


本文的第一作者罗琪竣、第二作者李梦琦为香港中文大学(深圳)计算机科学博士生,本文在上海交通大学赵磊老师、香港中文大学(深圳)李肖老师的指导下完成。
长序列训练对于模型的长序列推理等能力至关重要。随着序列长度增加,训练所需储存的激活值快速增加,占据训练的大部分内存。即便使用梯度检查点(gradient checkpointing)方法,激活值依然占据大量内存,限制训练所能使用的序列长度。
来自港中文(深圳)和上海交通大学的团队提出 StreamBP 算法。通过对链式法则进行线性分解和分步计算,StreamBP 将大语言模型训练所需的激活值内存(logits 和 layer activation)降低至梯度检查点(gradient checkpointing)的 20% 左右。

-
论文标题:StreamBP: Memory-Efficient Exact Backpropagation for Long Sequence Training of LLMs
-
论文:
https://arxiv.org/abs/2506.03077 -
代码:
https://github.com/Ledzy/StreamBP
在相同内存限制下,StreamBP 最大序列长度为梯度检查点的 2.8-5.5 倍。在相同序列长度下,StreamBP 的速度和梯度检查点接近甚至更快。StreamBP 适用于 SFT、GRPO、PPO 和 DPO 等常见 LLM 目标函数。代码已开源,可集成至现有训练代码。
激活值内存和梯度检查点
在反向传播(Backpropagation, BP)的过程中,计算模型梯度需要用到模型的中间输出(激活值)。举例来说,对于模型中的线性变换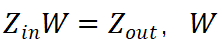 的梯度为
的梯度为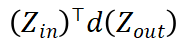 ,因而计算
,因而计算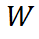 的梯度时需要储存相应的激活值
的梯度时需要储存相应的激活值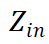 。
。
对于模型中的任意函数变换 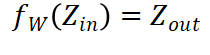 的梯度由以下链式法则计算:
的梯度由以下链式法则计算:
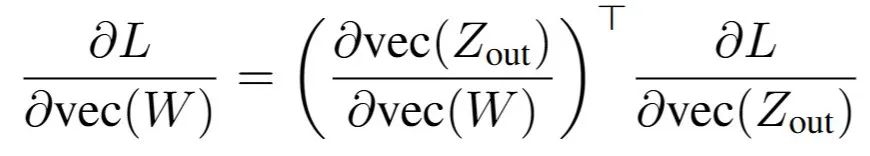
其中 为目标函数,
