


Anthropic把自家的深度研究功能构建过程分享出来了,非常值得一读

当面对需要跨越海量信息、探索未知领域的复杂研究任务时,单一的大语言模型(LLM)往往会遇到瓶颈。为了更有效地解决这类问题,Anthropic 的工程师们构建了一套先进的多智能体研究系统,并将其整合为 Claude 的“研究”(Research)功能。
Anthropic详细分享了该系统从原型到产品的全过程,为我们揭示了构建一个高效、可靠的智能体系统所必需的核心原则、架构设计和工程智慧
一、为什么选择多智能体系统?
研究工作本质上是开放和动态的,无法预设固定的路径。它需要根据新发现不断调整方向,这恰好是 AI 智能体(Agent)的优势所在。然而,单智能体在处理需要“广度优先”搜索的复杂查询时,仍然会因顺序执行而效率低下
多智能体系统通过以下方式解决了这一难题:
并行压缩与分工: 系统的核心思想是“压缩”——从海量信息中提炼洞见。多个“子智能体”(Subagents)可以并行工作,各自拥有独立的上下文窗口,同时探索问题的不同方面。这种分工不仅减少了路径依赖,还实现了关注点分离(例如,不同的子智能体使用不同的工具或提示)
性能的指数级提升: Anthropic 的内部评估显示,在处理需要分解任务的复杂查询时(如“找出标普500信息技术板块所有公司的董事会成员”),一个由 Claude Opus 4 担任主智能体、Claude Sonnet 4 担任子智能体的多智能体系统,其性能比单个 Claude Opus 4 智能体高出 90.2%。
代价与权衡: 强大的性能并非没有代价。多智能体系统是“token消耗大户”。数据显示,智能体交互的 token 消耗约为普通聊天的 4 倍,而多智能体系统则高达 15 倍。因此,这类系统最适用于那些能够通过其卓越性能创造足够高价值的任务
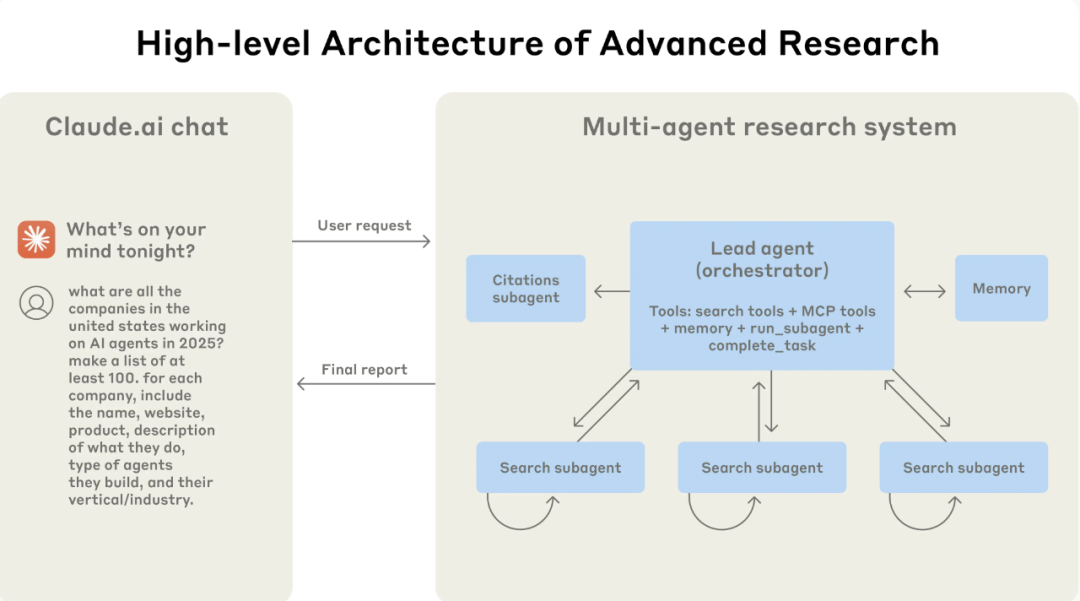
二、系统核心架构:“指挥家-演奏家”模式
该研究系统采用了一种经典的 “指挥家-演奏家”(Orchestrator-Worker)模式
主智能体(Lead Agent / 指挥家): 当用户提交一个复杂查询后,系统会创建一个主智能体。它负责:
* **理解和规划:** 分析用户意图,制定一个全面的研究策略。
* **任务分解与授权:** 将大任务分解为多个独立的子任务。
* **创建子智能体:** 为每个子任务生成专门的“子智能体”,并分配任务。
