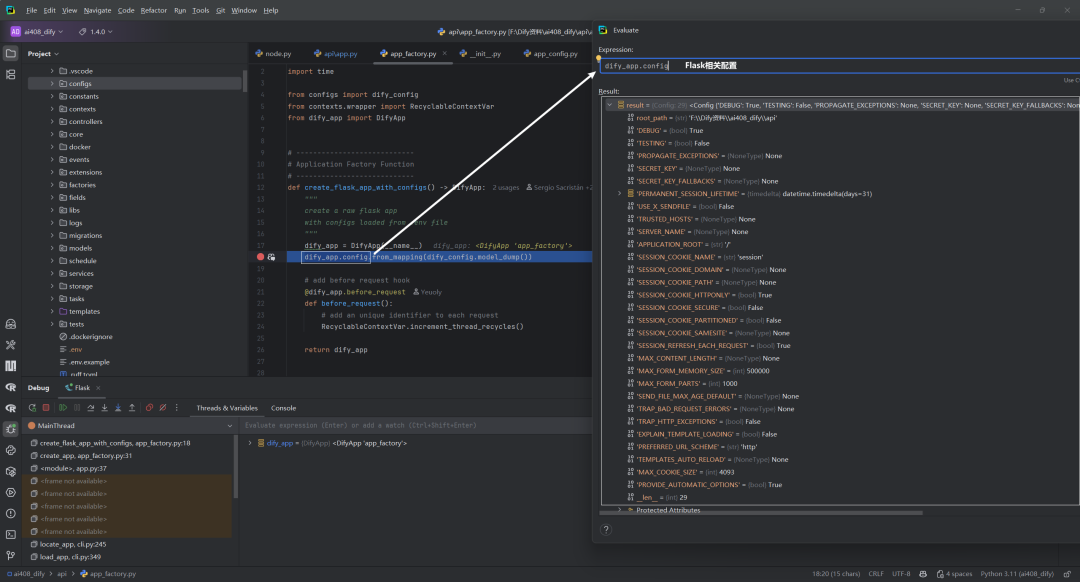
3.dify_app.config.from_mapping()
-
dify_app是DifyApp实例(Flask应用的扩展类) -
config是Flask应用的配置对象
-
from_mapping()方法接收一个字典参数,将字典中的所有键值对添加到应用配置中
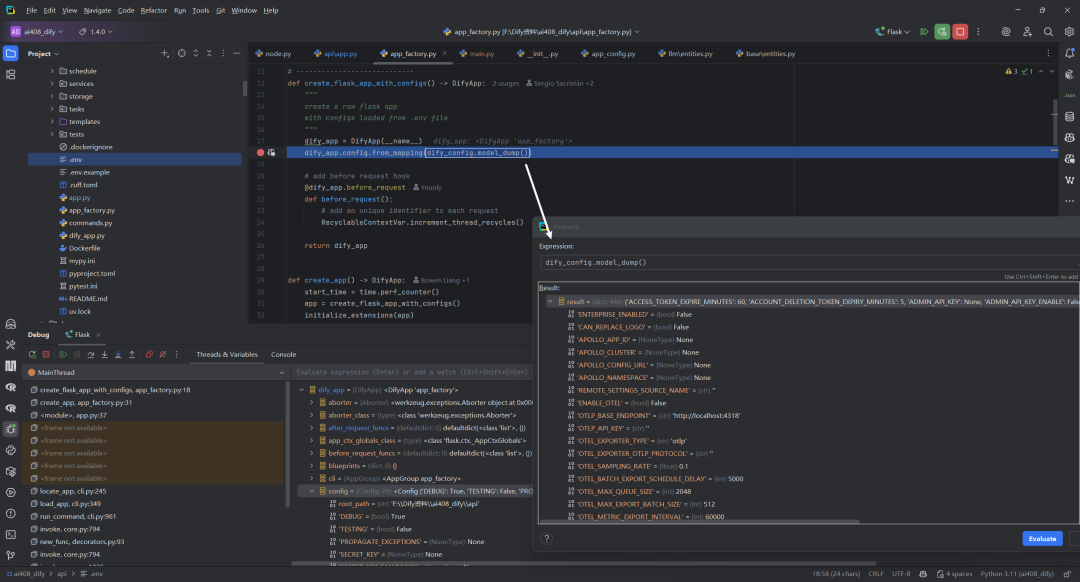
dify_app.config.from_mapping(dify_config.model_dump())代码执行后,dify_app.config内容如下所示:
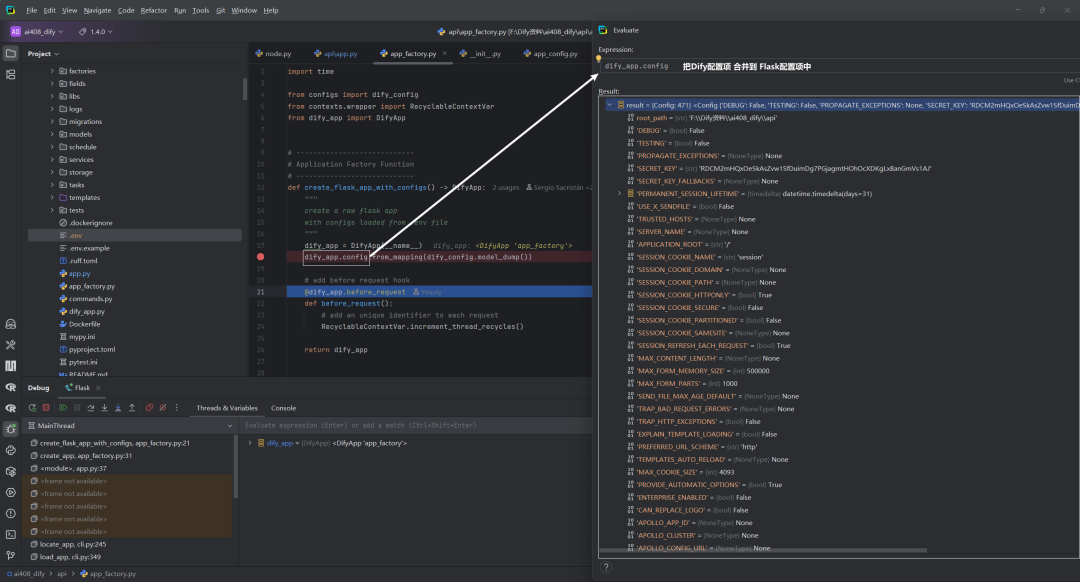
4.整体效果
-
将所有应用配置从Pydantic模型转换为字典格式
-
将这些配置加载到Flask应用实例中
-
使配置可通过
dify_app.config['KEY']形式访问
这是Flask应用工厂模式的典型实现,确保应用启动时正确加载所有必要配置。
四.dify_config = DifyConfig()
源码位置:dify\api\configs\app_config.py
这段代码定义了一个名为 DifyConfig 的配置类,它是整个应用程序配置的核心。该类通过多重继承整合了多个配置模块,并定制了配置加载的行为。
classDifyConfig(
# Packaging info
PackagingInfo,
# Deployment configs
DeploymentConfig,
# Feature configs
FeatureConfig,
# Middleware configs
MiddlewareConfig,
# Extra service configs
ExtraServiceConfig,
# Observability configs
ObservabilityConfig,
# Remote source configs
RemoteSettingsSourceConfig,
# Enterprise feature configs
# **Before using, please contact business@dify.ai by email to inquire about licensing matters.**
EnterpriseFeatureConfig,
):
model_config = SettingsConfigDict(
# read from dotenv format config file
env_file=".env",
env_file_encoding="utf-8",
# ignore extra attributes
extra="ignore",
)
