

MiniMax 深夜开源了训练成本只要53万美元的开源模型M1,输出长度达到8万Token!

MiniMax 放出了一颗重磅炸弹——MiniMax-M1,这是全球首个开源的大规模混合注意力推理模型。
这个模型最炸裂的地方在哪?
100万Token的输入,8万Token的输出,这个上下文窗口长度直接刷新了开源模型的纪录。

更离谱的是,M1 的训练成本只要53.47万美元!
要知道,现在训练一个大模型动辄就是几千万美元起步,MiniMax这波操作属实是把成本打到了地板上。
性能碾压一众大佬
看看官方放出的跑分数据,MiniMax-M1在多个维度上的表现都相当炸裂。
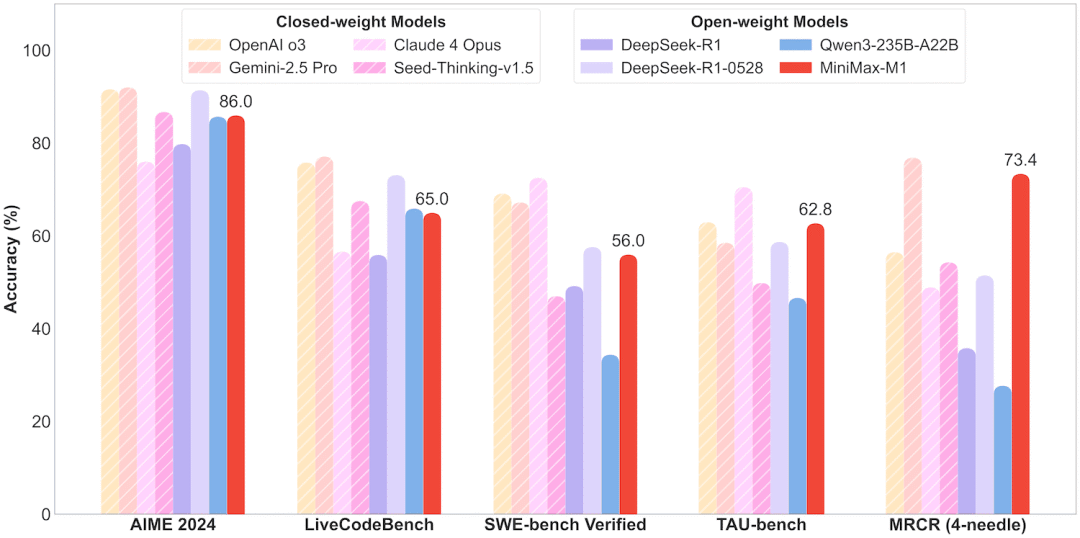
在数学推理任务AIME 2024上,MiniMax-M1-80K拿到了86.0分,虽然比不上DeepSeek-R1-0528的91.4分,但已经超过了Claude 4 Opus的76.0分。
更牛的是在编程任务上,LiveCodeBench的测试中,MiniMax-M1拿到了65.0分,直接把DeepSeek-R1原版的55.9分甩在身后。
拥有13.6万粉丝的AI研究员Aran Komatsuzaki(@arankomatsuzaki)兴奋评价称:
MiniMax-M1是一款开源大型语言模型,具备46亿活跃参数,展现出几乎达到最新技术水平的推理和自主智能代理能力。

