上一次相关的项目发布,还是前一段时间我写的MiniMax声音模型的更新,Speech-02。
而昨晚凌晨将近12点的时候,又是MiniMax,居然在X上,预告了他们一整周的发布计划。
给我整不会了,不是,为什么总是选择这么阴间的时间点发布啊。。。
而第一天(也就是昨天),发布了他们MiniMax Week的第一个项目:开源MiniMax首个推理模型M1。
我先说结论:“MiniMax M1的上下文能力,就现在全球最屌、最牛逼的、足以媲美Gemini 2.5 Pro的开源模型。”
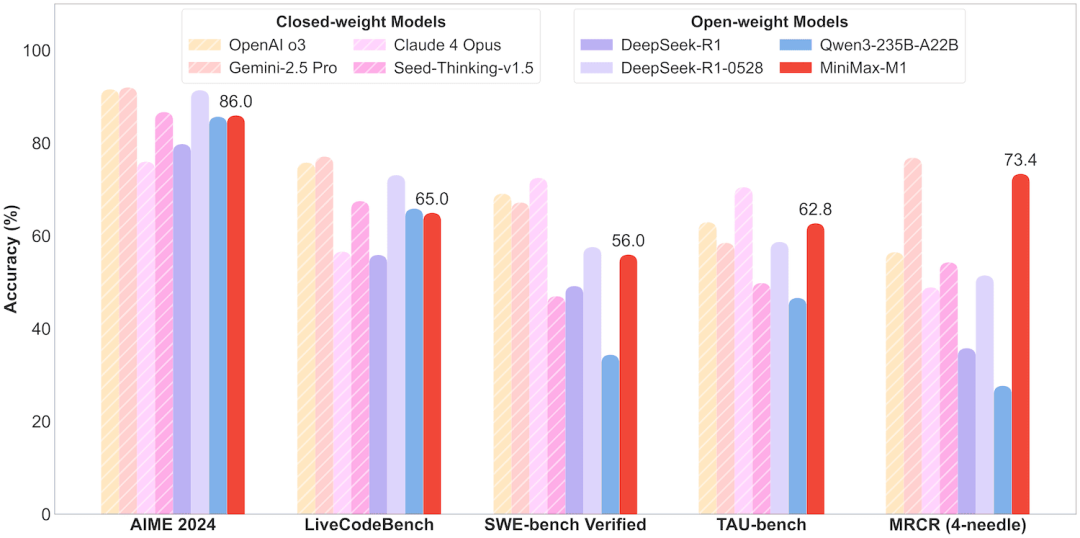
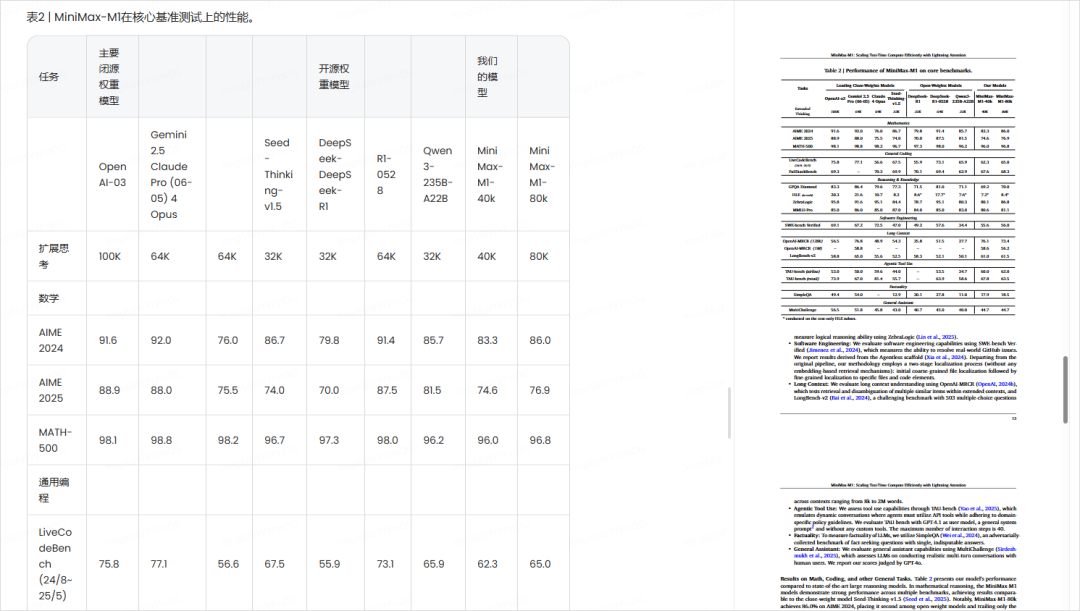
在AIME 2024逻辑数学题目上(偏奥数思维)和LiveCodeBench编程题上、还有SWE-bench Verified(真实世界代码补全+修改),MiniMax M1的表现只能说中规中矩,有弱的、有强的。
而TAU-bench(需要理解任务目标、推理动机的场景),M1 准确率62.8%,开始媲美开源模型。
但是,最离谱的来了,最后一个,MRCR(4-needle)。
这个直接,屠榜了,真的就一瞬间,一柱擎天,直接跟Gemini2.5Pro肩并肩,我相信用过Gemini 2.5 pro的伙伴,都知道,这玩意的上下文有多离谱,而现在,MiniMax M1作为一个开源的大模型,首次,在这个评测集上,能跟Gemini 2.5 Pro并驾齐驱了。
很多人不知道MRCR(4-needle)是个啥,我简单解释一下。
AI圈之前一直有一个测上下文能力的测试,叫做“大海捞针”。
我23年的这个测试刚出来的时候我就写过:花7000块实测Claude2.1 – 200K Token的超大杯效果究竟怎么样?
X上一个大佬Greg Kamradt,为了弄明白当年Claude2.1的200K Token,究竟实测效果怎么样,就调用Claude 的API做了个压力测试,从一段不同长度的文本中,捞出特定的信息,而这个测试,花了他1000美金。
Claude-2.1当时红了一片,200K几乎没有蛋用,巨水无比。
而那一次,Kimi在我的文章下留言,说自己内部测了一下,全绿。
后来呢,Gemini觉得这个大海捞针测试太初级了,于是自己搓了一个新的测试方法,叫做Michelangelo。
