

机器之心编辑部
人人都绕不开的推荐系统,如今正被注入新的 AI 动能。
随着 AI 领域掀起一场由大型语言模型(LLM)引领的生成式革命,它们凭借着强大的端到端学习能力、海量数据理解能力以及前所未有的内容生成潜力,开始重塑各领域的传统技术栈。
作为互联网流量的核心引擎,推荐系统面临着级联架构导致的算力碎片化、优化目标割裂等问题,并逐渐制约其创新发展。实现从碎片化拼装到一体化整合的范式跃迁,是推荐系统重焕生机的必由之路,而利用 LLM 技术重构架构以实现效果提升、成本降低成为关键。
近日,快手技术团队交出了他们的答卷,最新提出的「OneRec」首次以端到端生成式架构重构推荐系统全链路。在效果与成本这场看似零和的博弈中,OneRec 让「既要又要」成为可能:
-
从效果来看:将推荐模型的有效计算量提升了 10 倍,更让长期「水土不服」的强化学习技术在推荐场景焕发新生;
-
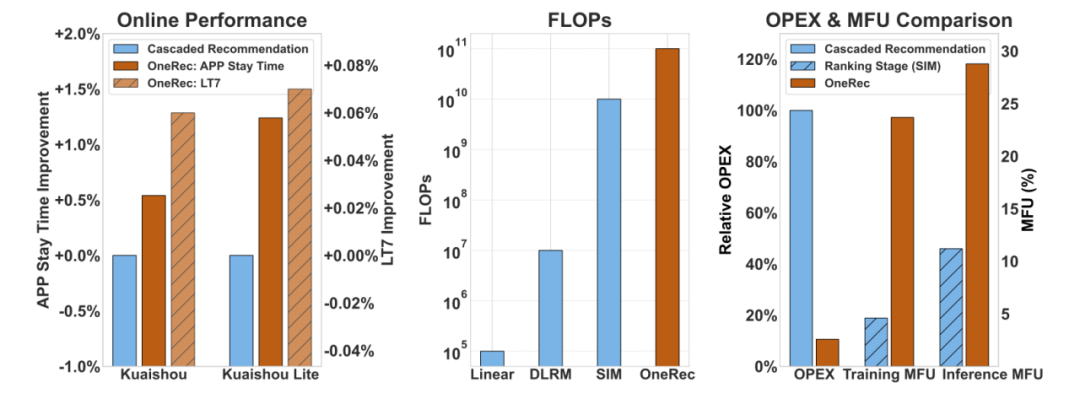
从成本来看:通过架构级创新将训练 / 推理 MFU (模型算力利用率) 提升至 23.7%/28.8%,通信与存储开销锐减使得运营成本(OPEX)仅为传统方案的 10.6%。
目前,该系统已在快手 App / 快手极速版双端服务所有用户,承接约 25% 的QPS(每秒请求数量),带动 App 停留时长提升 0.54%/1.24%,关键指标 7 日用户生命周期(LT7)显著增长,为推荐系统从传统 Pipeline 迈向端到端生成式架构提供了首个工业级可行方案。
下图(左)展示了快手 / 快手极速版中 OneRec 与级联推荐架构的 Online 性能比较,图(中)展示了 OneRec 与 Linear、DLRM、SIM 的 FLOPs 比较,图(右)展示了 OneRec 与级联推荐架构的 OPEX 对比,以及和链路中计算复杂度最高的精排模型 SIM 的 MFU 对比
推荐效果与算力效率双双提升的背后,是 OneRec 在架构设计和训练框架层面的一系列创新性突破。
