

-

-
• 超高效率: 中国AI独角兽MiniMax发布开源模型M1,凭借混合闪电注意力架构,推理效率是竞品的4倍,而整个强化学习训练成本仅为惊人的53万美元。 -
• 旗舰级性能: M1拥有100万Token输入和8万Token输出的旗舰级能力,在软件工程、长文本理解等关键生产力任务上,性能超越一众开源模型,甚至在部分场景比肩乃至超越了OpenAI o3、Claude 4等闭源巨头。 -
• 创新RL框架: 首次提出全新强化学习算法CISPO,并攻克了混合架构下的精度不匹配、优化器敏感等工程难题,实现了高效稳定的长链条推理训练。 -
• 完全开源普惠: 模型权重、技术报告全部公开,并提供行业最低价API和免费应用,旨在推动AI平民化,让顶尖智能触手可及。
AI竞赛的“内卷”与破局者
AI的世界,从未像今天这样喧嚣。一边是OpenAI、Google、Anthropic等巨头轮番上演“神仙打架”;另一边,国内大模型赛道也卷起了一场腥风血雨,“价格战”的屠刀挥向了每一个token。
在这场以 “烧钱”和“堆规模”为主旋律的竞赛中,一个根本性的问题摆在所有产品经理和工程师面前:除了无尽的军备竞赛,AI的未来还有没有第三条路?牌桌上真的没有新玩法了吗?
2025年6月16日,来自中国的AI“小神龙”——MiniMax,用一款名为M1的新模型,给出了一个响亮的回答。它像一位精通内力的武林高手,不追求肌肉的绝对围度,却以惊人的效率和精准的打击力,成为了赛道上最不容忽视的效率破局者。
M1的旗舰规格:重塑产品边界
让我们先看M1的旗舰规格,每一项都重新定义了AI产品的可能性。
下表直观对比了M1与全球顶尖模型的输入/输出能力,这是评估一个模型能否承载复杂应用的基础。
| Table 1: M1在输入和输出长度上均达到世界顶级水平。 |
|
|
|
|
|
|
1M tokens | 80K tokens |
|
|
1M tokens |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
而在综合性能上,M1更是在多个关键领域展现了统治力。
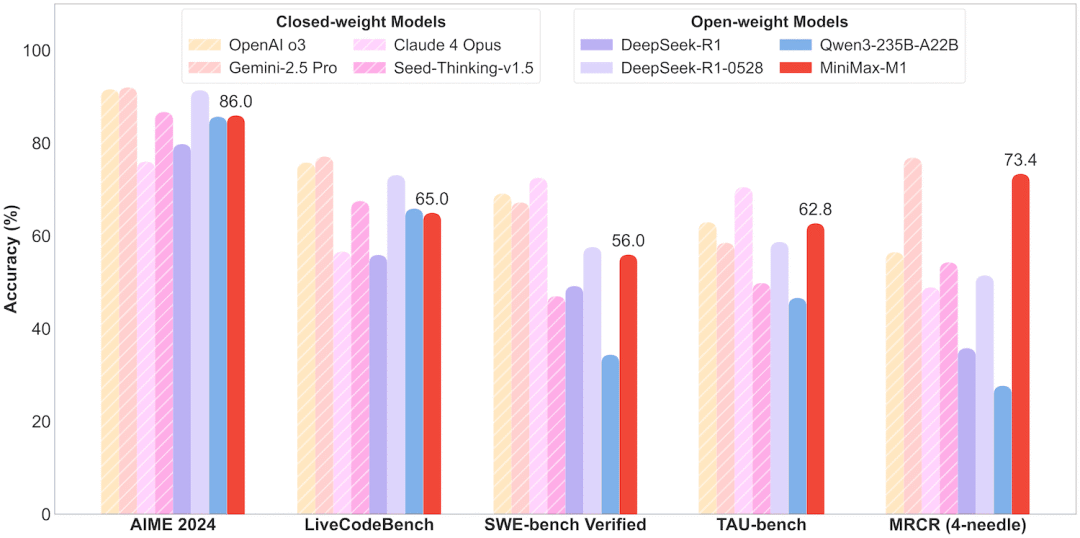
对于产品经理而言,这张图意味着M1在软件工程、长文本理解、AI Agent等高价值场景具备了顶级的竞争力。对于工程师来说,这意味着M1不仅是个“理论上”强大的模型,更是在实际复杂任务中被验证过的可靠工具。
那么,如此惊人的效率与性能,究竟是如何锻造出来的?
深度拆解:M1的引擎室里有什么?
