

今天是2025年6月16日,星期一,北京,晴
来看两个工作,一个是DeepResearch Bench评测,看看不同代表方案的表现;一个是E^2GraphRAG思路,看看怎么个提速法?
一、DeepResearch Bench评测
先看《DeepResearch Bench: A Comprehensive Benchmark for Deep Research Agents》(https://arxiv.org/pdf/2506.11763),专门用于评估Deep Research Agents, DRAs)的综合基准测试,https://github.com/Ayanami0730/deep_research_bench,包含100个博士级别的研究任务,每个任务由领域专家精心设计和迭代优化,涵盖22个不同的领域,通过收集和分析96,147个原始用户查询,确定每个主题领域的任务数量,并构建了100个高难度且基于真实研究需求的研究任务。
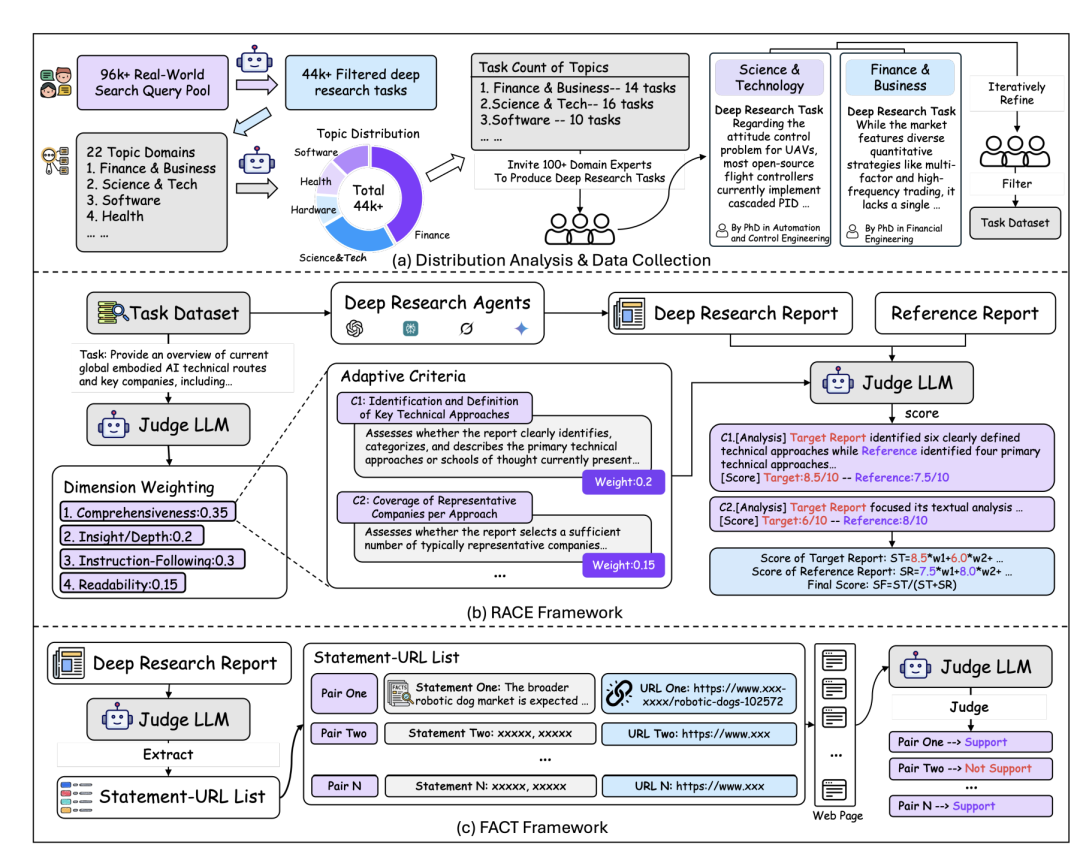
评估方面,基于领域专家知识,建立四个顶层维度:全面性(COMP)、洞察力/深度(DEPTH)、遵循指令(INST)和可读性(READ),通过加权维度级得分和维度权重,计算目标报告的总得分。
主要评估了四种早期发布的Agent:Gemini-2.5-pro-based Deep Research、OpenAI Deep Research、Grok Deeper Search和Perplexity Deep Research。