完整技术报告链接:https://arxiv.org/abs/2506.13695
突破传统级联架构的桎梏
推荐算法从早期的因子分解机到如今的深度神经网络,虽历经多次革新,却始终未能摆脱多阶段级联架构的束缚 —— 这种碎片化的设计正面临以下三大关键瓶颈:
首先,算力效率低下成为致命伤。以快手为例的分析显示,即使是推荐系统中计算复杂度最高的精排模型 (SIM),在旗舰版 GPU 上训练 / 推理的 MFU (Model FLOPs Utilization) 也只有 4.6%/11.2%,远低于大语言模型在 H100 上 40%-50% 的水平;
其次,目标函数冲突愈演愈烈,平台需要同时优化用户、创作者和生态系统的数百个目标,这些目标在不同阶段相互掣肘,导致系统一致性和效率持续恶化;
更严峻的是,技术代差正在拉大,现有架构难以吸纳 Scaling Law、强化学习等 AI 领域的最新突破,并且难以充分利用最新计算硬件的能力,使得推荐系统与主流 AI 技术的发展渐行渐远。
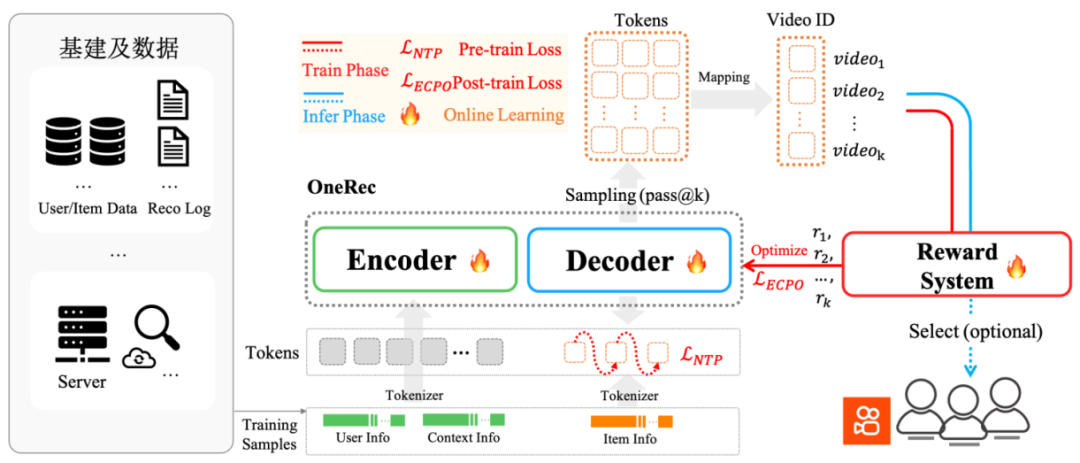
面对这些挑战,快手技术团队提出端到端生成式推荐系统 OneRec,其核心在于利用 Encoder 压缩用户全生命周期行为序列实现兴趣建模,同时基于 MoE 架构的 Decoder 实现超大规模参数扩展,确保短视频推荐的端到端精准生成;配合定制化强化学习框架和极致的训练/推理优化,使模型实现效果和效率的双赢。
下图为 OneRec 系统概览。
可喜的是,这个新系统在以下几个方面的效果显著:
-
可以用远低于线上系统的成本,采用更大的模型,取得更好的推荐效果;
-
在一定范围内,找到了推荐场景的 Scaling Law;
-
过去很难影响和优化推荐结果的 RL 技术在这个架构上体现出了非常高的潜力;
-
目前该系统从训练到 serving 架构以及 MFU 水平都和 LLM 社区接近,LLM 社区的很多技术可以很好地在这个系统上落地。
OneRec 基础模型剖析
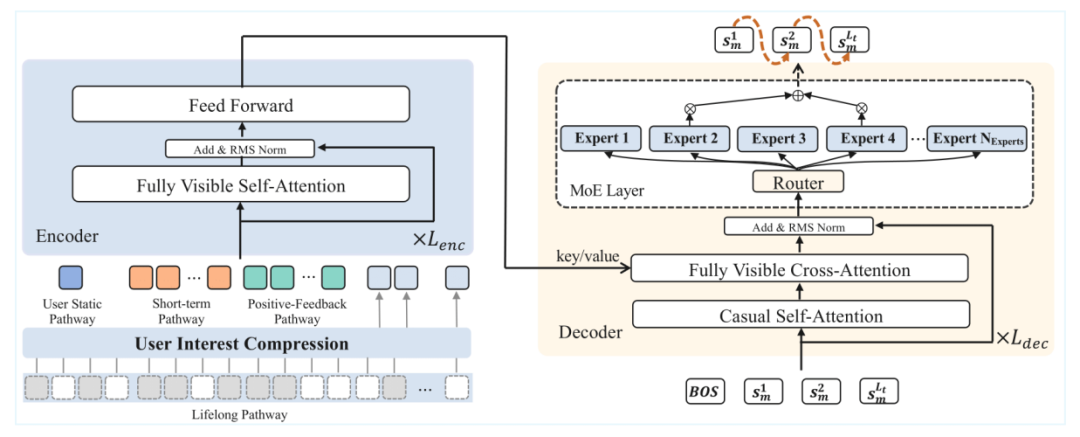