对于产品经理,这部分解释了M1低成本、高性能背后的“魔法”。对于工程师,这是你一直在等待的技术深潜。
核心架构:混合闪电注意力
M1的基座是MiniMax-Text-01,一个拥有4560亿总参数、45.9亿激活参数和32个专家(Experts)的庞大MoE模型。其真正的革命性在于其混合注意力架构。
传统Transformer的Softmax注意力,计算复杂度是O(n²)。M1则创造性地将它与一种名为“闪电注意力”(Lightning Attention,一种I/O感知的线性注意力实现)结合,其核心设计是:
-
• 架构比例: 每7个Transnormer模块(使用闪电注意力)搭配1个Transformer模块(使用Softmax注意力)。 -
• 工作原理: 这就像一个高效的专家团队,大部分日常计算由速度飞快的“专员”(闪电注意力)以O(n)线性复杂度处理,只在需要全局信息聚合的关键节点,才由“首席科学家”(Softmax注意力)进行精算。
这种设计带来了颠覆性的效率提升。
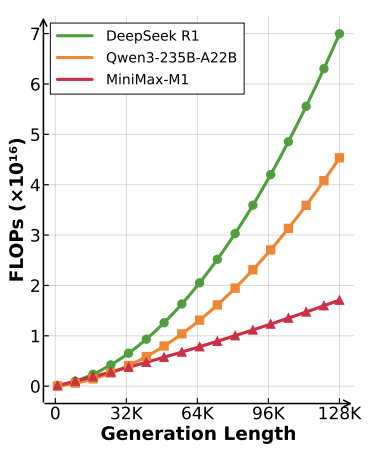
结论是震撼的:当生成长度达到10万个token时,M1消耗的算力(FLOPs)仅为DeepSeek R1的25%! 这意味着更低的推理成本(TCO)和更快的响应速度。
强化学习(RL)框架:从算法创新到工程落地
M1的另一个杀手锏是其高效的RL框架,这不仅包括算法创新,更包含了一系列扎实的工程实践。
算法创新:CISPO
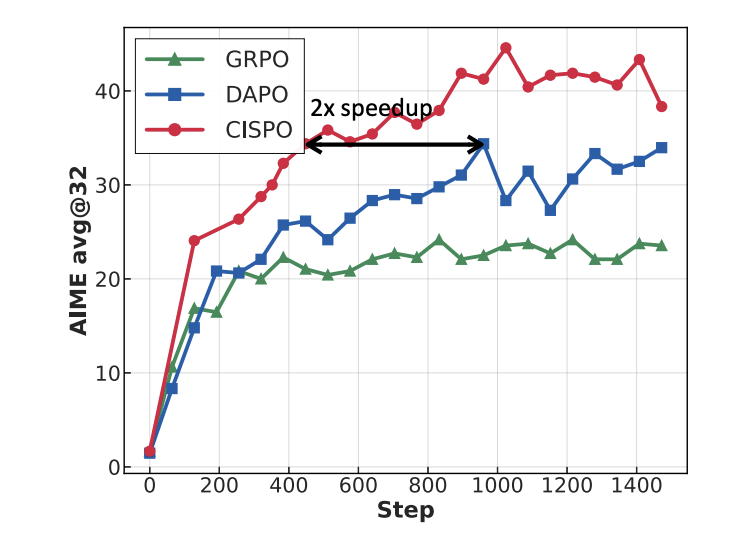
工程师都清楚,传统RL算法(如PPO)会“裁剪”掉低概率的探索性token,但这会扼杀模型的“灵感火花”。为此,MiniMax提出了全新的CISPO(Clipped IS-weight Policy Optimization)算法。
-
• 核心思想: 不裁剪token更新,而是裁剪重要性采样(IS)权重。这保留了完整的思考链条,允许模型进行“笨拙”但宝贵的探索,从而学会更复杂的推理。 -
• 效果: 在AIME数学竞赛实验中,其收敛速度是字节跳动DAPO算法的2倍。
工程挑战与解决方案
作为首个大规模应用混合注意力进行RL训练的团队,MiniMax趟平了许多坑,这些经验对工程师极具价值:
-
1. 计算精度不匹配问题: 团队发现RL训练中,训练模式和推理模式下的token概率存在巨大差异,导致奖励无法增长。通过逐层分析,定位到问题出在LM head的高幅度激活值上。 -
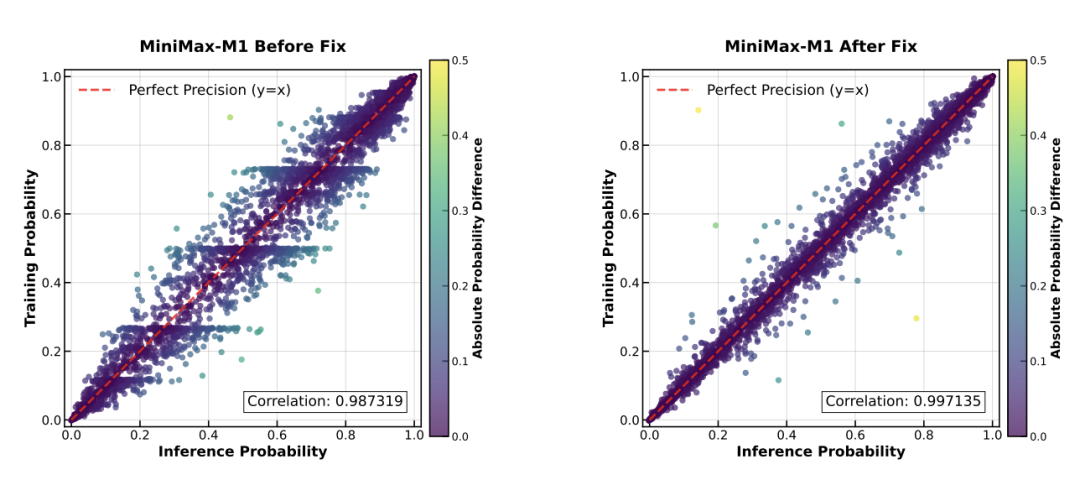
-
-
• 解决方案: 将LM head的计算精度提升至FP32,成功将两种模式的概率相关性从0.987提升至0.997,解决了训练不收敛的致命问题。 -
2. 优化器超参数敏感问题: 混合架构的梯度范围极广(从1e-18到1e-5),标准AdamW优化器配置(betas=(0.9, 0.999))会导致不收敛。 -
• 解决方案: 经过细致调试,最终采用betas=(0.9, 0.95), eps=1e-15的配置,稳定了训练过程。 -
3. 数据与课程设计: M1的RL训练数据极其丰富,涵盖了数学、逻辑推理(基于自研的SynLogic框架合成)、编程、以及从真实GitHub issue构建的沙盒化软件工程环境。 -