在这个论文里,他们提出了Michelangelo的几个评估任务,有Latent List、IDK,而第三个,就是MRCR。
全称叫Multi-Round Co-reference Resolution,翻译成中文叫多轮共指消解,反正非常拗口。
它主要考察一个模型在处理较长的、多轮对话时,能否准确地理解和区分用户要求中具体指的是哪一次对话、哪一个内容。
比如用户和AI进行了一系列对话,用户要求AI写一些东西,比如诗、谜语、文章。在这些对话中,会刻意插入多个看起来类似的话题(比如多首关于企鹅的诗)。
然后再让AI回头去重新找到某一次特定的话,比如用户要求“再重复一遍第二首写企鹅的诗”,此时模型必须精准识别这个“第二首”指的具体是哪一次回答的内容。
这个事其实不简单,因为对话很长,涉及多个话题和文体,非常考验模型的上下文理解力。
有些内容在主题和格式上极其相似,比如“关于企鹅的第一首诗”和“关于企鹅的第二首诗”。模型必须能清晰区分、精准回溯。
后面OpenAI在发GPT-4.1的时候,也在blog里面提到,自己魔改了一个难度更高的MRCR的评测集,用来评估模型的上下文性能。
而“4-needle” 指的是,在同一段超长上下文里同时埋下 4 个“针”(关键信息片段),然后在后续对话里以交错的方式把这 4 根针全部翻出来。
在这个任务下,MiniMax-M1,吊打了一切,只跟Gemini 2.5 pro,差了那一点点的距离。
我翻了下技术报告,M1之所以在上下文有这个性能,核心点还是在于他们之前开源的基座模型MiniMax-01。
得益于MiniMax-01 Lightning Attention线性注意力机制的应用,M1的时间和空间复杂度随序列长度增加近似线性增长,不像传统Transformer那样呈平方级膨胀。
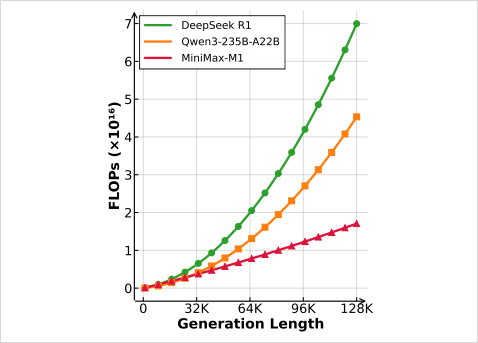
因为Lightning Attention机制,在推理生成长度64K token时,FLOPs消耗不到DeepSeek R1的一半。
当生成长度达到100K token时,M1仅消耗其约25%的FLOPs。
而这个MiniMax-M1,跟之前开源的基座模型MiniMax-01一样,也是456B参数,MoE架构,实际激活45.9B。
最长上下文长度为100万字,也就是1M,是DeepSeek-R1的8倍。