研究员Wenhu Chen(@WenhuChen) 表示:
该模型表现优异但发布低调,显示了该模型在多项指标上的强劲实力。
开源社区炸锅了
消息一出,整个AI圈都沸腾了。
Hugging Face的训练LLM工程师elie(@eliebakouch)激动地回应:
走起来了 😍
Hugging Face的首席”get-shit-done”官Vaibhav (VB) Srivastav(@reach_vb)更是连发多条推文:
太强了!!你们太牛了!而且还是Apache许可证,爱了爱了
Minimax M1 456B支持百万上下文,性能优于DeepSeek R1和Qwen 235B。
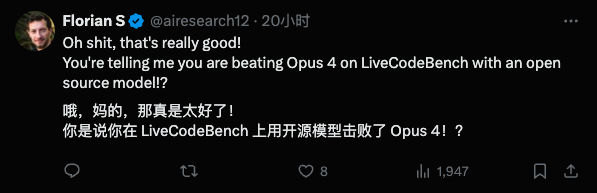
AI 研究员Florian S(@airesearch12)看到LiveCodeBench的成绩后直接惊呼:
卧槽,这真的太强了!你告诉我一个开源模型在LiveCodeBench上打败了Opus 4?!
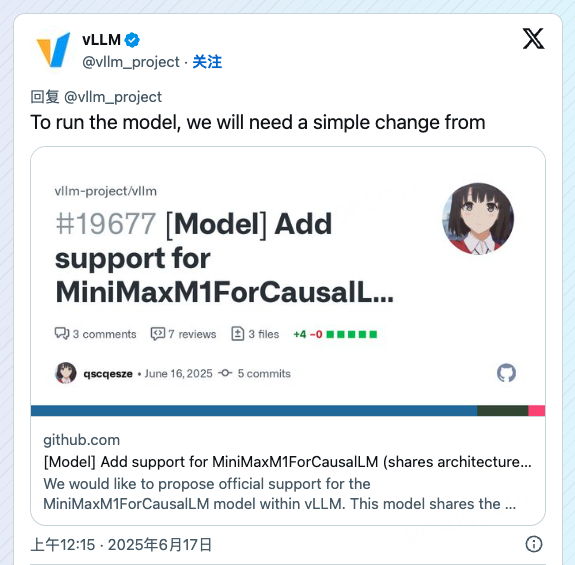
vLLM团队(@vllm_project)神速响应:
vLLM团队确认已在Day 1支持该模型的推理运行,并发布了相关适配补丁。
独立开发者Johnny(@j4redux)感叹:
1百万上下文窗口 + 4万输出在tau bench retail上超越了gemini 2.5 pro——太疯狂了!
技术细节:混合架构的魔力
翻看技术报告,MiniMax-M1的成功离不开几个关键创新。
首先是混合专家(MoE)架构结合闪电注意力机制。
模型总参数量456亿,但每个Token激活的参数只有45.9亿,这种设计既保证了性能又控制了计算成本。
更重要的是他们提出的CISPO算法——一种新颖的强化学习算法,通过裁剪重要性采样权重而非Token更新,显著提升了训练效率。
Google DeepMind研究员rohan anil(@arohan)从技术角度深入分析:
根据近期论文的分析,推理时间的核心限制是KV(key-value)记忆访问。该访问成本与生成长度呈二次关系。MiniMax-M1包含10个完整的Attention层,其KV维度为128×8×2=2048,而对比模型R1的KV维度为576。
这种混合架构设计让MiniMax-M1在处理10万Token生成任务时,计算量只有DeepSeek R1的25%。
硅谷开发者valn1x(@valn1x)爆料:
这比o1的训练效率高了15000-20000倍。这是实际数字。
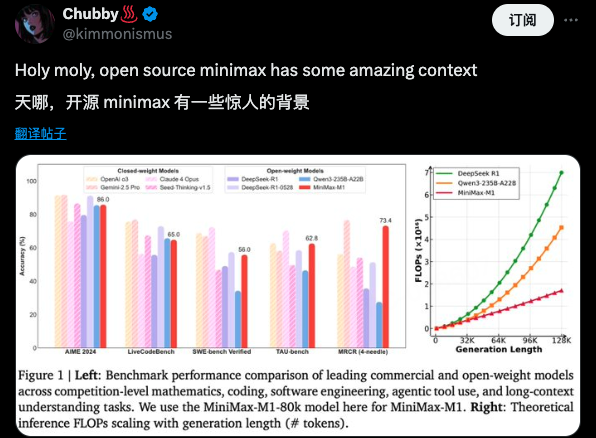
Chubby♨️(@kimmonismus)总结道:
天哪!
该模型支持世界上最长的上下文窗口:可处理100万令牌的输入和8万令牌的输出。采用强化学习训练,训练成本仅为53.47万美元,效率领先。
实战案例展示
兴奋的网友们纷纷上手,贡献了无数的 M1 实操case(都不用我上手了)——可以看到了M1 模型的真正实力。
UI组件生成
只需一个提示词,M1就能即时构建带有canvas动画粒子背景的HTML页面:
交互式应用开发
让M1创建一个打字速度测试应用,它生成了一个干净、功能完善的Web应用,可以实时追踪WPM(每分钟字数):
可视化工具
创建带有canvas动画粒子背景的HTML页面,粒子能够平滑移动并在接近时连接:
游戏开发
M1还能创建迷宫生成器和路径寻找可视化工具,随机生成迷宫并逐步可视化A*算法求解过程:
部署指南