* **结果合成:** 汇总所有子智能体返回的信息,进行综合分析,形成最终报告。子智能体(Subagents / 演奏家): 它们是并行的工作单元,接收主智能体的指令,独立地执行搜索、评估信息,然后将关键发现返回给主智能体
外部记忆(Memory): 为了处理超过模型上下文窗口(如200K tokens)的超长任务,系统使用外部记忆来持久化存储研究计划等关键信息,防止上下文丢失
引用智能体(Citation Agent): 在生成最终报告后,一个专门的引用智能体会负责检查报告中的所有声明,并将其与原始信源进行匹配,确保所有信息都有据可查。
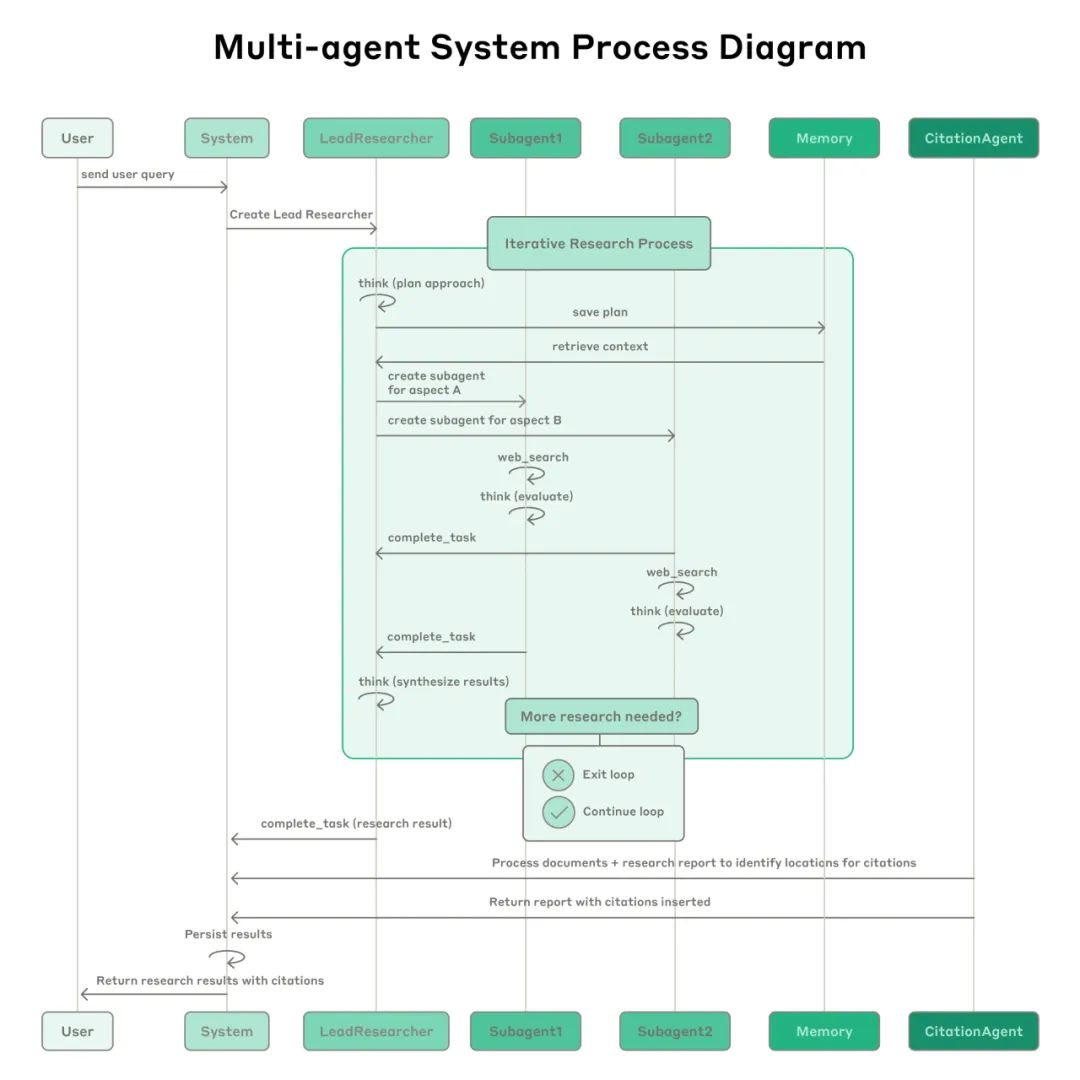
整个流程是一个动态的、迭代的循环。主智能体可以根据初步结果调整策略,创建更多的子智能体进行深入或补充研究,直到收集到足够的信息为止。
三、成功的关键:提示工程与评估的最佳实践
让一群智能体高效协作远比控制单个智能体复杂。Anthropic 分享了他们在提示工程和系统评估方面的八大原则:
提示工程(Prompt Engineering)的八大原则:
-
1. 像智能体一样思考: 通过模拟系统,逐步观察智能体的行为,理解其“心智模型”,从而发现失败模式(如过度搜索、选择错误工具)并进行针对性优化 -
2. 教会“指挥家”如何授权: 给子智能体的指令必须清晰具体,包含明确的目标、输出格式、工具使用建议和任务边界,避免模糊指令导致的重复工作或任务失败。 -
3. 根据任务复杂度调整投入: 在提示中嵌入规则,指导主智能体根据任务的复杂性(简单事实查询、对比分析、复杂研究)来决定启动的子智能体数量和工具调用次数,避免资源浪费。 -
4. 精心设计工具(Tool): 工具的接口和描述至关重要。为智能体提供明确的启发式规则(如优先使用专用工具、先广泛搜索再深入),确保它们能选择正确的工具。 -
5. 让智能体自我改进: Claude 4 模型本身就是优秀的提示工程师。Anthropic 创建了一个“工具测试智能体”,当发现一个工具描述有问题时,它能自我诊断、重写描述以避免未来出错,使任务完成时间减少了 40%。 -
6. 先拓宽,再深入(Start wide, then narrow down): 引导智能体模仿人类专家的研究方式——先用宽泛的查询探索全景,评估可用信息,再逐步缩小焦点。 -