这次开源了两个上下文长度的推理模型,40K和80K。
80K版本是在40K版本基础上进一步训练得到的增强版本。
这里注意一下,80K和40K指的不是上下文长度,上下文长度是1M,80K和40K指的是Extended Thinking的上限。
GitHub: https://github.com/MiniMax-AI/MiniMax-M1
Hugging Face:https://huggingface.co/spaces/MiniMaxAI/MiniMax-M1
目前在MiniMax的官网上也上线了。
网址在此,可以直接用。
https://chat.minimaxi.com/
我也第一时间,上去测了一下。
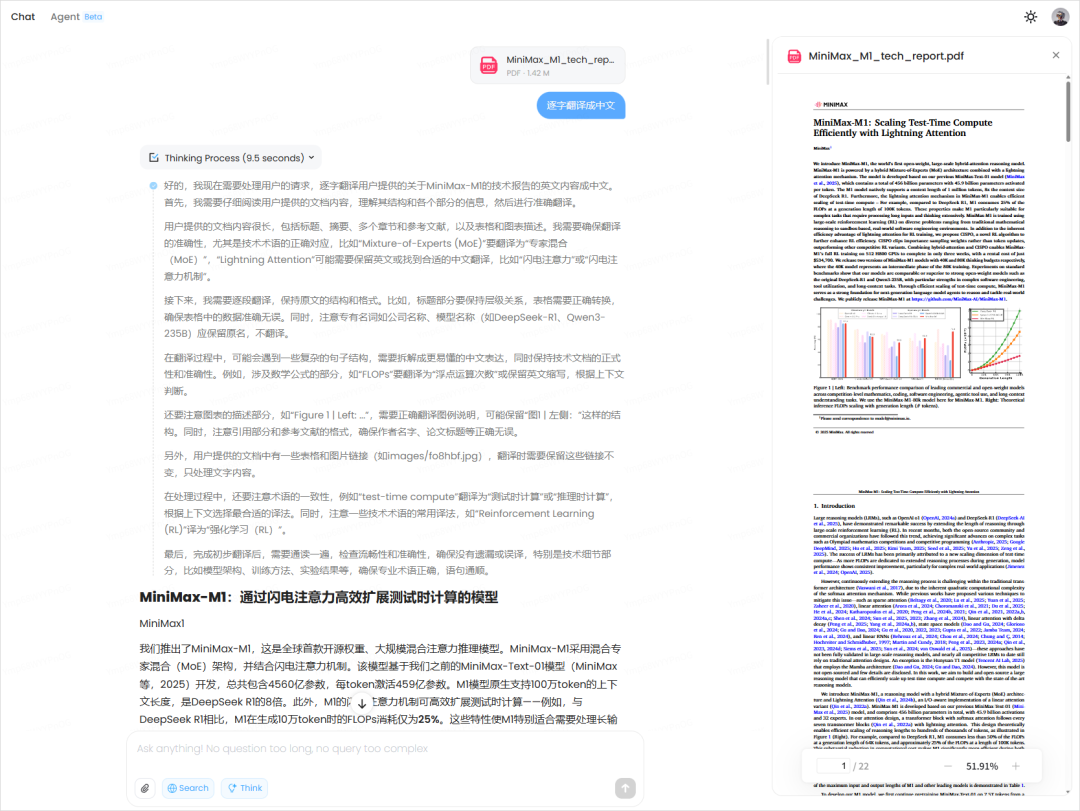
我的第一个任务,就让我开了眼,因为我只是,小小的尝试一下,没想到效果,比我预期的还要好,我直接把MiniMax-M1的技术报告扔了进去,让它,给我逐字翻译。
现在看着还比较正常对吧。
但是,马上,离谱的事情来了。
他居然把图,也给我…带出来了。。。
甚至不仅有图,还有,公式。
还把表格,直接拎出来翻译了。
这效果,这体验,真的无敌。
虽然中间,有部分的图表丢失,还没有达到100%的完整度,但是这个效果,也已经非常非常好了,关键的是文字,一个不落,全部都整整齐齐的给我翻译出来了。
最搞笑的是,他还自作主张,在最后,可能觉得参考文献翻译出来没什么用,直接自己给省略了。
我说实话,这个参考文献,占了5页,对我来说,确实没啥用。。。
在翻译上,我又试了一个更有趣的场景,我扔了一个文档过去,然后说:
“翻译成中文,在括号里标注一些符合我英语水平的原文英文词汇或短语。我英语水平是大学六级。”
太有意思了,这个上下文准确性,是真的牛逼。
然后我又做了一个测试,把我群里这一周的聊天记录,导出出去也扔给了MiniMax-M1,让他把绛烨的聊天记录都找出来。
他准确的识别除了绛烨的微信ID,然后找到了他的微信号,扒出了他的所有聊天记录。。。
这些链接,是真的能点的,我惊了,他还做了样式重构。。。
因为超长超准的上下文,你还可以,跟大模型玩一局,真正的文字冒险游戏,因为他不会忘记你的出身,他会记得,一切。
推理模型+超长且精准上下文的扩充,确实会带来,很多不一样的花活玩法。