# Before adding any config,
# please consider to arrange it in the proper config group of existed or added
# for better readability and maintainability.
# Thanks for your concentration and consideration.
@classmethod
defsettings_customise_sources(
cls,
settings_cls: type[BaseSettings],
init_settings: PydanticBaseSettingsSource,
env_settings: PydanticBaseSettingsSource,
dotenv_settings: PydanticBaseSettingsSource,
file_secret_settings: PydanticBaseSettingsSource,
) -> tuple[PydanticBaseSettingsSource, ...]:
return (
init_settings,
env_settings,
RemoteSettingsSourceFactory(settings_cls),
dotenv_settings,
file_secret_settings,
)
1.类继承结构
DifyConfig 通过多重继承整合了8个不同的配置组件:
-
PackagingInfo– 包含应用程序的版本、名称等打包信息 -
DeploymentConfig– 部署相关的配置 -
FeatureConfig– 功能开关和特性配置 -
MiddlewareConfig– 中间件相关配置 -
ExtraServiceConfig– 额外服务配置 -
ObservabilityConfig– 可观察性(日志、监控等)配置 -
RemoteSettingsSourceConfig– 远程配置源设置 -
EnterpriseFeatureConfig– 企业版特性配置(需要授权)
2.配置行为设置
model_config = SettingsConfigDict(
env_file=".env",
env_file_encoding="utf-8",
extra="ignore",
)
这部分定义了配置的行为特性:
-
从项目根目录的
.env文件读取配置 -
使用UTF-8编码解析配置文件
-
忽略配置类中未定义的额外属性
3.配置源自定义
这个类方法重写了Pydantic的配置加载机制,自定义了配置源的优先级顺序:
@classmethod
defsettings_customise_sources(cls, ...)
-
init_settings– 初始化时直接传入的配置(最高优先级) -
env_settings– 环境变量中的配置 -
RemoteSettingsSourceFactory– 远程配置源(Apollo或Nacos) -
dotenv_settings– .env文件中的配置 -
file_secret_settings– 文件密钥配置(最低优先级)
这种设计使得配置可以从多个来源加载,并按照特定的优先级顺序覆盖,提供了灵活的配置管理机制。特别是通过添加RemoteSettingsSourceFactory,实现了从远程配置中心动态获取配置的能力。
五.RecyclableContextVar.increment_thread_recycles()
RecyclableContextVar.increment_thread_recycles() 是 Dify 代码里给 ContextVar 做”垃圾回收”用的小钩子,核心目的是——当同一条物理线程被从线程池中反复回收、复用时,主动清掉已经无用的 ContextVar 绑定,避免 Context 对象和旧值在内存里无限堆积。下面按实现思路分解说明:
| 关键点 | 作用 |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
总结:increment_thread_recycles() 只是给 RecyclableContextVar 增加一个”线程被复用的计数器”,当次数到达阈值就把该线程里陈旧的 ContextVar 绑定全部抹掉,防止线程池长期运行时出现隐性内存泄漏。
六.扩展和初始化
1.ext_database.init_app(app)
(1)app: DifyApp
dify\api\extensions\ext_database.py,如下所示:
from dify_app import DifyApp
from models import db
definit_app(app: DifyApp):
db.init_app(app)
因为DifyApp继承自Flask,所以本质上还是Flask应用程序。
(2)db.init_app(app)
该代码是在初始化数据库与应用程序的连接。如下所示:
-
db是从models模块导入的对象,很可能是 Flask-SQLAlchemy 的实例 -
init_app()是 Flask 扩展的标准方法,用于将扩展实例与 Flask 应用绑定 -
app是一个DifyApp类型的应用实例,作为参数传入
这是 Flask 应用中的常见模式,它实现了数据库与应用的关联,使应用能够执行数据库操作。这种方式允许在工厂函数中延迟初始化数据库,是 Flask 推荐的应用构建方式。
2.ext_migrate.init_app(app)
(1)app: DifyApp
dify\api\extensions\ext_migrate.py,如下所示
from dify_app import DifyApp
definit_app(app: DifyApp):
import flask_migrate # type: ignore
from extensions.ext_database import db
flask_migrate.Migrate(app, db)
(2)flask_migrate.Migrate(app, db)
该代码的作用是初始化 Flask-Migrate 扩展,将其与 Flask 应用实例 app 和数据库实例 db 关联起来。
-