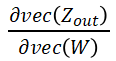
为了减少激活值的内存消耗,梯度检查点(gradient checkpointing)方法在 forward 时只储存每一层网络的输入,而不储存该层的中间值。在 backward 至该层时,将重新 forward 此层输入来计算得到该层激活值。使用梯度检查点时储存的激活值包括:
-
所有层的输入,一般为激活值内存的 5%-15%。 -
单层的完整激活值,占据超过 85% 的激活值内存。
StreamBP 的核心思想
不同于梯度检查点,StreamBP 避免储存单层的完整激活值,而将单层的 BP 过程进行线性分解,序列化计算并累加。注意到对于函数变换 ,链式法则存在以下线性分解:
,链式法则存在以下线性分解:
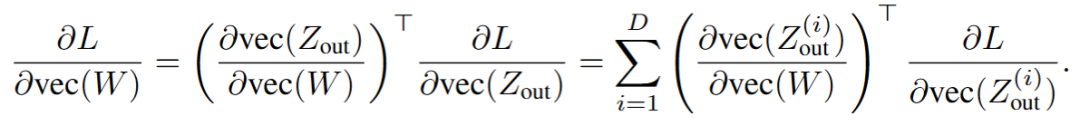
StreamBP 基于以下观察:对于 LLM 中的大部分函数变换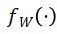 ,如 Transformer 层、lmhead 层,可通过策略性地将输出分块
,如 Transformer 层、lmhead 层,可通过策略性地将输出分块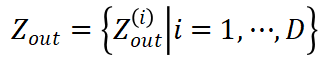 ,使得计算块 Jacobian-vector product
,使得计算块 Jacobian-vector product 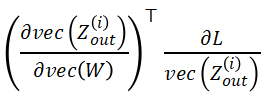 所需的激活值远小于计算完整的 Jacobian-vector product。基于该观察,StreamBP 依次计算上式中 D 个块的 Jacobian-vector product 并累加,得到准确的梯度。
所需的激活值远小于计算完整的 Jacobian-vector product。基于该观察,StreamBP 依次计算上式中 D 个块的 Jacobian-vector product 并累加,得到准确的梯度。
为了计算块 Jacobian-vector product,需要分析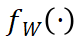 输入和输出的相关性,每次 forward 块输入
输入和输出的相关性,每次 forward 块输入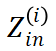 得到块输出
得到块输出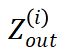 ,建立对应子计算图。以简单的线性变换
