跳至内容


智东西6月20日报道,生成式AI正以前所未有的速度渗透进我们的日常生活,但鲜少有人关注其背后的环境代价。OpenAI CEO Sam Altman曾透露,ChatGPT单次查询平均消耗0.34瓦时能源,相当于烤箱运行1秒多的耗电量,但凭借AI公司偶尔披露的零星数据,研究者无法对模型的能耗进行系统性评估。
昨日,一项针对DeepSeek、Qwen、Llama、Cogito等14个开源大模型的研究,填补了这一空白,让业内直观看到了不同类型、不同参数规模的模型在能耗、碳排量和性能之间的差异。
在回答同类问题时,具备推理能力的模型能耗与碳排量为非推理模型的4-6倍,然而,这并未给模型答题的准确率带来对应的提升,轻量级模型反而在某些简单任务上展示出更高的能效。
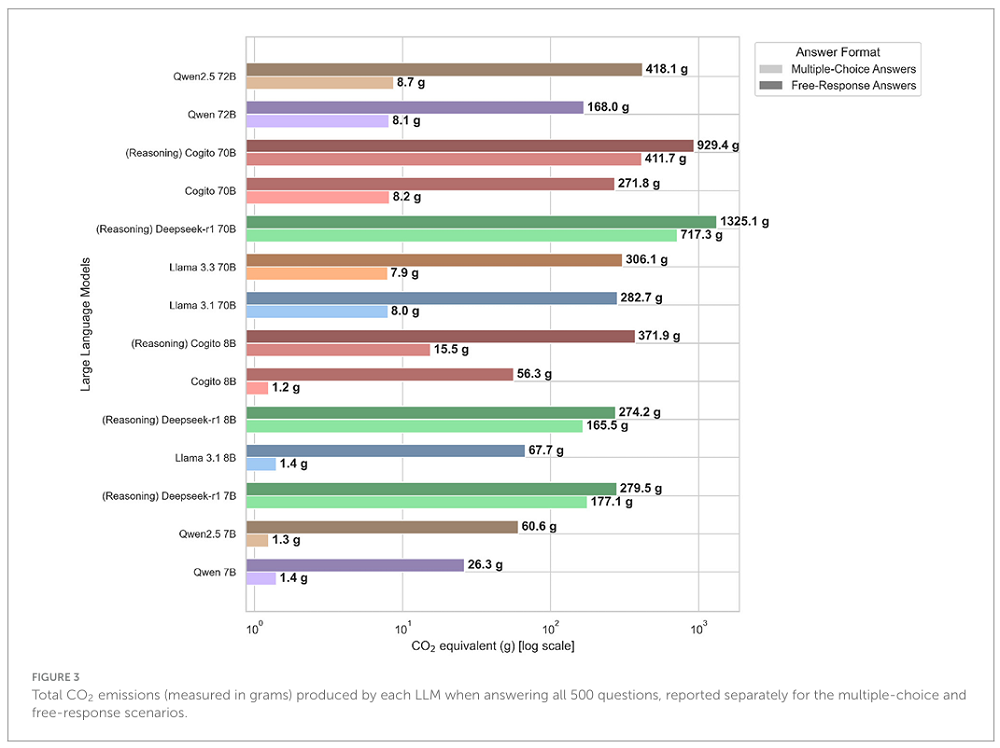
在所有模型中,DeepSeek-R1 70B的平均碳排放量是最高的,其回答1道抽象代数问题会排放4.8g二氧化碳,相当于使用了0.01度电,能让一只5W的灯泡持续亮灯2小时。来自硅谷新锐AI创企Deep Cogito的混合推理模型,在能耗和准确率上取得了不错的平衡。
研究还用真实数据,揭示了AI“过度思考”的问题。推理模型在回答不同难度的问题时都会倾向于生成更多token、使用更多的计算资源,这导致了更高的排放量。同时,像抽象代数这样的符号化和抽象领域对计算的需求更高,且准确率更低。
这一研究于昨日发表在国际期刊《通信前沿》上,研究者让上方14款开源大模型各自回答了1000道问题,涉及抽象代数、高中数学、高中世界历史、国际法、哲学这5个领域的内容,记录了每个模型所使用的能源,并将其换算为碳排量。
https://www.frontiersin.org/journals/communication/articles/10.3389/fcomm.2025.1572947/full
这篇论文的主要作者Maximilian Dauner称:“我们并不总是需要最大、最密集的模型来回答简单的问题,目标应该是为正确的任务选择正确的模型。”
为评估模型能耗,研究者在本地的英伟达A100集群上部署了14款开源大模型,并使用高性能计算应用能源基准测试Perun框架对其能耗进行测量。研究者还将能耗按照480 gCO₂/kWh的排放因子进行换算,以计算对应的碳排量,这一因子代表了目前全球的平均值。
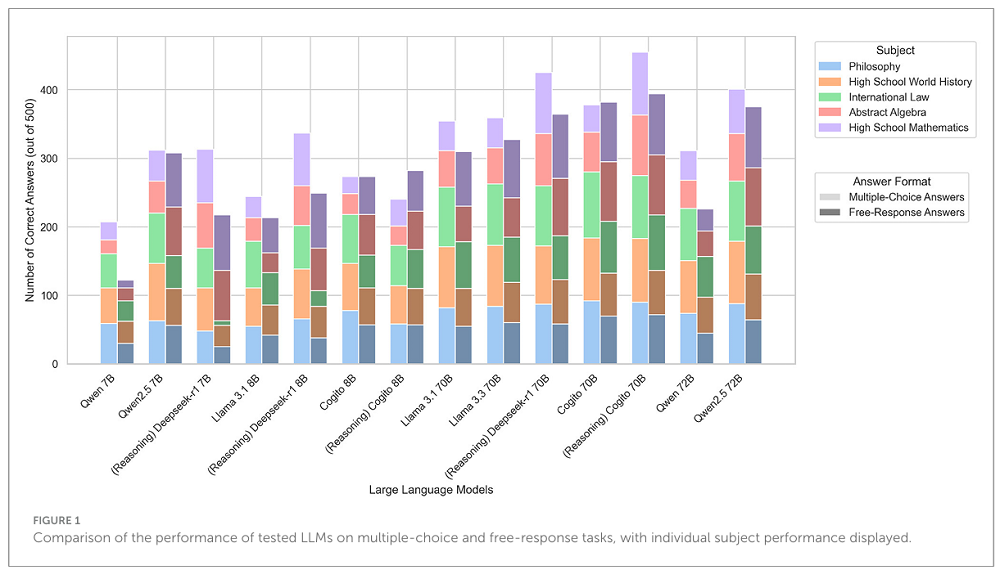