MiniMax提供了两个版本供选择:
1. MiniMax-M1-80k版本(8万Token思考预算):
from transformers import AutoTokenizer, AutoModelForCausalLM
# 加载模型和分词器
model_name = "MiniMaxAI/MiniMax-M1-80k"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# 使用模型进行推理
inputs = tokenizer("你的输入文本", return_tensors="pt")
outputs = model.generate(**inputs, max_length=80000)
response = tokenizer.decode(outputs[0])
2. MiniMax-M1-40k版本(轻量版,4万Token思考预算):
model_name = "MiniMaxAI/MiniMax-M1-40k"
# 其余代码与上面相同AI 专家Alexandre Strube(@alexandre_ganso) 则关心硬件要求,:
推荐的推理硬件,我猜测需要8x GH200 144GB,还是96GB的就够了?
而手快的Novita AI(@novita_labs) 则已经第一时间提供了API 服务:
Minimax-M1已在Novita上线!世界首个开源的大规模混合注意力推理模型!💰
2.2 per 1M tokens (输入/输出)
展望
前银行软件工程师Lincoln 🇿🇦(@Presidentlin)的评论道出了很多人的心声:
欢迎回到开源阵营 💙
北欧AI研究院(@nordicinst)评价:
MiniMax-M1是一款开源人工智能模型,具备高达1,000,000个令牌的上下文处理能力,同时采用了一种超高效的强化学习技术。该模型旨在为北欧地区的AI创新者提供强大且经济的解决方案。
MiniMax这次的开源举动,收获了全球网友的全面认可,也展示了其在AI领域的全面实力。
(不过我想说的是,你们除了棒、好、酷、牛之外,就不会点其他的了吗?……
作为成立于2021年的中国AI公司,除了这次开源的M1模型,MiniMax还拥有Hailuo AI视频生成平台、月活近3000万的Talkie AI角色扮演平台,以及服务全球4万多家企业的API平台。

MiniMax-M1的发布,不仅展示了中国AI公司在大模型技术上的突破,更重要的是为全球开源社区注入了新活力。
53万美元训练出一个性能如此强悍的模型,这个成就让整个AI界重新思考大模型发展的方向。
这标志着开源领域在长上下文理解和高效强化学习训练方面取得的重要进展,也预示着国产开源模型正在国际舞台上发挥越来越重要的影响力。
而这,还只是 5 天发布的Day 1。
Hugging Face 模型库: https://huggingface.co/collections/MiniMaxAI/minimax-m1-68502ad9634ec0eeac8cf094
[2]GitHub 源码: https://github.com/MiniMax-AI/MiniMax-M1
[3]技术报告(PDF): https://github.com/MiniMax-AI/MiniMax-M1/blob/main/MiniMax_M1_tech_report.pdf
[4]在线体验: https://chat.minimax.io/
(文:AGI Hunt)