OneRec 采用 Encoder-Decoder 架构,将推荐问题转化为序列生成任务,在训练过程中使用 NTP (Next Token Prediction) 损失函数优化。下图展示了 Encoder-Decoder 架构的完整组件。
语义分词器
面对快手平台上亿级别的视频内容,如何让模型「理解」每个视频成为关键挑战。OneRec 首创了协同感知的多模态分词方案:
-
多模态融合:同时处理视频的标题、标签、语音转文字、图像识别等多维信息。
-
协同信号集成:不仅关注内容特征,更融入用户行为信息建模。
-
分层语义编码:采用 RQ-Kmeans 技术,将每个视频转化为 3 层粗到细的语义 ID。
Encoder-Decoder 架构
在训练阶段,OneRec 通过 Encoder-Decoder 架构执行下一个 token 预测,进而实现对目标物品的预测。该架构在编解码阶段起到的作用分别如下:
-
多尺度用户建模:编码阶段同时考虑用户静态特征、短期行为序列、有效观看序列和终身行为序列。
-
专家混合解码器:解码阶段采用逐点生成策略,通过 Mixture of Experts(MoE)架构提升模型容量和效率。
推荐系统中的 Scaling Law
参数规模实验是 OneRec 研究中的另一亮点,它试图回答一个根本性的问题:推荐系统是否同样遵循大语言模型领域已被证实的 Scaling Law?
实验结果清晰地表明,随着模型参数量从 0.015B 到 2.633B 的递增,训练损失呈现出明显的下降趋势,详见下图损失变化曲线。
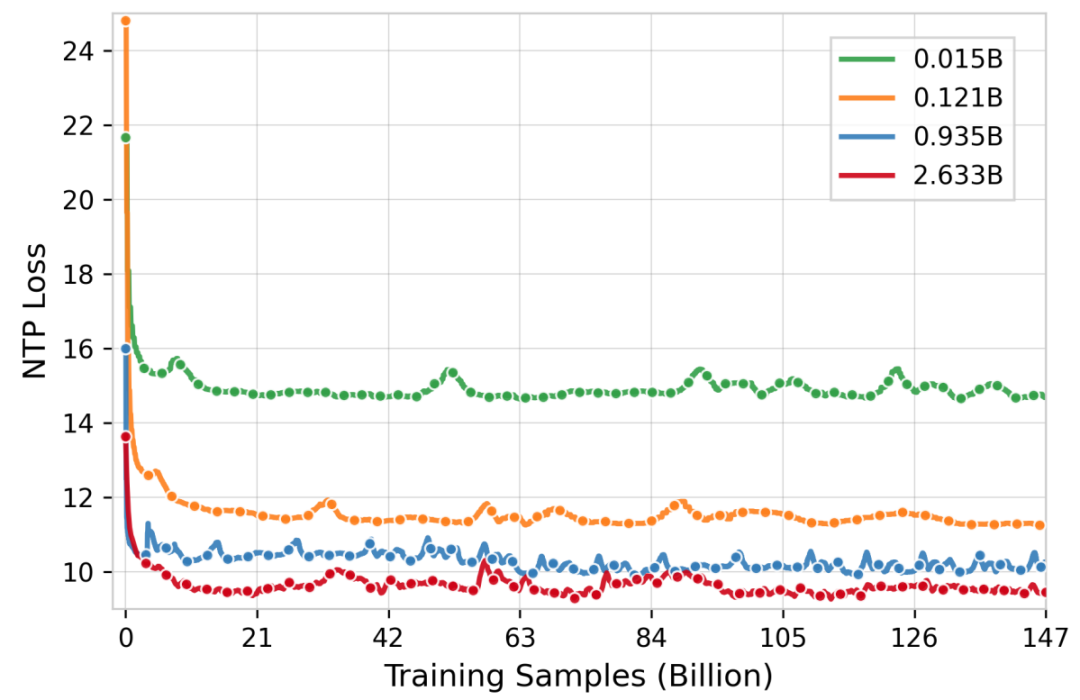
此外,技术报告中还介绍了包含 Feature Scaling、Codebook Scaling 和 Infer Scaling 等,极大地利用算力来提升推荐的精度。
强化学习(RL)偏好对齐
预训练模型虽然可以通过下一个 token 预测来拟合曝光物品的空间分布,但这些曝光物品来源于过去的传统推荐系统,这导致模型无法突破传统推荐系统的性能天花板。