• 训练策略: 采用课程学习(Curriculum Learning),先用规则明确、有确定性奖励的任务(如数学、编程)进行训练,再逐步混入需要模型化奖励的通用任务,确保模型在扩展能力的同时,核心推理能力不退化。
正是这一系列从算法到工程的创新,最终造就了53万美元训练出顶级模型的效率奇迹。
应用场景解读:M1为三大未来战场而来
对于产品经理来说,最关心的是技术能落地到哪些场景。M1的优势集中在以下三大领域:
场景一:软件工程——不止是代码补全,更是问题解决者
SWE-bench测试要求模型修复真实的GitHub Bug。M1在此取得了56.0%的惊人成绩。这意味着它可以深度参与到代码调试、Bug修复、甚至系统重构等高价值环节,成为工程师真正的“智能副驾”。
场景二:长文本处理——从财报分析到知识库构建
凭借100万Token的上下文能力,M1在长文本“大海捞针”任务上的表现超越了OpenAI o3和Claude 4。这为产品带来了无限可能:
-
• 企业知识库问答: 一次性读入所有内部文档,提供精准回答。 -
• 智能投研/法务助手: 快速分析几百页的财报或复杂的法律合同,提炼要点。 -
• 科研辅助: 整合海量研究论文,发现新的洞见。
场景三:AI Agent——赋予应用自主决策的“大脑”
在模拟真实世界场景的TAU-bench测试中,M1的工具使用和规划能力甚至超越了Gemini 2.5 Pro。这表明M1有潜力成为下一代AI Agent最强大的“大脑”,让应用能够自主理解任务、调用API、与环境交互,完成复杂的工作流。
M1正在改写AI游戏规则
M1的发布,其意义远超模型本身,它更像一份宣言,正在为产品经理和工程师们揭示新的可能性。
规则一:从“堆规模”到“提效率”
M1证明,AI竞赛的关键,正在从“静态规模”(参数量)的比拼,转向 “动态能力”(测试时计算)的扩展效率。未来的赢家,不一定是模型最大的,但一定是在解决问题时, “想”得最深、最快、最便宜的。
规则二:顶级性能开源,重塑竞争格局
M1以顶级性能开源,打破了“最强模型皆闭源”的迷思。这为工程师提供了前所未有的机会,也为产品经理提供了对抗巨头、实现差异化创新的利器。
规则三:极致性价比,加速AI应用落地
最关键的是商业模式。M1不仅在APP/Web端免费,其API定价更是极具颠覆性。

这种 “掀桌子”式的定价,将极大降低AI应用的开发和运营成本,加速从金融、法律到科研、教育等各行各业的AI应用落地。
下一个AI时代,从“聪明”地思考开始
MiniMax M1的横空出世,为我们描绘了一幅激动人心的未来图景。它告诉所有AI领域的建设者:智慧的较量,最终比拼的不是蛮力,而是思想的深度和效率。
当AI学会了像人类一样,在面对难题时能够“停下来,想一想”,并且这种思考的成本变得微不足道时,一个真正由AI驱动的生产力革命,才算真正拉开序幕。
推荐阅读
-
• 技术报告原文 (工程师必读): MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention,https://arxiv.org/abs/2506.13585 -
• Hugging Face模型下载: https://huggingface.co/MiniMaxAI -
• GitHub项目地址: https://github.com/MiniMax-AI/MiniMax-M1
(文:子非AI)