Flask-Migrate 是 Flask 的一个扩展,基于 Alembic 构建,用于处理数据库架构迁移。
-
通过这行代码,应用程序获得了以下能力:
-
跟踪数据库模式(schema)变化
-
自动生成迁移脚本
-
应用迁移更新数据库结构
-
在需要时回滚迁移
-
初始化后开发者可使用命令行工具来管理数据库迁移:
-
flask db init– 创建迁移仓库 -
flask db migrate– 生成迁移脚本 -
flask db upgrade– 应用迁移到数据库 -
flask db downgrade– 回滚迁移
这是构建数据库迁移功能的关键一步,使应用能够有序地管理数据库结构的变化。
3.db数据库实例(SQLAlchemy)
dify\api\models\engine.py。这段代码设置了一个 Flask 应用程序的数据库连接引擎,主要功能如下:
from flask_sqlalchemy import SQLAlchemy
from sqlalchemy import MetaData
POSTGRES_INDEXES_NAMING_CONVENTION = {
"ix": "%(column_0_label)s_idx",
"uq": "%(table_name)s_%(column_0_name)s_key",
"ck": "%(table_name)s_%(constraint_name)s_check",
"fk": "%(table_name)s_%(column_0_name)s_fkey",
"pk": "%(table_name)s_pkey",
}
metadata = MetaData(naming_convention=POSTGRES_INDEXES_NAMING_CONVENTION)
# ****** IMPORTANT NOTICE ******
#
# NOTE(QuantumGhost): Avoid directly importing and using `db` in modules outside of the
# `controllers` package.
#
# Instead, import `db` within the `controllers` package and pass it as an argument to
# functions or class constructors.
#
# Directly importing `db` in other modules can make the code more difficult to read, test, and maintain.
#
# Whenever possible, avoid this pattern in new code.
db = SQLAlchemy(metadata=metadata)
(1)导入模块
代码首先导入了必要的 SQLAlchemy 相关模块:
-
SQLAlchemy类:Flask 扩展,用于管理数据库连接 -
MetaData类:用于存储表格、索引等数据库对象信息
(2)PostgreSQL 命名约定
POSTGRES_INDEXES_NAMING_CONVENTION = {
"ix": "%(column_0_label)s_idx",
"uq": "%(table_name)s_%(column_0_name)s_key",
"ck": "%(table_name)s_%(constraint_name)s_check",
"fk": "%(table_name)s_%(column_0_name)s_fkey",
"pk": "%(table_name)s_pkey",
}
这个字典定义了数据库中各种对象的命名规则:
-
ix:索引的命名格式
-
uq:唯一约束的命名格式
-
ck:检查约束的命名格式
-
fk:外键约束的命名格式
-
pk:主键约束的命名格式
(3)元数据配置
使用上述命名约定创建一个 MetaData 对象,确保数据库对象遵循统一的命名规则。
(4)数据库对象创建
最后创建了 SQLAlchemy 实例 db,同时附带了重要的使用说明:
-
避免在
controllers包外直接导入和使用db -
推荐在
controllers包中导入db并作为参数传递 -
这种做法有助于提高代码的可读性、可测试性和可维护性
这种设计模式遵循了依赖注入原则,使得代码更易于单元测试和维护。
参考文献
[0] app_factory.py中的create_migrations_app()函数:https://z0yrmerhgi8.feishu.cn/wiki/M7ugwP8Zdiwguok5ZT4cewldnzb
[1] contextvars — Context Variables:https://docs.python.org/3/library/contextvars.html
[2] gevent.contextvars – Cooperative contextvars:https://www.gevent.org/api/gevent.contextvars.html
[3] Flask-SQLAlchemy:https://flask-sqlalchemy.readthedocs.io/en/stable/
[4] flask-sqlalchemy github:flask-sqlalchemy
[5] SQLAlchemy :https://www.sqlalchemy.org/
[6] sqlalchemy github:https://github.com/sqlalchemy/sqlalchemy
[7] Flask-Migrate:https://flask-migrate.readthedocs.io/en/latest/
[8] Flask-Migrate 4.1.0:https://pypi.org/project/Flask-Migrate/
[9] Flask-Migrate github:https://github.com/miguelgrinberg/Flask-Migrate
知识星球服务内容:Dify源码剖析及答疑,Dify对话系统源码,NLP电子书籍报告下载,公众号所有付费资料。加微信buxingtianxia21进NLP工程化资料群。
(文:NLP工程化)