比如我还有一个特别狠的测试。
就是我手上有一个34个刘慈欣老师的小说的合集,因为大刘除了世人皆知的三体之外,他其实还写过特别多的科幻中短篇小说,也特别好看。
比如我最爱的《山》。
我现在,想把这些故事,安利给我的朋友们,我想,让AI根据这34个故事,每一个故事都写一段故事总结+推荐语。
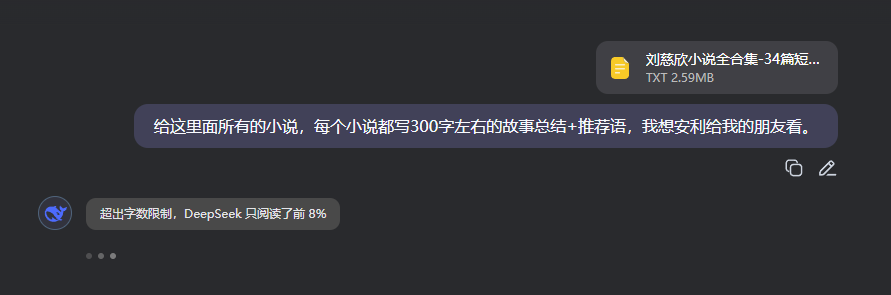
这个任务,你要是扔给DeepSeek。
你就会得到一个非常离谱的提示,DeepSeek只阅读了8%。。。
而MiniMax-M1,出色的完成了任务。
超长上下文的魅力,此时体现的淋漓尽致。
不过我有一个更变态的任务,还是给MiniMax-M1干宕机了。
就是…我让它数本草纲目里一共有多少药材= =
数了8分钟,最后跟我说,有400中种,但其实答案是1892种= =
不过我也能理解,这个任务,确实实在是太变态了。。。
除了上下文之外,我也测了些写作、编程、数学。
写作和数学就不详细提了,写作这块中规中矩,数学的高考题实在没空完整做了,我觉得我需要抽空写一个脚本。
不过测了两道大题,目前是都对的。
最后稍微吐槽一下编程这块,就是前端审美,感觉还是有一些进步空间的。
就…有一点,不好看啊。
比如我昨天下午去参加了飞书多维表格的闭门会,会议特别有价值,我想做个可视化网页。
这是Gemini生成的。
这是M1生成的。
咱就是说,可以不这么直男审美的= =
总体来说,M1模型,还是让我有一点惊喜的,他们自己的新研究,确实卷出了一些很有意思的特性,也把开源领域的模型水平,又拔高了一个层级。
还有4天时间,我现在有点期待MiniMax会继续掏出什么有意思的大货了。
以我对MiniMax的了解,视频模型总归要来一个的吧,已经有一段时间没更新了,Video 01-Director已经是几个月前的事了。
你Hailuo 02(0616)都去打榜了,那你这5天里,得掏一下吧。
海螺的人物情绪表演、动作表演,至今依然是我心中的白月光。
极度期待Hailuo 02,在人物表演上,会带给我什么样的震撼。
声音模型估计不发新的了,因为一个月前Speech-02才发。
图片和3DMiniMax不做,那在掏个音乐模型?这个符合MiniMax的气质。
这一周,希望MiniMax尽情撒货吧。
让AI的这一把火。
烧的更热烈些。
(文:数字生命卡兹克)