为了解决这一挑战,OneRec 引入了基于奖励机制的偏好对齐方法,利用强化学习增强模型效果。通过奖励反馈机制,模型得以感知更为细粒度的用户偏好信息。为此,OneRec 构建了一套综合性的奖励系统:
-
偏好奖励(Preference Reward):用于对齐用户偏好。
-
格式奖励(Format Reward):确保生成的 token 均为有效格式。
-
工业场景奖励(Industrial Reward):满足各类业务场景的需求。
下图为奖励系统总体框架。
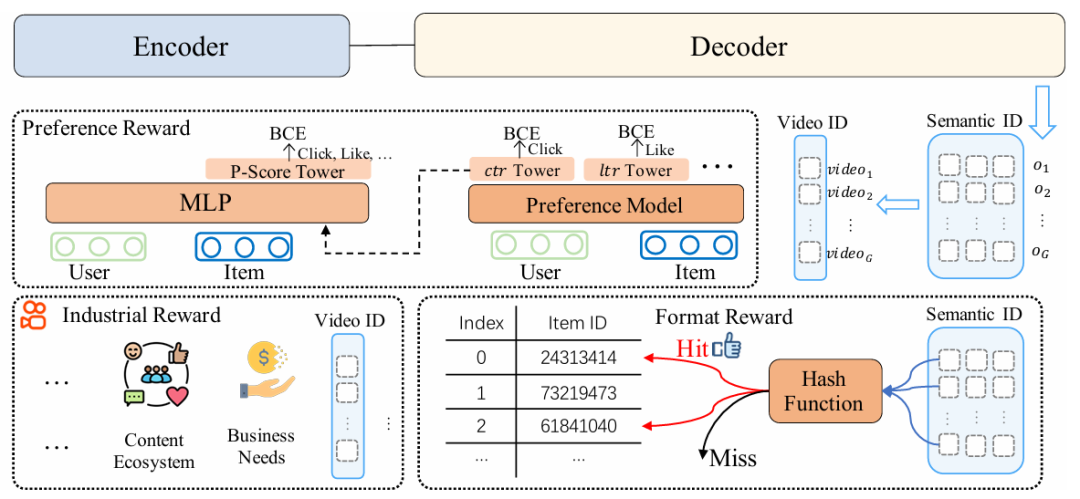
什么样的视频应该被奖励呢?OneRec 提出采用偏好奖励模型,能基于用户特征,输出对不同目标预测值进行「个性化融合」后的偏好分数。用该分数「P-Score」作为强化学习的奖励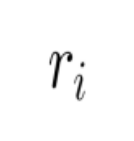 ,并通过 GRPO 的改进版 ECPO(Early-Clipped GRPO)进行优化。
,并通过 GRPO 的改进版 ECPO(Early-Clipped GRPO)进行优化。
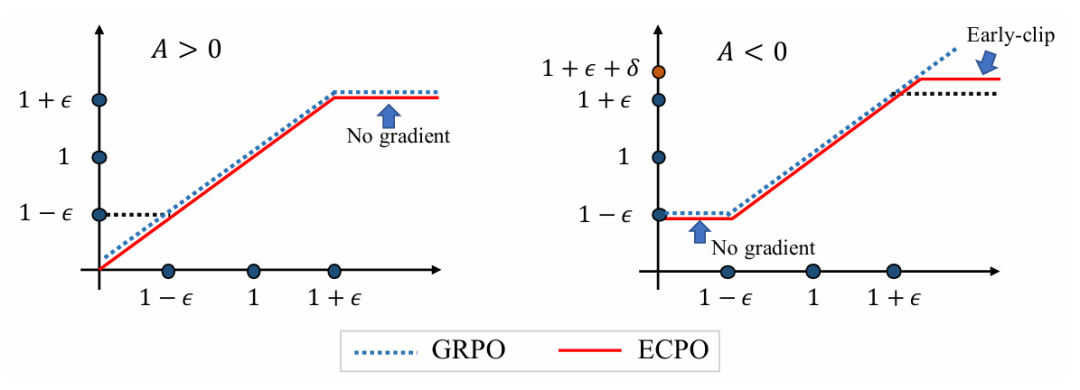
如下图所示,相较于 GRPO,ECPO 对负优势(A<0)样本进行更严格的策略梯度截断,保留样本的同时防止梯度爆炸使训练更加稳定。
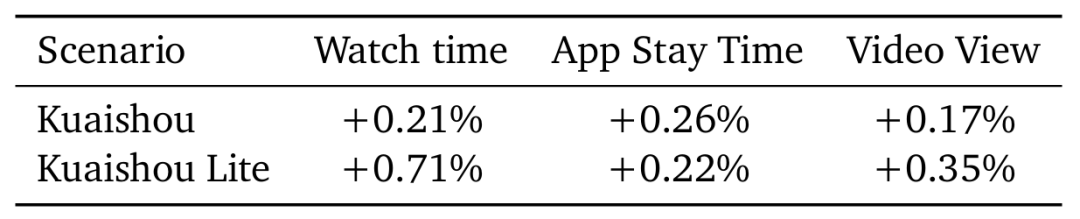
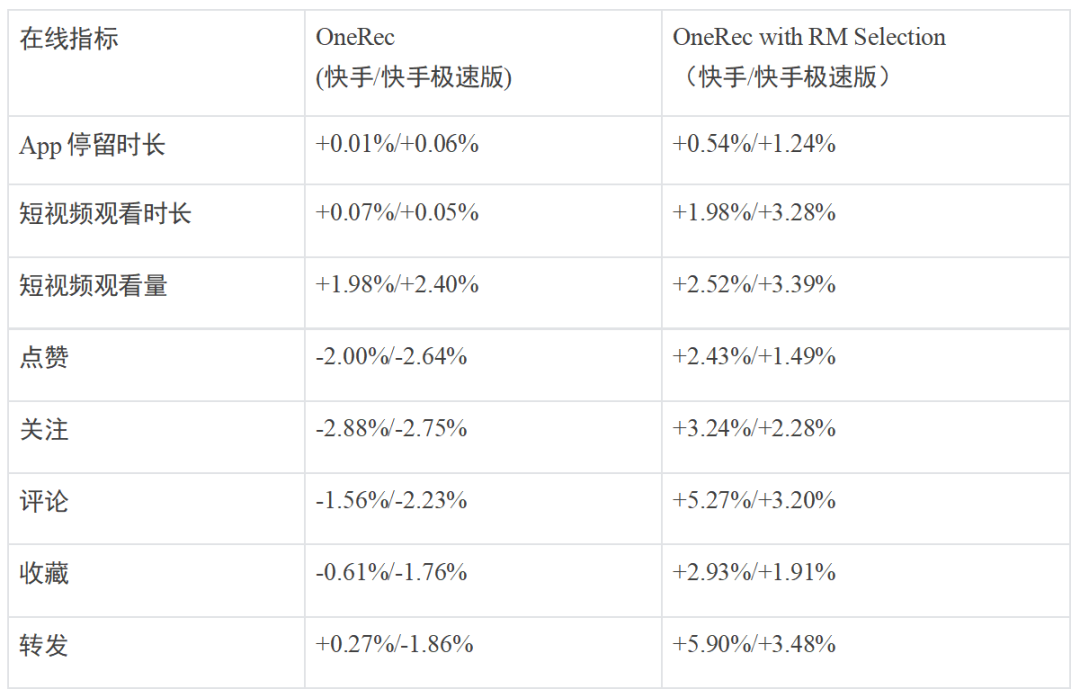
OneRec 在快手 / 快手极速版场景中进行了强化学习的消融实验,线上结果显示在不损失视频曝光量的情况下显著提升 App 使用时长。下表展示了 OneRec 使用「P-Score」 奖励相较于不使用情况下的各指标效果提升。
性能优化
MFU(模型浮点运算利用率)作为衡量算力效率的核心指标,传统推荐排序模型却长期深陷「个位数魔咒」,主要有以下两方面的原因:
-
一是业务迭代积累的历史包袱,如快手精排模型算子数量高达 15000+ 个,复杂结构导致无法像 LLM 那样进行深度优化;
-
二是成本与延迟约束下的规模瓶颈,致使单个算子计算密度低下,显存带宽成为性能天花板,GPU 算力利用率长期低于 10%。
而 OneRec 的生成式架构带来破局性变革:通过采用类 LLM 的 Encoder-Decoder 架构精简组件,将关键算子数量压缩 92% 至 1,200 个,配合更大模型规模提升计算密度;更通过重构推荐链路释放延迟压力,使训练 / 推理 MFU 分别飙升至 23.7% 和 28.6%,较传统方案实现 3-5 倍提升,首次让推荐系统达到与主流 AI 模型比肩的算力效能水平。
此外,快手技术团队还针对 OneRec 特性在训练和推理框架层面进行了深度定制优化。
训练优化
在训练阶段,OneRec 通过以下几项核心优化实现了加速:
-
计算压缩:针对同一请求下的多条曝光样本(如一次下发 6 个视频,平均 5 条曝光),这些样本共享用户和 context 特征。快手按请求 ID 分组,避免在 context 序列上重复执行 ffn 计算。同时,利用变长 flash attention,有效避免重复的 kv 访存操作,进一步提升 attention 的计算密度。
-
Embedding 加速优化:针对单样本需训练 1000 万以上 Embedding 参数的挑战,快手技术团队自研了 SKAI 系统,实现了 Embedding 训练全流程在 GPU 上完成,避免 GPU/CPU 同步中断;通过统一 GPU 内存管理(UGMMU)大幅减少 kernel 数量;采用时间加权 LFU 智能缓存算法充分利用数据的时间局部性,并通过 Embedding 预取流水线将参数传输与模型计算重叠,有效隐藏传输延迟,整体大幅提升了 Embedding 训练效率。
另外还有高效并行训练、混合精度与编译优化等关键优化技术。
推理优化