研究使用的问题主要来自于MMLU基准测试,涵盖了不同教育水平、不同领域。在多项选择和自由回答两类问题上,参数规模更大的模型始终保持了领先优势。开启推理模式的Cogito 70B的正确率排名第一,而DeepSeek-R1 70B的正确率排名第二。
除了不同模型的准确性之外,这一研究还分析了模型在回答问题时产生的token数量。在多项选择题中,模型平均每题生成37.7个token,而推理模型则需要额外使用543.5个token。
按学科划分,高中数学题的答案最长,而抽象代数则需要最高的思考开销(平均每题865.5个toekn)。研究中记录到的最大推理长度(6716个token)来自于Deepseek-R1 7B模型在回答一道抽象代数问题时的思考。
下图则反映了模型回答问题时的平均碳排量,这一数字从1.2克到1325.1克不等,模型的参数规模、是否开启推理模式,都会直接影响平均碳排量。总体而言,推理模型的碳排量明显高于非推理模型。
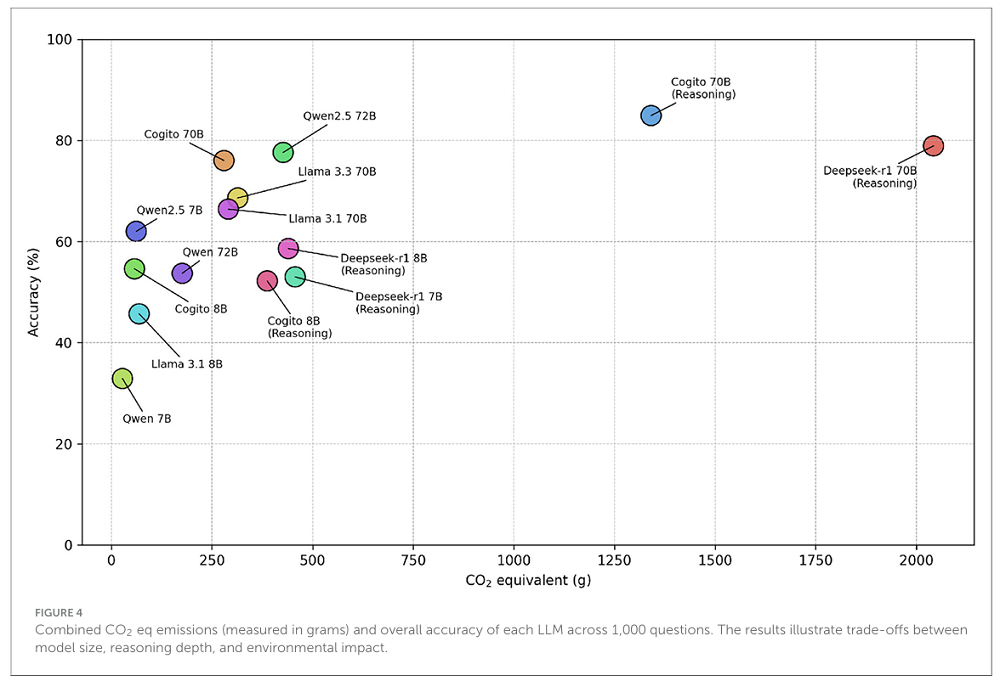
同时,研究者还将碳排量与准确性放到了同一张图表上进行关联研究。随着模型规模的增加,准确性往往有所提高。然而,这种提升也与二氧化碳当量排放量和生成token数量的显著增长密切相关。
最小的模型Qwen 7B拥有最低的碳足迹,但准确率仅为32.9%。相反,最大的推理模型Deepseek-R1 70B碳排量最高,但准确率达到78.9%。
值得注意的是,开启推理模式的Cogito 70B展现出了性能和效率之间的平衡,实现了最高的84.9%准确率,同时碳排放还比DeepSeek-R1 70B模型少34.3%。这表明为大模型添加推理组件可以在不大幅增加碳排量的情况下显著提高准确性。
研究者承认,这一研究尚未覆盖千亿参数规模的大模型,测试排放量时使用的GPU型号也并非当下最新、能效比最高的,因此研究结论无法直接外推到其他AI系统上。数据中心所使用的能源类型也会对碳排放量有明显影响。
尽管这项研究存在局限性,但它仍然让业界看到了能耗与模型准确性之间的关系。研究者称,优化推理效率和回答的简洁性,尤其是在像抽象代数这样具有挑战性的学科中,对于推动更可持续、更环保的AI技术发展至关重要。
目前,业内已有企业在探索“推理预算”、混合推理模型等能够对模型推理长度做出一定限制的方法,但这些方法究竟能带来多少能效的提升,仍有待进一步观察。
(文:智东西)