,建立对应子计算图。以简单的线性变换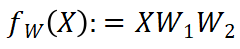 为例,输出和输入在行维度上一一对应。StreamBP 按行分块,每次计算单行的 Jacobian-vector product 并累加。下图对比了标准 BP 和 StreamBP 在上述线性变换下的实现:
为例,输出和输入在行维度上一一对应。StreamBP 按行分块,每次计算单行的 Jacobian-vector product 并累加。下图对比了标准 BP 和 StreamBP 在上述线性变换下的实现:
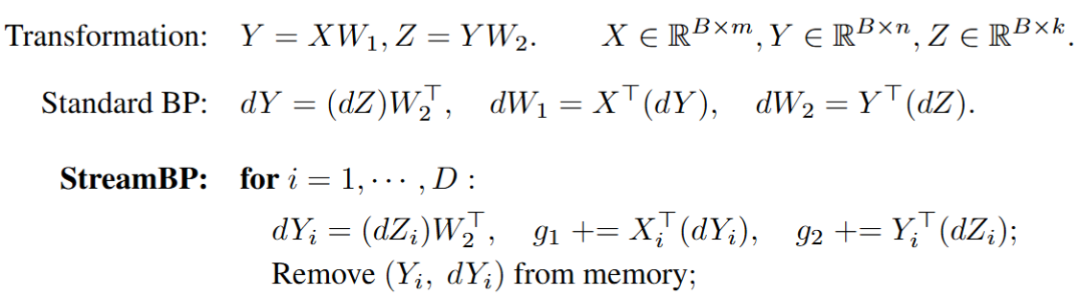
D 步累加得到的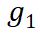 和
和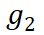 即为
即为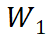 和
和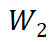 准确梯度。相比于标准 BP,StreamBP 仅需储存
准确梯度。相比于标准 BP,StreamBP 仅需储存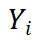 和
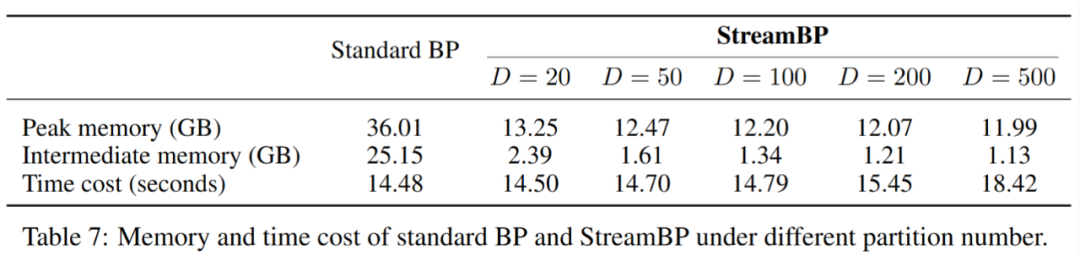
和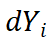 ,且总计算 FLOPs 相同。下表为 StreamBP 和标准 BP 的内存和时间对比:
,且总计算 FLOPs 相同。下表为 StreamBP 和标准 BP 的内存和时间对比:
LLM 训练中的 StreamBP
StreamBP 应用于 LLM 中的 Transformer 层和 lmhead 层,分别用于降低层激活值和 logits 的内存消耗。
与线性变换不同,由于 Transformer 层存在注意力机制,块输出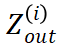 并非仅由对应位置的块输入
并非仅由对应位置的块输入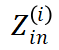 决定,而与该块及以前所有位置的输入
决定,而与该块及以前所有位置的输入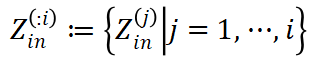 都有关。StreamBP 利用只与块
