


近年来,强化学习 (RL) 在提升大型语言模型 (LLM) 的链式思考 (CoT) 推理能力方面展现出巨大潜力,其中直接偏好优化 (DPO) 和组相对策略优化 (GRPO) 是两大主流算法。
如今,这股 RL 的浪潮也涌向了图像生成领域。当我们将自回归图像生成也视为一种序列化的 CoT 推理过程时,一个核心问题浮出水面:DPO 和 GRPO 在这个新战场上表现如何?它们各自的优势、挑战以及最佳实践又是什么?
近日,一篇来自香港中文大学、北京大学及上海人工智能实验室的最新研究给出了答案。该研究首次对 GRPO 和 DPO 算法在自回归图像生成中的应用进行了全面深入的比较,不仅评估了它们在域内(in-domain)和域外(out-of-domain)的性能,还细致探究了不同奖励模型及扩展策略对其能力的影响。

-
论文标题:Delving into RL for Image Generation with CoT: A Study on DPO vs. GRPO
-
论文链接:https://arxiv.org/abs/2505.17017
-
代码链接:https://github.com/ZiyuGuo99/Image-Generation-CoT
与 LLM 的 CoT 推理不同,图像生成的 CoT 面临着独特的挑战,例如确保文本 – 图像一致性、提升图像美学质量以及设计复杂的奖励模型(而非简单的基于规则的奖励)。现有工作虽然已将 RL 引入该领域,但往往缺乏对这些领域特定挑战以及不同 RL 策略特性的深入分析。
该团队的这项新研究填补了这一空白,为我们揭示了 DPO 和 GRPO 在图像生成领域的「相爱相杀」和「各自为王」。
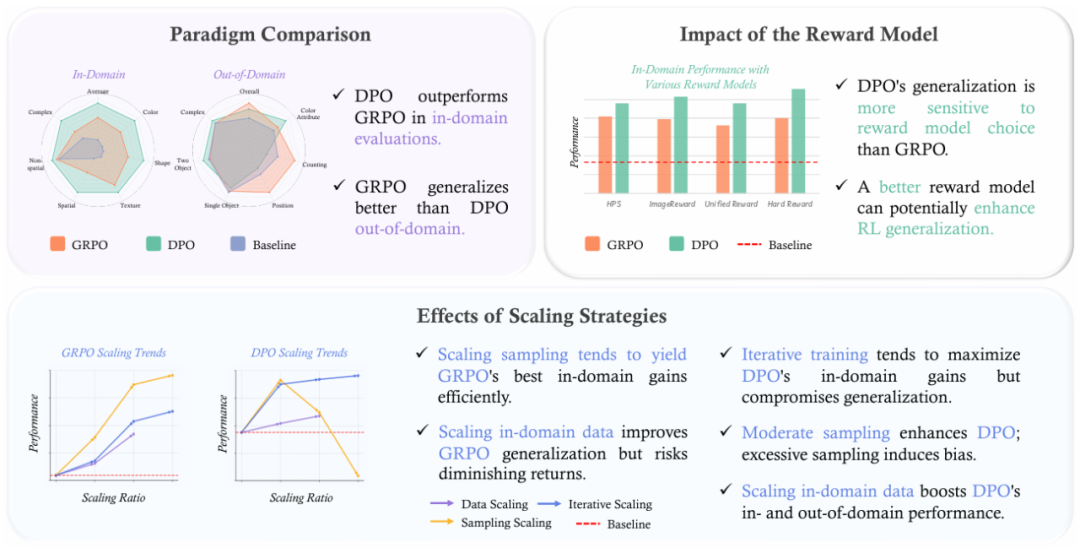
图 1: GRPO 与 DPO 在自回归图像生成中的研究总览,涵盖了域内域外性能对比、不同奖励模型的影响以及扩展策略的效果。
研究核心发现概览
研究团队以最新的自回归图像生成模型 Janus-Pro 为基线,在 T2I-CompBench (域内、长文本复杂场景) 和 GenEval (域外、短文本模板化) 数据集上进行了细致评估。核心发现可归纳为三大方面:
1. 域内性能 vs. 域外泛化:DPO 与 GRPO 各擅胜场
-
DPO 称雄域内: 实验结果显示,离策略 (off-policy) 的 DPO 方法在域内任务上表现优于 GRPO。在 T2I-CompBench 数据集上,DPO 的平均性能比 GRPO 高出约 11.53%;在使用官方评估工具作为奖励信号时,DPO 甚至能达到 7.8% 的峰值提升。这突显了 DPO 在域内任务上的有效性和鲁棒性。
-
GRPO 泛化更强: 与之相反,在策略 (on-policy) 的 GRPO 在域外泛化能力上表现更出色。在 GenEval 数据集上,GRPO 始终展现出比 DPO 更好的泛化性能;在使用 HPS 奖励模型时,GRPO 的峰值提升甚至比 DPO 高出 2.42%。
2. 奖励模型的影响:DPO 更敏感,优质奖励模型提升 RL 泛化
-
DPO 对奖励模型选择更敏感: 研究发现,DPO 的泛化性能对奖励模型的选择比 GRPO 更为敏感,表现为更大的域外性能波动。GRPO 在 GenEval 上的性能方差为 0.5486,显著低于 DPO 的 0.9547。
-
奖励模型的内在泛化能力至关重要: 一个具有更强内在泛化能力的奖励模型,能够潜在地提升 RL 算法的整体泛化性能。研究中,不同奖励模型(如 HPS、ImageReward、Unified Reward 等)在 GenEval 上的表现排序,与它们通过 GRPO 或 DPO 优化后的 RL 模型表现排序高度一致。
3. 有效扩展策略的探索:因材施教,DPO 与 GRPO 策略迥异
研究团队系统探索了三种主流扩展策略:扩展每个提示生成的样本图像数量、扩展域内训练数据的多样性和体量,以及采用迭代训练方法。
-
对于 GRPO:
-
扩展采样图像数量能带来更高效的域内性能提升。
-
适度扩展采样规模和域内数据有助于改善泛化能力,但过度扩展可能导致过拟合。
-
对于 DPO:
-
迭代训练倾向于最大化域内性能,但在多轮迭代后可能损害泛化能力。
-
适度采样能锐化偏好对比,优化域内和域外性能;但过度采样会引入偏差。
-
扩展域内数据通过缓解小数据集带来的偏好范围局限,能同时提升域内和域外性能。
研究细节与洞察
研究团队首先明确了任务设定:自回归图像生成模型(如 LlamaGen、Show-o、Janus-Pro)通过将图像转换为离散 token 序列进行预测,其过程与 LLM 的文本生成类似,因此可以无缝集成 DPO 和 GRPO 的损失机制。
在 DPO 与 GRPO 的对比中,研究者确保了两者在计算成本上的可比性。例如,DPO 中每个 prompt 生成的图像数量与 GRPO 中的组大小对齐,并使用相同的奖励模型。
结果清晰地显示,DPO 凭借其对预收集静态数据的有效利用,在域内场景(如 T2I-CompBench 的复杂长描述)中表现更佳。而 GRPO 通过迭代优化策略和在线采样,更能适应复杂任务分布,从而在域外场景(如 GenEval 的模板化短描述)中展现出更强的泛化性。