在推理阶段,OneRec 采用大 beam size(通常为 512)来提升生成式推荐的多样性和覆盖率。面对如此大规模的并行生成需求,快手技术团队从计算复用、算子优化、系统调度等多个维度进行了深度优化:
-
计算复用优化: OneRec 针对大规模并行生成需求,通过多种计算复用手段大幅提升效率:首先,同一用户请求下 encoder 侧特征在所有 beam 上完全一致,因此 encoder 只需前向计算一次,避免了重复计算;其次,decoder 生成过程中 cross attention 的 key/value 在所有 beam 间共享,显著降低显存占用和算力消耗;同时,decoder 内部采用 KV cache 机制,缓存历史步骤的 key/value,进一步减少重复计算。
-
算子级优化: OneRec 推理阶段全面采用 Float16 混合精度计算,显著提升了计算速度并降低了显存占用。同时,针对 MoE、Attention、BeamSearch 等核心算子,进行了深度 kernel 融合和手工优化,有效减少了 GPU kernel 启动和内存访问次数,全面提升了算子计算效率和整体吞吐能力。
另外还有系统调度优化等专属优化。
通过以上系统性的优化策略,OneRec 在训练和推理的 MFU 分别达到了 23.7% 和 28.8%,相比传统推荐模型的 4.6% 和 11.2% 有了大幅改善。运营成本降低至传统方案的 10.6%,实现了接近 90% 的成本节约。
Online 实验效果
OneRec 在快手主站 / 极速双端 App 的短视频推荐主场景上均进行了严格实验。
通过为期一周 5% 流量的 AB 测试,纯生成式模型(OneRec)仅凭 RL 对齐用户偏好即达到原有复杂推荐系统同等效果,而叠加奖励模型选择策略(OneRec with RM Selection)后更实现停留时长提升 0.54%/1.24%、7 日用户生命周期(LT7)增长 0.05%/0.08% 的显著突破 —— 须知在快手体系中,0.1% 停留时长或 0.01% LT7 提升即具统计显著性。
