

国内著名大模型平台月之暗面(MoonshotAI)对其开源的多模态模型Kimi-VL-A3B-Thinking进行了大升级,发布了2506版本。
开源地址:https://huggingface.co/moonshotai/Kimi-VL-A3B-Thinking-2506
在线demo:https://huggingface.co/spaces/moonshotai/Kimi-VL-A3B-Thinking
在性能表现上,Kimi-VL-A3B-Thinking-2506实现了更聪明且更省token的突破。在多模态推理基准测试中取得了更好的准确性:MathVision上达到56.9(提升20.1),MathVista上为80.1(提升8.4),MMMU-Pro上是46.3(提升3.2),MMMU上为64.0(提升2.1),同时平均所需的思考长度减少了20%。
视觉理解能力方面,模型做到了“边思考边看得更清晰”。不同于前一版本专注于思考任务,2506版本在常规视觉感知与理解任务上也达到了同等甚至更好的能力。
例如,在MMBench-EN-v1.1上得分为84.4,MMStar上为70.4,RealWorldQA上是70.0,MMVet上为78.4,超越了非思考模型Kimi-VL-A3B-Instruct的能力,展现出更全面的视觉理解实力。
此外,模型还实现了更高分辨率的支持。2506版本支持单张图像320万总像素(1792×1792),是前一版本的4倍。使得模型在高分辨率感知和OS-agent接地基准测试中取得了显著进步:在V*Benchmark上得分为83.2,ScreenSpot-Pro上为52.8,OSWorld-G上为52.5,能够更好地处理高清晰度图像相关任务。
在使用方面,2506版本在图像理解、图表推理、数学计算、OS智能体接地、长PDF理解和视频分析等多个领域都有出色表现,并且支持特定回答模式和思考链。
例如,在图像理解中,能准确识别猫的品种、高分辨率图像内容等;在图表推理中,可正确分析不同模型在特定类别下的语义标签准确率;在数学计算里,轻松解决数字填空谜题;

在OS智能体接地任务中,精准定位并点击界面元素;在长PDF理解时,深入分析文档内容得出基准测试中的最先进模型及其性能;在视频理解方面,将视频精准拆分为多个场景并详细描述。
根据月之暗面之前公布的技术报告显示,Kimi-VL-A3B-Thinking是一个多模态专家混合模型,主要由MoonViT、MLP投影器、专家混合模型三大块组成。
原生分辨率视觉编码器MoonViT,可直接处理不同分辨率的图像,无需借助复杂的子图像分割和拼接操作。
借鉴了NaViT中的打包方法,将图像分割成小块,然后将这些小块展平并顺序连接成1D序列。这种预处理方式使得MoonViT能够与语言模型共享相同的核心计算操作,例如支持可变长度序列注意力机制的FlashAttention,从而确保了不同分辨率图像的训练吞吐量不受影响。
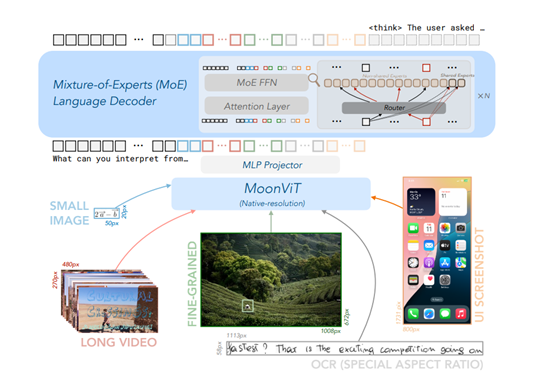
MoonViT的初始权重来源于SigLIP-SO-400M,该模型原本采用可学习的固定大小绝对位置嵌入来编码空间信息。然而,当图像分辨率增加时,这种原始位置嵌入会逐渐变得不适用。为了解决这一问题,Kimi-VL引入了2D旋转位置嵌入,在高度和宽度维度上对细粒度的位置信息进行编码,并将其与原始位置嵌入相结合。
这种结合方式使得MoonViT能够高效地处理不同分辨率的图像,同时无缝地融入到整个模型的架构中。
MLP投影器则采用了双层架构,在视觉编码器和语言模型之间起到了至关重要的桥梁作用。MLP投影器首先通过像素洗牌操作对MoonViT提取的图像特征进行空间维度的压缩。这一操作通过执行2×2的下采样,在空间域中对特征进行降维,同时相应地扩展通道维度。

随后,将像素洗牌后的特征输入到两层MLP中,将其投影到与LLM嵌入维度相同的维度上。这一过程为后续训练阶段的顺利进行提供了有力支持,确保了视觉特征能够以合适的形式被语言模型所接收和处理。
Kimi-VL-A3B-Thinking的语言模型基于Moonlight模型,这是一种28亿激活参数、160亿总参数的专家混合模型。其架构与DeepSeek-V3相似,从Moonlight的预训练阶段的一个中间检查点初始化。这个中间检查点已经处理了5.2万亿纯文本数据标记,并激活了8192个标记的上下文长度。

在此基础上,继续使用总计2.3万亿标记的多模态和纯文本数据进行联合预训练。这种联合预训练的方式使得模型能够同时提升其语言能力和多模态理解能力,为后续的各种应用奠定了坚实的基础。
在优化器方面,Kimi-VL采用了增强版的Muon优化器。与原始Muon优化器相比,该版本在多个方面进行了改进。首先,它添加了权重衰减,这有助于控制模型的复杂度,防止过拟合现象的发生。
其次,对每个参数的更新比例进行了精心调整,以实现更优的训练效果。此外,还开发了遵循ZeRO-1优化策略的Muon优化器分布式实现。这种分布式实现不仅提高了内存的使用效率,降低了通信开销,还保留了算法的数学特性,从而在整个训练过程中为模型的优化提供了有力保障。
(文:AIGC开放社区)