图 2: 域内与域外性能对比的可视化结果。
在奖励模型影响的分析中,研究团队考察了三类奖励模型:基于人类偏好的模型 (HPS, ImageReward)、视觉问答模型 (UnifiedReward, Ft. ORM) 和基于度量的奖励模型。
一个有趣的发现是,奖励模型自身的泛化能力(通过 best-of-N 策略在 GenEval 上评估得到)与通过 RL 算法(DPO 或 GRPO)训练后模型的泛化能力排序高度吻合(Unified Reward > Image Reward > HPS Reward)。这表明,提升奖励模型本身的泛化性是提升 RL 泛化性的一个关键途径。

图 3: 不同奖励模型影响的可视化结果。
在扩展策略的探索上,研究团队针对 GRPO 和 DPO 的特性提出了不同的优化路径。例如,对于 GRPO,增加每轮采样的图像数量(group size)比增加训练数据量或迭代次数,能更经济地提升域内性能。
而对于 DPO,迭代训练(如 DPO-Iter)虽然能显著提升域内分数,但过早地在泛化能力上达到瓶颈甚至衰退,这可能源于对训练偏好数据的过拟合。另一方面,扩展域内训练数据的多样性和数量,则能帮助 DPO 克服小规模偏好数据集带来的局限性,从而同时提升域内和域外表现。

图 4: 扩展策略影响的可视化结果。
总结与展望
这项研究为我们提供了一幅关于 DPO 和 GRPO 在自回归图像生成领域应用的清晰图景。它不仅揭示了 DPO 在域内任务上的优势和 GRPO 在域外泛化上的长处,还强调了高质量、高泛化性奖励模型的重要性,并为两种 RL 范式提供了针对性的扩展策略建议。
这些发现为未来开发更高效的 RL 算法,以在自回归图像生成领域实现更鲁棒的 CoT 推理,铺平了新的道路。研究者希望这项工作能启发更多后续研究,共同推动 AI 在视觉创造力上的边界。
©
(文:机器之心)