

音乐生成领域迎来重磅突破!腾讯AI Lab最新开源了一款高保真音乐生成模型:LeVo。

近年来,大型语言模型(LLMs)和语音模型的进步显著提升了音乐生成,特别是在歌词到歌曲的生成方面。
然而,现有方法在歌曲的复杂结构和高质量数据的稀缺性上仍面临挑战,导致音质、音乐性、指令遵循和声乐-乐器和谐方面的局限性。
所以为了解决这些挑战,腾讯AI实验室引入了 LeVo,一个基于LM的框架,由LeLM和音乐编解码器组成。
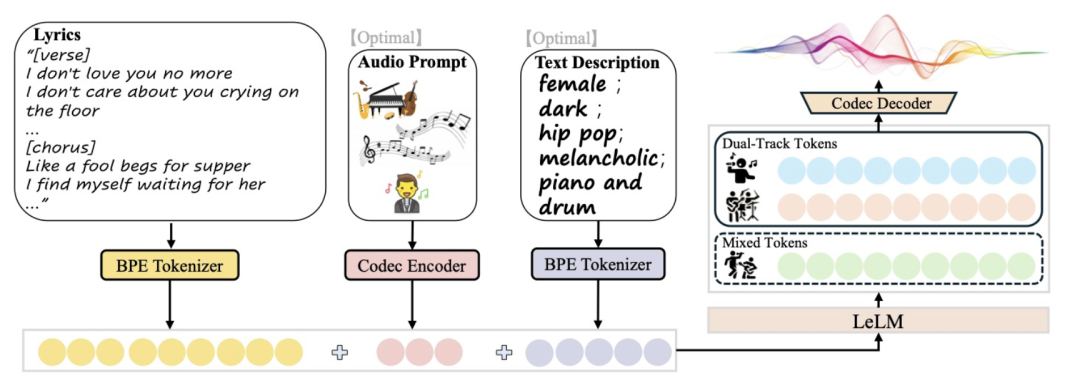
LeLM能够并行建模两种类型的标记:混合标记,代表人声和伴奏的混合音频,以实现人声-乐器和谐,以及双轨标记,分别编码人声和伴奏,用于高质量歌曲生成。
它采用两个仅解码器的Transformer和一个模块化扩展训练策略,以防止不同标记类型之间的干扰。
为了进一步增强音乐性和指令遵循,还引入了一种基于直接偏好优化(DPO)的多偏好对齐方法。该方法通过半自动数据构建过程和DPO微调处理多样化的用户偏好。
实验结果表明,LeVo在客观和主观指标上均优于现有方法。
LeVo支持零样本风格迁移,可根据参考音频或文本描述生成特定风格和情感的歌曲。支持中英文歌曲生成,歌词匹配度方面超Suno等闭源模型。
核心功能
-
• 高保真歌曲生成:支持中英文歌词,生成48kHz立体声音频,音质媲美Suno。 -
• 零样本风格迁移:根据参考音频提取风格、节奏、音色,生成类似歌曲。 -
• 文本控制生成:通过描述(如“男声、悲伤、流行、钢琴/鼓”)控制歌曲风格和情感。 -
• 双轨建模:支持混合令牌(人声+伴奏)和双轨令牌(分开编码人声和伴奏),确保人声-乐器和谐。 -
• 模块化训练:使用双解码器Transformer和模块化扩展训练策略,避免令牌干扰。
快速部署
如果想直接体验的,官方有部署好的Hugging Face应用空间,可直接访问试用。
对于有本地部署需求的可按照下面步骤进行。部署环境要求:Python>=3.8.12和CUDA>=11.8。
克隆项目:
git clone https://github.com/tencent-ailab/SongGeneration.git安装依赖:
pip install -r requirements.txt --no-deps
pip install https://github.com/Dao-AILab/flash-attention/releases/download/v2.6.3/flash_attn-2.6.3+cu118torch2.2cxx11abiFALSE-cp310-cp310-linux_x86_64.whl也可以通过Docker快速部署启动:
docker pull juhayna/song-generation-levo:v0.1
docker run -it --gpus all --network=host juhayna/song-generation-levo:v0.1 /bin/bash同时开源社区已有搭建对接好的ComfyUI工作流供使用:
https://github.com/smthemex/ComfyUI_SongGeneration对于输入格式,都有严格的结构,可以参考 sample/lyrics.jsonl 示例文件和项目文档进行操作(由于指南内容相对过多,这里就省略了)。
适用场景
LeVo的高保真和灵活控制让它适用于多种场景:
-
• 短视频BGM:生成流行/爵士背景音乐,适配抖音、YouTube。 -
• 歌曲Demo:快速生成中英文歌曲草稿,音乐人试水创意。 -
• 游戏音效:为RPG生成“悲伤钢琴”主题曲。 -
• 播客配乐:定制“温暖男声”开场曲,提升氛围。 -
• 风格实验:用参考音频迁移爵士到摇滚,探索新流派。
写在最后
LeVo 的开源代码和权重,也会降低音乐生成门槛,对于更多音乐数据训练提供进一步研究。
双轨建模和DPO优化确保高保真输出,零样本风格迁移满足多样化创作需求。
也相信腾讯AI Lab未来对于优化LeVo有更加深入的计划,比如:更长音乐生成、更多语言扩展、实时生成等方面。
国产大模型(多模态、语音、音乐等)正在一步步走向世界,国产AI也必将走向全世界,在此为他们点个赞。
GitHub 项目地址:https://github.com/tencent-ailab/songgeneration/
HF 体验地址:https://huggingface.co/spaces/tencent/SongGeneration

● 一款改变你视频下载体验的神器:MediaGo
● 字节把 Coze 核心开源了!可视化工作流引擎 FlowGram 上线,AI 赋能可视化流程!
● 英伟达开源语音识别模型!0.6B 参数登顶 ASR 榜单,1 秒转录 60 分钟音频!
● 开发者的文档收割机来了!这个开源工具让你一小时干完一周的活!
● PDF文档解剖术!OCR神器+1,这个开源工具把复杂排版秒变结构化数据!

(文:开源星探)