实验结果如下:
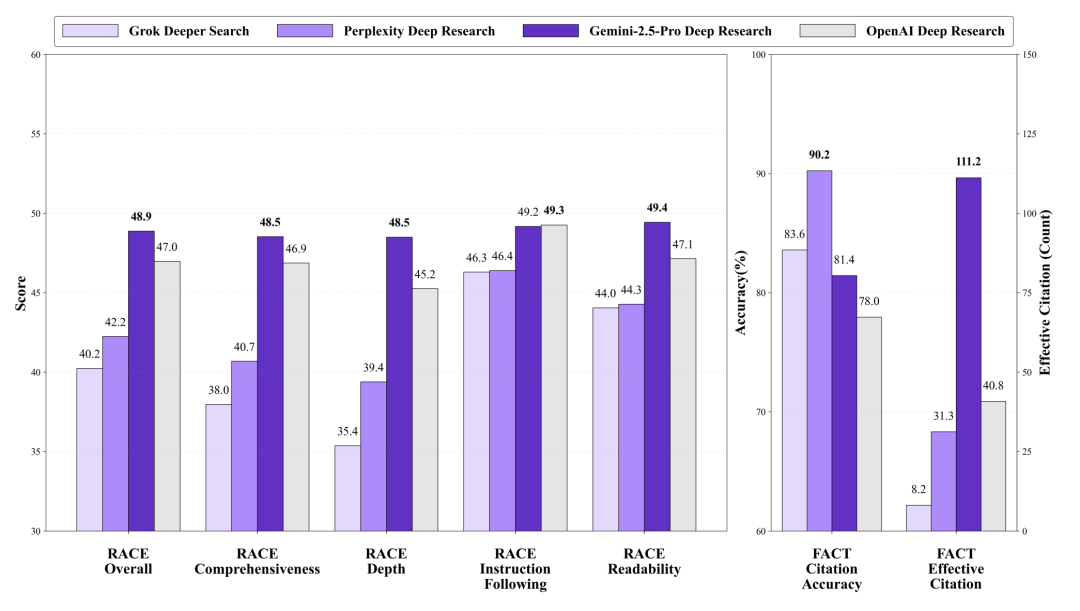
1、在DRAs类别中,Gemini-2.5-Pro Deep Research在RACE框架上展示了领先的整体性能。OpenAI Deep Research在遵循指令(INST)维度上表现出色。
2、Gemini-2.5-Pro Deep Research在其最终报告中平均有效引用数为111.21,显著优于其他模型。
3、引用准确率方面,Perplexity Deep Research的表现优于Gemini-2.5-Pro Deep Research和OpenAI Deep Research。
二、E^2GraphRAG提速思路
回到GraphRAG问题,看个新思路。
GraphRAG通过构建层次化实体图来支持全局查询,但存在高索引成本的问题;
RAPTOR通过递归聚类和总结文档构建层次化摘要树,但忽略了原始文档的上下文流;
LightRAG通过简化实体和关系的提取过程来提高效率,但仍需LLM生成复杂的JSON格式输出。
所以,可以在索引阶段构建一个摘要树和一个实体图,并在检索阶段设计一个自适应检索策略,利用图结构动态选择局部或全局查询模式,这就是《E^2GraphRAG: Streamlining Graph-based RAG for High Efficiency and Effectiveness》(https://arxiv.org/pdf/2505.24226)的方案。
先说结果:
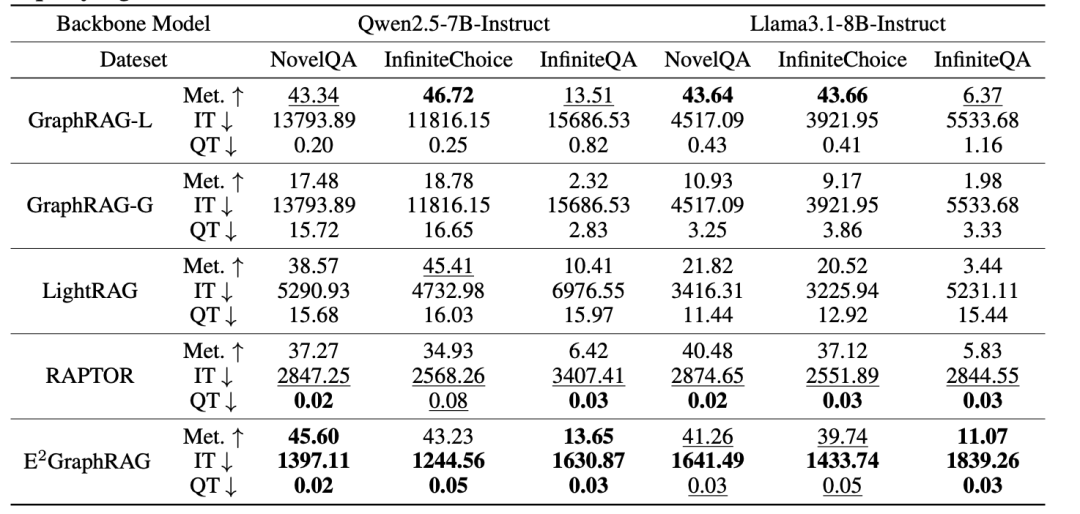
在效率上,E2GraphRAG在索引阶段的效率最高,比GraphRAG快10倍,比RAPTOR快约2倍。在检索阶段,E2GraphRAG比LightRAG快100倍,比GraphRAG的本地模式快约10倍。
在效果上,E2GraphRAG在效果上与GraphRAG相当,在某些数据集上甚至表现更好。例如,在NovelQA数据集上,使用Qwen模型时,E2GraphRAG取得了最佳性能。
在计算成本上,E2GraphRAG在索引阶段的LLM调用次数较少,检索阶段主要依赖SpaCy进行实体提取。RAPTOR在索引阶段的聚类操作引入了额外的开销,但在检索阶段由于使用了GPU加速的密集检索,速度较快。
再看过程:
1、索引阶段
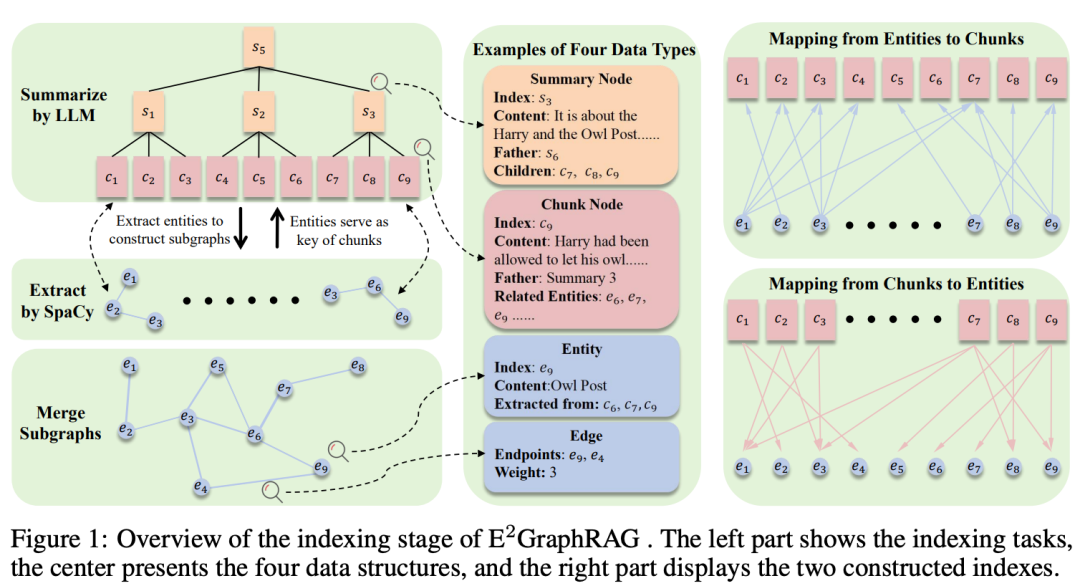
1)摘要树构建
首先,将文档分割成多个文本块(chunks),并使用LLM对每连续的g个文本块进行总结。
通过递归合并这些摘要,最终形成一个树状结构,其中叶子节点对应文本块,中间或根节点对应摘要。
使用预训练的嵌入模型对所有的文本块和摘要进行编码,并存储在Faiss中以支持高效的密集检索。
2)实体图构建
使用SpaCy从每个文本块中提取命名实体(如人名、地名等),并通过实体在同一句子中的共现关系来构建无向加权边。
如果在同一句子中出现,则在这些实体之间建立一条边,边的权重反映它们在句子中的共现频率。
这样,每个文本块就会形成一个子图,捕捉了该块内实体之间的关系。