7. 引导思考过程(Extended thinking): 利用模型的“思考”能力作为可控的草稿纸。主智能体通过“思考”来规划、评估和分配任务。子智能体则在每次工具调用后进行“思考”,评估结果质量并规划下一步行动。 -
8. 并行化提升速度与性能: 系统实现了两个层面的并行化:主智能体并行启动多个子智能体;每个子智能体可以并行调用多个工具。这使得复杂研究的耗时从数小时缩短到几分钟。
有效评估(Effective Evaluation)的三大原则:
-
1. 从小样本开始快速迭代: 在开发早期,一个小的、有代表性的测试集(约20个查询)就足以发现重大问题并验证改进效果。不要等到构建完美的大型评估集才开始测试 -
2. 利用 LLM 作为“裁判”: 对于难以程序化评估的自由格式文本输出,LLM 是理想的“裁判”。Anthropic 使用一个 LLM 裁判,根据一套标准(事实准确性、引用准确性、完整性、信源质量等)对输出进行打分。 -
3. 人工评估不可或缺: 自动化评估无法捕捉所有边缘案例。人工测试员能发现微妙的偏见(如早期版本偏爱SEO优化的内容农场而非学术PDF)和系统性故障。
四、从原型到产品:生产环境的可靠性挑战
将一个复杂的智能体系统投入生产环境,会遇到传统软件开发中不常见的挑战
状态与错误累积: 智能体是长时运行且有状态的。任何一个小错误都可能被放大,导致整个任务失败。因此,系统必须具备 从故障点恢复(Resume)的能力,而不是从头开始。
调试困难: 智能体的非确定性使得复现和调试问题异常困难。解决方案是引入 高级别的生产追踪(Tracing,监控智能体的决策模式和交互结构,而非具体对话内容,以保护用户隐私
部署协调: 由于智能体是持续运行的,不能简单地停止旧版本、启动新版本。Anthropic 采用 “彩虹部署”(Rainbow Deployments),新旧版本的系统同时运行,流量逐步从旧版本迁移到新版本,确保平稳过渡
性能瓶颈: 目前的同步执行模式(主智能体等待一批子智能体完成后再继续)简化了协调,但造成了瓶颈。未来的方向是异步执行,虽然会增加复杂性,但性能收益将是巨大的。
结论
构建一个生产级别的多智能体研究系统是一项艰巨的工程挑战,“最后一公里”往往最为艰难。从原型到可靠的产品,需要细致的工程设计、全面的测试、精巧的提示与工具设计,以及跨团队的紧密合作。
参考:
https://www.anthropic.com/engineering/built-multi-agent-research-system
⭐
(文:AI寒武纪)