都有关。StreamBP 利用只与块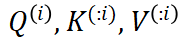 有关的性质,建立了如下计算图:
有关的性质,建立了如下计算图:
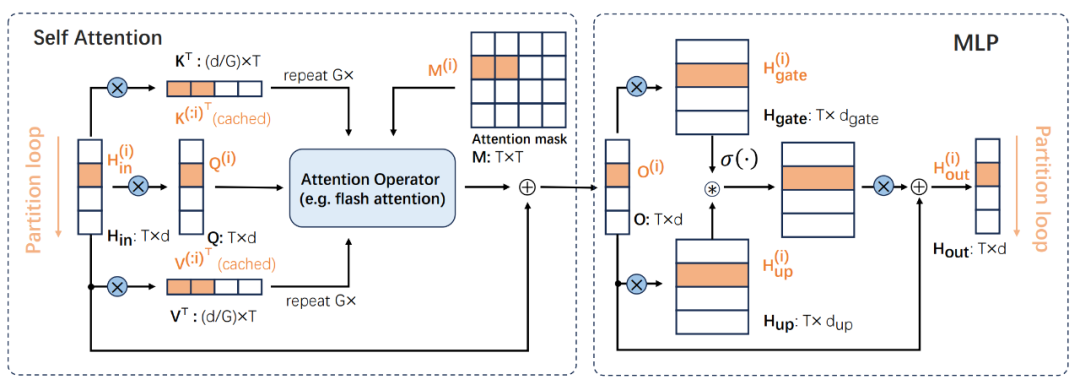
StreamBP 所需储存的激活值和注意力掩码(橙色)大幅低于梯度检查点(橙色 + 白色部分)。
对于 lmhead 层,当以 SFT 或 GRPO 为目标函数时,观察到不同位置的 logits 对于目标函数的影响相互独立。因此,StreamBP 从序列维度分块,每次计算单块损失函数的梯度,从而只需储存单块 logits 和 logits 梯度。
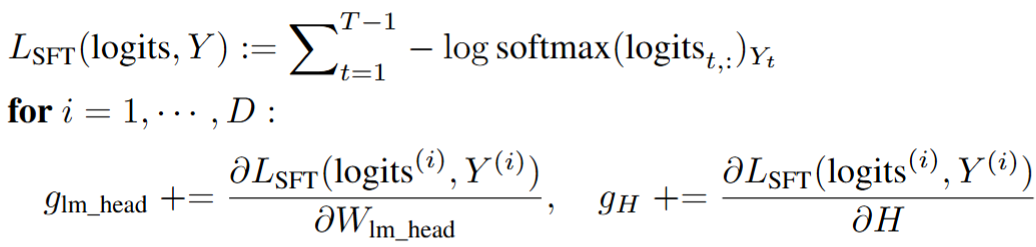
图:StreamBP for SFT
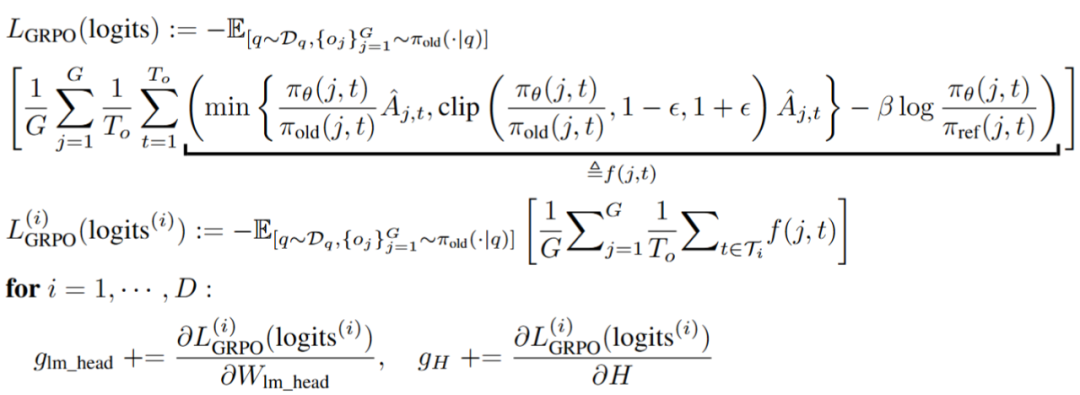
图:StreamBP for GRPO
对于 DPO,由于非线性 sigmoid 函数的存在,每个位置的 logits 对于目标函数的影响并不独立。StreamBP 利用 logits 梯度在序列维度的独立性,分块进行梯度计算。
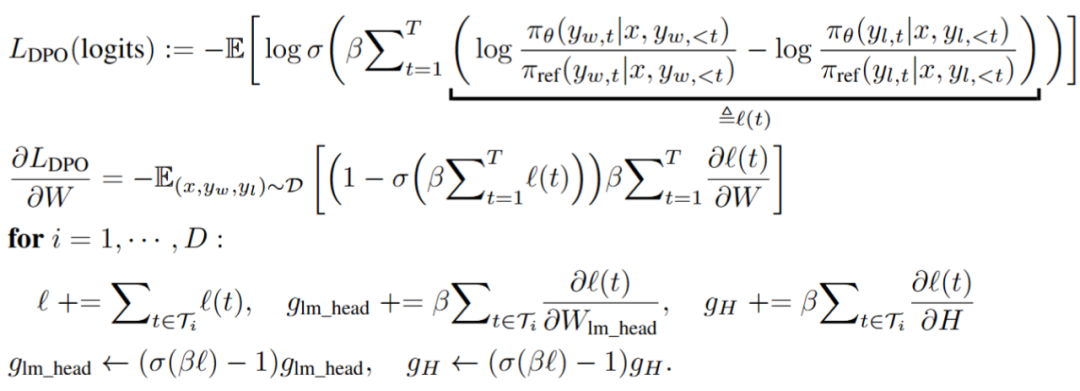
图:StreamBP for DPO
实验结果
我们在单张 A800-80GB GPU 上测试了不同大小的模型,StreamBP 的最大 BP 序列长度为标准 BP 的 23-36 倍,梯度检查点的 2.5-5.5 倍。
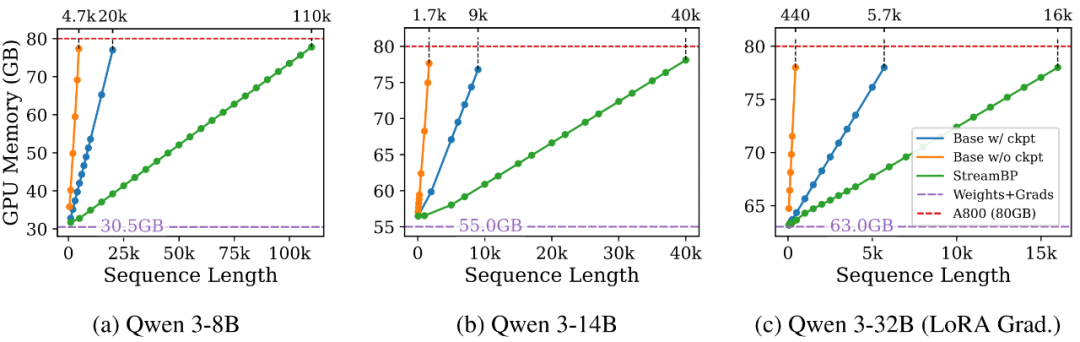
图:不同序列长度下的 BP 峰值内存
在现有 Transformers 框架下,StreamBP 的实现可避免计算掩码部分的 pre-attention score(见论文 3.2.2 部分),在长序列训练下相较于梯度检查点实现了加速。
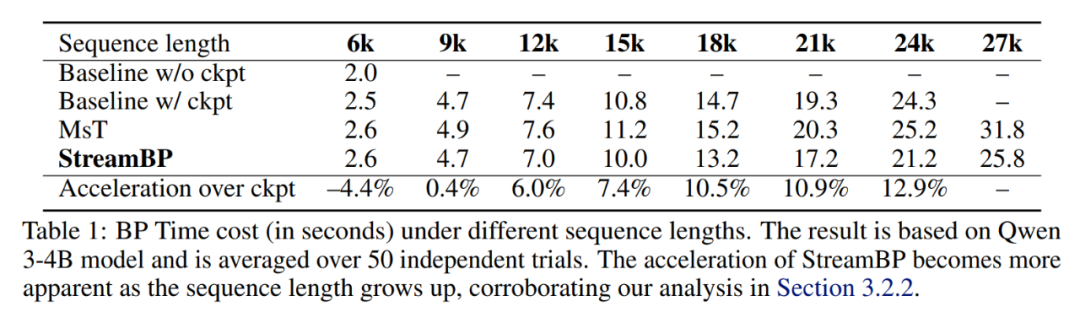
通过使用 StreamBP,不同目标函数下最大的序列长度得到了大幅提升。在同样的序列长度下,StreamBP 允许更大的批处理大小以加速训练。


表:Qwen 3-4B 单个样本 BP 时间,序列长度为 9000。
在 Deepspeed ZeRO 分布式训练模式下,Distributed StreamBP 比梯度检查点的最大可训练序列长度提升了5—5.6倍。

©
(文:机器之心)