最后,将所有文本块的子图合并成一个全局图,统一相同的实体并汇总相同源和目标实体的边的权重。
2、检索阶段
设计一种自适应检索策略,利用图结构在局部和全局模式之间动态选择。如果查询实体在图中密集连接,则执行局部检索;否则,切换到全局检索。
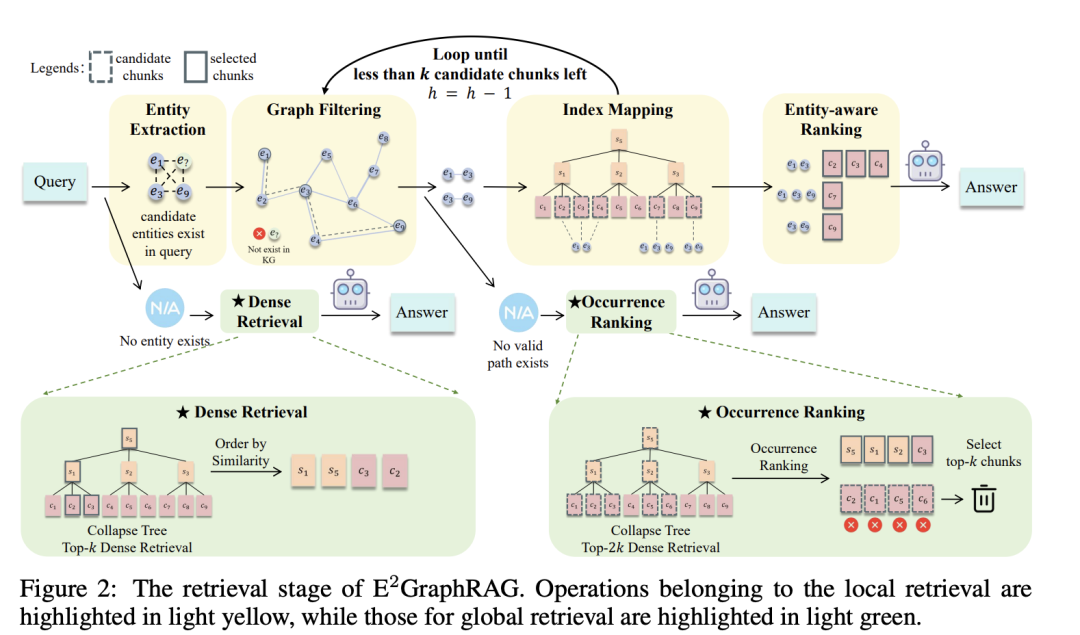
如上所示,具体步骤包括:
1)实体提取:首先,使用SpaCy从查询中提取实体,并将这些实体映射到构建的图中。如果没有识别到任何实体,则执行密集检索。
2)图过滤:如果有实体,则引入图过滤步骤,保留核心实体。具体来说,计算查询中所有实体对之间的最短路径长度,只保留在h跳数以内的实体对。这样可以过滤掉不相关的实体对;
3)索引映射:如果有细粒度的实体对,则执行索引映射,找到与这些实体相关的块集合。通过实体到块的索引和块到实体的索引,找到同时包含这两个实体的块集合。
4)调整跳数阈值:根据块集合的大小,逐步减少跳数阈值,直到满足条件或检索结果为空。如果过滤后没有细粒度的相关实体对,则将其分类为粗粒度的全局查询;
5)实体感知排序:最后,应用实体感知排序机制,从筛选后的块中选择前k个作为补充证据。排序基于多个结构和统计信号,如实体覆盖度和实体出现频率。
通过这种自适应策略,根据查询实体的图结构动态选择局部或全局检索模式,从而提高检索效率和准确性。
参考文献
1、https://arxiv.org/pdf/2506.11763
2、https://arxiv.org/pdf/2505.24226
(文:老刘说NLP)