更值得关注的是,模型在点赞、关注、评论等所有交互指标上均取得正向收益(如下表所示),证明其能规避多任务系统的「跷跷板效应」实现全局最优。该系统目前已经在短视频推荐主场景推全到所有用户,承担约 25% 的请求(QPS)。
除了短视频推荐的消费场景之外,OneRec 在快手本地生活服务场景同样表现惊艳:AB 对比实验表明该方案推动 GMV 暴涨 21.01%、订单量提升 17.89%、购买用户数增长 18.58%,其中新客获取效率更实现 23.02% 的显著提升。
目前,该业务线已实现 100% 流量全量切换。值得注意的是,全量上线后的指标增长幅度较实验阶段进一步扩大,充分验证了 OneRec 在不同业务场景的泛化能力。
结语
生成式 AI 方兴未艾,正在对各个领域产生根本性的技术变革与降本增效。随着快手 OneRec 新范式的到来,推荐系统将加速迎来「端到端生成式觉醒」时刻。
OneRec 不仅论证了推荐系统与 LLM 技术栈深度融合的必要性,更重构了互联网核心基础设施的技术 DNA。一方面,通过创新的端到端生成式架构重构推荐系统的技术范式;另一方面,经过极致的工程优化,在效果与效率双重维度上实现全面超越。
当然,新系统还有很多地方需要进一步完善。快手技术团队指出了三个待突破的方向:
-
推理能力:Infer 阶段 step 的 Scaling up 能力尚不明显,这预示着 OneRec 还不具备很强的推理能力;
-
多模态桥接:构建用户行为模态与 LLM/VLM 的原生融合架构,借鉴 VLM 中的跨模态对齐技术,实现用户行为序列、视频内容与语义空间的统一学习,成为一个原生全模态的模型;
-
完备的 Reward System:目前的设计还比较初级。在 OneRec 端到端的架构下,Reward System 既能影响在线结果也能影响离线训练,快手期望利用该能力引导模型更好地理解用户偏好和业务需求,提供更优的推荐体验。
可以预见,未来补上更多 AI 能力的 OneRec 无疑会更强大,从而在包括快手在内更广泛的推荐应用场景中释放出更大的价值。
©
(文:机器之心)